


Pengarang: Ya Jie Yingliang, Chen Long dan lain-lain
Memandangkan perniagaan penghantaran makanan Meituan terus berkembang, penghantaran makanan Pasukan enjin pengiklanan telah menjalankan penerokaan dan amalan kejuruteraan dalam pelbagai bidang dan telah mencapai beberapa keputusan. Kami akan berkongsinya secara bersiri, dan kandungan terutamanya termasuk: ① Amalan platformisasi perniagaan ② Amalan kejuruteraan model pembelajaran mendalam berskala besar ③ Penerokaan dan amalan pengkomputeran talian dekat; -pembinaan indeks skala dan perkhidmatan mendapatkan semula dalam talian ⑤ Amalan platform kejuruteraan mekanisme. Tidak lama dahulu, kami telah menerbitkan amalan platformisasi perniagaan (Untuk butiran, sila rujuk "Penerokaan dan Amalan Platformisasi Pengiklanan Takeout Meituan》Satu artikel). Artikel ini adalah yang kedua dalam satu siri artikel Kami akan menumpukan pada cabaran yang dibawa oleh model mendalam berskala besar pada peringkat pautan penuh, bermula dari dua aspek: kependaman dalam talian dan kecekapan luar talian, dan menghuraikan kejuruteraan pengiklanan secara besar. -model dalam skala, saya harap ia boleh membawa sedikit bantuan atau inspirasi kepada semua orang.
Menjalankan perlombongan data dan minat dalam senario perniagaan Internet teras seperti carian, pengesyoran dan pengiklanan (selepas ini dirujuk sebagai promosi carian) Pemodelan dan menyediakan perkhidmatan berkualiti tinggi kepada pengguna telah menjadi elemen utama dalam meningkatkan pengalaman pengguna. Dalam tahun-tahun kebelakangan ini, untuk perniagaan carian dan promosi, model pembelajaran mendalam telah dilaksanakan secara meluas dalam industri dengan bantuan dividen data dan dividen teknologi perkakasan Pada masa yang sama, dalam senario CTR, industri telah beralih secara beransur-ansur daripada DNN kecil model kepada model Embedding yang besar dengan bertrilion parameter atau model super besar. Barisan perniagaan pengiklanan bawa pulang terutamanya telah melalui proses evolusi "model cetek LR (model pokok)" -> "model pembelajaran mendalam" -> "model pembelajaran mendalam berskala besar". Keseluruhan aliran evolusi secara beransur-ansur beralih daripada model ringkas berdasarkan ciri buatan kepada model pembelajaran mendalam yang kompleks dengan data sebagai teras. Penggunaan model besar telah meningkatkan keupayaan ekspresif model, lebih tepat memadankan bahagian penawaran dan permintaan, dan memberikan lebih banyak kemungkinan untuk pembangunan perniagaan seterusnya. Tetapi apabila skala model dan data terus meningkat, kami mendapati kecekapan mempunyai hubungan berikut dengan mereka:  Seperti yang ditunjukkan dalam rajah di atas, apabila skala data dan model meningkat, yang sepadan "Tempoh" akan menjadi lebih lama dan lebih lama. "Tempoh" ini sepadan dengan tahap luar talian, yang ditunjukkan dalam kecekapan sepadan dengan tahap dalam talian, yang ditunjukkan dalam Kependaman. Dan kerja kami dijalankan mengikut pengoptimuman "tempoh" ini.
Seperti yang ditunjukkan dalam rajah di atas, apabila skala data dan model meningkat, yang sepadan "Tempoh" akan menjadi lebih lama dan lebih lama. "Tempoh" ini sepadan dengan tahap luar talian, yang ditunjukkan dalam kecekapan sepadan dengan tahap dalam talian, yang ditunjukkan dalam Kependaman. Dan kerja kami dijalankan mengikut pengoptimuman "tempoh" ini.
Berbanding dengan model kecil biasa, masalah teras model besar ialah: kerana jumlah data dan skala model meningkat berpuluh-puluh kali Walaupun seratus kali, storan, komunikasi, pengkomputeran, dll. pada pautan keseluruhan akan menghadapi cabaran baharu, yang akan menjejaskan kecekapan lelaran luar talian algoritma. Bagaimana untuk menerobos beberapa siri masalah seperti kekangan kelewatan dalam talian? Mari analisa keseluruhan pautan dahulu, seperti yang ditunjukkan di bawah:
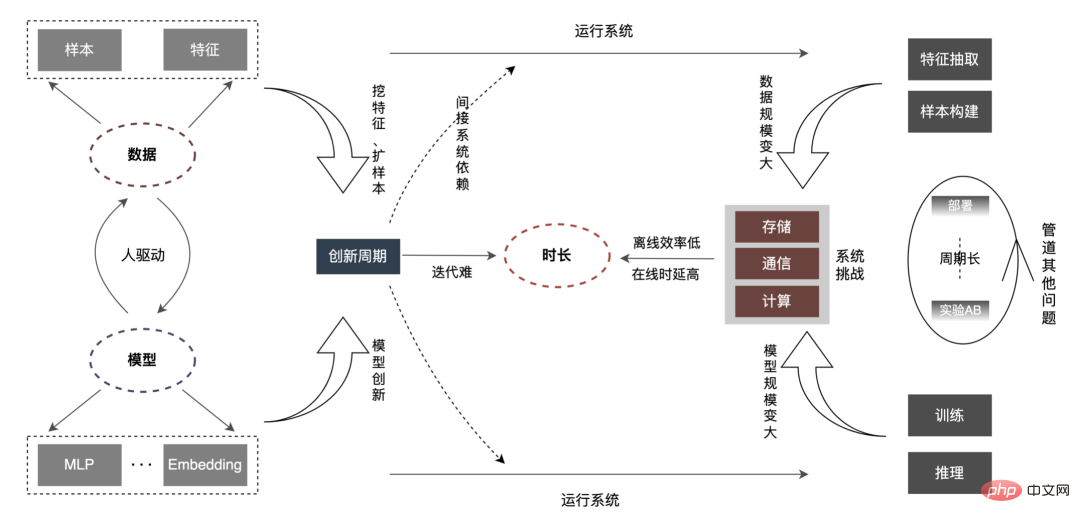
"Tempoh" menjadi lebih lama, yang ditunjukkan terutamanya dalam aspek berikut:
Artikel ini memfokuskan pada kependaman dalam talian (inferens model, perkhidmatan ciri ), kecekapan luar talian ( Ia akan dijalankan dari dua aspek: pembinaan sampel dan penyediaan data ), dan secara beransur-ansur menerangkan amalan kejuruteraan pengiklanan pada model mendalam berskala besar. Bagaimana untuk mengoptimumkan "tempoh" dan isu lain yang berkaitan, kami akan kongsikan dalam bab-bab seterusnya, jadi nantikan.
Pada peringkat inferens model, pengiklanan bawa pulang telah melalui tiga versi, dari era 1.0, diwakili oleh model DNN yang menyokong skala khusus, hingga 2.0 Pada era, kecekapan tinggi dan kod rendah menyokong lelaran berbilang perkhidmatan, dan dalam era 3.0 hari ini, ia secara beransur-ansur menghadapi keperluan pembelajaran mendalam kuasa pengkomputeran DNN dan storan berskala besar. Aliran evolusi utama ditunjukkan dalam rajah di bawah: 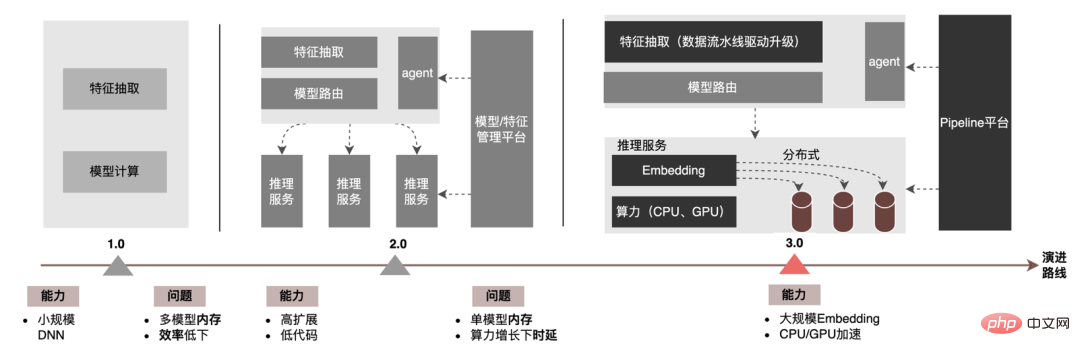
Untuk senario inferens model besar, dua masalah teras yang diselesaikan oleh seni bina 3.0 ialah: "masalah penyimpanan" dan "prestasi masalah". Sudah tentu, cara mengulang untuk N ratusan model G+, cara memastikan kestabilan dalam talian apabila beban pengiraan meningkat berpuluh-puluh kali ganda, cara mengukuhkan Talian Paip, dsb. juga merupakan cabaran yang dihadapi oleh projek. Di bawah ini kita akan menumpukan pada cara seni bina Model Inference 3.0 menyelesaikan masalah penyimpanan model yang besar melalui "pengedaran" dan cara menyelesaikan masalah prestasi dan pemprosesan melalui pecutan CPU/GPU.
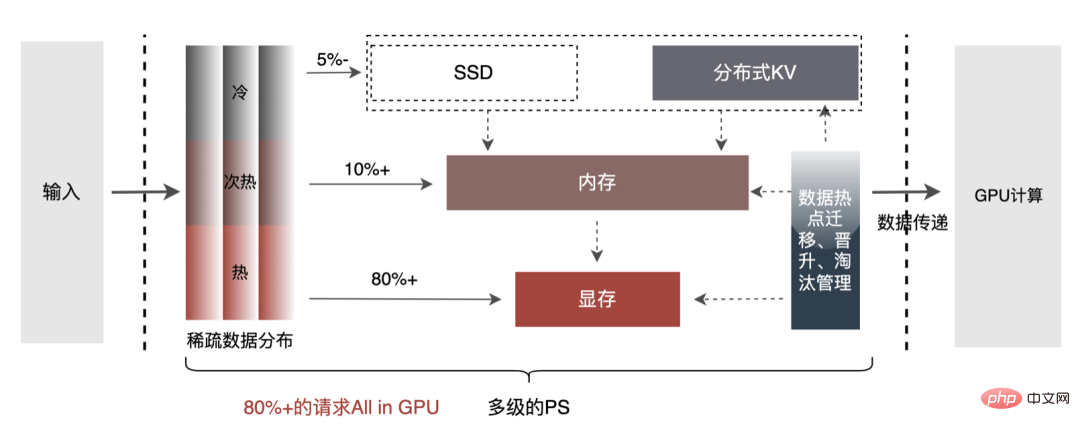
Parameter model besar terbahagi terutamanya kepada dua bahagian: Parameter jarang dan Parameter Padat.
Oleh itu, kunci untuk menyelesaikan masalah pertumbuhan skala parameter model besar ialah mengubah parameter Jarang daripada storan mesin tunggal kepada storan teragih Kaedah transformasi merangkumi dua bahagian: ① Penukaran struktur rangkaian model ;② Eksport parameter Jarang.
Kaedah industri untuk mendapatkan parameter teragih secara kasar dibahagikan kepada dua jenis: perkhidmatan luaran mendapatkan parameter terlebih dahulu dan menyerahkannya kepada perkhidmatan anggaran ; Perkhidmatan anggaran secara dalaman memperoleh parameter daripada storan teragih dengan mengubah pengendali TF (TensorFlow). Untuk mengurangkan kos pengubahsuaian seni bina dan mengurangkan pencerobohan ke dalam struktur model sedia ada, kami memilih untuk mendapatkan parameter teragih dengan mengubah suai pengendali TF.
Dalam keadaan biasa, model TF akan menggunakan operator asli untuk membaca parameter Jarang Pengendali teras ialah operator GatherV2 Input pengendali terutamanya mempunyai dua bahagian: ① ID Pertanyaan Diperlukan senarai; ② Membenamkan jadual yang menyimpan parameter Jarang. Fungsi pengendali
ialah membaca data Benam yang sepadan dengan indeks senarai ID daripada jadual Benam dan mengembalikannya pada asasnya proses pertanyaan Hash. Antaranya, parameter Sparse yang disimpan dalam jadual Embedding semuanya disimpan dalam memori mesin tunggal dalam model mesin tunggal.
Mengubah pengendali TF pada asasnya ialah transformasi struktur rangkaian model Inti utama transformasi merangkumi dua bahagian: ① Pembinaan semula graf rangkaian ② Operator teragih tersuai.
1. Pembinaan semula rajah rangkaian: Ubah struktur rangkaian model, gantikan pengendali TF asli dengan pengendali teragih tersuai dan lakukan jadual Benam asli pada masa yang sama masa menjadi kukuh.
 2 Pengendali teragih tersuai: Ubah pertanyaan berdasarkan senarai ID The Embedding. proses diubah suai daripada menanyakan jadual Embedding tempatan kepada menanyakan KV yang diedarkan.
2 Pengendali teragih tersuai: Ubah pertanyaan berdasarkan senarai ID The Embedding. proses diubah suai daripada menanyakan jadual Embedding tempatan kepada menanyakan KV yang diedarkan.
Proses keseluruhan ditunjukkan dalam rajah di bawah Kami memastikan keselamatan ratusan gigabait melalui penukaran struktur model teragih luar talian, jaminan ketekalan data barisan dan tempat liputan dalam talian. caching data. Keperluan lelaran biasa model.
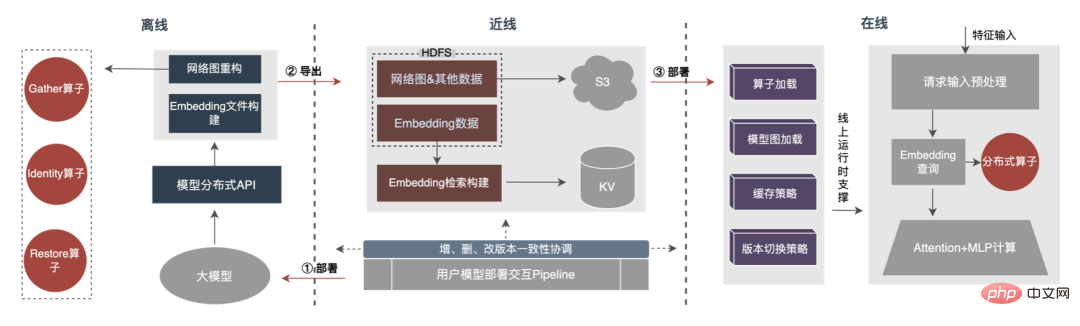
Dapat dilihat bahawa storan yang digunakan oleh storan teragih adalah keupayaan KV luaran, yang akan digantikan dengan yang lebih cekap, fleksibel dan mudah- untuk mengurus Perkhidmatan Pembenaman pada masa hadapan.
Selain kaedah pengoptimuman model itu sendiri, terdapat dua kaedah pecutan CPU biasa utama: ① Pengoptimuman set arahan, seperti menggunakan AVX2 , Set Arahan AVX512 ② Gunakan pustaka pecutan (TVM, OpenVINO).
Di bawah, kami akan menumpukan pada beberapa pengalaman praktikal kami dalam menggunakan OpenVINO untuk pecutan CPU. OpenVINO ialah satu set rangka kerja pengoptimuman pecutan pengkomputeran berasaskan pembelajaran mendalam yang dilancarkan oleh Intel, yang menyokong pengoptimuman mampatan, pengkomputeran dipercepatkan dan fungsi lain model pembelajaran mesin. Prinsip pecutan OpenVINO ringkasnya diringkaskan kepada dua bahagian: gabungan operator linear dan penentukuran ketepatan data.
Pecutan CPU biasanya mempercepatkan inferens untuk baris gilir calon kelompok tetap, tetapi dalam senario promosi carian, baris gilir calon selalunya dinamik. Ini bermakna sebelum inferens model, operasi pemadanan Kelompok perlu ditambah, iaitu baris gilir calon Batch dinamik yang diminta dipetakan kepada model Kelompok yang paling hampir dengannya, tetapi ini memerlukan membina N model padanan, menghasilkan N kali penggunaan memori. . Jumlah model semasa telah mencapai ratusan gigabait, dan ingatan sangat ketat. Oleh itu, memilih struktur rangkaian yang munasabah untuk pecutan adalah isu utama yang perlu dipertimbangkan. Gambar di bawah menunjukkan seni bina pengendalian keseluruhan: 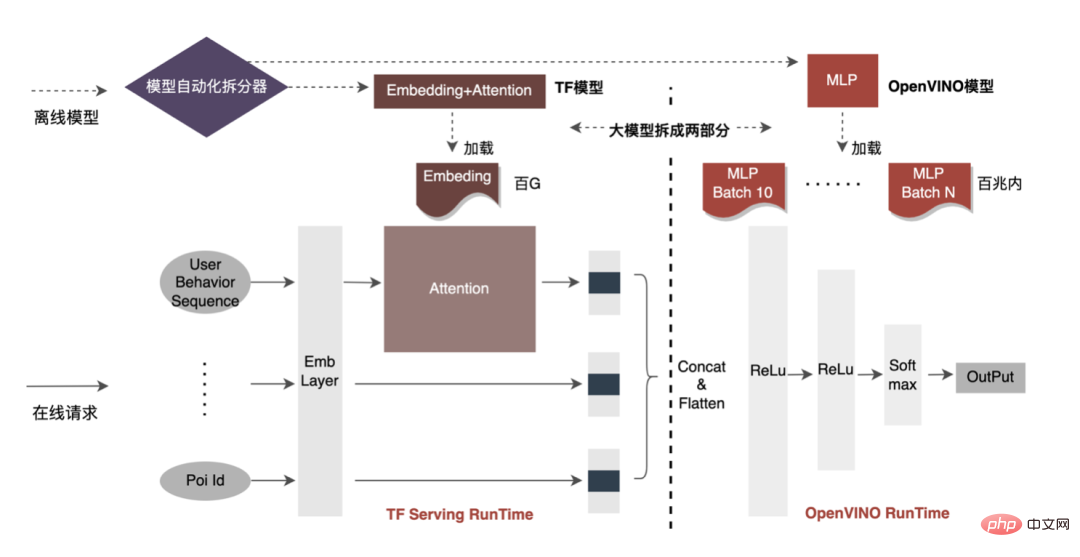
Pada masa ini, penyelesaian pecutan CPU berdasarkan OpenVINO telah mencapai hasil yang baik dalam persekitaran pengeluaran: apabila CPU adalah sama dengan garis dasar, daya pemprosesan perkhidmatan meningkat sebanyak 40 %, dan kelewatan purata dikurangkan sebanyak 15%. Jika anda ingin melakukan sedikit pecutan pada tahap CPU, OpenVINO ialah pilihan yang baik.
Di satu pihak, dengan perkembangan perniagaan, bentuk perniagaan menjadi semakin banyak, trafik semakin tinggi dan lebih tinggi, dan model semakin luas dan lebih dalam Penggunaan kuasa meningkat secara mendadak, sebaliknya, adegan pengiklanan terutamanya menggunakan model DNN, yang melibatkan sejumlah besar operasi titik apungan rangkaian saraf. Sebagai akses memori dan perkhidmatan dalam talian intensif pengkomputeran, ia mesti memenuhi keperluan kependaman rendah dan daya pemprosesan tinggi sambil memastikan ketersediaan, yang juga merupakan cabaran kepada kuasa pengkomputeran mesin tunggal. Jika konflik antara keperluan sumber pengkomputeran dan ruang ini tidak diselesaikan dengan baik, ia akan sangat mengehadkan pembangunan perniagaan: sebelum model diperluas dan diperdalam, perkhidmatan inferens CPU tulen boleh memberikan daya pemprosesan yang besar, tetapi selepas model dilebarkan dan diperdalam, pengiraan menjadi kompleks. Untuk memastikan ketersediaan yang tinggi, sejumlah besar sumber mesin perlu digunakan, yang menjadikan model besar tidak dapat digunakan dalam talian secara besar-besaran. Pada masa ini, penyelesaian biasa dalam industri adalah menggunakan GPU untuk menyelesaikan masalah ini sendiri lebih sesuai untuk tugasan intensif pengkomputeran. Menggunakan GPU memerlukan penyelesaian cabaran berikut: cara mencapai daya pemprosesan setinggi mungkin sambil memastikan ketersediaan dan kependaman rendah, sambil mempertimbangkan kemudahan penggunaan dan serba boleh. Untuk tujuan ini, kami juga telah melakukan banyak kerja praktikal pada GPU, seperti TensorFlow-GPU, TensorFlow-TensorRT, TensorRT, dll. Untuk mengambil kira fleksibiliti TF dan kesan pecutan TensorRT, kami menggunakan reka bentuk seni bina dua peringkat bebas TensorFlow+TensorRT.
Fasa inferens pembelajaran mendalam mempunyai keperluan yang tinggi pada kuasa pengkomputeran dan kependaman Jika rangkaian saraf terlatih secara langsung Apabila digunakan hingga akhir inferens, masalah seperti kuasa pengkomputeran yang tidak mencukupi atau masa inferens yang panjang mungkin berlaku. Oleh itu, kita perlu melakukan pengoptimuman tertentu pada rangkaian saraf terlatih. Idea umum untuk mengoptimumkan model rangkaian saraf dalam industri boleh dioptimumkan dari aspek yang berbeza seperti pemampatan model, penggabungan lapisan rangkaian yang berbeza, sparsifikasi, dan penggunaan jenis data berketepatan rendah, malah memerlukan pengoptimuman yang disasarkan ciri perkakasan. Untuk tujuan ini, kami terutamanya mengoptimumkan sekitar dua matlamat berikut:
Yang berikut akan menumpukan pada dua matlamat di atas dan memperkenalkan secara terperinci kerja kami tentang pengoptimuman model, pengoptimuman gabungan dan pengoptimuman enjin Sesetengah kerja telah selesai.
1. Pengiraan dan penyahduplikasi penghantaran: Semasa inferens, Kumpulan yang sama hanya mengandungi satu maklumat pengguna. . Oleh itu, maklumat pengguna boleh dikurangkan daripada Saiz Kelompok kepada 1 sebelum inferens, dan kemudian dikembangkan apabila inferens benar-benar diperlukan untuk mengurangkan kos penghantaran salinan data dan pengiraan berulang. Seperti yang ditunjukkan dalam rajah di bawah, anda boleh menanyakan maklumat ciri kelas pengguna sekali sahaja sebelum inferens, dan memotongnya dalam subrangkaian berkaitan pengguna sahaja, dan kemudian mengembangkannya apabila anda perlu mengira perkaitan.
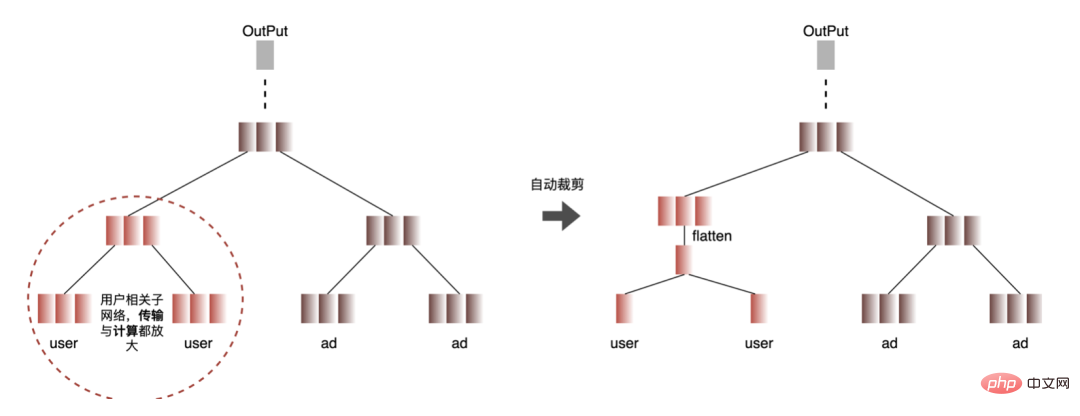
2. Pengoptimuman ketepatan data : disebabkan oleh model Semasa latihan, perambatan belakang diperlukan untuk mengemas kini kecerunan, yang memerlukan ketepatan data yang tinggi manakala semasa inferens model, hanya inferens ke hadapan dilakukan tanpa mengemas kini kecerunan Oleh itu, di bawah premis memastikan kesan, FP16 atau ketepatan campuran digunakan untuk pengoptimuman untuk menjimatkan ruang memori, mengurangkan overhed penghantaran dan meningkatkan prestasi inferens dan daya pemprosesan.
3. Tekan ke bawah Pengiraan: Struktur model CTR terutamanya terdiri daripada tiga lapisan: Lapisan Benam, Perhatian dan MLP data. Perhatian sebahagiannya logik dan sebahagiannya pengiraan Untuk mengeksploitasi sepenuhnya potensi GPU, kebanyakan logik pengiraan Perhatian dan MLP dalam struktur model CTR dialihkan daripada CPU ke GPU untuk pengiraan, dan keseluruhan pemprosesan. bertambah baik.
Semasa inferens model dalam talian, operasi pengiraan setiap lapisan diselesaikan oleh GPU Malah, CPU melengkapkan pengiraan dengan memulakan kernel CUDA yang berbeza Pengiraan tensor adalah sangat pantas, tetapi banyak masa sering terbuang untuk memulakan kernel CUDA dan membaca serta menulis tensor input/output setiap lapisan, yang menyebabkan kesesakan dalam lebar jalur memori dan pembaziran sumber GPU. Di sini kami terutamanya akan memperkenalkan dua bahagian TensorRT: pengoptimuman automatik dan pengoptimuman manual. 1. Pengoptimuman automatik: TensorRT ialah pengoptimum inferens pembelajaran mendalam berprestasi tinggi yang boleh menyediakan penggunaan inferens berkependaman rendah dan berkemampuan tinggi untuk aplikasi pembelajaran mendalam. TensorRT boleh digunakan untuk mempercepatkan inferens pada model berskala sangat besar, platform terbenam atau platform pemanduan autonomi. TensorRT kini boleh menyokong hampir semua rangka kerja pembelajaran mendalam seperti TensorFlow, Caffe, MXNet dan PyTorch Menggabungkan TensorRT dengan GPU NVIDIA boleh mendayakan penggunaan dan inferens yang pantas dan cekap dalam hampir semua rangka kerja. Dan sesetengah pengoptimuman tidak memerlukan terlalu banyak penyertaan pengguna, seperti beberapa Pelaburan Lapisan, Penalaan Auto Kernel, dsb.
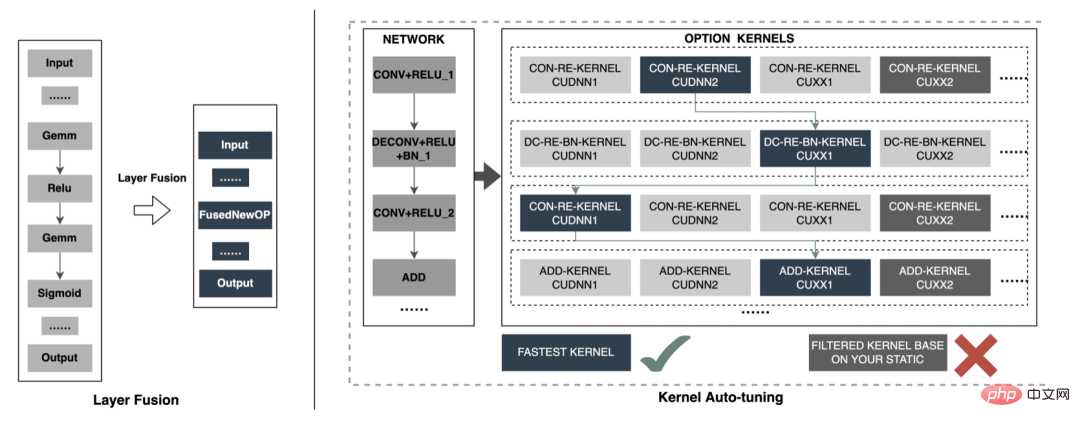
2 Pengoptimuman manual: Seperti yang kita sedia maklum, GPU sesuai untuk pengendali intensif pengiraan. . Jenis operator lain (operator pengiraan ringan, operator operasi logik, dll.) tidak begitu mesra. Apabila menggunakan pengiraan GPU, setiap operasi biasanya melalui beberapa proses: CPU memperuntukkan memori video pada GPU -> CPU menghantar data ke GPU -> CPU memulakan kernel CUDA -> CPU mengambil data -> CPU mengeluarkan memori video GPU. Untuk mengurangkan overhed seperti penjadualan, pelancaran kernel dan akses memori, integrasi rangkaian diperlukan. Oleh kerana struktur model besar CTR yang fleksibel dan boleh diubah, sukar untuk menyatukan kaedah gabungan rangkaian, dan hanya masalah khusus yang boleh dianalisis secara terperinci. Contohnya, dalam arah menegak, Cast, Unsqueeze dan Less dicantumkan, dan TensorRT internal Conv, BN dan Relu dicantumkan dalam arah mendatar, operator input dari dimensi yang sama dicantumkan. Untuk tujuan ini, kami menggunakan alat analisis prestasi berkaitan NVIDIA (NVIDIA Nsight Systems, NVIDIA Nsight Compute, dll.) untuk menganalisis isu khusus berdasarkan senario perniagaan dalam talian sebenar. Integrasikan alat analisis prestasi ini ke dalam persekitaran inferens dalam talian untuk mendapatkan fail Profing GPU semasa proses inferens. Melalui fail Profing, kami dapat melihat dengan jelas proses inferens Kami mendapati bahawa fenomena terikat pelancaran kernel bagi sesetengah operator dalam keseluruhan inferens adalah serius, dan jurang antara beberapa operator adalah besar, dan terdapat ruang untuk pengoptimuman, seperti yang ditunjukkan dalam angka berikut:
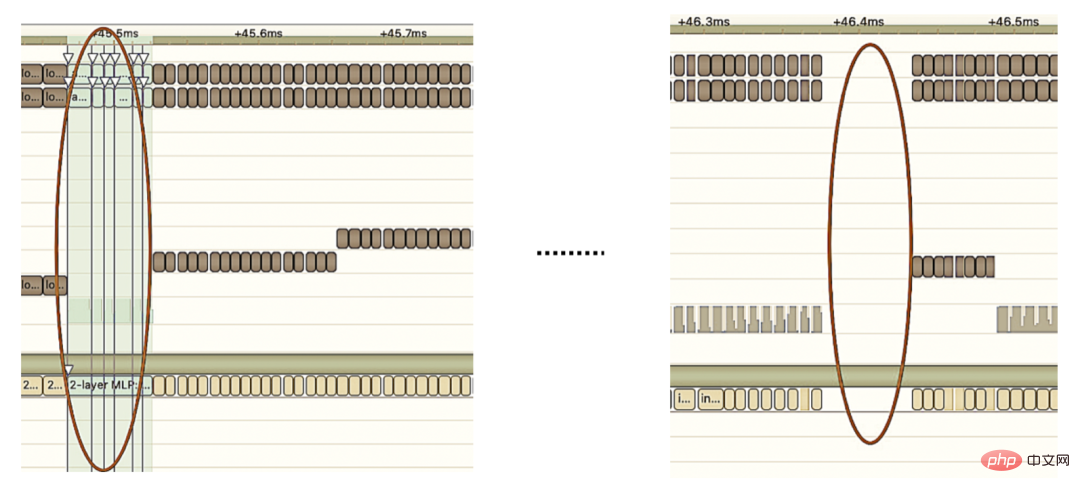
Untuk tujuan ini, analisa keseluruhan Rangkaian berdasarkan alat analisis prestasi dan model yang ditukar, ketahui bahagian yang TensorRT telah dioptimumkan, dan kemudian lakukan penyepaduan rangkaian pada substruktur lain dalam Rangkaian yang boleh dioptimumkan, sambil memastikan bahawa substruktur ini menduduki bahagian tertentu dalam keseluruhan Rangkaian, memastikan ketumpatan pengkomputeran boleh meningkat ke tahap tertentu selepas gabungan. Bagi jenis kaedah penyepaduan rangkaian yang akan digunakan, ia boleh digunakan secara fleksibel mengikut senario tertentu Rajah berikut ialah perbandingan rajah substruktur sebelum dan selepas penyepaduan kami:
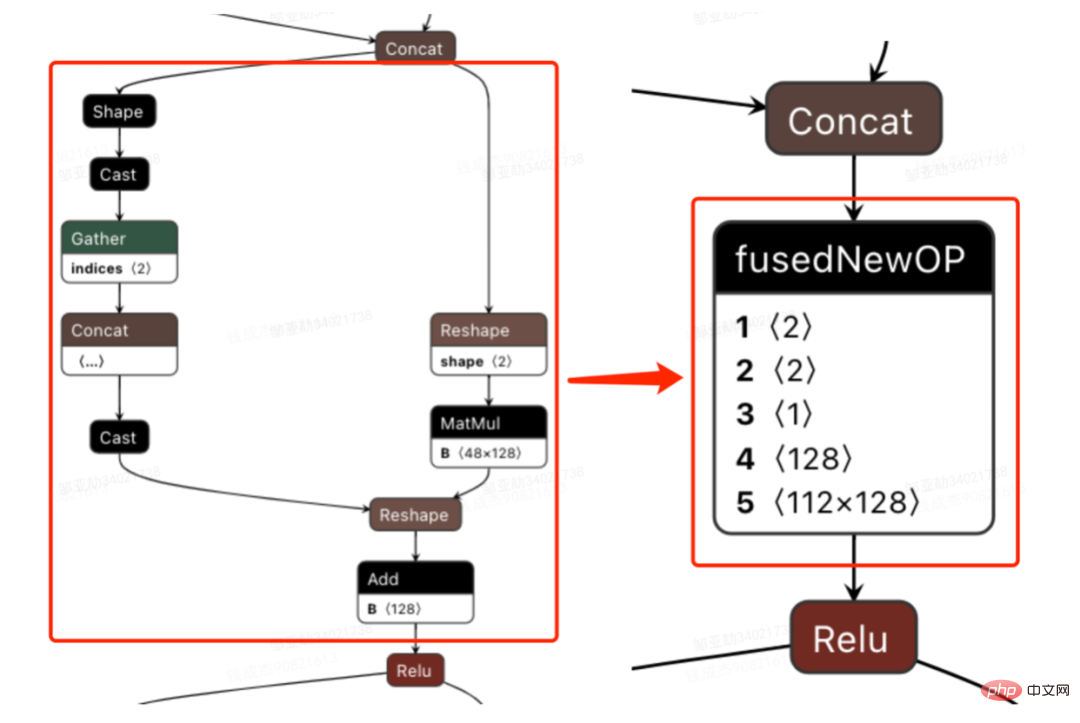
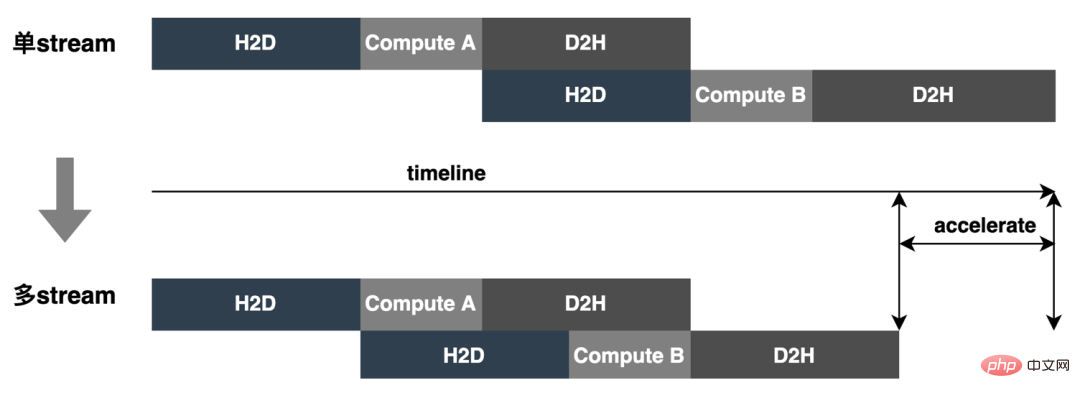
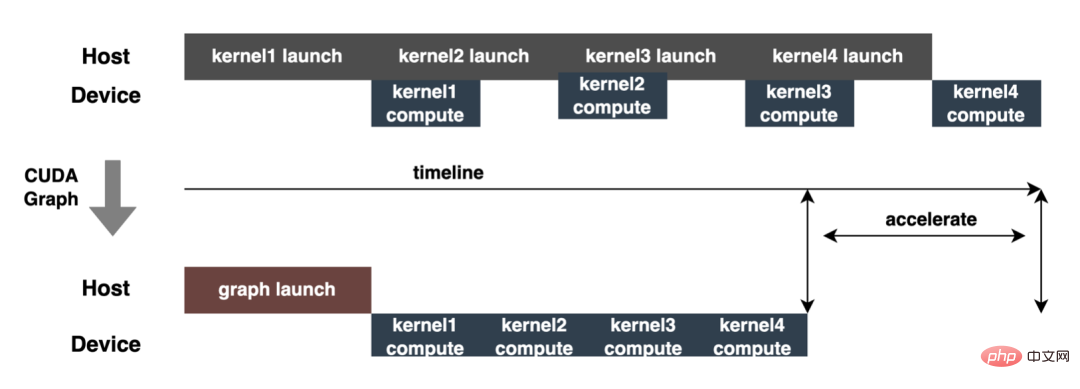
Keseluruhan proses model daripada latihan luar talian untuk pemuatan akhir dalam talian adalah menyusahkan, dan model ini tidak boleh digunakan secara universal pada kad GPU yang berbeza, versi TensorRT dan CUDA yang berbeza, yang membawa lebih banyak kemungkinan ralat dalam penukaran model. Oleh itu, untuk meningkatkan kecekapan keseluruhan lelaran model, kami telah membina keupayaan yang berkaitan dalam Pipeline, seperti yang ditunjukkan dalam rajah di bawah:
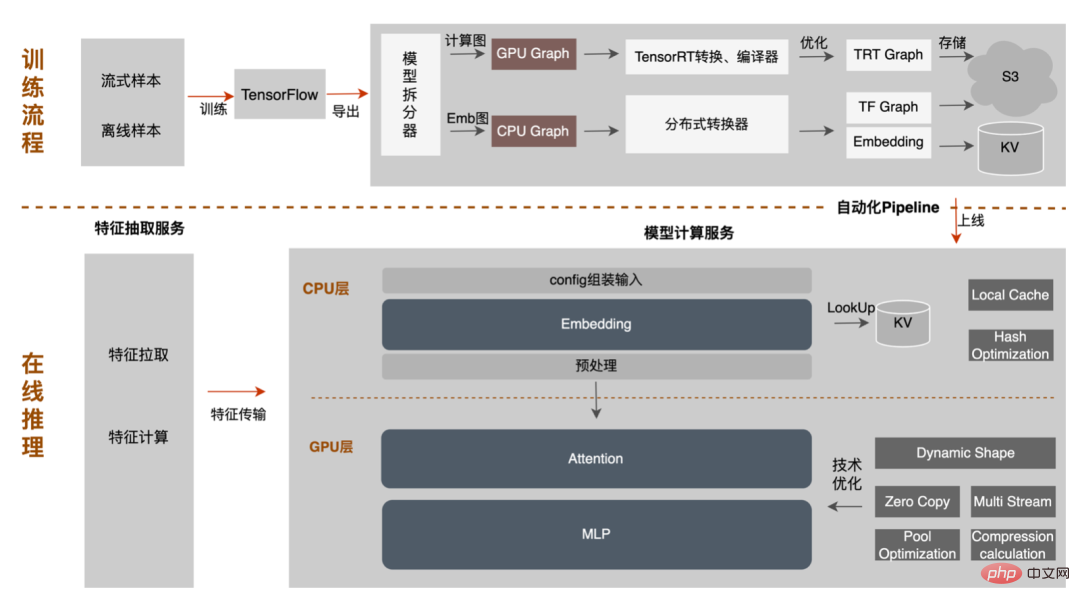
Pembinaan saluran paip termasuk dua bahagian: proses pemisahan dan penukaran model luar talian dan proses penggunaan model dalam talian:
Pipeline telah meningkatkan kecekapan lelaran model melalui pembinaan keupayaan konfigurasi dan satu klik, membantu pelajar algoritma dan kejuruteraan untuk lebih memfokuskan pada pekerjaan mereka. Angka berikut menunjukkan faedah keseluruhan yang dicapai dalam amalan GPU berbanding dengan inferens CPU tulen:
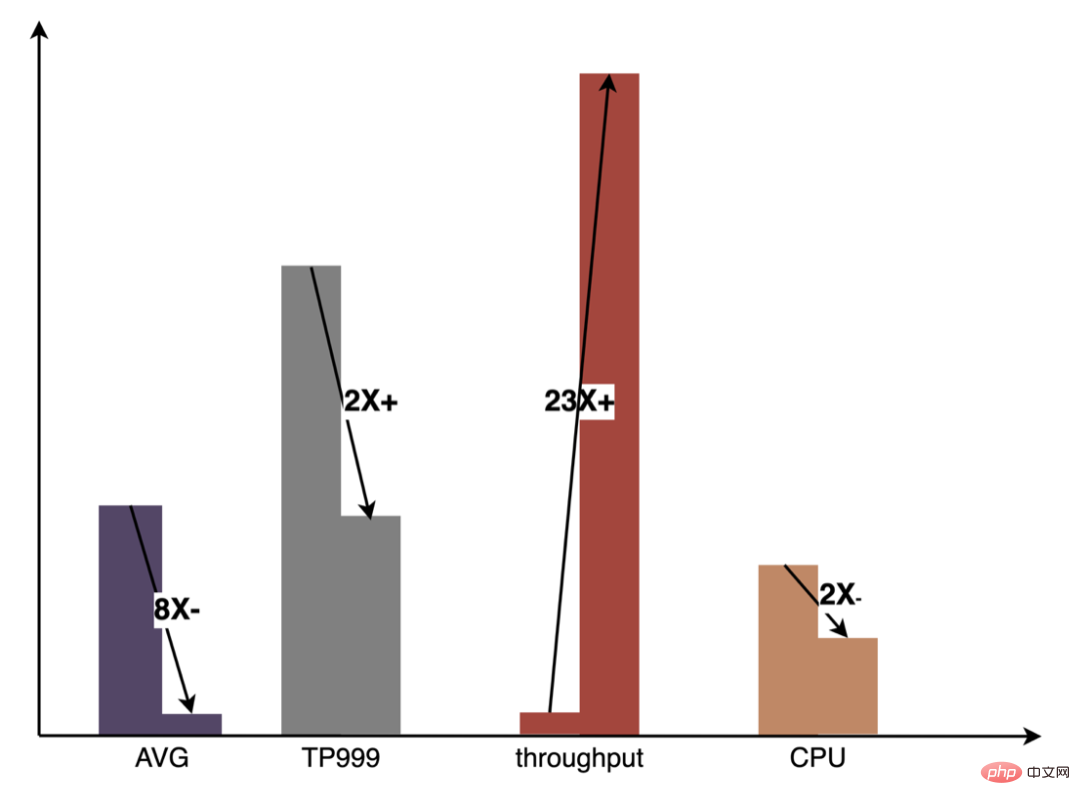
Ciri Pengekstrakan ialah peringkat pra pengiraan model Sama ada model LR tradisional atau model pembelajaran mendalam yang semakin popular, input perlu diperoleh melalui pengekstrakan ciri. Dalam blog sebelum ini Pembinaan dan Amalan Meituan Takeout Feature Platform, kami menerangkan bahawa kami berdasarkan ciri model MFDL perihalan kendiri, dan mengira ciri Proses ini dikonfigurasikan untuk memastikan ketekalan sampel semasa anggaran dalam talian dan latihan luar talian. Dengan lelaran perniagaan yang pesat, bilangan ciri model terus meningkat terutamanya model yang besar memperkenalkan sejumlah besar ciri diskret, mengakibatkan penggandaan jumlah pengiraan. Untuk tujuan ini, kami telah membuat beberapa pengoptimuman pada lapisan pengekstrakan ciri dan mencapai keuntungan yang ketara dalam pemprosesan dan penggunaan masa.
DSL ialah penerangan bagi logik pemprosesan ciri. Dalam pelaksanaan pengiraan ciri awal, DSL yang dikonfigurasikan untuk setiap model telah ditafsir dan dilaksanakan. Kelebihan mentafsir pelaksanaan ialah ia mudah untuk dilaksanakan, dan pelaksanaan yang baik boleh dicapai melalui reka bentuk yang baik, seperti corak lelaran yang biasa digunakan ialah prestasi pelaksanaan adalah rendah, dan banyak lompatan dan jenis cawangan tidak boleh dielakkan di peringkat pelaksanaan demi kepelbagaian penukaran dll. Malah, untuk versi tetap konfigurasi model, semua peraturan penukaran ciri modelnya adalah tetap dan tidak akan berubah dengan permintaan. Dalam kes yang melampau, berdasarkan maklumat yang diketahui ini, setiap ciri model boleh dikodkan keras untuk mencapai prestasi muktamad. Jelas sekali, konfigurasi ciri model sentiasa berubah, dan adalah mustahil untuk mengodkan setiap model secara manual. Oleh itu idea CodeGen, yang secara automatik menjana satu set kod proprietari untuk setiap konfigurasi semasa penyusunan. CodeGen bukanlah teknologi atau rangka kerja tertentu, tetapi idea yang melengkapkan proses penukaran daripada bahasa penerangan abstrak kepada bahasa pelaksanaan tertentu. Malah, dalam industri, adalah amalan biasa untuk menggunakan CodeGen untuk mempercepatkan pengiraan dalam senario intensif pengkomputeran. Contohnya, Apache Spark menggunakan CodeGen untuk mengoptimumkan prestasi pelaksanaan SparkSql daripada ExpressionCodeGen dalam 1.x untuk mempercepatkan operasi ekspresi kepada WholeStageCodeGen yang diperkenalkan dalam 2.x untuk pecutan peringkat penuh, peningkatan prestasi yang sangat jelas telah dicapai. Dalam bidang pembelajaran mesin, beberapa rangka kerja pecutan model TF, seperti TensorFlow XLA dan TVM, juga berdasarkan idea CodeGen Tensor nod disusun menjadi IR lapisan tengah bersatu, dan pengoptimuman penjadualan dilakukan berdasarkan IR yang digabungkan dengan. persekitaran tempatan untuk mencapai pecutan pengiraan model runtime.

Belajar daripada Spark's WholeStageCodeGen, matlamat kami adalah untuk menyusun keseluruhan pengiraan ciri DSL ke dalam kaedah boleh laku, dengan itu mengurangkan kehilangan prestasi apabila kod dijalankan. Keseluruhan proses kompilasi boleh dibahagikan kepada: bahagian hadapan (FrontEnd), pengoptimum (Optimizer) dan back-end (BackEnd). Bahagian hadapan bertanggungjawab terutamanya untuk menghuraikan DSL sasaran dan menukar kod sumber kepada AST atau IR pengoptimuman mengoptimumkan kod perantaraan yang diperoleh berdasarkan bahagian hadapan untuk menjadikan kod bahagian belakang menukar perantaraan yang dioptimumkan; kod ke dalam kod Asli untuk platform masing-masing. Pelaksanaan khusus adalah seperti berikut:
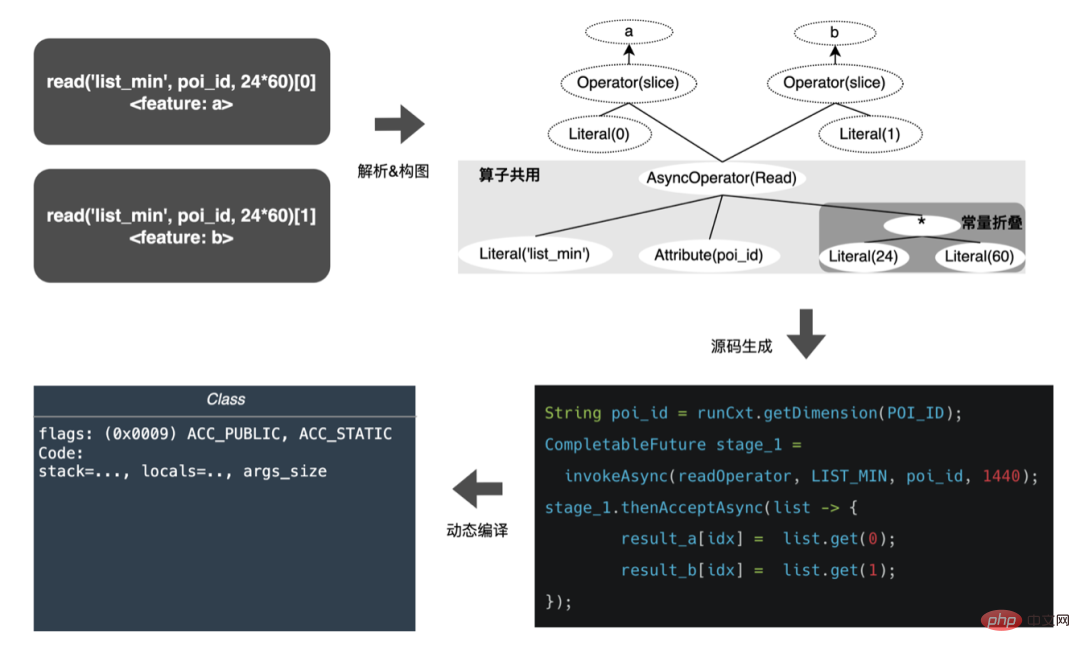
Selepas pengoptimuman, terjemahan graf DAG nod, iaitu, pelaksanaan kod hujung belakang, menentukan prestasi akhir. Salah satu kesukaran juga ialah sebab mengapa enjin ekspresi sumber terbuka sedia ada tidak boleh digunakan secara langsung: pengiraan ciri DSL bukanlah ungkapan pengiraan semata-mata. Ia boleh menerangkan proses pemerolehan dan pemprosesan ciri melalui gabungan pengendali baca dan pengendali penukaran:
Jadi dalam pelaksanaan sebenar, adalah perlu untuk mempertimbangkan penjadualan pelbagai jenis tugas, memaksimumkan penggunaan sumber mesin dan mengoptimumkan keseluruhan proses yang memakan masa. Menggabungkan penyelidikan industri dan amalan sendiri, tiga pelaksanaan berikut telah dijalankan:
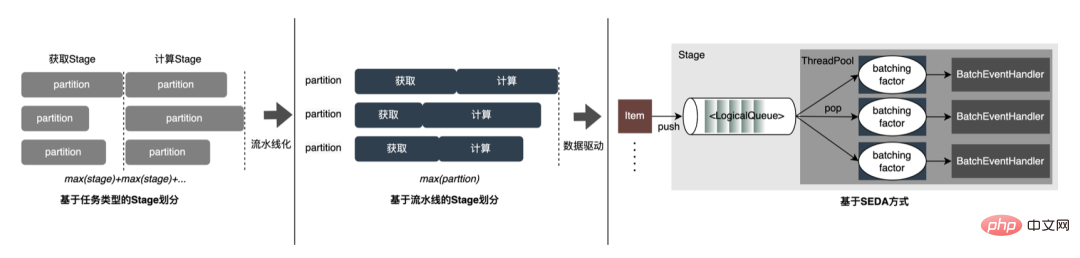
Kod yang dihasilkan secara dinamik mengurangkan kebolehbacaan kod dan meningkatkan kos penyahpepijatan Walau bagaimanapun, menggunakan CodeGen sebagai lapisan penyesuaian juga menyediakan penyelesaian yang lebih mendalam. Pengoptimuman membuka ruang. Berdasarkan CodeGen dan pelaksanaan tanpa sekatan asynchronous, faedah yang baik telah dicapai dalam talian Di satu pihak, ia mengurangkan pengiraan ciri yang memakan masa, sebaliknya, ia juga mengurangkan beban CPU dengan ketara dan meningkatkan daya pemprosesan sistem. Pada masa hadapan, kami akan terus memanfaatkan CodeGen dan melaksanakan pengoptimuman yang disasarkan dalam proses penyusunan bahagian belakang, seperti meneroka gabungan arahan perkakasan ( seperti SIMD) atau pengkomputeran heterogen ( seperti GPU) untuk pengoptimuman yang lebih mendalam.
Perkhidmatan ramalan dalam talian ialah seni bina dua lapisan secara keseluruhan Lapisan pengekstrakan ciri bertanggungjawab untuk penghalaan model dan pengiraan ciri, dan lapisan pengiraan model bertanggungjawab untuk pengiraan model. Proses sistem asal adalah untuk menyambung hasil pengiraan ciri ke dalam matriks M (Saiz Kelompok Diramalkan) × N (Lebar Sampel), dan kemudian bersiri dan menghantarnya ke pengkomputeran lapisan. Sebab untuk ini, dalam satu pihak, sebab sejarah Format input banyak model ringkas bukan DNN adalah matriks Selepas lapisan penghalaan disambungkan, lapisan pengkomputeran boleh digunakan secara langsung tanpa penukaran , format tatasusunan agak padat dan boleh Menjimatkan masa pada penghantaran rangkaian.  Walau bagaimanapun, dengan pembangunan berulang model, model DNN secara beransur-ansur menjadi arus perdana, dan keburukan penghantaran matriks juga sangat jelas:
Walau bagaimanapun, dengan pembangunan berulang model, model DNN secara beransur-ansur menjadi arus perdana, dan keburukan penghantaran matriks juga sangat jelas:
Untuk menyelesaikan masalah di atas, proses yang dioptimumkan menambah lapisan penukaran di atas lapisan penghantaran untuk menukar ciri model yang dikira ke dalam Format yang diperlukan, seperti Tensor, matriks atau format CSV untuk kegunaan luar talian, dsb.  Kebanyakan model dalam talian sebenar adalah model TF Untuk menjimatkan penggunaan penghantaran lagi, platform mereka bentuk format Tensor Sequence untuk menyimpan setiap matriks Tensor: antaranya, r_flag digunakan untuk menandakan sama ada ia. ialah ciri jenis item , panjang mewakili panjang ciri item, nilainya ialah M (Bilangan Item)×NF (Panjang ciri), data digunakan untuk menyimpan nilai ciri sebenar, untuk ciri Item, nilai Ciri M disimpan rata, dan ciri jenis permintaan diisi terus. Berdasarkan format Jujukan Tensor yang padat, struktur data lebih padat dan jumlah data yang dihantar melalui rangkaian dikurangkan. Format penghantaran yang dioptimumkan juga telah mencapai hasil yang baik dalam talian Saiz permintaan lapisan penghalaan yang memanggil lapisan pengkomputeran telah dikurangkan sebanyak 50%+, dan masa penghantaran rangkaian telah dikurangkan dengan ketara.
Kebanyakan model dalam talian sebenar adalah model TF Untuk menjimatkan penggunaan penghantaran lagi, platform mereka bentuk format Tensor Sequence untuk menyimpan setiap matriks Tensor: antaranya, r_flag digunakan untuk menandakan sama ada ia. ialah ciri jenis item , panjang mewakili panjang ciri item, nilainya ialah M (Bilangan Item)×NF (Panjang ciri), data digunakan untuk menyimpan nilai ciri sebenar, untuk ciri Item, nilai Ciri M disimpan rata, dan ciri jenis permintaan diisi terus. Berdasarkan format Jujukan Tensor yang padat, struktur data lebih padat dan jumlah data yang dihantar melalui rangkaian dikurangkan. Format penghantaran yang dioptimumkan juga telah mencapai hasil yang baik dalam talian Saiz permintaan lapisan penghalaan yang memanggil lapisan pengkomputeran telah dikurangkan sebanyak 50%+, dan masa penghantaran rangkaian telah dikurangkan dengan ketara.
Ciri diskrit dan ciri jujukan boleh disatukan menjadi ciri Jarang Dalam peringkat pemprosesan ciri, ciri asal akan dicincang dan menjadi ciri kelas ID. Dalam menghadapi ciri dengan ratusan bilion dimensi, proses penggabungan rentetan dan pencincangan tidak dapat memenuhi keperluan dari segi ruang ekspresi dan prestasi. Berdasarkan penyelidikan industri, kami mereka bentuk dan menggunakan format pengekodan ciri berdasarkan pengekodan Slot:
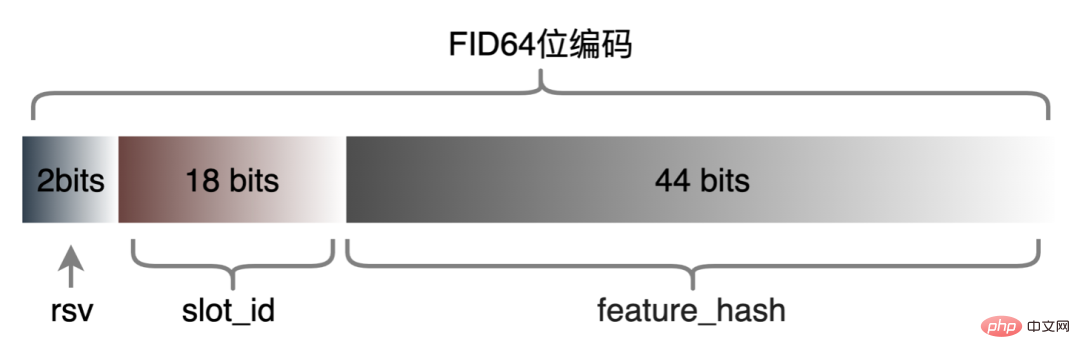
Antaranya, feature_hash ialah Hash bagi ciri asal nilai nilai selepas. Ciri integer boleh diisi secara langsung Ciri bukan integer atau ciri silang dicincang terlebih dahulu dan kemudian diisi Jika nombor melebihi 44 bit, ia akan dipotong. Selepas skim pengekodan Slot dilancarkan, ia bukan sahaja meningkatkan prestasi pengiraan ciri dalam talian, tetapi juga meningkatkan kesan model dengan ketara.
Untuk menyelesaikan masalah konsistensi dalam talian dan luar talian, industri secara amnya Data ciri yang digunakan dalam pemarkahan masa nyata pembuangan dalam talian dipanggil petikan ciri dan bukannya membina sampel melalui penyambungan label luar talian yang mudah dan pengisian semula ciri, kaedah ini akan menyebabkan ketidakkonsistenan data yang besar. Seni bina asal ditunjukkan dalam rajah di bawah:

Apabila skala ciri menjadi lebih besar dan senario lelaran menjadi lebih kompleks, penyelesaian ini menjadi semakin menonjol. Masalah terbesar ialah perkhidmatan pengekstrakan ciri dalam talian berada di bawah tekanan yang besar, dan kedua, kos mengumpul keseluruhan aliran data adalah terlalu tinggi. Penyelesaian pengumpulan sampel ini mempunyai masalah berikut:
Untuk menyelesaikan masalah di atas, terdapat dua penyelesaian biasa dalam industri: ①Flink pemprosesan strim masa nyata; ②Pemprosesan sekunder cache KV. Proses khusus ditunjukkan dalam rajah di bawah:
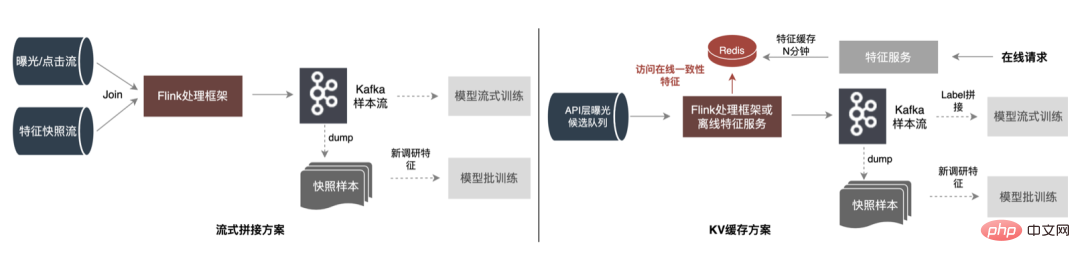
Dari perspektif mengurangkan pengiraan tidak sah, tidak semua data yang diminta akan didedahkan. Strategi ini mempunyai permintaan yang lebih kukuh untuk data terdedah, jadi pemajuan pemprosesan peringkat hari kepada pemprosesan strim boleh meningkatkan masa kesediaan data dengan ketara. Kedua, bermula dari kandungan data, ciri-ciri termasuk data berubah peringkat permintaan dan data berubah peringkat hari Pautan secara fleksibel memisahkan pemprosesan kedua-duanya, yang boleh meningkatkan penggunaan sumber dengan ketara. Angka berikut ialah pelan khusus.
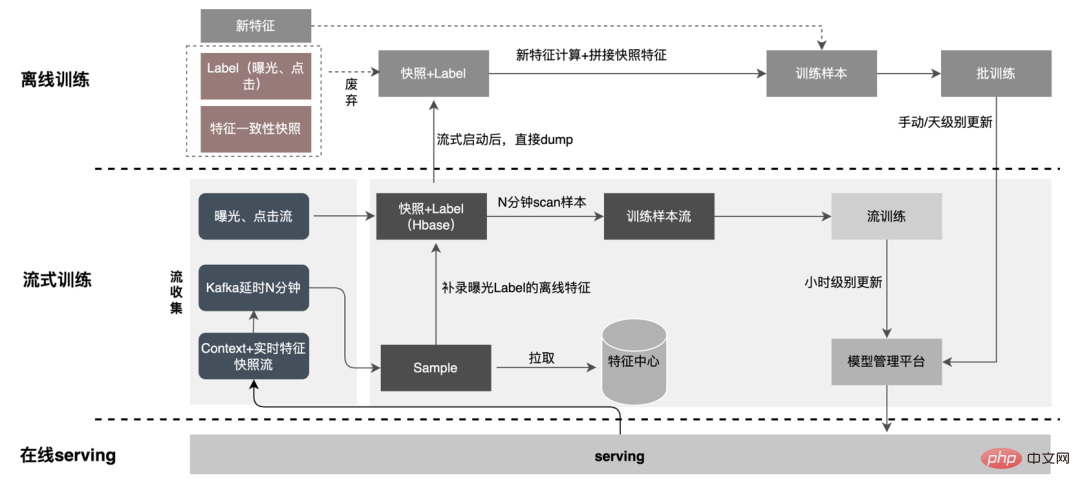
1. Pemisahan data: Selesaikan masalah volum penghantaran data yang besar (Masalah aliran syot kilat ciri), Label yang diramalkan Memadankan data masa nyata satu demi satu, data luar talian boleh diakses dua kali semasa aliran semula, yang boleh mengurangkan saiz aliran data pautan dengan banyak.
2. Penggunaan tertunda Kaedah join : Menyelesaikan masalah penggunaan memori yang besar.
3. Sampel rakaman tambahan ciri : Melalui Label’s Join, bilangan permintaan ciri yang ditambahkan di sini adalah kurang daripada 20% daripada sampel dalam talian Pembacaan tertunda, selepas sambung dengan pendedahan, tapis permintaan perkhidmatan model pendedahan (Konteks+ciri masa nyata), kemudian rekod semua ciri luar talian, kumpulkan data sampel yang lengkap dan tuliskannya ke HBase.
Dengan lelaran perniagaan, bilangan ciri dalam petikan ciri menjadi lebih besar dan lebih besar, menjadikan petikan ciri keseluruhan menjangkau berpuluh-puluh dalam satu senario perniagaan TB tahap/hari; dari sudut storan, gambaran ciri perniagaan tunggal selama beberapa hari sudah berada pada tahap PB, hampir mencapai ambang storan algoritma pengiklanan, tekanan storan adalah tinggi; sudut pandangan pengiraan, menggunakan Proses pengiraan asal, disebabkan oleh had sumber enjin pengkomputeran (Spark) ( shuffle digunakan, data dalam fasa tulis shuffle akan ditulis pada cakera. Jika memori yang diperuntukkan tidak mencukupi, penulisan berbilang cakera dan pengisihan luaran akan berlaku ), memerlukan memori dengan saiz yang sama dengan datanya sendiri dan lebih banyak CU pengkomputeran untuk melengkapkan pengiraan dengan berkesan, menduduki memori tinggi . Proses teras proses pembinaan sampel ditunjukkan dalam rajah di bawah:
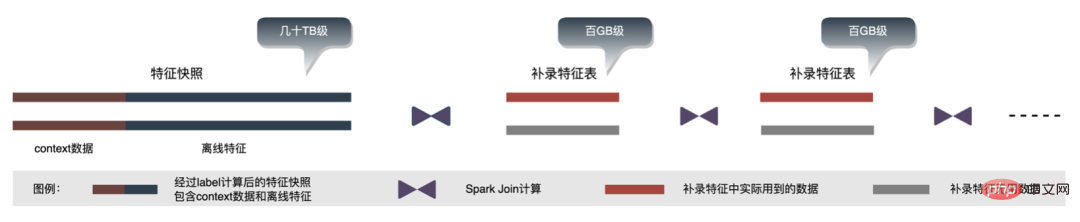
Apabila merakam semula ciri, terdapat masalah berikut:
Untuk menyelesaikan masalah kecekapan pembinaan sampel yang perlahan, kami akan mulakan dengan pengurusan struktur data dalam jangka pendek Proses terperinci adalah seperti rajah di bawah:
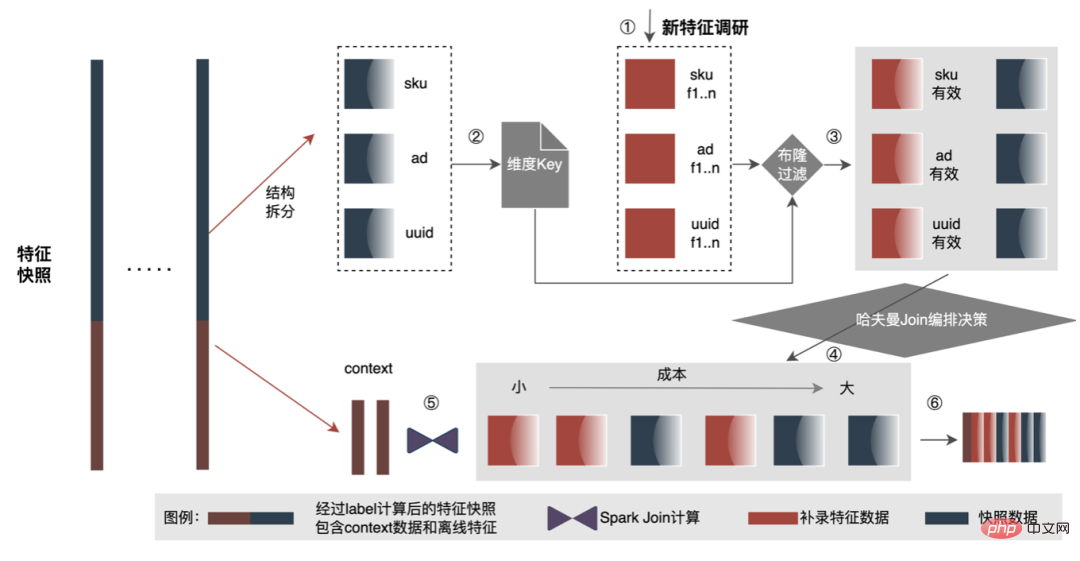
Sumber storan luar talian data telah disimpan sebanyak 80%+ dan kecekapan pembinaan sampel telah ditingkatkan sebanyak 200%+ Pada masa ini, keseluruhan data sampel juga sedang dilaksanakan berdasarkan di tasik data untuk meningkatkan lagi kecekapan data.
Platform ini telah mengumpulkan sejumlah besar kandungan berharga seperti ciri, sampel dan model serta berharap dapat membantu ahli strategi dengan menggunakan semula aset data ini. Jalankan lelaran perniagaan yang lebih baik dan capai faedah perniagaan yang lebih baik. Pengoptimuman ciri menyumbang 40% daripada semua kaedah yang digunakan oleh kakitangan algoritma untuk meningkatkan kesan model Walau bagaimanapun, kaedah perlombongan ciri tradisional mempunyai masalah seperti penggunaan masa yang lama, kecekapan perlombongan yang rendah dan perlombongan ciri yang berulang Oleh itu, platform berharap untuk memperkasakan dimensi ciri. Jika terdapat proses percubaan automatik untuk mengesahkan kesan mana-mana ciri dan mengesyorkan penunjuk kesan akhir kepada pengguna, ia sudah pasti akan membantu ahli strategi menjimatkan banyak masa. Apabila keseluruhan pembinaan pautan selesai, anda hanya perlu memasukkan set calon ciri yang berbeza untuk mengeluarkan penunjuk kesan yang sepadan. Untuk tujuan ini, platform telah membina mekanisme pintar untuk "penambahan", "penolakan", "pendaraban" dan "pembahagian" ciri dan sampel.
Pengesyoran ciri adalah berdasarkan kaedah ujian model, menggunakan semula ciri ke dalam model sedia ada dalam barisan perniagaan lain dan membina sampel dan model baharu ; kesan luar talian model baharu dan model Asas, dapatkan manfaat ciri baharu dan secara automatik menolaknya kepada pemimpin perniagaan yang berkaitan. Proses pengesyoran ciri khusus ditunjukkan dalam rajah di bawah:
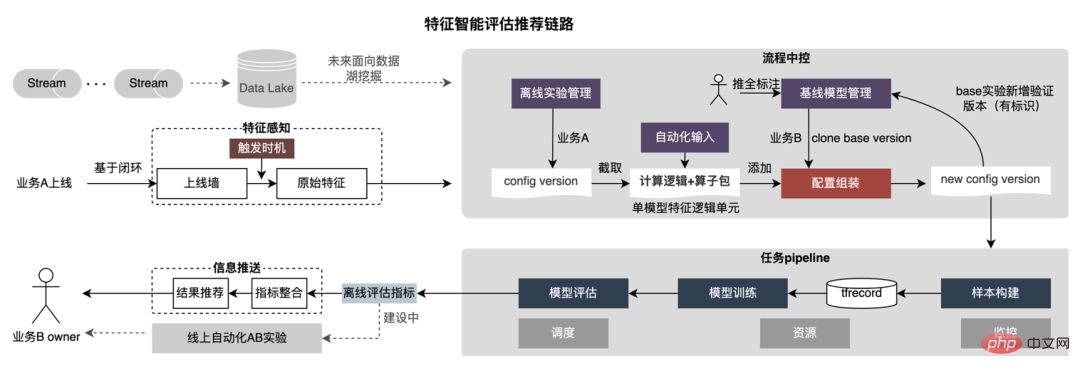
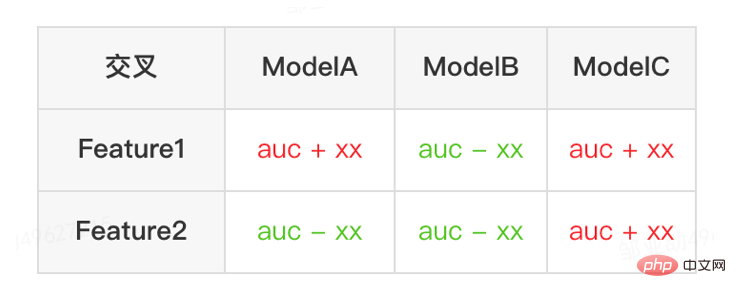
Selepas pengesyoran ciri dilaksanakan dalam iklan dan telah mencapai faedah tertentu, kami Membuat beberapa penerokaan baharu pada tahap pemerkasaan ciri. Dengan pengoptimuman berterusan model, kelajuan pengembangan ciri adalah sangat pantas, dan penggunaan sumber perkhidmatan model meningkat secara mendadak. Oleh itu, platform telah membina satu set alat penapisan ciri hujung ke hujung.

Akhirnya, selepas 40% ciri berada di luar talian dalam model dalaman, penurunan dalam penunjuk perniagaan masih dikawal dalam ambang yang munasabah.
Untuk mendapatkan kesan model yang lebih baik, beberapa penerokaan baharu telah dimulakan dalam pengiklanan, termasuk model besar, masa nyata dan ciri perpustakaan menunggu. Terdapat matlamat utama di sebalik penerokaan ini: keperluan untuk data yang lebih banyak dan lebih baik untuk menjadikan model lebih pintar dan lebih cekap. Bermula dari situasi semasa pengiklanan, pembinaan pangkalan data sampel (Bank Data) dicadangkan untuk membawa lebih banyak jenis dan skala data luaran yang lebih besar dan menggunakannya pada perniagaan sedia ada. Khususnya seperti yang ditunjukkan dalam rajah di bawah:
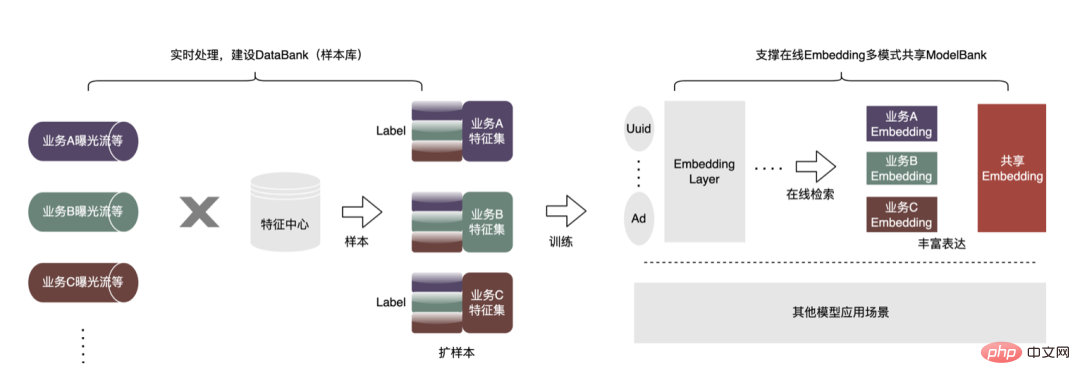
Kami telah mewujudkan platform perkongsian sampel universal, di mana barisan perniagaan lain boleh dipinjam untuk menjana sampel Tambahan . Ia juga membina seni bina perkongsian Embedding yang sama untuk merealisasikan integrasi perniagaan berskala besar dan berskala kecil. Berikut ialah contoh penggunaan semula sampel bukan pengiklanan dalam baris perniagaan pengiklanan Kaedah khusus adalah seperti berikut:
Contohnya, dengan menggunakan semula sampel bukan pengiklanan ke dalam perniagaan dalam pengiklanan, bilangan sampel telah meningkat beberapa kali Digabungkan dengan algoritma pembelajaran pemindahan, AUC luar talian telah meningkat sebanyak seribu mata Keempat, CPM akan meningkat sebanyak 1% selepas pergi ke dalam talian. Di samping itu, kami juga sedang membina perpustakaan tema sampel pengiklanan untuk mengurus data sampel yang dijana oleh setiap perniagaan secara seragam (Metadata bersatu), dan mendedahkan pengelasan tema sampel bersatu kepada pengguna untuk pendaftaran, carian dan penggunaan semula dengan pantas. Storan bersatu untuk lapisan bawah, menjimatkan storan dan sumber pengkomputeran, mengurangkan gabungan data dan meningkatkan ketepatan masa.
Melalui ciri "subtraction", beberapa ciri yang tidak mempunyai kesan positif boleh dihapuskan, tetapi melalui pemerhatian, didapati terdapat masih banyak ciri dengan sedikit nilai dalam ciri model. Oleh itu, kita boleh mengambil langkah lebih jauh dengan mempertimbangkan secara menyeluruh kedua-dua nilai dan kos Di bawah kekangan berasaskan kos keseluruhan pautan, kita boleh menapis ciri tersebut dengan input dan output yang agak rendah dan mengurangkan penggunaan sumber. Proses penyelesaian di bawah kekangan kos ini ditakrifkan sebagai "pembahagian". Proses keseluruhan ditunjukkan dalam rajah di bawah.
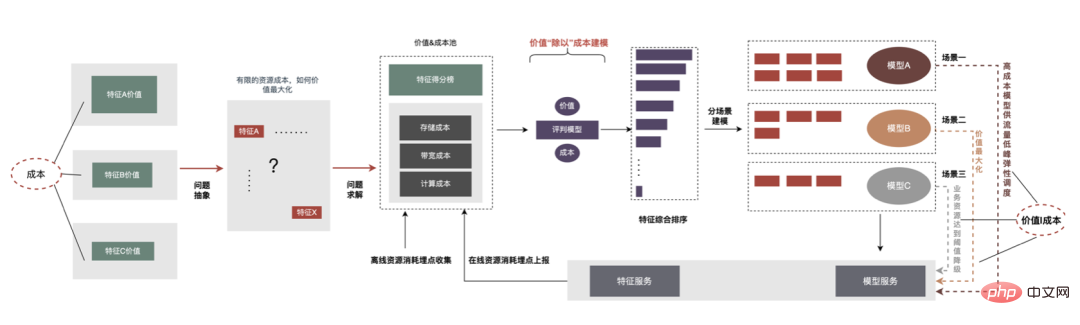
Dalam dimensi luar talian, kami telah mewujudkan sistem penilaian nilai ciri untuk memberikan kos dan nilai ciri boleh digunakan penaakulan dalam talian Maklumat digunakan untuk melakukan kemerosotan trafik, pengiraan keanjalan ciri dan operasi lain Langkah-langkah utama untuk "pembahagian" adalah seperti berikut:
Di atas adalah amalan anti-"peningkatan" kami dalam projek pembelajaran mendalam berskala besar untuk membantu Kurangkan kos perniagaan dan tingkatkan kecekapan. Pada masa hadapan, kami akan terus meneroka dan berlatih dalam aspek berikut:
Ya Jie, Ying Liang, Chen Long, Cheng Jie, Deng Feng, Dong Kui, Tong Ye, Simin, Lebin, dsb., semuanya datang daripada pasukan teknikal penghantaran makanan Meituan.
Atas ialah kandungan terperinci Amalan kejuruteraan model pembelajaran mendalam berskala besar untuk pengiklanan bawa pulang. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menetapkan textarea baca sahaja
Bagaimana untuk menetapkan textarea baca sahaja
 Bagaimana untuk membuka kebenaran skop
Bagaimana untuk membuka kebenaran skop
 Bagaimana untuk mengambil tangkapan skrin pada telefon mudah alih Huawei
Bagaimana untuk mengambil tangkapan skrin pada telefon mudah alih Huawei
 Apakah sistem Honor?
Apakah sistem Honor?
 Cara melaksanakan senarai terpaut dalam go
Cara melaksanakan senarai terpaut dalam go
 Bagaimana untuk memasuki laman web 404
Bagaimana untuk memasuki laman web 404
 Cara menukar bandar di Douyin
Cara menukar bandar di Douyin
 Bagaimana untuk memadam karya anda sendiri di TikTok
Bagaimana untuk memadam karya anda sendiri di TikTok








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



