



Hello semua, saya Abang J. (Buku diberikan pada penghujung artikel)
Visualisasi data merujuk kepada penggunaan grafik atau jadual untuk mempersembahkan data. Carta boleh membentangkan sifat data dan perhubungan antara data atau atribut dengan jelas, menjadikannya mudah untuk orang mentafsir carta. Melalui Graf Penerokaan, pengguna boleh memahami ciri data, mencari arah aliran dalam data dan menurunkan ambang untuk memahami data.
Bab ini terutamanya menggunakan Panda untuk melukis graf dan bukannya menggunakan modul Matplotlib. Malah, Pandas telah menyepadukan kaedah lukisan Matplotlib ke dalam DataFrame, jadi dalam aplikasi praktikal, pengguna boleh menyelesaikan kerja lukisan tanpa merujuk terus Matplotlib.
Carta garisan ialah carta paling asas, yang boleh digunakan untuk menunjukkan hubungan antara data berterusan dalam medan yang berbeza. Kaedah plot.line() digunakan untuk melukis carta garisan dan parameter seperti warna dan bentuk boleh ditetapkan. Dari segi penggunaan, kaedah melukis gambarajah garisan selisih sepenuhnya mewarisi penggunaan Matplotlib, jadi atur cara juga mesti memanggil plt.show() pada penghujungnya untuk menjana gambar rajah, seperti yang ditunjukkan dalam Rajah 8.4.
df_iris[['sepal length (cm)']].plot.line() plt.show() ax = df[['sepal length (cm)']].plot.line(color='green',title="Demo",style='--') ax.set(xlabel="index", ylabel="length") plt.show()
Carta Taburan digunakan untuk melihat hubungan antara data diskret dalam medan yang berbeza. Plot serakan dilukis menggunakan df.plot.scatter(), seperti yang ditunjukkan dalam Rajah 8.5.
df = df_iris
df.plot.scatter(x='sepal length (cm)', y='sepal width (cm)')
from matplotlib import cm
cmap = cm.get_cmap('Spectral')
df.plot.scatter(x='sepal length (cm)',
y='sepal width (cm)',
s=df[['petal length (cm)']]*20,
c=df['target'],
cmap=cmap,
title='different circle size by petal length (cm)')
Carta Histogram biasanya digunakan dalam lajur yang sama untuk menunjukkan taburan data berterusan, yang lain carta yang serupa dengan histogram ialah Carta Bar, yang digunakan untuk melihat lajur yang sama, seperti yang ditunjukkan dalam Rajah 8.6.
df[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)','petal width (cm)']].plot.hist() 2 df.target.value_counts().plot.bar()
Carta Pai boleh digunakan untuk melihat semua kategori dalam lajur yang sama medan yang sama atau taburan data dalam medan yang berbeza dibandingkan dengan carta kotak, seperti yang ditunjukkan dalam Rajah 8.7.
df.target.value_counts().plot.pie(legend=True) df.boxplot(column=['target'],figsize=(10,5))
Bahagian ini menggunakan dua set data sebenar untuk benar-benar menunjukkan beberapa kaedah penerokaan data.
Dalam Tinjauan Komuniti Amerika, kira-kira 3.5 juta isi rumah ditanya butiran tentang siapa mereka dan cara hidup mereka. Tinjauan itu merangkumi beberapa topik termasuk keturunan, pendidikan, pekerjaan, pengangkutan, penggunaan internet dan tempat tinggal.
Sumber data: https://www.kaggle.com/census/2013-american-community-survey.
Nama data: Tinjauan Komuniti Amerika 2013.
Mula-mula perhatikan penampilan dan ciri-ciri data, serta makna, jenis dan skop setiap medan.
# 读取数据
df = pd.read_csv("./ss13husa.csv")
# 栏位种类数量
df.shape
# (756065,231)
# 栏位数值范围
df.describe()Mula-mula sambungkan dua ss13pusa.csv Data ini mengandungi sejumlah 300,000 keping data, dengan 3 medan: SCHL (Peringkat Sekolah), PINCP (Pendapatan) dan ESR (Status Kerja, Status Kerja. ).
pusa = pd.read_csv("ss13pusa.csv") pusb = pd.read_csv("ss13pusb.csv")
# 串接两份数据
col = ['SCHL','PINCP','ESR']
df['ac_survey'] = pd.concat([pusa[col],pusb[col],axis=0)Kumpulkan data mengikut latar belakang pendidikan, perhatikan perkadaran nombor dengan kelayakan akademik yang berbeza, dan kemudian hitung purata pendapatan mereka.
group = df['ac_survey'].groupby(by=['SCHL']) print('学历分布:' + group.size())
group = ac_survey.groupby(by=['SCHL']) print('平均收入:' +group.mean())Set Data Harga Boston House mengandungi maklumat tentang perumahan di kawasan Boston, termasuk 506 sampel data dan 13 dimensi ciri.
Sumber data: https://archive.ics.uci.edu/ml/machine-learning-databases/housing/.
Nama data: Set Data Harga Rumah Boston.
Mula-mula perhatikan penampilan dan ciri-ciri data, serta makna, jenis dan skop setiap medan.
Taburan harga rumah (MEDV) boleh dilukis dalam bentuk histogram, seperti yang ditunjukkan dalam Rajah 8.8.
df = pd.read_csv("./housing.data")
# 栏位种类数量
df.shape
# (506, 14)
#栏位数值范围df.describe()
import matplotlib.pyplot as plt
df[['MEDV']].plot.hist()
plt.show()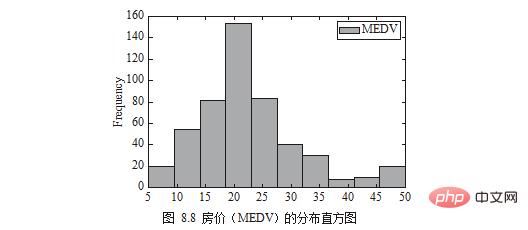
Nota: Bahasa Inggeris dalam gambar sepadan dengan nama yang ditentukan oleh pengarang dalam kod atau data Secara praktikalnya, pembaca boleh menggantikannya dengan perkataan mereka perlukan.
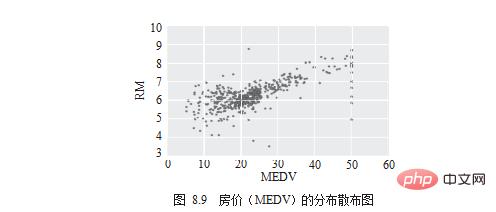
Perkara seterusnya yang perlu anda ketahui ialah dimensi mana yang jelas berkaitan dengan "harga rumah". Mula-mula perhatikan menggunakan gambar rajah serakan, seperti yang ditunjukkan dalam Rajah 8.9.
# draw scatter chart df.plot.scatter(x='MEDV', y='RM') . plt.show()
最后,计算相关系数并用聚类热图(Heatmap)来进行视觉呈现,如图 8.10 所示。
# compute pearson correlation corr = df.corr() # drawheatmap import seaborn as sns corr = df.corr() sns.heatmap(corr) plt.show()
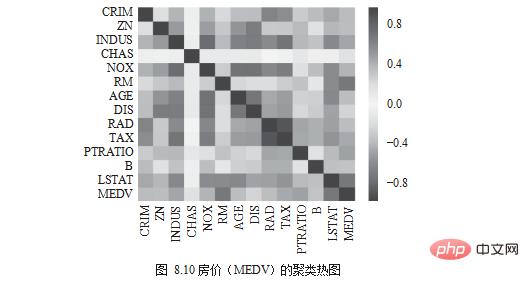
颜色为红色,表示正向关系;颜色为蓝色,表示负向关系;颜色为白色,表示没有关系。RM 与房价关联度偏向红色,为正向关系;LSTAT、PTRATIO 与房价关联度偏向深蓝, 为负向关系;CRIM、RAD、AGE 与房价关联度偏向白色,为没有关系。
声明:本文选自清华大学出版社的《深入浅出python数据分析》一书,略有修改,经出版社授权刊登于此。
Atas ialah kandungan terperinci Kongsi contoh yang baik untuk mempelajari visualisasi data Python!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



