


Kecerdasan Am Buatan (AGI) boleh dianggap sebagai sistem kecerdasan buatan yang mampu memahami, memproses dan bertindak balas terhadap tugas intelektual seperti manusia. Ini adalah tugas yang mencabar yang memerlukan pemahaman yang mendalam tentang bagaimana otak manusia berfungsi supaya kita boleh menirunya. Walau bagaimanapun, kemunculan ChatGPT telah menimbulkan minat yang besar daripada komuniti penyelidik dalam membangunkan sistem tersebut. Microsoft telah mengeluarkan sistem dipacu AI utama yang dipanggil HuggingGPT (Microsoft Jarvis).
Sebelum kita menyelami perkara baharu dalam HuggingGPT dan butiran yang berkaitan tentang cara ia berfungsi, mari kita fahami dahulu isu dengan ChatGPT dan sebab ia menghadapi kesukaran menyelesaikan tugasan AI yang kompleks. Model bahasa besar seperti ChatGPT pandai mentafsir data teks dan mengendalikan tugas umum. Walau bagaimanapun, mereka sering bergelut dengan tugas tertentu dan boleh bertindak balas dengan tidak masuk akal. Anda mungkin telah menemui jawapan palsu daripada ChatGPT semasa menyelesaikan masalah matematik yang rumit. Sebaliknya, kami mempunyai model AI peringkat pakar seperti Stable Diffusion dan DALL-E, yang mempunyai pemahaman yang lebih mendalam tentang bidang subjek masing-masing tetapi bergelut dengan pelbagai tugas yang lebih luas. Melainkan kami mewujudkan hubungan antara LLM dan model AI profesional, kami tidak dapat mengeksploitasi sepenuhnya potensi LLM untuk menyelesaikan tugas AI yang mencabar. Inilah yang dilakukan oleh HuggingGPT, ia menggabungkan kelebihan kedua-duanya untuk mencipta sistem AI yang lebih berkesan, tepat dan serba boleh.
Menurut kertas baru-baru ini yang diterbitkan oleh Microsoft, HuggingGPT memanfaatkan kuasa LLM, menggunakannya sebagai pengawal untuk menyambungkannya dengan pelbagai model AI dalam komuniti pembelajaran mesin (HuggingFace), membolehkannya digunakan Alat luaran untuk meningkatkan produktiviti. HuggingFace ialah tapak web yang menyediakan banyak alat dan sumber kepada pembangun dan penyelidik. Ia juga mempunyai pelbagai jenis model profesional dan berketepatan tinggi. HuggingGPT menggunakan model ini untuk tugas AI yang kompleks dalam domain dan mod yang berbeza, mencapai hasil yang mengagumkan. Ia mempunyai keupayaan berbilang modal yang sama seperti OPenAI GPT-4 apabila ia berkaitan dengan teks dan imej. Walau bagaimanapun, ia juga menghubungkan anda ke Internet, dan anda boleh menyediakan pautan web luaran untuk bertanya soalan mengenainya.
Andaikan anda mahu model melakukan bacaan audio teks yang ditulis pada imej. HuggingGPT akan melaksanakan tugas ini secara bersiri menggunakan model yang paling sesuai. Pertama, ia akan mengeksport teks daripada imej dan menggunakan hasilnya untuk penjanaan audio. Butiran respons boleh dilihat dalam imej di bawah. Sungguh menakjubkan!

Analisis kualitatif kerjasama multimodal mod video dan audio
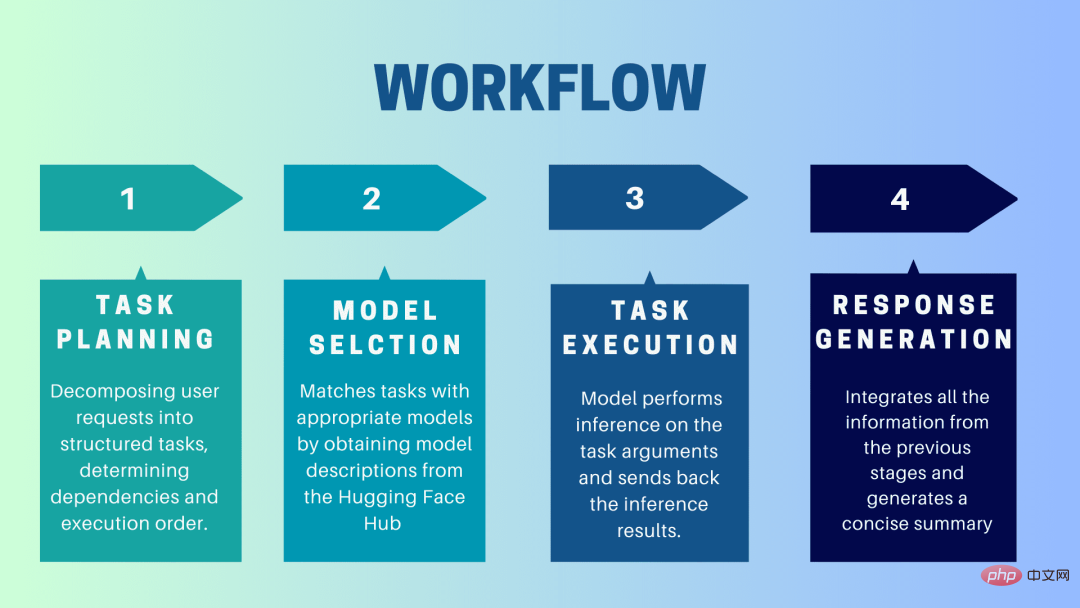
HuggingGPT ialah sistem kerjasama yang menggunakan LLM sebagai antara muka untuk menghantar permintaan pengguna kepada model pakar. Proses lengkap daripada gesaan pengguna kepada model sehingga respons diterima boleh diuraikan kepada langkah-langkah diskret berikut:
Pada peringkat ini, HuggingGPT menggunakan ChatGPT untuk memahami gesaan pengguna, Kemudian pecahkan pertanyaan kepada tugasan kecil yang boleh diambil tindakan. Ia juga mengenal pasti kebergantungan tugas ini dan mentakrifkan susunan tugasan tersebut dilaksanakan. HuggingGPT mempunyai empat slot untuk penghuraian tugas, iaitu jenis tugasan, ID tugasan, kebergantungan tugas dan parameter tugas. Sembang antara HuggingGPT dan pengguna direkodkan dan dipaparkan pada skrin yang menunjukkan sejarah sumber.
Berdasarkan persekitaran pengguna dan model yang tersedia, HuggingGPT menggunakan mekanisme peruntukan model tugas kontekstual untuk memilih model yang paling sesuai untuk tugasan tertentu. Mengikut mekanisme ini, pemilihan model dianggap sebagai soalan aneka pilihan, yang pada mulanya menapis model berdasarkan jenis tugasan. Selepas itu, model telah disenaraikan berdasarkan bilangan muat turun, kerana ia dianggap sebagai ukuran kualiti model yang boleh dipercayai. Model Top-K dipilih berdasarkan kedudukan ini. K di sini hanyalah pemalar yang mencerminkan bilangan model, sebagai contoh, jika ia ditetapkan kepada 3, maka ia akan memilih 3 model dengan paling banyak muat turun.
Di sini, tugasan diberikan kepada model tertentu, yang melakukan inferens padanya dan mengembalikan hasilnya. Untuk menjadikan proses ini lebih cekap, HuggingGPT boleh menjalankan model yang berbeza secara serentak, selagi mereka tidak memerlukan sumber yang sama. Contohnya, jika diberi gesaan untuk menjana gambar kucing dan anjing, model yang berbeza boleh dijalankan secara selari untuk melaksanakan tugas ini. Walau bagaimanapun, kadangkala model mungkin memerlukan sumber yang sama, itulah sebabnya HuggingGPT mengekalkan atribut
Langkah terakhir ialah menjana respons kepada pengguna. Pertama, ia menyepadukan semua maklumat dan hasil penaakulan daripada peringkat sebelumnya. Maklumat dipersembahkan dalam format berstruktur. Contohnya, jika gesaan adalah untuk mengesan bilangan singa dalam imej, ia akan melukis kotak sempadan yang sesuai dengan kebarangkalian pengesanan. LLM (ChatGPT) kemudian mengambil format ini dan menjadikannya dalam bahasa mesra manusia.
HuggingGPT dibina pada seni bina GPT-3.5 Hugging Face yang terkini, iaitu model rangkaian saraf dalam yang boleh menjana teks bahasa semula jadi. Berikut ialah langkah bagaimana untuk menyediakannya pada mesin tempatan anda:
Konfigurasi lalai memerlukan Ubuntu 16.04 LTS, sekurang-kurangnya 24GB VRAM, sekurang-kurangnya 12GB (minimum), 16GB (standard) atau 80GB (penuh) RAM, dan sekurang-kurangnya 284GB ruang cakera. Selain itu, 42GB ruang diperlukan untuk damo-vilab/text-to-video-ms-1.7b, 126GB untuk ControlNet, 66GB untuk stable-diffusion-v1-5 dan 50GB untuk sumber lain. Untuk konfigurasi "lite", hanya Ubuntu 16.04 LTS diperlukan.
Mula-mula, gantikan OpenAI Key dan Hugging Face Token dalam fail server/configs/config.default.yaml dengan kunci anda. Sebagai alternatif, anda boleh meletakkannya dalam pembolehubah persekitaran OPENAI_API_KEY dan HUGGINGFACE_ACCESS_TOKEN masing-masing
Jalankan arahan berikut:
# 设置环境cd serverconda create -n jarvis pythnotallow=3.8conda activate jarvisconda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidiapip install -r requirements.txt# 下载模型。确保`git-lfs`已经安装。cd modelsbash download.sh # required when `inference_mode` is `local` or `hybrid`.# 运行服务器cd ..python models_server.py --config configs/config.default.yaml # required when `inference_mode` is `local` or `hybrid`python awesome_chat.py --config configs/config.default.yaml --mode server # for text-davinci-003Kini anda boleh mengakses perkhidmatan Jarvis dengan menghantar permintaan HTTP ke titik akhir API Web. Hantar permintaan kepada:
Permintaan ini hendaklah dalam format JSON dan harus mengandungi senarai maklumat yang dimasukkan bagi pihak pengguna.
cd webnpm installnpm run dev# 可选:安装 ffmpeg# 这个命令需要在没有错误的情况下执行。LD_LIBRARY_PATH=/usr/local/lib /usr/local/bin/ffmpeg -i input.mp4 -vcodec libx264 output.mp4Menyediakan Jarvis menggunakan CLI adalah sangat mudah. Jalankan sahaja arahan yang dinyatakan di bawah:
cd serverpython awesome_chat.py --config configs/config.default.yaml --mode cliDemo gradio juga dihoskan pada Ruang Wajah Memeluk. Anda boleh mencuba selepas memasukkan OPENAI_API_KEY dan HUGGINGFACE_ACCESS_TOKEN.
Untuk menjalankannya secara setempat:
python models_server.py --config configs/config.gradio.yamlpython run_gradio_demo.py --config configs/config.gradio.yamldocker run -it -p 7860:7860 --platform=linux/amd64 registry.hf.space/microsoft-hugginggpt:latest python app.pyNota: Jika anda mempunyai sebarang soalan, sila rujuk Github Repo rasmi (https: //github.com/microsoft/JARVIS).
HuggingGPT juga mempunyai batasan tertentu yang perlu ditekankan di sini. Sebagai contoh, kecekapan sistem adalah halangan utama, dan HuggingGPT memerlukan berbilang interaksi dengan LLM pada semua peringkat yang dinyatakan sebelum ini. Interaksi ini boleh mengakibatkan pengalaman pengguna yang terdegradasi dan peningkatan kependaman. Begitu juga, panjang konteks maksimum dihadkan oleh bilangan token yang dibenarkan. Isu lain ialah kebolehpercayaan sistem, kerana LLM mungkin salah tafsir gesaan dan menghasilkan urutan tugas yang salah, yang seterusnya menjejaskan keseluruhan proses. Walau bagaimanapun, ia mempunyai potensi besar untuk menyelesaikan tugas AI yang kompleks dan merupakan kemajuan yang baik untuk AGI. Mari kita nantikan hala tuju penyelidikan ini akan membawa masa depan AI!
Atas ialah kandungan terperinci HuggingGPT: Alat ajaib untuk tugas AI. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah alamat e-mel dan bagaimana untuk mengisinya?
Apakah alamat e-mel dan bagaimana untuk mengisinya? Penggunaan typedef dalam bahasa c
Penggunaan typedef dalam bahasa c js mendapat masa semasa
js mendapat masa semasa lebar mengimbangi
lebar mengimbangi Berapakah nilai satu Bitcoin dalam RMB?
Berapakah nilai satu Bitcoin dalam RMB? Kaedah pelaksanaan fungsi main balik suara Android
Kaedah pelaksanaan fungsi main balik suara Android Perbezaan antara telefon gantian rasmi dan telefon baharu
Perbezaan antara telefon gantian rasmi dan telefon baharu Bagaimana untuk menyelesaikan tiada laluan ke hos
Bagaimana untuk menyelesaikan tiada laluan ke hos




















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



