


Disebabkan kerumitannya, rangkaian saraf sering dianggap sebagai "holy grail" untuk menyelesaikan semua masalah pembelajaran mesin. Kaedah berasaskan pokok, sebaliknya, tidak mendapat perhatian yang sama, terutamanya disebabkan oleh kesederhanaan yang jelas bagi algoritma tersebut. Walau bagaimanapun, kedua-dua algoritma ini mungkin kelihatan berbeza, tetapi ia seperti dua sisi syiling yang sama, kedua-duanya adalah penting.

Kaedah berasaskan pokok biasanya lebih baik daripada rangkaian saraf. Pada asasnya, kaedah berasaskan pokok dan kaedah berasaskan rangkaian saraf diletakkan dalam kategori yang sama kerana kedua-duanya mendekati masalah melalui penyahbinaan langkah demi langkah, dan bukannya memisahkan keseluruhan set data melalui sempadan kompleks seperti mesin vektor sokongan atau regresi logistik. .
Jelas sekali, kaedah berasaskan pokok secara beransur-ansur membahagikan ruang ciri di sepanjang ciri yang berbeza untuk mengoptimumkan perolehan maklumat. Apa yang kurang jelas ialah rangkaian saraf juga mendekati tugas dengan cara yang sama. Setiap neuron memantau bahagian tertentu ruang ciri (dengan pelbagai pertindihan). Apabila input memasuki ruang ini, neuron tertentu diaktifkan.
Rangkaian saraf melihat model sekeping demi sekeping ini sesuai dari perspektif kebarangkalian, manakala kaedah berasaskan pokok mengambil perspektif deterministik. Walau apa pun, prestasi kedua-duanya bergantung pada kedalaman model, kerana komponennya dikaitkan dengan pelbagai bahagian ruang ciri.
Model dengan terlalu banyak komponen (nod untuk model pokok, neuron untuk rangkaian saraf) akan terlampau muat, manakala model dengan terlalu sedikit komponen tidak akan memberikan ramalan Bermakna. (Kedua-duanya bermula dengan menghafal titik data, dan bukannya belajar untuk membuat generalisasi.)
Untuk memahami dengan lebih intuitif bagaimana rangkaian saraf membahagikan ruang ciri, anda boleh membaca artikel pengenalan ini mengenai Penghampiran Universal Teorem: https://medium.com/analytics-vidhya/you-dont-understand-neural-networks-until-you-understand-the-universal-approximation-theory-85b3e7677126.
Walaupun terdapat banyak varian berkuasa pepohon keputusan seperti Random Forest, Gradient Boosting, AdaBoost dan Deep Forest, secara amnya, kaedah berasaskan pokok pada asasnya adalah penyederhanaan versi rangkaian saraf.
Kaedah berasaskan pokok menyelesaikan masalah sekeping demi sekeping melalui garisan menegak dan mendatar untuk meminimumkan entropi (pengoptimum dan kerugian). Rangkaian saraf menggunakan fungsi pengaktifan untuk menyelesaikan masalah sekeping demi sekeping.
Kaedah berasaskan pokok adalah bersifat deterministik dan bukannya probabilistik. Ini membawa beberapa pemudahan yang bagus seperti pemilihan ciri automatik.
Nod keadaan yang diaktifkan dalam pepohon keputusan adalah serupa dengan neuron yang diaktifkan (aliran maklumat) dalam rangkaian saraf.
Rangkaian saraf mengubah input melalui parameter pemasangan dan secara tidak langsung membimbing pengaktifan neuron seterusnya. Pokok keputusan secara eksplisit sesuai dengan parameter untuk membimbing aliran maklumat. (Ini adalah hasil daripada deterministik lawan probabilistik.)
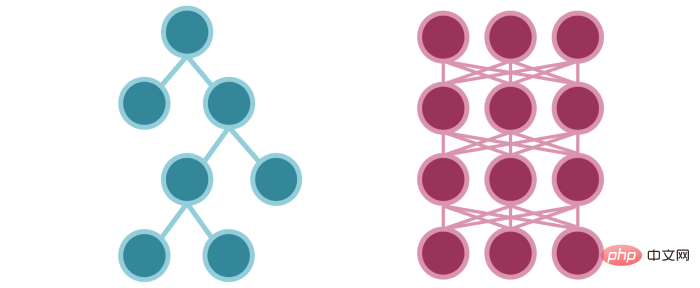
Aliran maklumat adalah serupa dalam kedua-dua model, hanya dalam model pokok Aliran kaedah lebih mudah.
Sudah tentu, ini adalah kesimpulan abstrak, dan mungkin terdapat malah menjadi Kontroversial. Memang, terdapat banyak halangan untuk membuat hubungan ini. Walau apa pun, ini adalah bahagian penting dalam memahami bila dan mengapa kaedah berasaskan pokok lebih baik daripada rangkaian saraf.
Adalah lumrah bagi pepohon keputusan untuk berfungsi dengan data berstruktur dalam bentuk jadual atau jadual. Kebanyakan orang bersetuju bahawa menggunakan rangkaian saraf untuk melakukan regresi dan ramalan pada data jadual adalah berlebihan, jadi beberapa pemudahan dibuat di sini. Pilihan 1s dan 0s, bukannya kebarangkalian, adalah sumber utama perbezaan antara kedua-dua algoritma. Oleh itu, kaedah berasaskan pokok boleh berjaya digunakan pada situasi di mana kebarangkalian tidak diperlukan, seperti data berstruktur.
Sebagai contoh, kaedah berasaskan pokok menunjukkan prestasi yang baik pada set data MNIST kerana setiap nombor mempunyai beberapa ciri penting. Tidak perlu mengira kebarangkalian dan masalahnya tidak begitu rumit, itulah sebabnya model ensembel pokok yang direka dengan baik boleh berprestasi sebaik atau lebih baik daripada rangkaian saraf konvolusi moden.
Secara amnya, orang ramai cenderung untuk mengatakan bahawa "kaedah berasaskan pokok hanya ingat peraturan", yang betul. Rangkaian saraf adalah sama, kecuali mereka boleh mengingati peraturan berasaskan kebarangkalian yang lebih kompleks. Daripada memberikan ramalan benar/salah secara eksplisit untuk keadaan seperti x>3, rangkaian saraf menguatkan input kepada nilai yang sangat tinggi, menghasilkan nilai sigmoid 1 atau menjana ungkapan berterusan.
Sebaliknya, memandangkan rangkaian saraf sangat kompleks, terdapat banyak perkara yang boleh dilakukan dengannya. Kedua-dua lapisan konvolusi dan berulang adalah varian rangkaian saraf yang luar biasa kerana data yang diproses selalunya memerlukan nuansa pengiraan kebarangkalian.
Terdapat sangat sedikit imej yang boleh dimodelkan dengan satu dan sifar. Nilai pepohon keputusan tidak dapat mengendalikan set data dengan banyak nilai perantaraan (mis. 0.5) sebab itu ia berfungsi dengan baik pada set data MNIST di mana nilai piksel hampir semuanya hitam atau putih tetapi piksel set data lain Nilainya bukan (cth. ImageNet) . Begitu juga, teks mempunyai terlalu banyak maklumat dan terlalu banyak anomali untuk dinyatakan dalam istilah yang pasti.
Ini juga merupakan sebab mengapa rangkaian saraf digunakan terutamanya dalam bidang ini, dan juga sebab mengapa penyelidikan rangkaian saraf terbantut pada hari-hari awal (sebelum permulaan abad ke-21) apabila sejumlah besar data imej dan teks tidak tersedia . Penggunaan biasa rangkaian neural yang lain adalah terhad kepada ramalan berskala besar, seperti algoritma pengesyoran video YouTube, yang sangat besar dan mesti menggunakan kebarangkalian.
Pasukan sains data di mana-mana syarikat mungkin akan menggunakan model berasaskan pokok dan bukannya rangkaian saraf, melainkan mereka membina aplikasi tugas berat seperti mengaburkan latar belakang video Zoom. Tetapi dalam tugas klasifikasi perniagaan harian, kaedah berasaskan pokok menjadikan tugasan ini ringan kerana sifat deterministiknya, dan kaedahnya adalah sama seperti rangkaian saraf.
Dalam banyak situasi praktikal, pemodelan deterministik adalah lebih semula jadi daripada pemodelan probabilistik. Contohnya, untuk meramalkan sama ada pengguna akan membeli item daripada tapak web e-dagang, model pokok ialah pilihan yang baik kerana pengguna secara semula jadi mengikuti proses membuat keputusan berasaskan peraturan. Proses membuat keputusan pengguna mungkin kelihatan seperti ini:
Secara umumnya, manusia mengikut proses membuat keputusan berasaskan peraturan dan tersusun. Dalam kes ini, pemodelan kebarangkalian tidak diperlukan.
Atas ialah kandungan terperinci Pembelajaran Mesin: Jangan memandang rendah kuasa model pokok. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



