


Pembelajaran pengukuhan (RL) membolehkan robot berinteraksi melalui percubaan dan kesilapan untuk mempelajari tingkah laku yang kompleks dan menjadi lebih baik dan lebih baik dari semasa ke semasa. Beberapa kerja terdahulu di Google telah meneroka cara RL boleh membolehkan robot menguasai kemahiran kompleks seperti menggenggam, pembelajaran berbilang tugas dan juga bermain pingpong. Walaupun pembelajaran pengukuhan dalam robot telah mencapai kemajuan yang besar, kami masih tidak melihat robot dengan pembelajaran pengukuhan dalam persekitaran harian. Oleh kerana dunia sebenar adalah kompleks, pelbagai dan sentiasa berubah dari semasa ke semasa, ini menimbulkan cabaran besar kepada sistem robotik. Walau bagaimanapun, pembelajaran pengukuhan harus menjadi alat yang sangat baik untuk menangani cabaran ini: dengan berlatih, menambah baik dan belajar di tempat kerja, robot harus dapat menyesuaikan diri dengan dunia yang berubah-ubah.
Dalam kertas kerja Google "Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators", penyelidik meneroka cara menyelesaikan masalah ini melalui eksperimen berskala besar terkini, mereka mengerahkan kumpulan 23 robot berdaya RL selama dua tahun untuk mengisih dan mengitar semula sampah di bangunan pejabat Google. Sistem robotik yang digunakan menggabungkan pembelajaran pengukuhan dalam berskala daripada data dunia sebenar dengan input sedar objek berpandu dan tambahan daripada latihan simulasi untuk meningkatkan generalisasi sambil mengekalkan kelebihan latihan akhir ke hujung untuk disahkan.

Alamat kertas: https://rl-at-scale.github.io/assets/rl_at_scale .pdf
Jika orang ramai tidak menyusun sisa mereka dengan betul, kumpulan kitar semula boleh menjadi tercemar dan kompos boleh dibuang dengan tidak betul di tapak pelupusan sampah. Dalam percubaan Google, robot berkeliaran di sekitar bangunan pejabat mencari "pembuangan sampah" (tong kitar semula, tong kompos dan tong sampah lain). Tugas robot adalah untuk tiba di setiap stesen sampah untuk menyusun sisa, mengangkut barang antara tong yang berbeza untuk meletakkan semua barang kitar semula (tin, botol) ke dalam tong kitar semula dan semua barang boleh kompos (bekas kadbod, cawan kertas ) ke dalam tong kompos dan semua yang lain dalam tong sampah lain.
Sebenarnya tugasan ini tidak semudah yang dilihat. Hanya sub-tugas mengutip barang-barang yang berbeza yang dibuang orang ke dalam tong sampah sudah menjadi cabaran besar. Robot juga mesti mengenal pasti tong yang sesuai untuk setiap objek dan menyusunnya secepat dan seefisien mungkin. Di dunia nyata, robot menghadapi pelbagai situasi unik, seperti contoh bangunan pejabat sebenar berikut:
Di tempat kerja Pembelajaran berterusan membantu , tetapi sebelum anda sampai ke tahap itu, anda perlu membimbing robot dengan set kemahiran asas. Untuk tujuan ini, Google menggunakan empat sumber pengalaman: (1) strategi reka bentuk tangan yang mudah, yang mempunyai kadar kejayaan yang rendah tetapi membantu memberikan pengalaman awal; (2) rangka kerja latihan simulasi yang menggunakan pemindahan simulasi kepada sebenar untuk menyediakan beberapa pengalaman awal. strategi pengasingan sampah; (3) "bilik darjah robot", di mana robot menggunakan stesen sampah untuk berlatih secara berterusan;
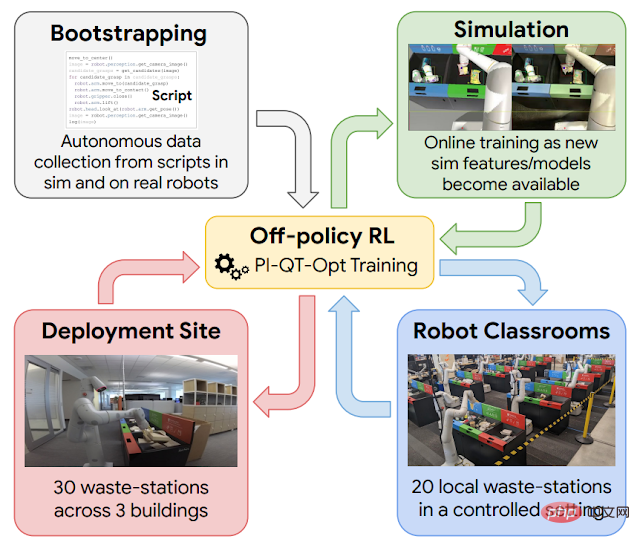
Gambar rajah skematik pembelajaran pengukuhan dalam aplikasi berskala besar ini. Gunakan data yang dijana skrip untuk membimbing pelancaran dasar (kiri atas). Model simulasi kepada sebenar kemudiannya dilatih, menjana data tambahan dalam persekitaran simulasi (kanan atas). Semasa setiap kitaran penggunaan, tambahkan data yang dikumpul dalam "bilik darjah robot" (kanan bawah). Menyebarkan dan mengumpul data di bangunan pejabat (kiri bawah).
Rangka kerja pembelajaran pengukuhan yang digunakan di sini adalah berdasarkan QT-Opt, yang juga digunakan untuk menangkap sampah yang berbeza dalam persekitaran makmal dan satu siri kemahiran lain. Mulakan dengan strategi skrip mudah untuk membimbing anda dalam persekitaran simulasi, gunakan pembelajaran pengukuhan dan gunakan kaedah pemindahan berasaskan CycleGAN untuk menjadikan imej simulasi kelihatan lebih realistik menggunakan RetinaGAN.
Di sinilah anda mula memasuki "bilik darjah robot". Walaupun bangunan pejabat sebenar memberikan pengalaman yang paling realistik, daya pemprosesan data adalah terhad—sesetengah hari akan ada banyak sampah untuk diisih, hari lain tidak begitu banyak. Robot telah mengumpul sebahagian besar pengalaman mereka dalam "bilik darjah robot." Dalam "bilik darjah robot" yang ditunjukkan di bawah, terdapat 20 robot yang berlatih tugas menyusun sampah:

Apabila robot ini dilatih dalam "bilik darjah robot" Pada masa yang sama, robot lain sedang belajar pada masa yang sama pada 30 tong sampah di 3 bangunan pejabat.
Akhirnya, penyelidik mengumpul 540,000 data percubaan daripada "bilik darjah robot" dan 325,000 data percubaan dalam persekitaran penggunaan sebenar. Apabila data terus meningkat, prestasi keseluruhan sistem bertambah baik. Para penyelidik menilai sistem akhir dalam "bilik darjah robot" untuk membolehkan perbandingan terkawal, menyediakan senario berdasarkan perkara yang akan dilihat oleh robot dalam penggunaan sebenar. Sistem akhir mencapai ketepatan purata kira-kira 84%, dengan prestasi bertambah baik secara berterusan apabila data ditambah. Di dunia nyata, penyelidik mendokumentasikan statistik daripada penggunaan sebenar pada 2021 hingga 2022 dan mendapati bahawa sistem itu boleh mengurangkan bahan cemar dalam tong sebanyak 40 hingga 50 peratus mengikut berat. Dalam kertas kerja mereka, penyelidik Google memberikan pandangan yang lebih mendalam tentang reka bentuk teknologi, kajian pengecilan pelbagai keputusan reka bentuk dan statistik yang lebih terperinci daripada percubaan mereka.
Hasil eksperimen menunjukkan bahawa sistem berasaskan pembelajaran pengukuhan boleh membolehkan robot mengendalikan tugas sebenar dalam persekitaran pejabat sebenar. Gabungan data luar talian dan dalam talian membolehkan robot menyesuaikan diri dengan pelbagai situasi di dunia nyata. Pada masa yang sama, pembelajaran dalam persekitaran "bilik darjah" yang lebih terkawal, termasuk dalam persekitaran simulasi dan persekitaran sebenar, boleh menyediakan mekanisme permulaan yang berkuasa yang membolehkan "roda tenaga" pembelajaran tetulang mula berputar, dengan itu mencapai kebolehsuaian.
Walaupun keputusan penting telah dicapai, masih banyak kerja yang perlu dilakukan: strategi pembelajaran peneguhan akhir tidak selalu berjaya, model yang lebih berkuasa diperlukan untuk meningkatkan prestasi mereka, dan Kembangkan ini kepada pelbagai tugasan yang lebih luas. Selain itu, sumber pengalaman lain, termasuk daripada tugas lain, robot lain, dan juga video Internet, boleh menambah lagi pengalaman permulaan yang diperoleh daripada simulasi dan "bilik darjah". Ini adalah isu-isu yang perlu ditangani pada masa hadapan.
Atas ialah kandungan terperinci Google mengambil masa dua tahun untuk membina 23 robot menggunakan pembelajaran pengukuhan untuk membantu menyusun sampah. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



