


Mengenai pembelajaran pengukuhan, banyak adrenalin penyelidik melonjak secara tidak terkawal! Ia memainkan peranan yang sangat penting dalam sistem AI permainan, robot moden, sistem reka bentuk cip dan aplikasi lain.
Terdapat pelbagai jenis algoritma pembelajaran pengukuhan, tetapi ia terbahagi kepada dua kategori: "berasaskan model" dan "bebas model".
Dalam perbualan dengan TechTalks, ahli sains saraf dan pengarang "The Birth of Intelligence" Daeyeol Lee membincangkan model pembelajaran pengukuhan yang berbeza dalam manusia dan haiwan, kecerdasan buatan dan kecerdasan semula jadi serta hala tuju penyelidikan masa hadapan .

Pada akhir abad ke-19, "undang-undang kesan" yang dicadangkan oleh ahli psikologi Edward Thorndike menjadi asas model- pembelajaran pengukuhan percuma . Thorndike mencadangkan bahawa tingkah laku yang mempunyai kesan positif dalam situasi tertentu lebih berkemungkinan berlaku lagi dalam situasi itu, manakala tingkah laku yang mempunyai kesan negatif kurang berkemungkinan berlaku lagi.
Thorndike meneroka "hukum kesan" ini dalam percubaan. Dia meletakkan seekor kucing di dalam kotak maze dan mengukur masa yang diambil untuk kucing itu melarikan diri dari kotak itu. Untuk melarikan diri, kucing mesti mengendalikan satu siri alat, seperti tali dan tuas. Thorndike memerhatikan bahawa semasa kucing berinteraksi dengan kotak teka-teki, ia mempelajari tingkah laku yang membantu melarikan diri. Apabila masa berlalu, kucing itu melarikan diri dari kotak dengan lebih cepat dan lebih cepat. Thorndike membuat kesimpulan bahawa kucing boleh belajar daripada ganjaran dan hukuman yang diberikan oleh tingkah laku mereka. "Hukum Kesan" kemudiannya membuka jalan kepada behaviorisme. Behaviorisme ialah satu cabang psikologi yang cuba menerangkan tingkah laku manusia dan haiwan dari segi rangsangan dan tindak balas. "Hukum Kesan" juga merupakan asas pembelajaran peneguhan tanpa model. Dalam pembelajaran peneguhan tanpa model, ejen melihat dunia dan kemudian mengambil tindakan sambil mengukur ganjaran.
Dalam pembelajaran peneguhan tanpa model, tiada pengetahuan langsung atau model dunia. Ejen RL mesti mengalami secara langsung keputusan setiap tindakan melalui percubaan dan kesilapan.
"Hukum Kesan" Thorndike kekal popular sehingga tahun 1930-an. Seorang lagi ahli psikologi pada masa itu, Edward Tolman, menemui satu pandangan penting sambil meneroka bagaimana tikus cepat belajar mengemudi labirin. Semasa eksperimennya, Tolman menyedari bahawa haiwan boleh belajar tentang persekitaran mereka tanpa tetulang.
Sebagai contoh, apabila tetikus dilepaskan dalam labirin, ia akan meneroka terowong secara bebas dan secara beransur-ansur memahami struktur persekitaran. Jika tikus itu kemudiannya diperkenalkan semula ke persekitaran yang sama dan dibekalkan dengan isyarat pengukuhan, seperti mencari makanan atau mencari jalan keluar, ia boleh mencapai matlamat lebih cepat daripada haiwan yang belum meneroka labirin. Tolman memanggil ini "pembelajaran terpendam", yang menjadi asas pembelajaran peneguhan berasaskan model. "Pembelajaran terpendam" membolehkan haiwan dan manusia membentuk gambaran mental dunia mereka, mensimulasikan senario hipotetikal dalam fikiran mereka dan meramalkan hasil.
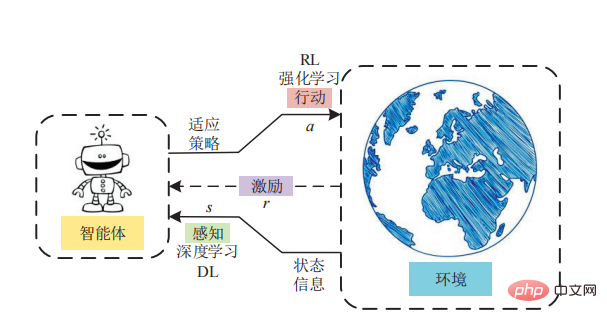
Kelebihan pembelajaran tetulang berasaskan model ialah ia menghapuskan keperluan untuk ejen melakukan percubaan dan kesilapan dalam persekitaran. Perlu ditekankan bahawa pembelajaran pengukuhan berasaskan model telah berjaya terutamanya dalam membangunkan sistem kecerdasan buatan yang mampu menguasai permainan papan seperti catur dan Go, mungkin kerana persekitaran permainan ini bersifat deterministik.

Secara umumnya, pembelajaran peneguhan berasaskan model akan memakan masa yang sangat lama , ia mungkin Bahaya maut berlaku. "Secara pengiraan, pembelajaran tetulang berasaskan model adalah lebih kompleks," kata Lee "Mula-mula anda perlu mendapatkan model, melakukan simulasi mental, dan kemudian anda perlu mencari trajektori proses saraf dan kemudian mengambil tindakan. pembelajaran peneguhan berasaskan model tidak semestinya Ia lebih rumit daripada RL tanpa model "Apabila persekitaran sangat kompleks, jika ia boleh dimodelkan dengan model yang agak mudah (yang boleh diperolehi dengan cepat), maka simulasi akan menjadi lebih mudah. dan kos efektif.
Malah, pembelajaran peneguhan berasaskan model mahupun pembelajaran peneguhan tanpa model adalah penyelesaian yang sempurna. Di mana-mana sahaja anda melihat sistem pembelajaran tetulang menyelesaikan masalah yang kompleks, kemungkinan besar sistem tersebut menggunakan kedua-dua pembelajaran tetulang berasaskan model dan tanpa model, dan mungkin juga lebih banyak bentuk pembelajaran. Penyelidikan dalam neurosains menunjukkan bahawa kedua-dua manusia dan haiwan mempunyai pelbagai cara pembelajaran, dan otak sentiasa bertukar antara mod ini pada bila-bila masa. Dalam tahun-tahun kebelakangan ini, terdapat peningkatan minat dalam mencipta sistem kecerdasan buatan yang menggabungkan pelbagai model pembelajaran pengukuhan. Penyelidikan terkini oleh saintis di UC San Diego menunjukkan bahawa menggabungkan pembelajaran tetulang tanpa model dan pembelajaran tetulang berasaskan model boleh mencapai prestasi unggul dalam tugas kawalan. "Jika anda melihat algoritma kompleks seperti AlphaGo, ia mempunyai kedua-dua elemen RL bebas model dan elemen RL berasaskan model," kata Lee "Ia mempelajari nilai keadaan berdasarkan konfigurasi papan. Ia pada asasnya RL tanpa model. tetapi Carian hadapan berasaskan model juga dilakukan 》
Walaupun pencapaian yang ketara, kemajuan dalam pembelajaran pengukuhan adalah perlahan. Sebaik sahaja model RL menghadapi persekitaran yang kompleks dan tidak dapat diramalkan, prestasinya mula merosot.
Lee berkata: "Saya rasa otak kita ialah dunia algoritma pembelajaran yang kompleks yang telah berkembang untuk mengendalikan pelbagai situasi yang berbeza
Selain daripada sentiasa bergerak antara mod pembelajaran ini Selain daripada beralih, otak juga berjaya mengekalkan dan mengemas kininya sepanjang masa, walaupun mereka tidak terlibat secara aktif dalam membuat keputusan.
Pakar psikologi Daniel Kahneman berkata: "Mengekalkan modul pembelajaran yang berbeza dan mengemas kininya secara serentak boleh membantu meningkatkan kecekapan dan ketepatan sistem kecerdasan buatan
Kita juga perlu memahami aspek lain - bagaimana untuk gunakan bias induktif yang betul dalam sistem AI untuk memastikan mereka mempelajari perkara yang betul dengan cara yang kos efektif. Berbilion tahun evolusi telah memberikan manusia dan haiwan kecenderungan induktif yang diperlukan untuk belajar dengan berkesan sambil menggunakan data sesedikit mungkin. Bias induktif boleh difahami sebagai meringkaskan peraturan daripada fenomena yang diperhatikan dalam kehidupan sebenar, dan kemudian meletakkan kekangan tertentu pada model, yang boleh memainkan peranan pemilihan model, iaitu memilih model yang lebih konsisten dengan peraturan sebenar daripada ruang hipotesis. "Kami mendapat sangat sedikit maklumat daripada persekitaran. Menggunakan maklumat itu, kami perlu membuat generalisasi," kata Lee "Sebabnya ialah otak mempunyai kecenderungan induktif, dan terdapat kecenderungan untuk membuat generalisasi daripada satu set contoh yang kecil. produk evolusi." , semakin ramai ahli sains saraf berminat dalam hal ini." Walau bagaimanapun, walaupun bias induktif mudah difahami dalam tugas pengecaman objek, ia menjadi kabur dalam masalah abstrak seperti membina hubungan sosial. Pada masa hadapan, masih banyak yang perlu kita ketahui~~~
https://thenextweb.com/news/everything-you-need-to- tahu-tentang-pembelajaran-peneguhan-bebas-model-dan-berasaskan-model
Atas ialah kandungan terperinci Daripada tikus berjalan dalam mez kepada AlphaGo mengalahkan manusia, pembangunan pembelajaran pengukuhan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah itu mata wang digital
Apakah itu mata wang digital
 Bagaimana untuk membuka fail ESP
Bagaimana untuk membuka fail ESP
 Bagaimana untuk mematikan perlindungan masa nyata dalam Pusat Keselamatan Windows
Bagaimana untuk mematikan perlindungan masa nyata dalam Pusat Keselamatan Windows
 Apakah ciri baharu Hongmeng OS 3.0?
Apakah ciri baharu Hongmeng OS 3.0?
 Bagaimana untuk membuka kunci telefon oppo jika saya terlupa kata laluan
Bagaimana untuk membuka kunci telefon oppo jika saya terlupa kata laluan
 Bagaimana untuk menyelesaikan masalah yang localhost tidak boleh dibuka
Bagaimana untuk menyelesaikan masalah yang localhost tidak boleh dibuka
 MySQL mencipta prosedur tersimpan
MySQL mencipta prosedur tersimpan
 Bagaimana untuk membeli dan menjual Bitcoin? Tutorial Dagangan Bitcoin
Bagaimana untuk membeli dan menjual Bitcoin? Tutorial Dagangan Bitcoin








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



