


Dalam era maklumat hari ini, imej atau kandungan visual telah lama menjadi pembawa maklumat yang paling penting dalam kehidupan harian model pembelajaran mendalam bergantung pada keupayaan kuat mereka untuk memahami kandungan visual dan boleh Pelbagai pemprosesan dan pengoptimuman.
Walau bagaimanapun, dalam pembangunan dan aplikasi model visual yang lalu, kami memberi lebih perhatian kepada pengoptimuman model itu sendiri untuk meningkatkan kelajuan dan kesannya. Sebaliknya, untuk peringkat pra dan pasca pemprosesan imej, sedikit pemikiran serius diberikan kepada cara mengoptimumkannya. Oleh itu, apabila kecekapan pengiraan model semakin tinggi dan lebih tinggi, melihat kembali pada pra-pemprosesan dan pasca-pemprosesan imej, saya tidak menjangkakan bahawa ia telah menjadi hambatan kepada keseluruhan tugasan imej.
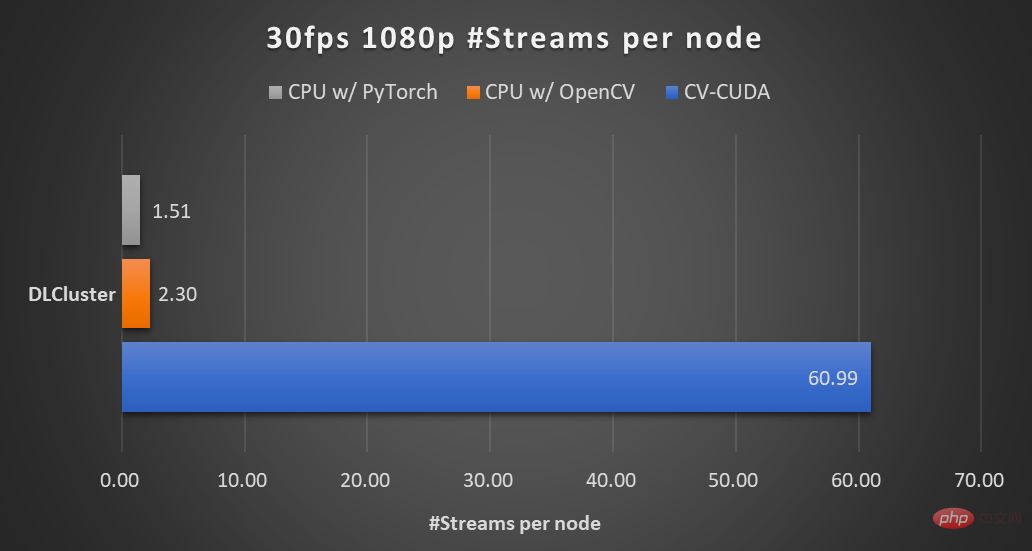
Untuk menyelesaikan kesesakan tersebut, NVIDIA telah bekerjasama dengan pasukan pembelajaran mesin ByteDance untuk membuka sumber banyak perpustakaan operator prapemprosesan imej CV-CUDA Mereka boleh berjalan dengan cekap pada GPU, dan kelajuan operator boleh mencapai kelajuan OpenCV (. berjalan pada CPU) Kira-kira seratus kali. Jika kami menggunakan CV-CUDA sebagai bahagian belakang untuk menggantikan OpenCV dan TorchVision, daya pemprosesan keseluruhan inferens boleh mencapai lebih daripada 20 kali ganda daripada asal. Selain itu, bukan sahaja kelajuan dipertingkatkan, tetapi dari segi kesan, CV-CUDA telah diselaraskan dengan OpenCV dari segi ketepatan pengiraan, jadi latihan dan inferens boleh disambungkan dengan lancar, mengurangkan beban kerja jurutera.
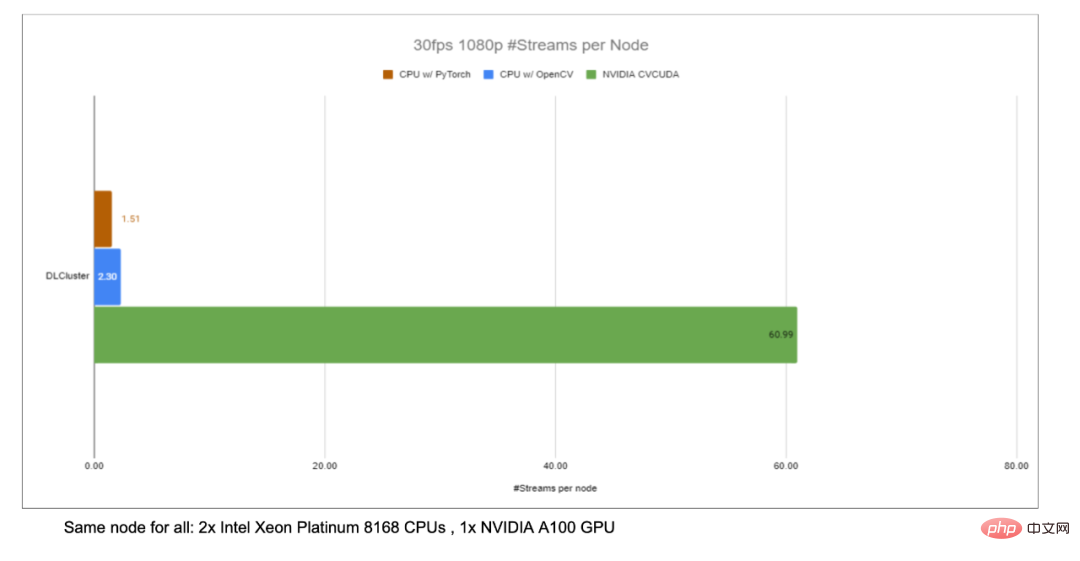
Mengambil algoritma kabur latar belakang imej sebagai contoh, CV-CUDA menggantikan OpenCV sebagai hujung belakang untuk pra/siaran imej -pemprosesan , pemprosesan keseluruhan proses penaakulan boleh ditingkatkan lebih daripada 20 kali ganda.
Jika anda ingin mencuba perpustakaan prapemprosesan visual yang lebih pantas dan lebih baik, anda boleh mencuba alat sumber terbuka ini. Alamat sumber terbuka: https://github.com/CVCUDA/CV-CUDA
Ramai jurutera algoritma yang terlibat dalam kejuruteraan dan produk tahu bahawa walaupun kita sering hanya membincangkan "penyelidikan canggih" seperti struktur model dan tugas latihan, dalam fakta yang kita perlukan Untuk membina produk yang boleh dipercayai, anda akan menghadapi banyak masalah kejuruteraan dalam proses, tetapi latihan model adalah bahagian yang paling mudah.
Prapemprosesan imej ialah masalah kejuruteraan. Kami mungkin hanya memanggil beberapa API untuk melakukan transformasi geometri, penapisan, transformasi warna, dll. pada imej semasa percubaan atau latihan, dan kami mungkin tidak mengambil berat mengenainya. Tetapi apabila kita memikirkan semula keseluruhan proses penaakulan, kita mendapati bahawa prapemprosesan imej telah menjadi hambatan prestasi, terutamanya untuk tugas visual dengan proses prapemprosesan yang kompleks.
Kesempitan prestasi seperti ini ditunjukkan terutamanya dalam CPU. Secara umumnya, untuk proses pemprosesan imej konvensional, kami akan melakukan prapemprosesan pada CPU dahulu, kemudian meletakkannya pada GPU untuk menjalankan model, dan akhirnya kembali ke CPU, dan mungkin perlu melakukan beberapa pemprosesan pasca.
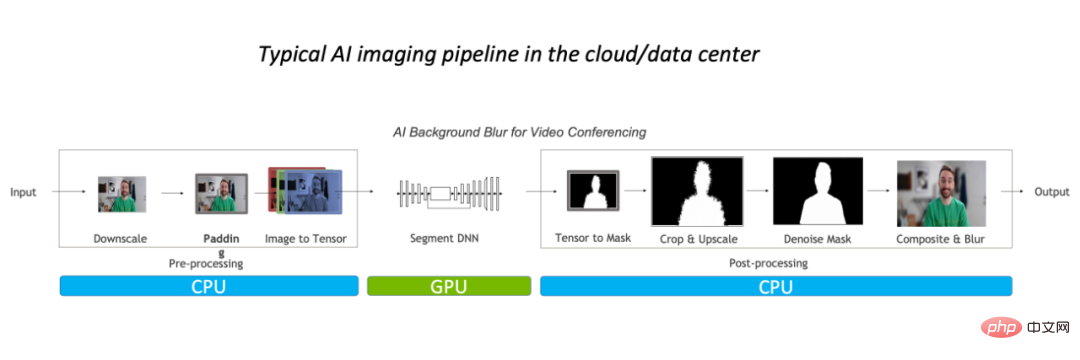
Mengambil algoritma kabur latar belakang imej sebagai contoh, dalam proses pemprosesan imej konvensional, pemprosesan prognostik diselesaikan terutamanya pada CPU, yang menduduki keseluruhan 90% daripada beban kerja, ia telah menjadi hambatan untuk tugas itu.
Oleh itu, untuk aplikasi video, atau adegan kompleks seperti pemodelan imej 3D, kerana bilangan bingkai imej atau maklumat imej cukup besar, proses prapemprosesan adalah cukup kompleks, dan Jika keperluan kependaman cukup rendah, pengoptimuman operator pra/pasca pemprosesan akan berlaku. Pendekatan yang lebih baik, sudah tentu, adalah menggantikan OpenCV dengan penyelesaian yang lebih pantas.
Mengapa OpenCV masih tidak cukup bagus?
Dalam CV, perpustakaan pemprosesan imej yang paling banyak digunakan sudah tentu OpenCV yang telah lama diselenggara Ia mempunyai rangkaian operasi pemprosesan imej yang sangat luas dan pada asasnya boleh memenuhi pelbagai visual tugasan pra/pasca pemprosesan. Walau bagaimanapun, apabila beban tugas imej meningkat, kelajuannya perlahan-lahan tidak dapat mengikuti, kerana kebanyakan operasi imej OpenCV dilaksanakan oleh CPU, kekurangan pelaksanaan GPU, atau terdapat beberapa masalah dengan pelaksanaan GPU.
Dalam pengalaman penyelidikan dan pembangunan pelajar algoritma NVIDIA dan ByteDance, mereka mendapati bahawa beberapa operator dalam OpenCV yang dilaksanakan oleh GPU mempunyai tiga masalah utama:
Melaksanakan pra dan pasca pemprosesan sepenuhnya pada GPU akan mengurangkan kesesakan CPU dalam bahagian pemprosesan imej dengan banyak.
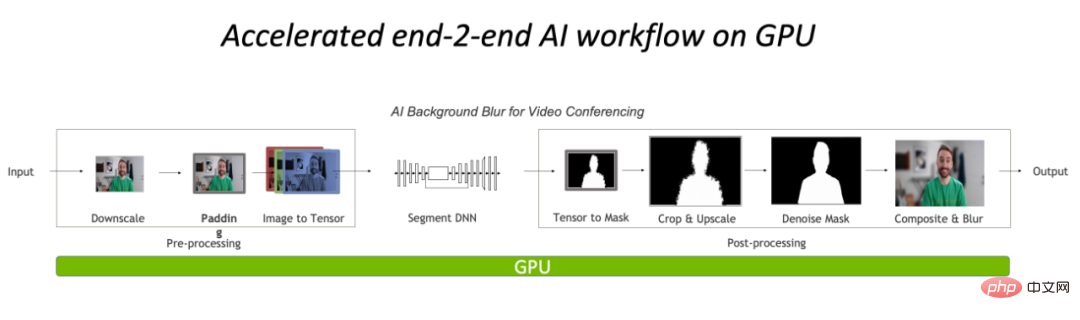
GPU Pustaka pecutan pemprosesan imej: CV-CUDA
Kelajuan CV-CUDA
CV -CUDA Kelajuan pertama kali ditunjukkan dalam pelaksanaan operator yang cekap Lagipun, ia ditulis oleh NVIDIA Kod pengkomputeran selari CUDA mesti telah melalui banyak pengoptimuman. Kedua, ia menyokong operasi kelompok, yang boleh menggunakan sepenuhnya kuasa pengkomputeran peranti GPU Berbanding dengan pelaksanaan bersiri imej satu demi satu pada CPU, operasi kelompok pastinya lebih pantas. Akhir sekali, terima kasih kepada seni bina GPU seperti Volta, Turing, dan Ampere yang disesuaikan dengan CV-CUDA, prestasi sangat dioptimumkan pada tahap kernel CUDA setiap GPU untuk mencapai hasil yang terbaik. Dalam erti kata lain, lebih baik kad GPU yang anda gunakan, lebih dibesar-besarkan keupayaan pecutannya. Seperti yang ditunjukkan dalam carta nisbah pecutan throughput kabur latar belakang sebelumnya, jika CV-CUDA digunakan untuk menggantikan pra dan pasca pemprosesan OpenCV dan TorchVision, daya pemprosesan keseluruhan proses inferens meningkat lebih daripada 20 kali ganda. Antaranya, prapemprosesan melakukan operasi seperti Saiz Saiz, Padding dan Image2Tensor pada imej, dan pasca pemprosesan melaksanakan operasi seperti Tensor2Mask, Crop, Resize dan Denoise pada hasil ramalan.
Untuk prestasi pengendali tunggal, NVIDIA dan rakan kongsi ByteDance juga telah menjalankan ujian prestasi Banyak pengendali pada GPU boleh mencapai seratus kali ganda daripada CPU . Saiz imej ialah 480*360, CPU ialah Intel(R) Core(TM) i9-7900X, saiz BatchSize ialah 1 dan bilangan proses ialah 1 Walaupun banyak operator pra/pasca pemprosesan bukanlah pendaraban matriks mudah dan operasi lain, untuk mencapai prestasi cekap yang disebutkan di atas, CV-CUDA sebenarnya telah melakukan banyak pengoptimuman di peringkat operator. Sebagai contoh, sebilangan besar strategi gabungan inti diguna pakai untuk mengurangkan masa akses pelancaran kernel dan akses memori global dioptimumkan untuk meningkatkan kecekapan membaca dan menulis data semua operator diproses secara tidak segerak untuk mengurangkan masa menunggu segerak, dsb . CV-CUDAumum dan fleksibel operasi Kestabilan keputusan adalah sangat penting untuk projek sebenar Contohnya, operasi Ubah Saiz biasa, OpenCV, OpenCV-gpu dan Torchvision dilaksanakan dengan cara yang berbeza, jadi dari latihan hingga penggunaan, akan ada lebih banyak kerja untuk menyelaraskan. keputusan. CV-CUDAkemudahan penggunaan mungkin ramai Jurutera akan berfikir, CV-CUDA melibatkan pengendali CUDA yang mendasari, jadi ia sepatutnya lebih sukar untuk digunakan? Tetapi ini tidak berlaku. Walaupun ia tidak bergantung pada API peringkat lebih tinggi, lapisan bawah CV-CUDA sendiri akan menyediakan struktur seperti dan kelas Allocator, jadi ia tidak menyusahkan untuk menyesuaikannya dalam C++. Di samping itu, pergi ke peringkat atas, CV-CUDA menyediakan antara muka penukaran data untuk PyTorch, OpenCV dan Pillow, jadi jurutera boleh menggantikan dan memanggil operator dengan cepat dengan cara yang biasa. Antara muka CV-CUDA C++ untuk Ubah Saiz Jika kita menggunakan antara muka Python CV-CUDA semasa proses latihan, ia sebenarnya akan menjadi sangat mudah untuk digunakan, ia hanya mengambil beberapa langkah mudah untuk memindahkan semua operasi prapemprosesan yang asalnya dilakukan pada CPU ke GPU. Proses pra-pemprosesan pengecaman imej konvensional, menggunakan CV-CUDA akan menyatukan proses pra-pemprosesan dan pengiraan model Run pada GPU. Seperti berikut, selepas menggunakan API torchvision untuk memuatkan imej ke GPU, jenis Torch Tensor boleh terus ditukar kepada objek CV-CUDA nvcvInputTensor melalui as_tensor, supaya API CV- Operasi prapemprosesan CUDA boleh dipanggil terus Pelbagai transformasi imej diselesaikan dalam GPU. Barisan kod berikut akan menggunakan CV-CUDA untuk melengkapkan proses prapemprosesan pengecaman imej dalam GPU: pangkas imej dan Normalkan piksel. Antaranya, resize() menukar tensor imej kepada saiz tensor input model convertto() menukar nilai piksel kepada nilai titik terapung ketepatan tunggal () menormalkan nilai piksel untuk menjadikan julat nilai lebih sesuai; model itu. Kini dengan bantuan pelbagai API CV-CUDA, prapemprosesan tugas pengelasan imej telah selesai. Ia boleh melengkapkan pengkomputeran selari pada GPU dengan cekap dan disepadukan dengan mudah ke dalam proses pemodelan rangka kerja pembelajaran mendalam arus perdana seperti PyTorch. Untuk selebihnya, anda hanya perlu menukar objek CV-CUDA nvcvPreprocessedTensor ke dalam jenis Torch Tensor untuk menyuapkannya kepada model Langkah ini juga sangat mudah Penukaran hanya memerlukan satu baris kod: Melalui contoh mudah ini, adalah mudah untuk mendapati bahawa CV-CUDA sememangnya mudah disematkan ke dalam logik latihan model biasa. Jika pembaca ingin mengetahui lebih banyak butiran penggunaan, mereka masih boleh menyemak alamat sumber terbuka CV-CUDA yang dinyatakan di atas. CV-CUDA sebenarnya telah melalui ujian praktikal perniagaan. Dalam tugas visual, terutamanya tugas dengan proses pra-pemprosesan imej yang agak kompleks, menggunakan kuasa pengkomputeran besar GPU untuk pra-pemprosesan boleh meningkatkan kecekapan latihan model dan inferens dengan berkesan. CV-CUDA kini digunakan dalam berbilang senario dalam talian dan luar talian dalam Kumpulan Douyin, seperti carian berbilang mod, klasifikasi imej, dsb. Dalam ByteDance OCR dan tugasan pelbagai mod video, dengan menggunakan CV-CUDA, kelajuan latihan keseluruhan boleh Ditingkatkan sebanyak 1 hingga 2 kali (nota: ia adalah peningkatan dalam kelajuan latihan keseluruhan model) Begitu juga dalam proses inferens pasukan pembelajaran mesin menyatakan bahawa dalam Selepas menggunakan CV-CUDA dalam tugasan berbilang modal carian, keseluruhan daya pengeluaran dalam talian telah dipertingkatkan lebih daripada 2 kali ganda berbanding dengan menggunakan CPU untuk prapemprosesan. Perlu diingat bahawa keputusan garis dasar CPU di sini sudah sangat dioptimumkan untuk berbilang teras, dan logik prapemprosesan yang terlibat dalam tugas ini agak mudah, tetapi kesan pecutan masih sangat jelas selepas menggunakan CV-CUDA.
Pada permulaan reka bentuk CV-CUDA, ia dianggap bahawa ramai jurutera sudah biasa menggunakan versi CPU OpenCV dalam perpustakaan pemprosesan imej semasa, oleh itu, apabila mereka bentuk operator, sama ada parameter fungsi atau pemprosesan imej hasil, selaraskan OpenCV sebanyak mungkin versi CPU pengendali. Oleh itu, apabila berhijrah daripada OpenCV ke CV-CUDA, hanya beberapa perubahan diperlukan untuk mendapatkan hasil pengkomputeran yang konsisten, dan model tidak perlu dilatih semula.
Selain itu, CV-CUDA direka dari peringkat operator, jadi tidak kira apa proses pra/pasca pemprosesan model, ia boleh digabungkan secara bebas dan mempunyai fleksibiliti yang tinggi.
Pasukan pembelajaran mesin ByteDance menyatakan bahawa terdapat banyak model yang dilatih dalam perusahaan, dan logik prapemprosesan yang diperlukan juga pelbagai, dengan banyak keperluan logik prapemprosesan tersuai. Fleksibiliti CV-CUDA boleh memastikan bahawa setiap OP menyokong masuk objek strim dan objek memori video (kelas Penampan dan Tensor, yang menyimpan penunjuk memori video secara dalaman), supaya sumber GPU yang sepadan boleh dikonfigurasikan dengan lebih fleksibel. Apabila mereka bentuk dan membangunkan setiap op, ia bukan sahaja mengambil kira fleksibiliti, tetapi juga menyediakan antara muka tersuai atas permintaan, meliputi pelbagai keperluan untuk prapemprosesan imej.
Selain itu, kerana CV-CUDA mempunyai antara muka C++ dan antara muka Python, ia boleh digunakan dalam kedua-dua latihan dan senario penggunaan perkhidmatan Antara muka Python digunakan untuk mengesahkan keupayaan model dengan cepat semasa latihan, dan antara muka C++ adalah digunakan untuk meramalkan penggunaan yang lebih cekap. CV-CUDA mengelakkan proses penjajaran hasil prapemprosesan yang menyusahkan dan meningkatkan kecekapan proses keseluruhan. 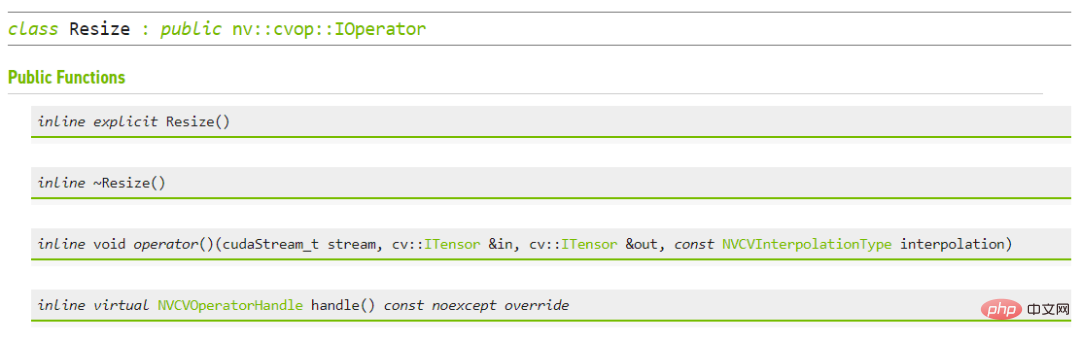
Pertempuran praktikal, CV-CUDACara menggunakan
Ambil klasifikasi imej sebagai contoh Pada asasnya, kita perlu menyahkod imej menjadi tensor dalam peringkat prapemprosesan dan memangkasnya agar sesuai dengan saiz input model Selepas pemangkasan, kita perlu menukar nilai piksel kepada data titik terapung jenis dan Selepas penormalan, ia boleh dihantar ke model pembelajaran mendalam untuk penyebaran ke hadapan. Di bawah ini kami akan menggunakan beberapa blok kod mudah untuk mengalami cara CV-CUDA pramemproses imej dan berinteraksi dengan Pytorch. 
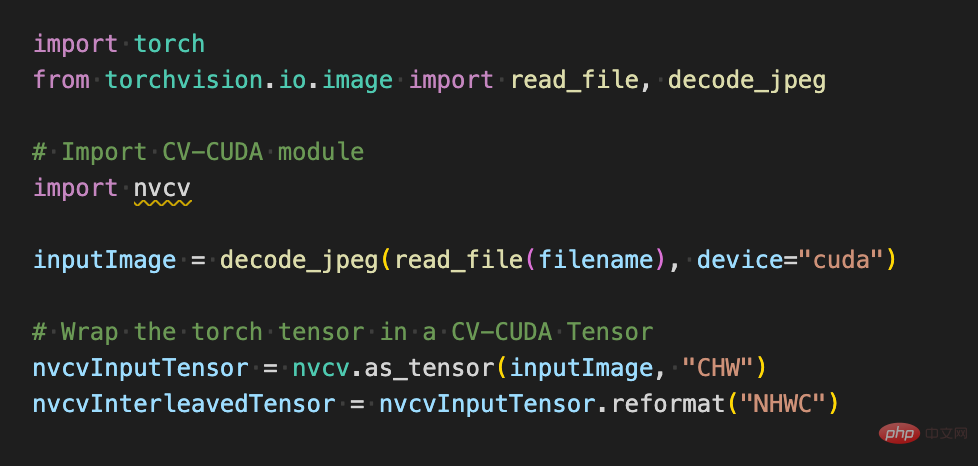
Penggunaan pelbagai operasi prapemprosesan dalam CV-CUDA tidak akan jauh berbeza daripada yang terdapat dalam OpenCV atau Torchvision Ia hanyalah pelarasan mudah kaedah, dan pengiraan sudah selesai pada GPU di belakangnya. 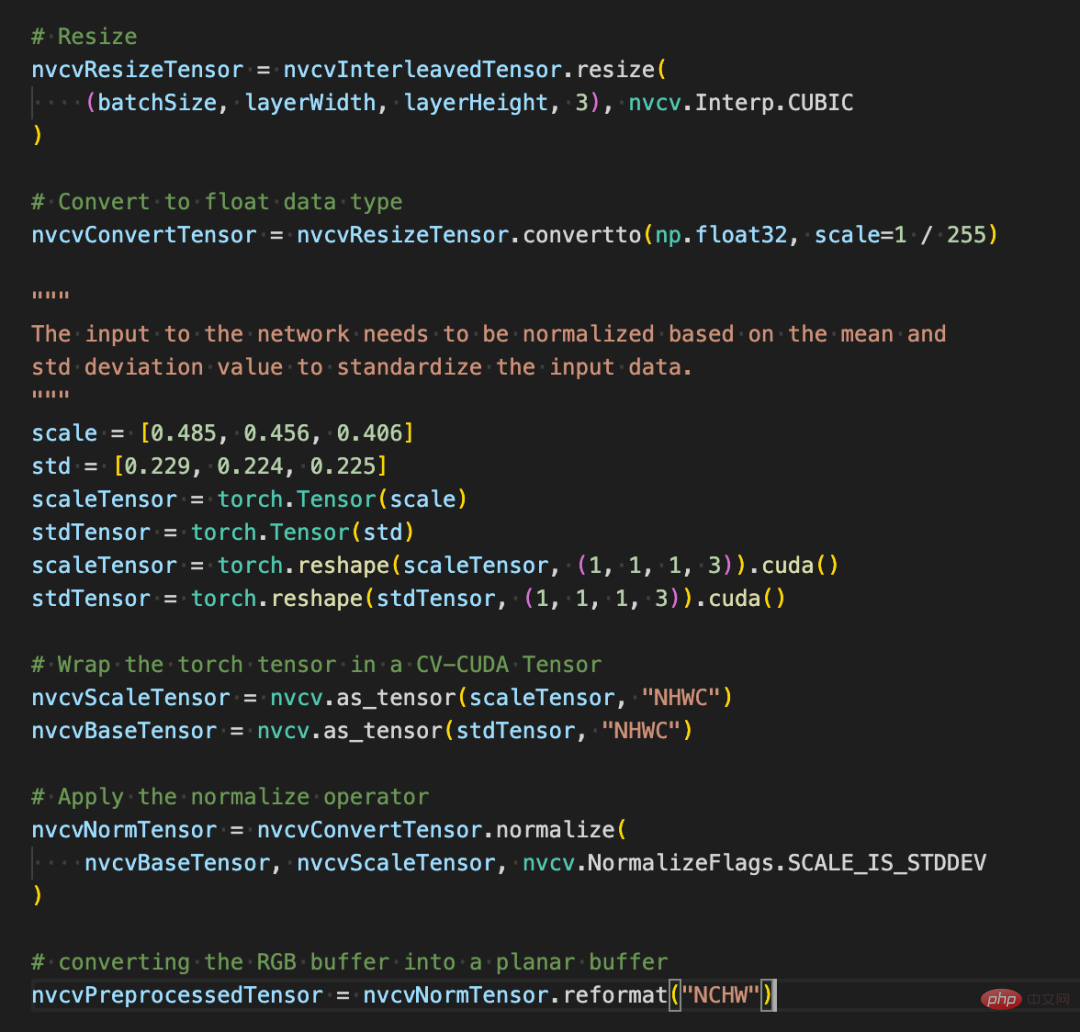
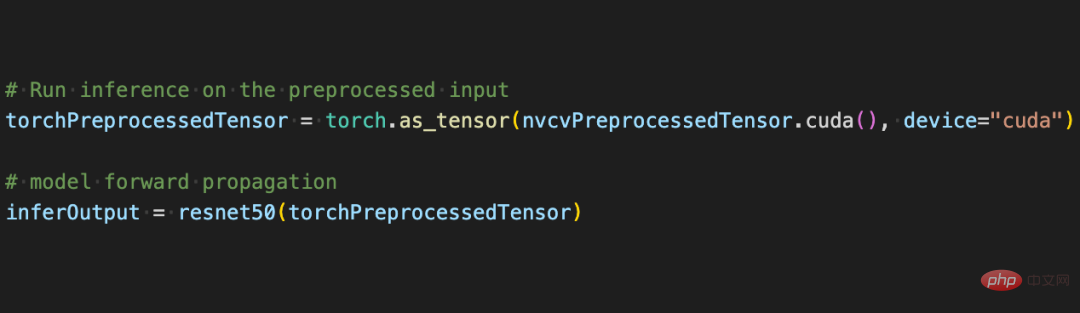
CV-CUDAPeningkatan perniagaan sebenar
Pasukan pembelajaran mesin Bytedance menyatakan bahawa penggunaan dalaman CV-CUDA boleh meningkatkan prestasi latihan dan inferens dengan ketara. Sebagai contoh, dari segi latihan, Bytedance ialah tugas berbilang modal yang berkaitan dengan video Bahagian pra-pemprosesan termasuk penyahkodan video berbilang bingkai dan banyak peningkatan data, menjadikan bahagian logik ini sangat rumit. Logik prapemprosesan yang kompleks menyebabkan prestasi berbilang teras CPU masih tidak bersaing semasa latihan Oleh itu, CV-CUDA digunakan untuk memindahkan semua logik prapemprosesan pada CPU ke GPU, mencapai pecutan 90% dalam kelajuan latihan keseluruhan. . Ambil perhatian bahawa ini adalah peningkatan dalam kelajuan latihan keseluruhan, bukan hanya dalam bahagian prapemprosesan. 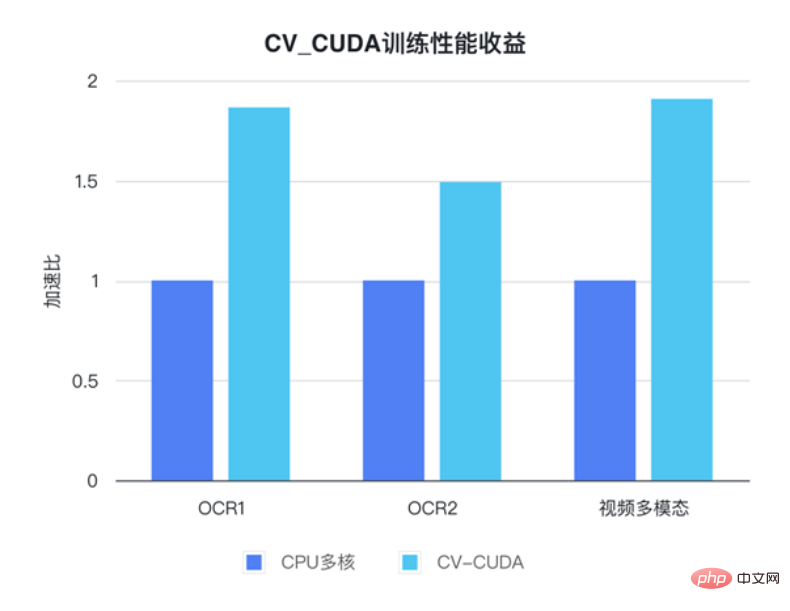
Kelajuan cukup cekap untuk memecahkan kesesakan pra-pemprosesan dalam tugas visual, dan ia juga mudah dan fleksibel untuk digunakan CV-CUDA telah membuktikan bahawa ia boleh meningkatkan penaakulan model dan kesan latihan dalam senario aplikasi sebenar. jadi jika tugas visual Pembaca juga dihadkan oleh kecekapan prapemprosesan, jadi cuba CV-CUDA sumber terbuka terkini.
Atas ialah kandungan terperinci Pustaka prapemprosesan imej CV-CUDA adalah sumber terbuka, memecahkan kesesakan prapemprosesan dan meningkatkan daya pengeluaran inferens lebih daripada 20 kali ganda.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Algoritma penggantian halaman
Algoritma penggantian halaman
 Apakah ciri baharu Hongmeng OS 3.0?
Apakah ciri baharu Hongmeng OS 3.0?
 Bagaimana untuk menyambungkan fail html dan fail css
Bagaimana untuk menyambungkan fail html dan fail css
 Apakah yang berlaku apabila saya tidak dapat menyambung ke rangkaian?
Apakah yang berlaku apabila saya tidak dapat menyambung ke rangkaian?
 Bagaimana untuk menukar warna latar belakang perkataan kepada putih
Bagaimana untuk menukar warna latar belakang perkataan kepada putih
 Apa yang perlu dilakukan jika 302 ditemui
Apa yang perlu dilakukan jika 302 ditemui
 Penjelasan terperinci tentang konfigurasi nginx
Penjelasan terperinci tentang konfigurasi nginx
 Apakah kad kad TF?
Apakah kad kad TF?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



