


ICLR (International Conference on Learning Representations) diiktiraf sebagai salah satu persidangan akademik antarabangsa yang paling berpengaruh dalam pembelajaran mesin.
Pada persidangan ICLR 2023 tahun ini, Microsoft Research Asia menerbitkan hasil penyelidikan terkini dalam bidang seperti keteguhan pembelajaran mesin dan kecerdasan buatan yang bertanggungjawab.
Antaranya, hasil kerjasama penyelidikan saintifik antara Microsoft Research Asia dan Korea Advanced Institute of Science and Technology (KAIST) di bawah rangka kerja kerjasama akademik antara kedua-dua pihak telah diiktiraf kerana kejelasan, wawasan, kreativiti dan potensi cemerlang mereka Impak yang berkekalan telah dianugerahkan Anugerah Kertas Cemerlang ICLR 2023.

Alamat kertas: https://arxiv.org/abs/2303.14969
Tugas ramalan padat ialah kelas tugas penting dalam bidang penglihatan komputer, seperti segmentasi semantik, anggaran kedalaman, pengesanan tepi dan tunggu pengesanan titik utama. Untuk tugasan sedemikian, anotasi manual bagi label tahap piksel menghadapi kos yang sangat tinggi. Oleh itu, bagaimana untuk belajar daripada sejumlah kecil data berlabel dan membuat ramalan yang tepat, iaitu, pembelajaran sampel kecil, adalah topik yang sangat membimbangkan dalam bidang ini. Dalam tahun-tahun kebelakangan ini, penyelidikan tentang pembelajaran sampel kecil terus membuat penemuan, terutamanya beberapa kaedah berdasarkan pembelajaran meta dan pembelajaran berlawanan, yang telah menarik banyak perhatian dan dialu-alukan daripada komuniti akademik.
Walau bagaimanapun, kaedah pembelajaran sampel kecil visi komputer sedia ada secara amnya ditujukan kepada jenis tugasan tertentu, seperti tugasan pengelasan atau tugasan segmentasi semantik. Mereka sering mengeksploitasi pengetahuan terdahulu dan andaian khusus untuk tugas-tugas ini dalam mereka bentuk seni bina model dan proses latihan, dan oleh itu tidak sesuai untuk generalisasi kepada tugas ramalan padat sewenang-wenangnya. Penyelidik di Microsoft Research Asia ingin meneroka soalan teras: sama ada terdapat pelajar beberapa pukulan umum yang boleh mempelajari tugas ramalan padat untuk segmen arbitrari imej ghaib daripada sebilangan kecil imej berlabel.
Matlamat tugas ramalan yang padat adalah untuk mempelajari pemetaan daripada imej input kepada label yang dianotasi dalam piksel, yang boleh ditakrifkan sebagai:
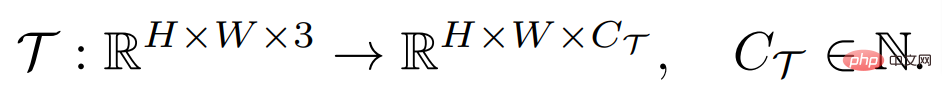
di mana H dan W ialah ketinggian dan lebar imej masing-masing. Imej input biasanya mengandungi tiga saluran RGB, dan C_Τ mewakili bilangan saluran keluaran. Tugas ramalan padat yang berbeza mungkin melibatkan nombor saluran keluaran dan atribut saluran yang berbeza Contohnya, output tugasan segmentasi semantik ialah perduaan berbilang saluran, manakala output tugasan anggaran kedalaman ialah nilai berterusan satu saluran. Pelajar umum beberapa sampel F, untuk mana-mana tugas Τ, diberikan sebilangan kecil set sokongan sampel berlabel S_Τ (termasuk N kumpulan sampel X^i dan label Y^i), boleh belajar untuk imej Pertanyaan yang tidak kelihatan Jangkaan:
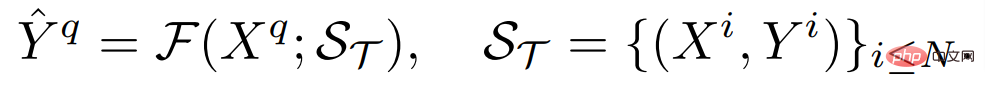
Kedua, pelajar harus melaraskan mekanisme ramalannya secara fleksibel untuk menyelesaikan tugasan ghaib dengan pelbagai semantik sambil cukup cekap untuk mengelakkan overfitting.
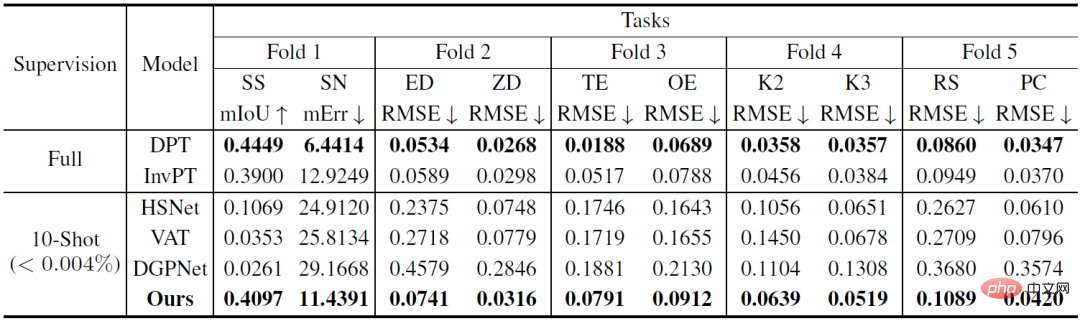
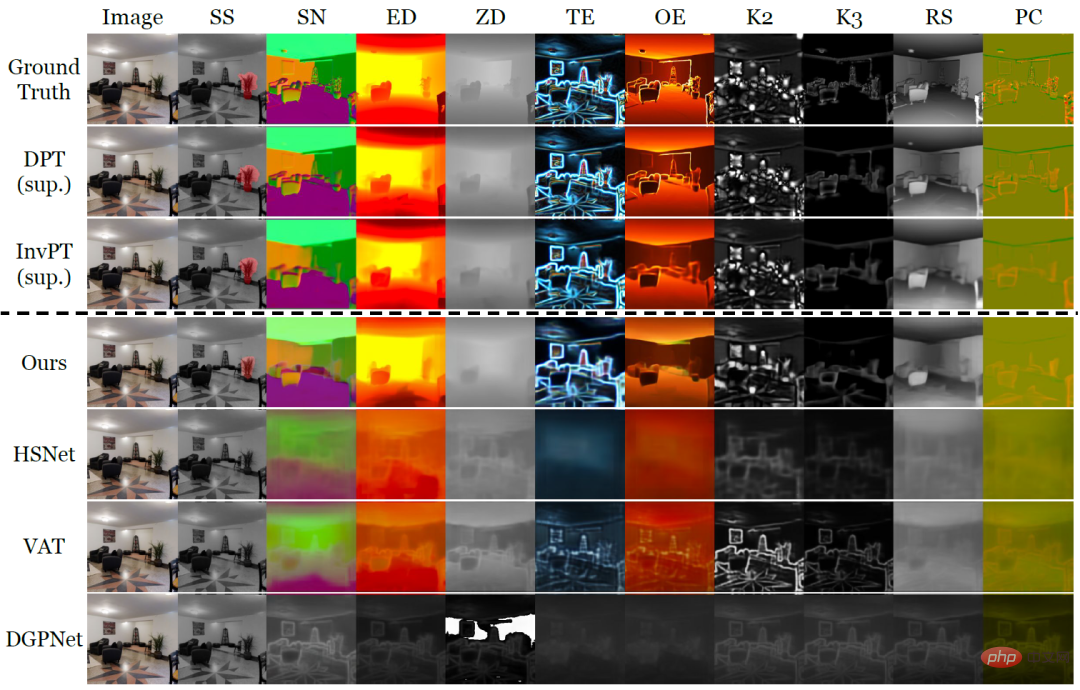
Reka bentuk VTM diilhamkan oleh analogi kepada proses pemikiran manusia: memandangkan sebilangan kecil contoh tugas baharu, manusia boleh dengan cepat menetapkan output yang serupa kepada input yang serupa berdasarkan persamaan antara contoh, dan boleh juga Fleksibel menyesuaikan tahap di mana input dan output adalah serupa berdasarkan konteks tertentu. Para penyelidik melaksanakan proses analogi untuk ramalan padat menggunakan padanan bukan parametrik berdasarkan tahap tampalan. Melalui latihan, model ini diilhamkan untuk menangkap persamaan dalam tampalan imej. Memandangkan sebilangan kecil contoh berlabel untuk tugas baharu, VTM mula-mula melaraskan pemahamannya tentang persamaan berdasarkan contoh yang diberikan dan label contoh, mengunci tampung imej sampel dengan yang bakal- Ramalkan tampalan imej yang serupa dan ramalkan label tampalan imej yang tidak kelihatan dengan menggabungkan labelnya. Rajah 1: Keseluruhan seni bina VTM VTM mengamalkan lapisan seni bina penyahkod pengekod melaksanakan padanan bukan parametrik berasaskan tampalan pada pelbagai peringkat. Ia terutamanya terdiri daripada empat modul, iaitu pengekod imej f_Τ, pengekod label g, modul pemadanan dan penyahkod label h. Memandangkan imej pertanyaan dan set sokongan, pengekod imej mula-mula mengekstrak perwakilan peringkat tampalan imej untuk setiap pertanyaan dan imej sokongan secara bebas. Pengekod teg juga akan mengekstrak setiap teg yang menyokong teg. Memandangkan label pada setiap peringkat, modul padanan melaksanakan padanan bukan parametrik dan penyahkod label akhirnya menyimpulkan label bagi imej pertanyaan. Intipati VTM ialah kaedah meta-pembelajaran. Latihannya terdiri daripada berbilang episod, setiap episod mensimulasikan masalah pembelajaran sampel kecil. Latihan VTM menggunakan set data latihan meta D_train, yang mengandungi pelbagai contoh berlabel tugas ramalan padat. Setiap episod latihan mensimulasikan senario pembelajaran beberapa pukulan untuk tugasan tertentu T_train dalam set data, dengan matlamat untuk menghasilkan label yang betul untuk imej pertanyaan diberikan set sokongan. Melalui pengalaman belajar daripada berbilang sampel kecil, model boleh mempelajari pengetahuan am untuk menyesuaikan diri dengan tugasan baharu dengan cepat dan fleksibel. Pada masa ujian, model perlu melakukan pembelajaran beberapa pukulan pada sebarang ujian T_tugas yang tidak disertakan dalam set data latihan D_train. Apabila berurusan dengan tugasan sewenang-wenangnya, memandangkan dimensi output C_Τ bagi setiap tugasan dalam meta-latihan dan ujian adalah berbeza, ia menjadi satu cabaran besar untuk mereka bentuk parameter model umum bersatu untuk semua tugas. Untuk menyediakan penyelesaian yang mudah dan umum, penyelidik mengubah tugasan kepada subtugas saluran tunggal C_Τ, mempelajari setiap saluran secara berasingan dan memodelkan setiap subtugas secara bebas menggunakan model F yang dikongsi. Untuk menguji VTM, para penyelidik juga membina khas varian dataset Taskonomy untuk mensimulasikan pembelajaran kecil tugas ramalan padat yang tidak kelihatan. Taskonomy mengandungi pelbagai imej dalaman beranotasi, yang mana penyelidik memilih sepuluh tugas ramalan padat dengan semantik dan dimensi output yang berbeza dan membahagikannya kepada lima bahagian untuk pengesahan silang. Dalam setiap pembahagian, dua tugasan digunakan untuk penilaian pukulan kecil (T_test) dan baki lapan tugasan digunakan untuk latihan (T_train). Penyelidik membina sekatan dengan teliti supaya tugas latihan dan ujian cukup berbeza antara satu sama lain, seperti mengumpulkan tugas tepi (TE, OE) ke dalam tugas ujian untuk membolehkan penilaian tugasan dengan semantik baharu. Jadual 1: Perbandingan kuantitatif pada dataset Taskonomy (Beberapa pukulan garis dasar selepas tugasan latihan dari partition lain, pembelajaran 10 pukulan dilakukan pada tugasan yang dibahagikan untuk diuji, dengan garis dasar yang diselia sepenuhnya dilatih dan dinilai pada setiap lipatan (DPT) atau semua lipatan (InvPT) Jadual 1 dan Rajah 2 secara kuantitatif dan kualitatif menunjukkan prestasi pembelajaran sampel kecil VTM dan dua jenis model garis dasar masing-masing pada sepuluh tugas ramalan intensif. Antaranya, DPT dan InvPT ialah dua kaedah pembelajaran terselia yang paling maju yang boleh dilatih secara bebas untuk setiap tugasan, manakala InvPT boleh bersama-sama melatih semua tugas. Memandangkan tiada kaedah sampel kecil khusus dibangunkan untuk tugas ramalan padat umum sebelum VTM, penyelidik membandingkan VTM dengan tiga kaedah pembahagian sampel kecil yang terkini, iaitu DGPNet, HSNet dan VAT, dan melanjutkannya untuk mengendalikan A ruang label umum untuk tugas ramalan padat. VTM tidak mempunyai akses kepada ujian T_test semasa latihan dan hanya menggunakan sebilangan kecil (10) imej berlabel pada masa ujian, tetapi ia menunjukkan prestasi terbaik dalam semua model garis dasar tangkapan kecil dan berprestasi baik pada banyak tugasan berbanding sepenuhnya model garis dasar yang diselia. Rajah 2: Satu sampel kecil hanya sepuluh imej berlabel dalam sepuluh tugas ramalan padat Taskonomy pada tugas baharu Perbandingan kualitatif pembelajaran kaedah. Apabila kaedah lain gagal, VTM berjaya mempelajari semua tugasan baharu dengan semantik yang berbeza dan perwakilan label yang berbeza. Dalam Rajah 2, di atas garis putus-putus ialah label sebenar dan dua kaedah pembelajaran yang diselia DPT dan InvPT masing-masing. Di bawah garis putus-putus adalah kaedah pembelajaran sampel kecil. Terutamanya, garis dasar sampel kecil yang lain mengalami kekurangan bencana pada tugas baharu, manakala VTM berjaya mempelajari semua tugasan. Percubaan menunjukkan bahawa VTM kini boleh menunjukkan prestasi yang sama secara kompetitif dengan garis dasar yang diselia sepenuhnya pada bilangan contoh berlabel yang sangat kecil ( Ringkasnya, walaupun idea asas VTM adalah sangat mudah, ia mempunyai seni bina bersatu dan boleh digunakan untuk sebarang tugas ramalan yang padat, kerana algoritma pemadanan pada asasnya Mengandungi semua tugas dan struktur label (cth., berterusan atau diskret). Di samping itu, VTM hanya memperkenalkan sebilangan kecil parameter khusus tugasan, membolehkannya tahan terhadap terlalu pasang dan fleksibel. Pada masa hadapan, penyelidik berharap untuk meneroka lebih lanjut kesan jenis tugasan, volum data dan pengedaran data pada prestasi generalisasi model semasa proses pra-latihan, dengan itu membantu kami membina pelajar sampel kecil yang benar-benar universal. 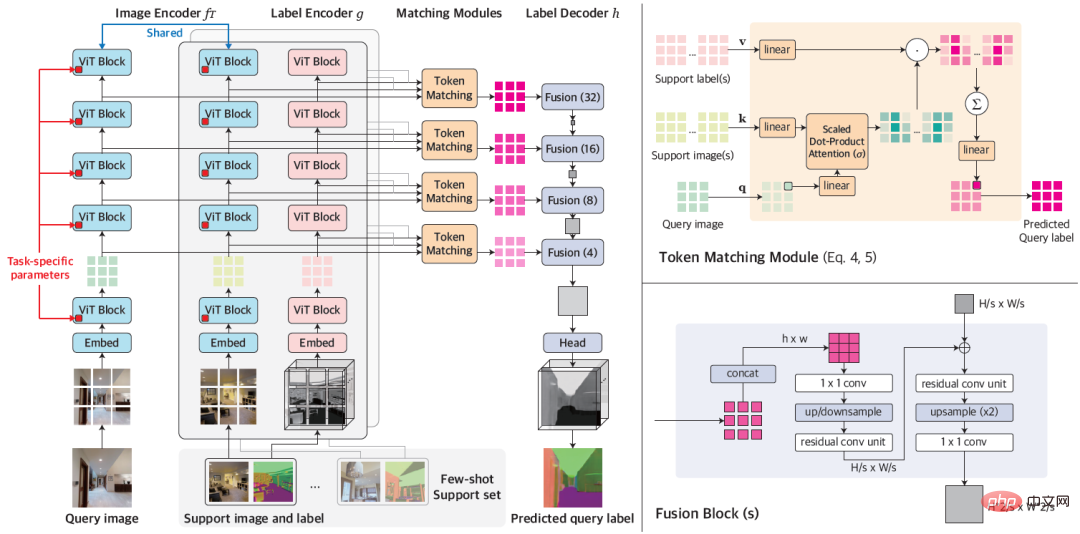
Atas ialah kandungan terperinci Pelajar beberapa pukulan universal: penyelesaian untuk pelbagai tugas ramalan intensif. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bahasa Komputer
Bahasa Komputer
 Medan aplikasi komputer
Medan aplikasi komputer
 Apakah pengekodan yang digunakan di dalam komputer untuk memproses data dan arahan?
Apakah pengekodan yang digunakan di dalam komputer untuk memproses data dan arahan?
 Sebab utama mengapa komputer menggunakan binari
Sebab utama mengapa komputer menggunakan binari
 Apakah ciri-ciri utama komputer?
Apakah ciri-ciri utama komputer?
 Apakah komponen asas komputer?
Apakah komponen asas komputer?
 Apakah kekunci yang dirujuk oleh anak panah dalam komputer?
Apakah kekunci yang dirujuk oleh anak panah dalam komputer?
 Bagaimana untuk memulihkan sejarah penyemak imbas pada komputer
Bagaimana untuk memulihkan sejarah penyemak imbas pada komputer








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



