


Persepsi alam sekitar ialah pautan pertama dalam pemanduan autonomi dan hubungan antara kenderaan dan alam sekitar. Prestasi keseluruhan sistem pemanduan autonomi sebahagian besarnya bergantung kepada kualiti sistem persepsi. Pada masa ini, terdapat dua laluan teknologi arus perdana untuk teknologi penderiaan alam sekitar:
① Penyelesaian gabungan berbilang sensor yang diterajui penglihatan, wakil biasa ialah Tesla
② Diterajui oleh Lidar, yang lain Sensor-; penyelesaian teknikal yang dibantu, wakil biasa seperti Google, Baidu, dsb.
Kami akan memperkenalkan algoritma persepsi visual utama dalam persepsi alam sekitar liputan tugasnya dan bidang teknikalnya ditunjukkan dalam rajah di bawah. Kami menyemak konteks dan arah algoritma persepsi visual 2D dan 3D di bawah.
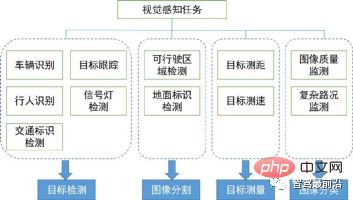
Dalam bahagian ini kami mula-mula memperkenalkan algoritma persepsi visual 2D bermula daripada beberapa tugas yang digunakan secara meluas dalam pemanduan autonomi , termasuk pengesanan dan penjejakan objek 2D berasaskan imej atau video, dan pembahagian semantik adegan 2D. Dalam beberapa tahun kebelakangan ini, pembelajaran mendalam telah menembusi pelbagai bidang persepsi visual dan mencapai hasil yang baik Oleh itu, kami telah menyusun beberapa algoritma pembelajaran mendalam klasik.
1.1 Pengesanan dua peringkat
Dua peringkat merujuk kepada dua cara untuk mencapai pengesanan . Terdapat dua proses, satu adalah untuk mengekstrak kawasan objek; Algoritma perwakilan termasuk siri R-CNN (R-CNN, Fast R-CNN, Faster R-CNN), dsb. R-CNN yang lebih pantas ialah rangkaian pengesanan hujung ke hujung yang pertama. Pada peringkat pertama, rangkaian calon wilayah (RPN) digunakan untuk menjana bingkai calon berdasarkan peta ciri, dan ROIPooling digunakan untuk menjajarkan saiz ciri calon pada peringkat kedua, lapisan bersambung sepenuhnya digunakan untuk diperhalusi klasifikasi dan regresi.
Idea Anchor dicadangkan di sini untuk mengurangkan kesukaran pengiraan dan meningkatkan kelajuan. Setiap kedudukan peta ciri akan menjana Sauh dengan saiz dan nisbah bidang yang berbeza, yang digunakan sebagai rujukan untuk regresi bingkai objek. Pengenalan Anchor membolehkan tugas regresi hanya menangani perubahan yang agak kecil, jadi pembelajaran rangkaian akan menjadi lebih mudah. Rajah di bawah ialah rajah struktur rangkaian R-CNN yang Lebih Pantas.
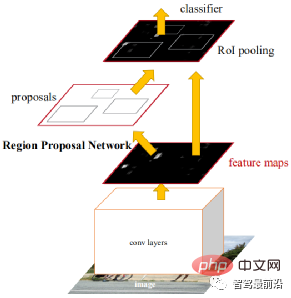
Peringkat pertama CascadeRCNN betul-betul sama dengan Faster R-CNN, dan peringkat kedua menggunakan berbilang lapisan RoiHead untuk melata. Kerja-kerja seterusnya kebanyakannya berkisar pada beberapa penambahbaikan rangkaian yang disebutkan di atas atau sebilangan besar kerja sebelumnya, dengan sedikit penambahbaikan terobosan.
1.2 Pengesanan satu peringkat
Berbanding dengan algoritma dua peringkat, algoritma satu peringkat hanya perlu mengekstrak ciri sekali untuk mencapai pengesanan sasaran dan kelajuannya algoritma adalah lebih pantas dan secara amnya Kejituannya lebih rendah sedikit. Kerja perintis jenis algoritma ini ialah YOLO, yang kemudiannya dipertingkatkan oleh SSD dan Retinanet Pasukan yang mencadangkan YOLO menyepadukan helah ini yang membantu meningkatkan prestasi ke dalam algoritma YOLO, dan seterusnya mencadangkan 4 versi yang dipertingkatkan YOLOv2~ YOLOv5. Walaupun ketepatan ramalan tidak sebaik algoritma pengesanan sasaran dua peringkat, YOLO telah menjadi arus perdana dalam industri kerana kelajuan lariannya yang lebih pantas. Rajah di bawah ialah rajah struktur rangkaian YOLO v3.
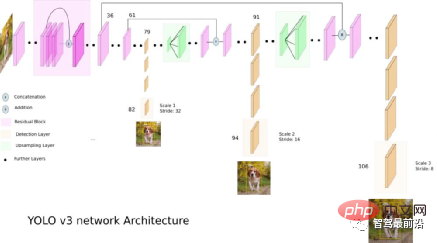
1.3 Pengesanan tanpa sauh (tiada pengesanan Sauh)
Kaedah jenis ini secara amnya mewakili objek sebagai beberapa perkara utama. CNN digunakan untuk mengembalikan lokasi titik penting ini. Titik utama boleh menjadi titik tengah (CenterNet), titik sudut (CornerNet) atau titik perwakilan (RepPoints) bingkai objek. CenterNet menukarkan masalah pengesanan sasaran kepada masalah ramalan titik tengah, iaitu, menggunakan titik tengah sasaran untuk mewakili sasaran, dan mendapatkan bingkai segi empat tepat sasaran dengan meramalkan offset, lebar dan ketinggian titik pusat sasaran. Peta Haba mewakili maklumat pengelasan, dan setiap kategori akan menjana Peta Haba yang berasingan. Untuk setiap Peta Haba, apabila koordinat tertentu mengandungi titik tengah sasaran, titik utama akan dijana pada sasaran Kami menggunakan bulatan Gaussian untuk mewakili keseluruhan titik utama.

RepPoints mencadangkan untuk mewakili objek sebagai set titik perwakilan dan menyesuaikan diri dengan perubahan bentuk objek melalui lilitan boleh ubah bentuk. Set titik akhirnya ditukar kepada bingkai objek dan digunakan untuk mengira perbezaan daripada anotasi manual.
1.4 Pengesanan Transformer
Sama ada pengesanan sasaran satu peringkat atau dua peringkat, sama ada Anchor digunakan atau tidak, mekanisme perhatian tidak digunakan dengan baik. Sebagai tindak balas kepada situasi ini, Relation Net dan DETR menggunakan Transformer untuk memperkenalkan mekanisme perhatian ke dalam bidang pengesanan sasaran. Relation Net menggunakan Transformer untuk memodelkan hubungan antara sasaran yang berbeza, menggabungkan maklumat perhubungan ke dalam ciri dan mencapai peningkatan ciri. DETR mencadangkan seni bina pengesanan sasaran baharu berdasarkan Transformer, membuka era baharu pengesanan sasaran Rajah berikut ialah proses algoritma DETR Pertama, CNN digunakan untuk mengekstrak ciri imej, dan kemudian Transformer digunakan untuk memodelkan hubungan spatial global . Akhir sekali, kami mendapat Output daripada dipadankan dengan anotasi manual melalui algoritma pemadanan graf dwipartit.
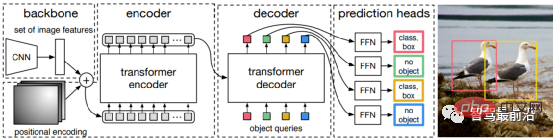
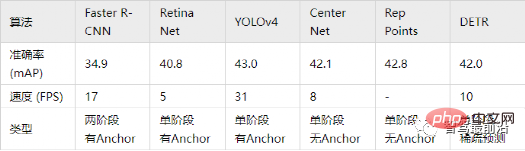
Ketepatan dalam jadual di bawah menggunakan mAP pada pangkalan data MS COCO sebagai penunjuk, manakala kelajuan diukur oleh FPS Berbanding dengan beberapa algoritma di atas, disebabkan oleh reka bentuk struktur rangkaian Terdapat banyak pilihan yang berbeza (seperti saiz input yang berbeza, rangkaian Tulang Belakang yang berbeza, dll.), dan platform perkakasan pelaksanaan setiap algoritma juga berbeza, jadi ketepatan dan kelajuan tidak dapat dibandingkan sepenuhnya hanya hasil kasar untuk rujukan anda.
Dalam aplikasi pemanduan autonomi, input adalah data video dan terdapat banyak sasaran yang perlu diberi perhatian Seperti kenderaan, pejalan kaki, basikal, dll. Oleh itu, ini adalah tugas pengesanan objek berbilang biasa (MOT). Untuk tugas MOT, rangka kerja yang paling popular pada masa ini ialah Penjejakan-demi-Pengesanan, dan prosesnya adalah seperti berikut:
① Pengesan sasaran memperoleh output bingkai sasaran pada satu imej bingkai tunggal; ② Ekstrak ciri setiap sasaran yang dikesan, biasanya termasuk ciri visual dan ciri gerakan; 🎜>
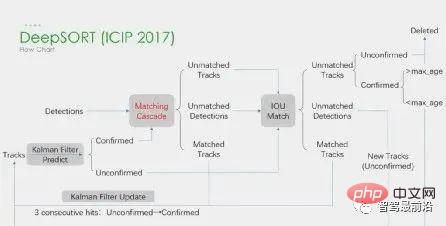
④ Padankan pengesanan sasaran dalam bingkai bersebelahan dan tetapkan ID yang sama kepada objek daripada sasaran yang sama. Pembelajaran mendalam diterapkan dalam semua empat langkah di atas, tetapi dua langkah pertama adalah yang utama. Dalam langkah 1, aplikasi pembelajaran mendalam adalah terutamanya untuk menyediakan pengesan objek berkualiti tinggi, jadi kaedah dengan ketepatan yang lebih tinggi biasanya dipilih. SORT ialah kaedah pengesanan sasaran berdasarkan Faster R-CNN, dan menggunakan algoritma penapis Kalman + algoritma Hungary untuk meningkatkan kelajuan penjejakan berbilang sasaran dan mencapai ketepatan SOTA Ia juga digunakan secara meluas dalam aplikasi praktikal. algoritma. Dalam langkah 2, aplikasi pembelajaran mendalam bergantung terutamanya pada penggunaan CNN untuk mengekstrak ciri visual objek. Ciri terbesar DeepSORT ialah menambah maklumat penampilan dan meminjam modul ReID untuk mengekstrak ciri pembelajaran mendalam, mengurangkan bilangan suis ID. Carta alir keseluruhan adalah seperti berikut:Selain itu, terdapat juga rangka kerja Pengesanan dan Penjejakan Serentak. Seperti CenterTrack wakil, yang berasal daripada algoritma pengesanan tanpa Anchor satu peringkat CenterNet yang diperkenalkan sebelum ini. Berbanding dengan CenterNet, CenterTrack menambah imej RGB bagi bingkai sebelumnya dan Peta Haba pusat objek sebagai input tambahan dan menambah cawangan Offset untuk perkaitan antara bingkai sebelumnya dan seterusnya. Berbanding dengan Penjejakan-demi-Pengesanan berbilang peringkat, CenterTrack menggunakan rangkaian untuk melaksanakan peringkat pengesanan dan pemadanan, meningkatkan kelajuan MOT.
 3. Segmen semantik
3. Segmen semantik
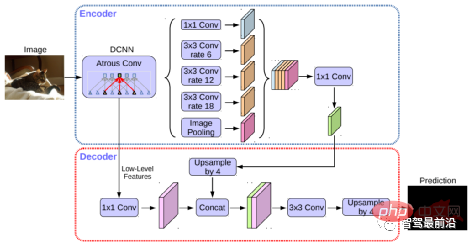
Algoritma STDC dalam beberapa tahun kebelakangan ini menggunakan struktur yang serupa dengan algoritma FCN, menghapuskan struktur penyahkod kompleks algoritma U-Net. Tetapi pada masa yang sama, dalam proses pensampelan rendah rangkaian, modul ARM digunakan untuk menggabungkan maklumat secara berterusan daripada peta ciri lapisan yang berbeza, dengan itu mengelakkan kelemahan algoritma FCN yang hanya mempertimbangkan perhubungan piksel tunggal. Ia boleh dikatakan bahawa algoritma STDC mencapai keseimbangan yang baik antara kelajuan dan ketepatan, dan ia boleh memenuhi keperluan masa nyata sistem pemanduan autonomi. Aliran algoritma ditunjukkan dalam rajah di bawah.
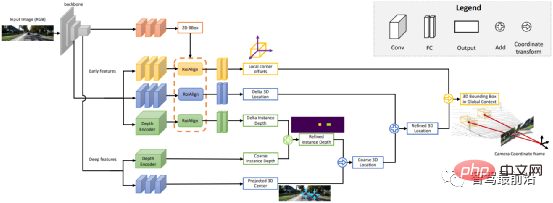
Dalam bahagian ini kami akan memperkenalkan persepsi pemandangan 3D yang penting dalam pemanduan autonomi. Kerana maklumat kedalaman, saiz tiga dimensi sasaran, dsb. tidak boleh diperoleh dalam persepsi 2D, dan maklumat ini adalah kunci untuk sistem pemanduan autonomi untuk membuat pertimbangan yang betul terhadap persekitaran sekeliling. Cara paling langsung untuk mendapatkan maklumat 3D adalah dengan menggunakan LiDAR. Walau bagaimanapun, LiDAR juga mempunyai kelemahannya, seperti kos yang lebih tinggi, kesukaran dalam pengeluaran besar-besaran produk gred automotif, kesan yang lebih besar daripada cuaca, dsb. Oleh itu, persepsi 3D berdasarkan kamera masih merupakan hala tuju penyelidikan yang sangat bermakna dan berharga Seterusnya, kami menyusun beberapa algoritma persepsi 3D berdasarkan monokular dan binokular.
Memperhatikan persekitaran 3D berdasarkan imej kamera tunggal adalah masalah yang tidak baik, tetapi ia boleh diselesaikan melalui andaian geometri (seperti sebagai piksel di atas tanah), Pengetahuan terdahulu atau beberapa maklumat tambahan (seperti anggaran kedalaman) boleh digunakan untuk membantu dalam menyelesaikan masalah. Kali ini kami akan memperkenalkan algoritma yang berkaitan bermula daripada dua tugas asas untuk merealisasikan pemanduan autonomi (pengesanan sasaran 3D dan anggaran kedalaman).
1.1 Pengesanan sasaran 3D
Penukaran perwakilan (pseudo lidar): Pengesanan kenderaan sekeliling lain, dsb. oleh penderia visual biasanya Apabila menghadapi masalah seperti oklusi dan ketidakupayaan untuk mengukur jarak, pandangan perspektif boleh ditukar kepada perwakilan pandangan mata burung. Dua kaedah transformasi diperkenalkan di sini. Yang pertama ialah pemetaan perspektif songsang (IPM), yang menganggap bahawa semua piksel berada di atas tanah dan parameter luaran kamera adalah tepat Pada masa ini, transformasi Homografi boleh digunakan untuk menukar imej kepada BEV, dan kemudian kaedah berdasarkan Rangkaian YOLO digunakan untuk mengesan rangka tanah sasaran . Yang kedua ialah Orthogonal Feature Transform (OFT), yang menggunakan ResNet-18 untuk mengekstrak ciri imej perspektif. Ciri berasaskan Voxel kemudiannya dijana dengan mengumpul ciri berasaskan imej ke atas kawasan voxel yang diunjurkan.
Ciri voxel kemudiannya dilipat secara menegak untuk menghasilkan ciri satah tanah ortogon. Akhir sekali, satu lagi rangkaian atas ke bawah yang serupa dengan ResNet digunakan untuk pengesanan objek 3D. Kaedah ini hanya sesuai untuk kenderaan dan pejalan kaki yang berhampiran dengan tanah. Untuk sasaran bukan darat seperti tanda lalu lintas dan lampu isyarat, awan titik pseudo boleh dijana melalui anggaran kedalaman untuk pengesanan 3D. Pseudo-LiDAR mula-mula menggunakan hasil anggaran kedalaman untuk menjana awan titik, dan kemudian secara langsung menggunakan pengesan sasaran 3D berasaskan lidar untuk menjana bingkai sasaran 3D Aliran algoritma ditunjukkan dalam rajah di bawah,

Isi penting dan model 3D: Saiz dan bentuk sasaran yang akan dikesan, seperti kenderaan dan pejalan kaki, adalah secara relatifnya tetap dan diketahui sasaran. DeepMANTA adalah salah satu karya perintis ke arah ini. Pertama, beberapa algoritma pengesanan sasaran seperti Faster RNN digunakan untuk mendapatkan bingkai sasaran 2D dan juga mengesan titik utama sasaran. Kemudian, bingkai sasaran 2D dan titik utama ini dipadankan dengan pelbagai model CAD kenderaan 3D dalam pangkalan data, dan model yang mempunyai persamaan tertinggi dipilih sebagai output pengesanan sasaran 3D. MonoGRNet mencadangkan untuk membahagikan pengesanan sasaran 3D monokular kepada empat langkah: Pengesanan sasaran 2D, anggaran kedalaman peringkat contoh, anggaran pusat 3D yang diunjurkan dan regresi sudut tempatan Aliran algoritma ditunjukkan dalam rajah di bawah. Kaedah jenis ini mengandaikan bahawa sasaran mempunyai model bentuk yang agak tetap, yang secara amnya memuaskan untuk kenderaan, tetapi agak sukar untuk pejalan kaki.
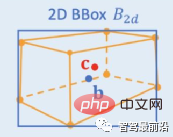
Kekangan geometri 2D/3D: Mengundur unjuran pusat 3D dan kedalaman contoh kasar, dan gunakan kedua-duanya untuk menganggar kedudukan 3D yang kasar. Kerja perintis ialah Deep3DBox, yang pertama kali menggunakan ciri imej dalam kotak sasaran 2D untuk menganggarkan saiz dan orientasi sasaran. Kemudian, kedudukan 3D titik tengah diselesaikan melalui kekangan geometri 2D/3D. Kekangan ini ialah unjuran bingkai sasaran 3D pada imej dikelilingi rapat oleh bingkai sasaran 2D, iaitu, sekurang-kurangnya satu titik sudut bingkai sasaran 3D boleh ditemui pada setiap sisi bingkai sasaran 2D. Melalui saiz dan orientasi yang diramalkan sebelum ini, digabungkan dengan parameter penentukuran kamera, kedudukan 3D titik tengah boleh dikira. Kekangan geometri antara kotak sasaran 2D dan 3D ditunjukkan dalam rajah di bawah. Shift R-CNN menggabungkan kotak sasaran 2D yang diperoleh sebelum ini, kotak sasaran 3D dan parameter kamera sebagai input berdasarkan Deep3DBox dan menggunakan rangkaian yang disambungkan sepenuhnya untuk meramalkan kedudukan 3D yang lebih tepat.
Menjana 3DBox secara langsung: Kaedah ini bermula dari kotak calon sasaran 3D yang padat dan menjaringkan semua kotak calon berdasarkan ciri pada imej 2D Kotak calon dengan markah tertinggi ialah output akhir. Agak serupa dengan kaedah tetingkap gelongsor tradisional dalam pengesanan sasaran. Algoritma Mono3D yang mewakili mula-mula menghasilkan kotak calon 3D yang padat berdasarkan kedudukan awal sasaran (koordinat z berada di atas tanah) dan saiz. Selepas bingkai calon 3D ini diunjurkan kepada koordinat imej, ia dijaringkan dengan menyepadukan ciri pada imej 2D, dan kemudian pusingan kedua pemarkahan dilakukan melalui CNN untuk mendapatkan bingkai sasaran 3D terakhir.
M3D-RPN ialah kaedah berasaskan Anchor yang mentakrifkan Anchor 2D dan 3D. Sauh 2D diperoleh melalui pensampelan padat pada imej, dan Sauh 3D ditentukan melalui pengetahuan terdahulu data set latihan (seperti min saiz sebenar sasaran). M3D-RPN juga menggunakan kedua-dua lilitan standard dan lilitan Depth-Aware. Yang pertama mempunyai invarian spatial, dan yang kedua membahagikan baris (koordinat Y) imej kepada berbilang kumpulan Setiap kumpulan sepadan dengan kedalaman pemandangan yang berbeza dan diproses oleh kernel lilitan yang berbeza. Kaedah pensampelan padat di atas adalah sangat intensif dari segi pengiraan. SS3D menggunakan pengesanan satu peringkat yang lebih cekap, termasuk CNN untuk mengeluarkan perwakilan berlebihan bagi setiap objek yang berkaitan dalam imej dan anggaran ketidakpastian yang sepadan, dan pengoptimum kotak sempadan 3D. FCOS3D juga merupakan kaedah pengesanan satu peringkat Sasaran regresi menambah pusat 2.5D tambahan (X, Y, Kedalaman) yang diperoleh dengan menayangkan pusat bingkai sasaran 3D ke imej 2D.
1.2 Anggaran Kedalaman
Sama ada pengesanan sasaran 3D yang disebutkan di atas atau satu lagi tugas penting persepsi pemanduan autonomi - pembahagian semantik, yang bermula daripada 2D ke 3D, Lagi atau kurang maklumat kedalaman yang jarang atau padat digunakan. Kepentingan anggaran kedalaman bermata adalah jelas Inputnya ialah imej, dan output adalah imej dengan saiz yang sama yang terdiri daripada nilai kedalaman pemandangan yang sepadan dengan setiap piksel. Input juga boleh menjadi urutan video, menggunakan maklumat tambahan yang dibawa oleh kamera atau gerakan objek untuk meningkatkan ketepatan anggaran kedalaman. Berbanding dengan pembelajaran diselia, kaedah anggaran kedalaman monokular tanpa pengawasan tidak memerlukan pembinaan set data kebenaran tanah yang mencabar dan kurang sukar untuk dilaksanakan. Kaedah tanpa pengawasan untuk anggaran kedalaman monokular boleh dibahagikan kepada dua jenis: berdasarkan jujukan video monokular dan berdasarkan pasangan imej stereo yang disegerakkan.
Yang pertama adalah berdasarkan andaian kamera bergerak dan adegan statik. Dalam kaedah terakhir, Garg et al mula-mula cuba menggunakan pasangan imej binokular yang diperbetulkan stereo pada masa yang sama untuk pembinaan semula imej Hubungan pose antara pandangan kiri dan kanan diperoleh melalui penentuan binokular, dan kesan yang agak ideal telah dicapai. Atas dasar ini, Godard et al menggunakan kekangan konsisten kiri dan kanan untuk meningkatkan lagi ketepatan Walau bagaimanapun, semasa mengekstrak ciri lanjutan dengan pensampelan ke bawah lapisan demi lapisan untuk meningkatkan medan penerimaan, resolusi ciri juga sentiasa menurun, dan butirannya. sentiasa hilang, menjejaskan pemprosesan butiran mendalam dan kejelasan tepi.
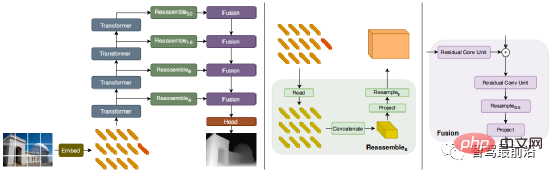
Untuk mengurangkan masalah ini, Godard et al memperkenalkan kehilangan berskala resolusi penuh, yang secara berkesan mengurangkan lubang hitam dan artifak replikasi tekstur di kawasan bertekstur rendah. Walau bagaimanapun, peningkatan dalam ketepatan ini masih terhad. Baru-baru ini, beberapa model berasaskan Transformer telah muncul dalam aliran yang tidak berkesudahan, bertujuan untuk mendapatkan medan penerimaan global dalam semua peringkat, yang juga sangat sesuai untuk tugas anggaran kedalaman intensif. Dalam DPT yang diselia, adalah dicadangkan untuk menggunakan Transformer dan struktur berbilang skala untuk memastikan ketepatan tempatan dan ketekalan ramalan global Rajah berikut ialah rajah struktur rangkaian.
Penglihatan binokular boleh menyelesaikan kekaburan yang disebabkan oleh transformasi perspektif, jadi secara teorinya Ia dikatakan bahawa ia boleh meningkatkan ketepatan persepsi 3D. Walau bagaimanapun, sistem binokular mempunyai keperluan yang agak tinggi dari segi perkakasan dan perisian. Dari segi perkakasan, dua kamera yang didaftarkan dengan tepat diperlukan, dan ketepatan pendaftaran mesti dipastikan semasa pengendalian kenderaan. Dari segi perisian, algoritma perlu memproses data daripada dua kamera pada masa yang sama Kerumitan pengiraan adalah tinggi, dan prestasi masa nyata algoritma sukar untuk dijamin. Berbanding dengan monokular, kerja binokular agak kurang. Seterusnya, kami juga akan memberikan pengenalan ringkas daripada dua aspek pengesanan sasaran 3D dan anggaran kedalaman.
2.1 Pengesanan sasaran 3D
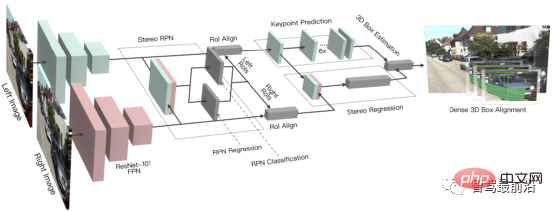
3DOP ialah kaedah pengesanan dua peringkat dan pengembangan kaedah R-CNN Pantas dalam medan 3D. Pertama, imej binokular digunakan untuk menjana peta kedalaman Peta kedalaman ditukar menjadi awan titik dan kemudian dikira ke dalam struktur data grid Ini kemudiannya digunakan sebagai input untuk menjana bingkai calon untuk sasaran 3D. Sama seperti Pseudo-LiDAR yang diperkenalkan sebelum ini, peta kedalaman padat (daripada LiDAR bermata, binokular atau malah nombor garis rendah) ditukar kepada awan titik, dan kemudian algoritma dalam bidang pengesanan sasaran awan titik digunakan. DSGN menggunakan pemadanan stereo untuk membina volum imbasan planar dan menukarnya kepada geometri 3D untuk mengekod geometri 3D dan maklumat semantik Ia merupakan rangka kerja hujung ke hujung yang boleh mengekstrak ciri tahap piksel untuk ciri pemadanan stereo dan pengecaman objek lanjutan , dan boleh menganggarkan kedalaman pemandangan secara serentak dan mengesan objek 3D. R-CNN Stereo memanjangkan R-CNN Lebih Pantas untuk input stereo untuk mengesan dan mengaitkan objek dalam pandangan kiri dan kanan secara serentak. Cawangan tambahan ditambah selepas RPN untuk meramalkan titik utama, sudut pandangan dan saiz objek yang jarang, dan menggabungkan kotak sempadan 2D dalam pandangan kiri dan kanan untuk mengira kotak sempadan objek 3D kasar. Kemudian, kotak sempadan 3D yang tepat dipulihkan dengan menggunakan penjajaran fotometrik berasaskan rantau bagi kawasan kiri dan kanan yang diminati. Rajah di bawah ialah struktur rangkaiannya.
2.2 Anggaran Kedalaman
Prinsip anggaran kedalaman binokular adalah sangat mudah, iaitu berdasarkan jarak antara yang sama Titik 3D pada pandangan kiri dan kanan Jarak piksel d (dengan mengandaikan kedua-dua kamera kekal pada ketinggian yang sama, jadi hanya jarak dalam arah mendatar dipertimbangkan), iaitu, perbezaan, jarak fokus f kamera, dan jarak B (panjang garis dasar) antara dua kamera, untuk menganggarkan kedalaman titik 3D, Formulanya adalah seperti berikut, dan kedalaman boleh dikira dengan menganggarkan paralaks. Kemudian, apa yang anda perlu lakukan ialah mencari titik padanan pada imej lain untuk setiap piksel.

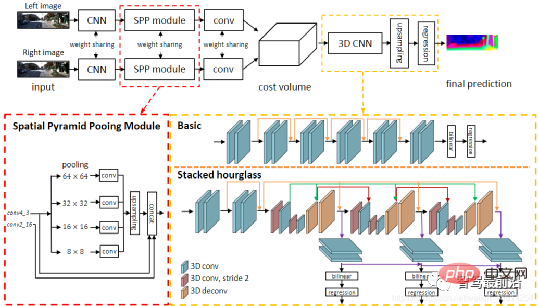
Untuk setiap kemungkinan d, ralat padanan pada setiap piksel boleh dikira, jadi data ralat tiga dimensi Jumlah Kos diperoleh. Melalui Volum Kos, kita boleh mendapatkan perbezaan pada setiap piksel dengan mudah (d sepadan dengan ralat pemadanan minimum), dan dengan itu memperoleh nilai kedalaman. MC-CNN menggunakan rangkaian saraf konvolusi untuk meramalkan tahap padanan dua tampalan imej dan menggunakannya untuk mengira kos pemadanan stereo. Kos diperhalusi melalui pengagregatan kos berasaskan persimpangan dan padanan separa global, diikuti dengan semakan konsistensi kiri-kanan untuk menghapuskan ralat di kawasan tersumbat. PSMNet mencadangkan rangka kerja pembelajaran hujung ke hujung untuk pemadanan stereo yang tidak memerlukan sebarang pasca pemprosesan, memperkenalkan modul pengumpulan piramid untuk menggabungkan maklumat konteks global ke dalam ciri imej, dan menyediakan CNN 3D jam pasir bertindan untuk mempertingkatkan lagi maklumat global. Rajah di bawah ialah struktur rangkaiannya.
Atas ialah kandungan terperinci Perbincangan mendalam tentang algoritma persepsi visual 2D dan 3D dalam pemanduan autonomi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Algoritma penggantian halaman
Algoritma penggantian halaman
 Penyelesaian kepada ralat sintaks prosedur sql
Penyelesaian kepada ralat sintaks prosedur sql
 apa itu nodejs
apa itu nodejs
 Pembayaran tanpa kata laluan Taobao
Pembayaran tanpa kata laluan Taobao
 pangkalan data phpstudy tidak boleh memulakan penyelesaian
pangkalan data phpstudy tidak boleh memulakan penyelesaian
 Perisian ujian bateri komputer riba manakah yang terbaik?
Perisian ujian bateri komputer riba manakah yang terbaik?
 matematik.penggunaan fungsi rawak
matematik.penggunaan fungsi rawak
 MySQL mencipta prosedur tersimpan
MySQL mencipta prosedur tersimpan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



