


Kohort secara literal bermaksud sekumpulan orang (dengan ciri yang sama atau tingkah laku yang serupa), seperti jantina yang berbeza dan umur yang berbeza.
Analisis kohort: Membandingkan perubahan dalam kumpulan yang serupa dari semasa ke semasa.
Produk akan terus berulang semasa anda membangunkan dan mengujinya, yang menyebabkan pengguna yang menyertai minggu pertama keluaran produk mempunyai pengalaman yang berbeza daripada mereka yang menyertai kemudian. Sebagai contoh, setiap pengguna akan melalui kitaran hayat: daripada percubaan percuma, kepada penggunaan berbayar, dan akhirnya berhenti menggunakannya. Pada masa yang sama, dalam tempoh ini, anda sentiasa membuat pelarasan pada model perniagaan anda. Oleh itu, pengguna yang "makan ketam" pada bulan pertama selepas produk dilancarkan pasti mempunyai pengalaman onboarding yang berbeza daripada pengguna yang menyertai selepas empat bulan. Apakah kesan ini terhadap kadar churn? Kami menggunakan analisis kohort untuk mengetahui.
Setiap kumpulan pengguna membentuk kohort dan mengambil bahagian dalam keseluruhan proses percubaan. Dengan membandingkan kohort yang berbeza, anda boleh mengetahui sama ada prestasi keseluruhan pada metrik utama semakin baik.
Digabungkan dengan tahap analisis pengguna, seperti pengguna yang diperoleh dalam bulan berbeza, pengguna baharu dari saluran berbeza, pengguna dengan ciri berbeza (seperti pengguna dalam WeChat yang berkomunikasi dengan sekurang-kurangnya 10 rakan di WeChat setiap hari).
Analisis Kohort ialah analisis perbandingan kumpulan orang ini dengan ciri yang berbeza untuk menemui perbezaan tingkah laku mereka dalam dimensi masa.
Oleh itu, analisis kohort digunakan terutamanya untuk dua perkara berikut:
Bandingkan penunjuk data kumpulan kohort yang berbeza dalam kitaran pengalaman yang sama untuk mengesahkan kesan produk pengoptimuman lelaran
Membandingkan penunjuk data kitaran pengalaman yang berbeza (kitaran hayat) kumpulan kohort yang sama, kami mendapati masalah pengalaman jangka panjang
Kami sedang menjalankan masa analisis kohort, boleh dibahagikan secara kasar kepada dua proses: menentukan kohort logik kumpulan dan menentukan penunjuk data utama untuk analisis kohort.
Kumpulan dengan ciri tingkah laku yang serupa
Kumpulan dengan tempoh masa yang sama
Contohnya:
Mengikut bulan pemerolehan pelanggan (dikumpulkan mengikut minggu atau bahkan hari)
Mengikut saluran pemerolehan pelanggan
Kategori berdasarkan tindakan khusus yang diselesaikan oleh pengguna, seperti bilangan kali pengguna melawati tapak web atau bilangan pembelian.
Mengenai penunjuk data utama, penunjuk tersebut perlu berdasarkan dimensi masa, seperti pengekalan, hasil, pekali perambatan sendiri, dsb.
Berikut ialah contoh kes yang menggunakan kadar pengekalan sebagai penunjuk:
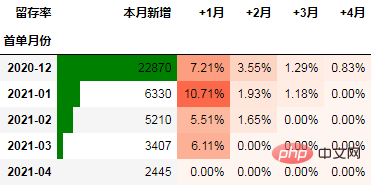
Berikut ialah data operasi syarikat e-dagang Kami akan menggunakan data ini untuk menunjukkan menggunakan analisis Cohort python.
Penjelasan terperinci kes analisis kohort:
Data ialah log pembayaran pengguna e-dagang Medan log termasuk tarikh, jumlah pembayaran dan ID pengguna, yang mempunyai telah desensitized.
import pandas as pd df = pd.read_csv('日志.csv', encoding="gb18030") df.head()
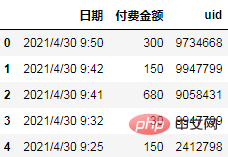
Logik kumpulan:
Di sini kami hanya mengikut awal pengguna Himpunkan mengikut bulan pembelian Jika log mengandungi lebih banyak medan klasifikasi (seperti saluran, jantina atau umur, dsb.), anda boleh mempertimbangkan lebih banyak logik pengumpulan.
Penunjuk data utama:
Untuk data ini, terdapat sekurang-kurangnya 3 penunjuk data yang boleh dianalisis:
Kadar Pengekalan
Amaun pembayaran per kapita
Bilangan pembelian per kapita
df['购买月份'] = pd.to_datetime(df.日期).dt.to_period("M")
df.head()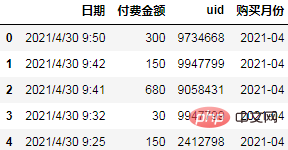 Kira bulan pembelian pertama setiap pengguna sebagai kumpulan kohort yang sama dan petakannya kepada data asal:
Kira bulan pembelian pertama setiap pengguna sebagai kumpulan kohort yang sama dan petakannya kepada data asal:
order = df.groupby(["uid", "购买月份"], as_index=False).agg(
月付费总额=("付费金额","sum"),
月付费次数=("uid","count"),
)
order.head()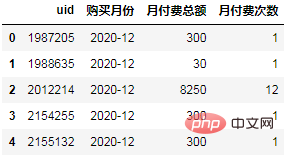 Kira perbezaan bulan antara masa setiap rekod pembelian dan masa pembelian pertama, dan tetapkan semula label perbezaan bulan:
Kira perbezaan bulan antara masa setiap rekod pembelian dan masa pembelian pertama, dan tetapkan semula label perbezaan bulan:
order["首单月份"] = order.groupby("uid")['购买月份'].transform("min")
order.head()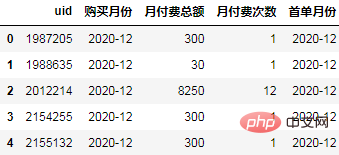
order["标签"] = (order.购买月份-order.首单月份).apply(lambda x:"同期群人数" if x.n==0 else f"+{x.n}月")
order.head()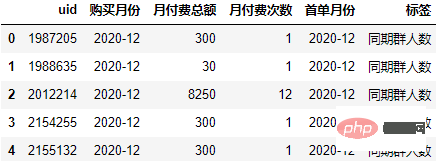 Analisis kohort
Analisis kohort
Seperti yang kami nyatakan sebelum ini, terdapat sekurang-kurangnya 3 penunjuk data yang boleh dianalisis: Kadar pengekalan
Jumlah bayaran setiap orang
Bilangan pembelian setiap orang
通过数据透视表可以一次性计算所需的数据:
cohort_number = order.pivot_table(index="首单月份", columns="标签",
values="uid", aggfunc="count",
fill_value=0).rename_axis(columns="留存率")
cohort_number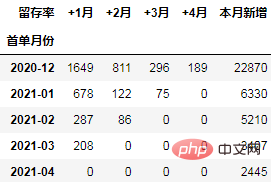
注意:rename_axis(columns=None)用于删除列标签的轴名称。rename_axis(columns=“留存率”)则设置轴名称为留存率。
将 本月新增 列移动到第一列:
cohort_number.insert(0, "同期群人数", cohort_number.pop("同期群人数"))
cohort_number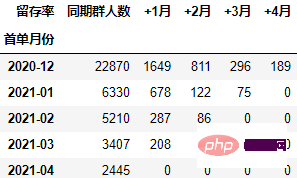
具体过程是先通过pop删除该列,然后插入到0位置,并命名为指定的列名。
在本次的分析中,留存率的具体计算方式为:+N月留存率=+N月付款用户数/首月付款用户数
cohort_number.iloc[:, 1:] = cohort_number.iloc[:, 1:].divide(cohort_number.本月新增, axis=0) cohort_number
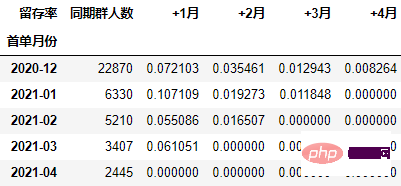
以百分比形式显示,并设置颜色:
out1 = (cohort_number.style
.format("{:.2%}", subset=cohort_number.columns[1:])
.bar(subset="同期群人数", color="green")
.background_gradient("Reds", subset=cohort_number.columns[1:], high=1, axis=None)
)
out1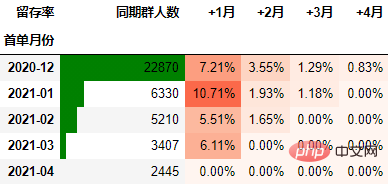
至此计算完毕。
要从从人均付款金额角度考虑,需要考虑同期群基期这个整体。具体计算方式是先计算各月的付款总额,然后除以基期的总人数:
cohort_amount = order.pivot_table(index="首单月份", columns="标签",
values="月付费总额", aggfunc="sum",
fill_value=0).rename_axis(columns="人均付款金额")
cohort_amount.insert(0, "首月人均付费", cohort_amount.pop("同期群人数"))
cohort_amount.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_amount.iloc[:, 1:] = cohort_amount.iloc[:, 1:].divide(cohort_amount.同期群人数, axis=0)
out2 = (cohort_amount.style
.format("{:.2f}", subset=cohort_amount.columns[1:])
.background_gradient("Reds", subset=cohort_amount.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
out2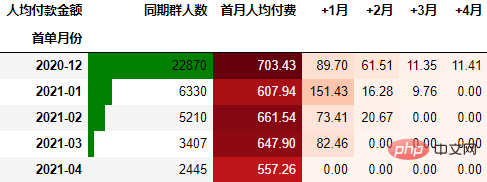
可以看到,12月份的同期群首月新用户人均消费为703.43元,然后逐月递减,到+4月后这些用户人均消费仅11.41元。而随着版本的迭代发展,新增用户的首月消费并没有较大提升,且接下来的消费趋势反而不如12月份。由此可见产品的发展受到了一定的瓶颈,需要思考增长营收的出路了。
一般来说, 通过同期群分析可以比较好指导我们后续更深入细致的数据分析,为产品优化提供参考。
依然按照上面一样的套路:
cohort_count = order.pivot_table(index="首单月份", columns="标签",
values="月付费次数", aggfunc="sum",
fill_value=0).rename_axis(columns="人均购买次数")
cohort_count.insert(0, "首月人均频次", cohort_count.pop("同期群人数"))
cohort_count.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_count.iloc[:, 1:] = cohort_count.iloc[:,
1:].divide(cohort_count.同期群人数, axis=0)
out3 = (cohort_count.style
.format("{:.2f}", subset=cohort_count.columns[1:])
.background_gradient("Reds", subset=cohort_count.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
out3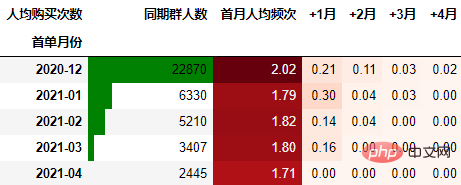
可以得到类似上述一致的结论。
下面我们看看每个月的总体消费情况:
order.groupby("购买月份").agg(
付费人数=("uid", "count"),
人均付款金额=("月付费总额", "mean"),
月付费总额=("月付费总额", "sum")
)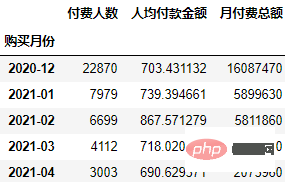
可以看到总体付费人数和付费金额都在逐月下降。
对于Styler类型,我们可以调用render方法转化为网页源代码,通过以下方式即可将其导入到一个网页文件中:
with open("out.html", "w") as f:
f.write(out1.render())
f.write(out2.render())
f.write(out3.render())如果你的电脑安装了谷歌游览器,还可以安装dataframe_image,将这个表格导出为图片。
安装:pip install dataframe_image
import dataframe_image as dfi dfi.export(obj=out1, filename='留存率.jpg') dfi.export(obj=out2, filename='人均付款金额.jpg') dfi.export(obj=out3, filename='人均购买次数.jpg')
dfi.export的参数:
obj : 被导出的Datafream对象
filename : 文件保存位置
fontsize : 字体大小
max_rows : 最大行数
max_cols : 最大列数
table_conversion : 使用谷歌游览器或原生’matplotlib’, 只要写非’chrome’的值就会使用原生’matplotlib’
chrome_path : 指定谷歌游览器位置
import pandas as pd
import dataframe_image as dfi
df = pd.read_csv('日志.csv', encoding="gb18030")
df['购买月份'] = pd.to_datetime(df.日期).dt.to_period("M")
order = df.groupby(["uid", "购买月份"], as_index=False).agg(
月付费总额=("付费金额", "sum"),
月付费次数=("uid", "count"),
)
order["首单月份"] = order.groupby("uid")['购买月份'].transform("min")
order["标签"] = (
order.购买月份-order.首单月份).apply(lambda x: "同期群人数" if x.n == 0 else f"+{x.n}月")
cohort_number = order.pivot_table(index="首单月份", columns="标签",
values="uid", aggfunc="count",
fill_value=0).rename_axis(columns="留存率")
cohort_number.insert(0, "同期群人数", cohort_number.pop("同期群人数"))
cohort_number.iloc[:, 1:] = cohort_number.iloc[:,1:].divide(cohort_number.同期群人数, axis=0)
out1 = (cohort_number.style
.format("{:.2%}", subset=cohort_number.columns[1:])
.bar(subset="同期群人数", color="green")
.background_gradient("Reds", subset=cohort_number.columns[1:], high=1, axis=None)
)
cohort_amount = order.pivot_table(index="首单月份", columns="标签",
values="月付费总额", aggfunc="sum",
fill_value=0).rename_axis(columns="人均付款金额")
cohort_amount.insert(0, "首月人均付费", cohort_amount.pop("同期群人数"))
cohort_amount.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_amount.iloc[:, 1:] = cohort_amount.iloc[:, 1:].divide(cohort_amount.同期群人数, axis=0)
out2 = (cohort_amount.style
.format("{:.2f}", subset=cohort_amount.columns[1:])
.background_gradient("Reds", subset=cohort_amount.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
cohort_count = order.pivot_table(index="首单月份", columns="标签",
values="月付费次数", aggfunc="sum",
fill_value=0).rename_axis(columns="人均购买次数")
cohort_count.insert(0, "首月人均频次", cohort_count.pop("同期群人数"))
cohort_count.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_count.iloc[:, 1:] = cohort_count.iloc[:,
1:].divide(cohort_count.同期群人数, axis=0)
out3 = (cohort_count.style
.format("{:.2f}", subset=cohort_count.columns[1:])
.background_gradient("Reds", subset=cohort_count.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
outs = [out1, out2, out3]
with open("out.html", "w") as f:
for out in outs:
f.write(out.render())
display(out)
dfi.export(obj=out1, filename='留存率.jpg')
dfi.export(obj=out2, filename='人均付款金额.jpg')
dfi.export(obj=out3, filename='人均购买次数.jpg')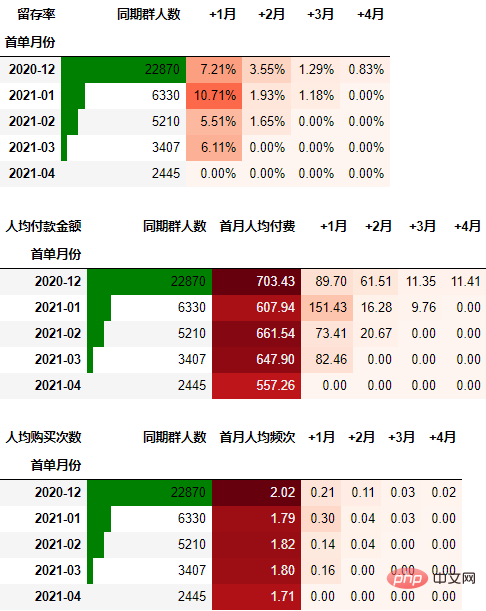
Atas ialah kandungan terperinci Bagaimana untuk menggunakan Python dalam analisis kohort. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!





























![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



