


Hari ini, Transformers ialah modul utama dalam kebanyakan seni bina pemprosesan bahasa semula jadi (NLP) dan penglihatan komputer (CV) termaju. Walau bagaimanapun, bidang data jadual masih didominasi oleh algoritma pepohon keputusan yang dirangsang kecerunan (GBDT). Jadi, terdapat percubaan untuk merapatkan jurang ini. Antaranya, kertas pemodelan data jadual berasaskan penukar pertama ialah kertas "TabTransformer: Tabular Data Modeling Using Context Embedding" yang diterbitkan oleh Huang et al.
Artikel ini bertujuan untuk menyediakan paparan asas kandungan kertas, sambil turut menyelidiki butiran pelaksanaan model TabTransformer dan menunjukkan kepada anda cara menggunakan TabTransformer khusus untuk data kami sendiri .
Idea utama kertas di atas ialah jika penukar digunakan untuk menukar benam klasifikasi konvensional kepada benam kontekstual, maka persepsi berbilang lapisan konvensional Prestasi pemproses (MLP) akan dipertingkatkan dengan ketara. Seterusnya, mari kita fahami penerangan ini dengan lebih mendalam.
Dalam model pembelajaran mendalam, cara klasik untuk menggunakan ciri kategori adalah dengan melatih benamnya. Ini bermakna setiap nilai kategori mempunyai perwakilan vektor padat yang unik dan boleh dihantar ke lapisan seterusnya. Sebagai contoh, anda boleh melihat daripada imej di bawah bahawa setiap ciri kategori diwakili oleh tatasusunan empat dimensi. Pembenaman ini kemudiannya digabungkan dengan ciri berangka dan digunakan sebagai input kepada MLP.
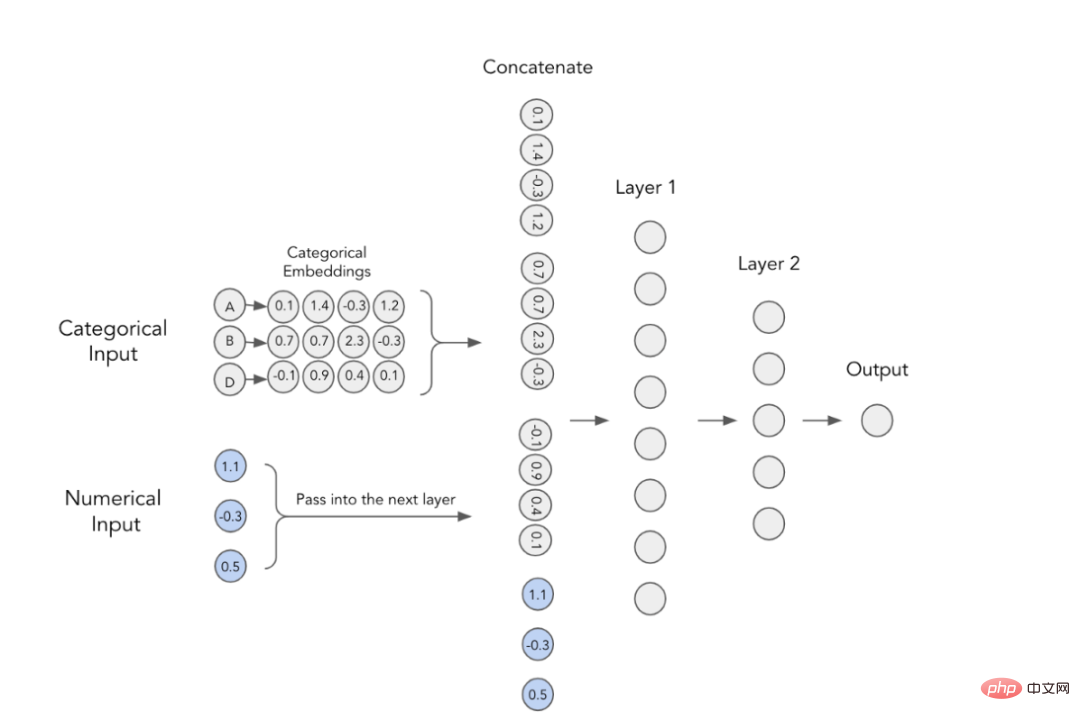
MLP dengan pembenaman klasifikasi
Pembenaman Kontekstual dalam TabTransformer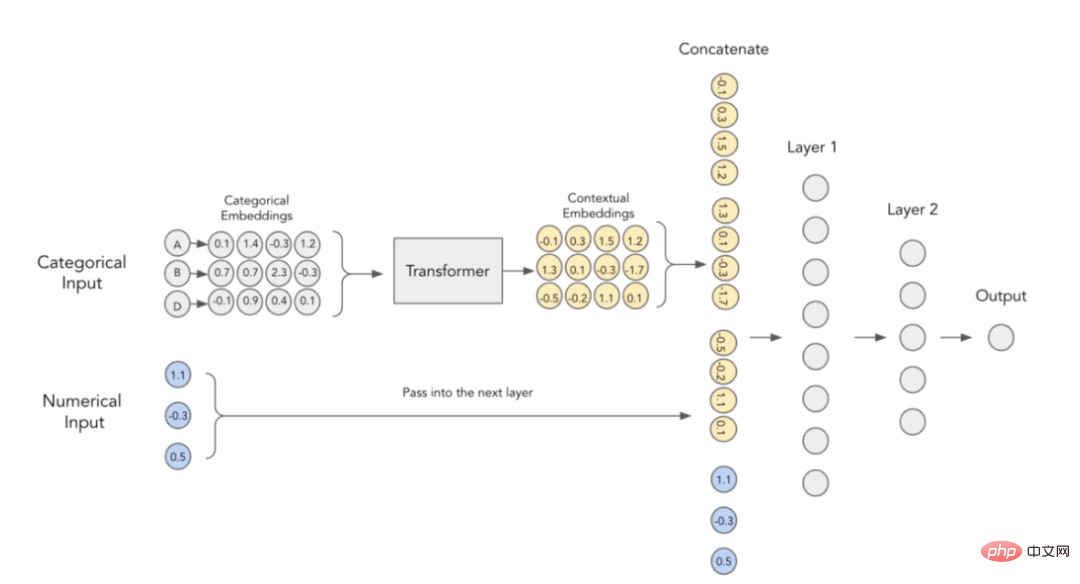
Contoh hasil pembenaman penukar TabTransformer terlatih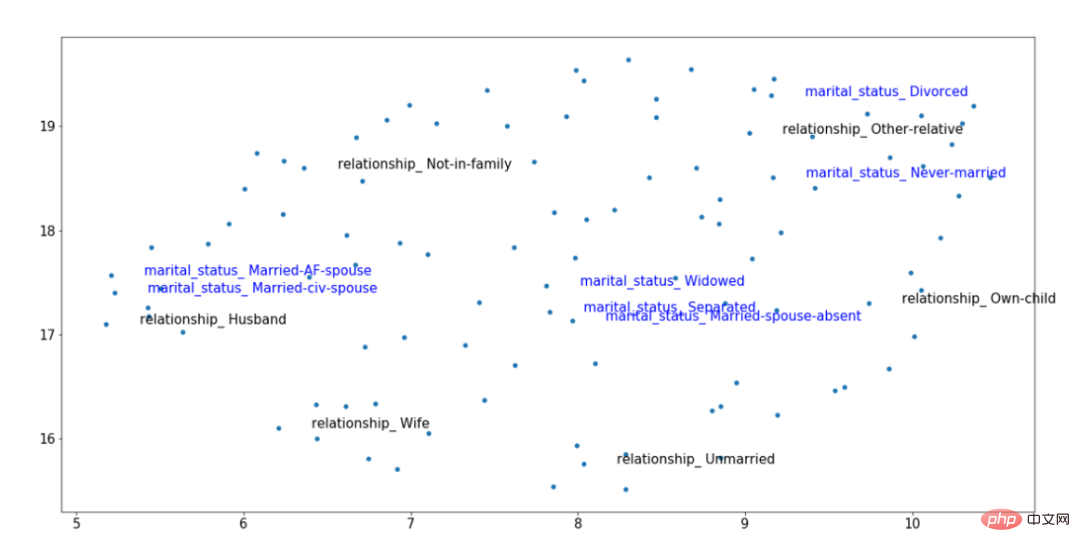
Rajah seni bina penukar TabTransformer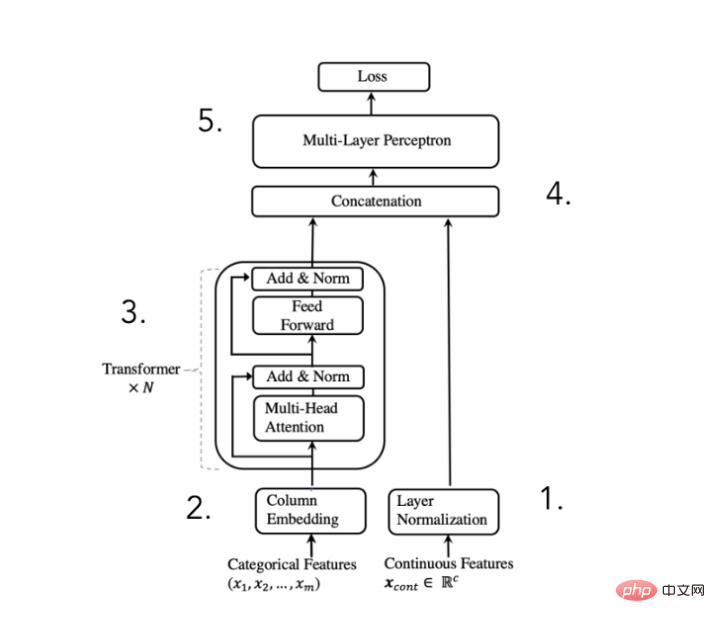
Seragamkan ciri berangka dan hantarkannya ke hadapan
Gambar rajah seni bina Transformer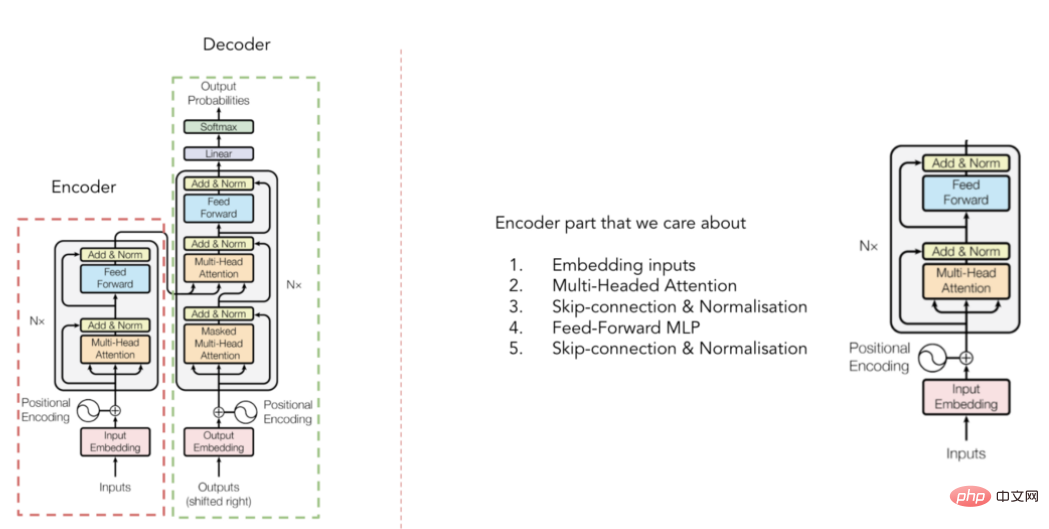
Untuk memetik penerangan daripada artikel kegemaran saya tentang mekanisme perhatian, ianya seperti ini:
“Konsep utama di sebalik perhatian diri ialah mekanisme ini membolehkan Rangkaian saraf belajar bagaimana untuk jadual maklumat dalam skema penghalaan terbaik antara pelbagai bahagian urutan input Dalam erti kata lain, perhatian kendiri membantu model mengetahui bahagian input mana yang lebih penting dan bahagian mana yang kurang penting apabila mewakili perkataan tertentu. kategori. Untuk itu, saya amat mengesyorkan anda membaca artikel yang dirujuk di atas untuk mendapatkan pemahaman yang lebih intuitif tentang sebab fokus kendiri sangat berkesan.
Mekanisme perhatian berbilang kepala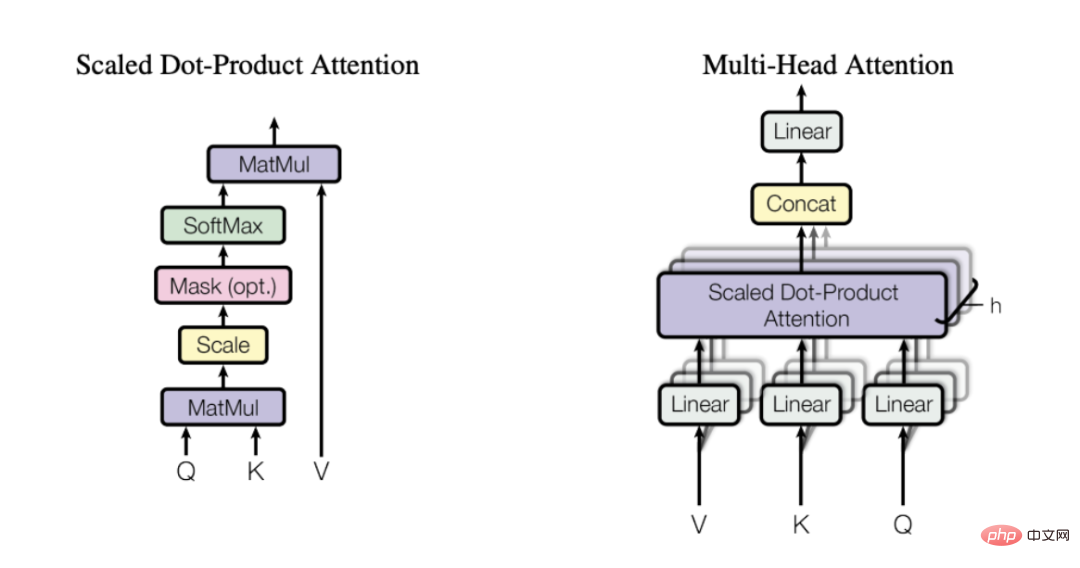 (dipilih daripada kertas yang diterbitkan oleh Vaswani et al. pada 2017)
(dipilih daripada kertas yang diterbitkan oleh Vaswani et al. pada 2017)
Perhatian dikira melalui 3 matriks yang dipelajari - Q, K dan V, yang mewakili pertanyaan, kunci dan nilai. Pertama, kita darabkan matriks Q dan K untuk mendapatkan matriks perhatian. Matriks ini berskala dan melalui lapisan softmax. Kami kemudian mendarabkan ini dengan matriks V untuk mendapatkan nilai akhir. Untuk pemahaman yang lebih intuitif, pertimbangkan skema di bawah, yang menunjukkan cara kami melaksanakan transformasi daripada pembenaman input kepada pembenaman konteks menggunakan matriks Q, K dan V.
Penggambaran proses fokus kendiri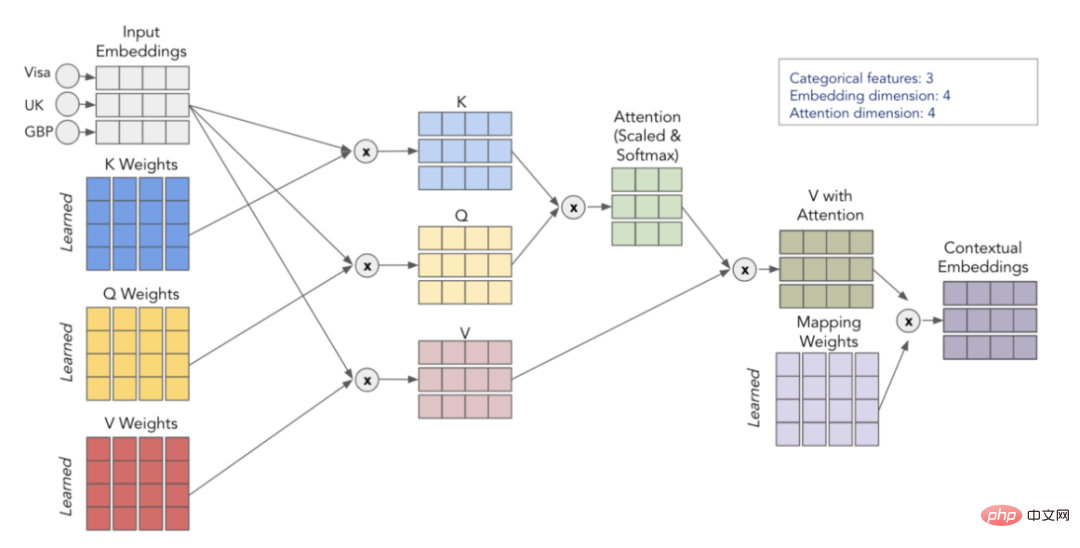
Dengan mengulangi proses h kali (menggunakan Q, K yang berbeza , matriks V), kita boleh mendapatkan pelbagai benam konteks, yang membentuk perhatian berbilang kepala terakhir kita.
6. Tinjauan ringkas
7. Paparan keputusan ujian
Data keputusan (dipilih daripada Huang et al. diterbitkan pada 2020 Kertas)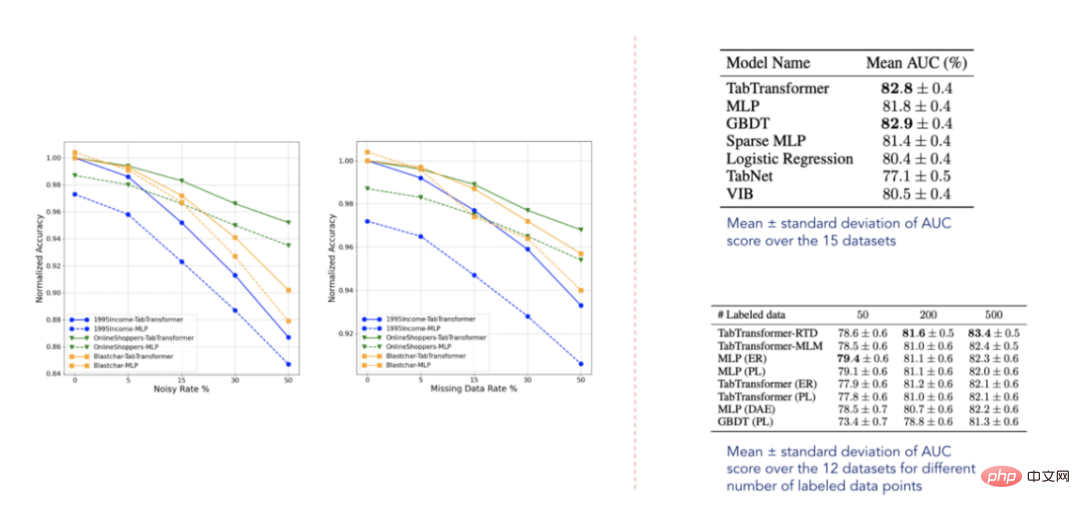
Menurut keputusan yang dilaporkan, TabTransformer mengatasi semua model jadual pembelajaran mendalam yang lain, tambahan pula, ia hampir dengan tahap prestasi GBDT, yang sangat menggalakkan. Model ini juga agak teguh kepada data yang hilang dan bising, dan mengatasi model lain dalam tetapan separa diselia. Walau bagaimanapun, set data ini jelas tidak menyeluruh dan masih terdapat banyak ruang untuk penambahbaikan, seperti yang disahkan oleh beberapa kertas berkaitan yang diterbitkan pada masa hadapan.
2. Membina program sampel kami sendiri
pip install tabtransformertf
1. Prapemprosesan data
from tabtransformertf.utils.preprocessing import df_to_dataset, build_categorical_prep # 设置数据类型 train_data[CATEGORICAL_FEATURES] = train_data[CATEGORICAL_FEATURES].astype(str) val_data[CATEGORICAL_FEATURES] = val_data[CATEGORICAL_FEATURES].astype(str) train_data[NUMERIC_FEATURES] = train_data[NUMERIC_FEATURES].astype(float) val_data[NUMERIC_FEATURES] = val_data[NUMERIC_FEATURES].astype(float) # 转换成TF数据集 train_dataset = df_to_dataset(train_data[FEATURES + [LABEL]], LABEL, batch_size=1024) val_dataset = df_to_dataset(val_data[FEATURES + [LABEL]], LABEL, shuffle=False, batch_size=1024)
from tabtransformertf.utils.preprocessing import build_categorical_prep category_prep_layers = build_categorical_prep(train_data, CATEGORICAL_FEATURES) # 输出结果是一个字典结构,其中键部分是特征名称,值部分是StringLookup层 # category_prep_layers -> # {'product_code': , #'attribute_0': , #'attribute_1': }
2. Bina model TabTransformer
from tabtransformertf.models.tabtransformer import TabTransformer tabtransformer = TabTransformer( numerical_features = NUMERIC_FEATURES,# 带有数字特征名称的列表 categorical_features = CATEGORICAL_FEATURES, # 带有分类特征名称的列表 categorical_lookup=category_prep_layers, # 带StringLookup层的Dict numerical_discretisers=None,# None代表我们只是简单地传递数字特征 embedding_dim=32,# 嵌入维数 out_dim=1,# Dimensionality of output (binary task) out_activatinotallow='sigmoid',# 输出层激活 depth=4,# 转换器块层的个数 heads=8,# 转换器块中注意力头的个数 attn_dropout=0.1,# 在转换器块中的丢弃率 ff_dropout=0.1,# 在最后MLP中的丢弃率 mlp_hidden_factors=[2, 4],# 我们为每一层划分最终嵌入的因子 use_column_embedding=True,#如果我们想使用列嵌入,设置此项为真 ) # 模型运行中摘要输出: # 总参数个数: 1,778,884 # 可训练的参数个数: 1,774,064 # 不可训练的参数个数: 4,820
LEARNING_RATE = 0.0001 WEIGHT_DECAY = 0.0001 NUM_EPOCHS = 1000 optimizer = tfa.optimizers.AdamW( learning_rate=LEARNING_RATE, weight_decay=WEIGHT_DECAY ) tabtransformer.compile( optimizer = optimizer, loss = tf.keras.losses.BinaryCrossentropy(), metrics= [tf.keras.metrics.AUC(name="PR AUC", curve='PR')], ) out_file = './tabTransformerBasic' checkpoint = ModelCheckpoint( out_file, mnotallow="val_loss", verbose=1, save_best_notallow=True, mode="min" ) early = EarlyStopping(mnotallow="val_loss", mode="min", patience=10, restore_best_weights=True) callback_list = [checkpoint, early] history = tabtransformer.fit( train_dataset, epochs=NUM_EPOCHS, validation_data=val_dataset, callbacks=callback_list )
val_preds = tabtransformer.predict(val_dataset) print(f"PR AUC: {average_precision_score(val_data['isFraud'], val_preds.ravel())}") print(f"ROC AUC: {roc_auc_score(val_data['isFraud'], val_preds.ravel())}") # PR AUC: 0.26 # ROC AUC: 0.58
您也可以自己给测试集评分,然后将结果值提交给Kaggle官方。我现在选择的这个解决方案使我跻身前35%,这并不坏,但也不太好。那么,为什么TabTransfromer在上述方案中表现不佳呢?可能有以下几个原因:
本文探讨了TabTransformer背后的主要思想,并展示了如何使用Tabtransformertf包来具体应用此转换器。
归纳起来看,TabTransformer的确是一种有趣的体系结构,它在当时的表现明显优于大多数深度表格模型。它的主要优点是将分类嵌入语境化,从而增强其表达能力。它使用在分类特征上的多头注意力机制来实现这一点,而这是在表格数据领域使用转换器的第一个应用实例。
TabTransformer体系结构的一个明显缺点是,数字特征被简单地传递到最终的MLP层。因此,它们没有语境化,它们的价值也没有在分类嵌入中得到解释。在下一篇文章中,我将探讨如何修复此缺陷并进一步提高性能。
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文链接:https://towardsdatascience.com/transformers-for-tabular-data-tabtransformer-deep-dive-5fb2438da820?source=collection_home---------4----------------------------
Atas ialah kandungan terperinci Penukar TabTransformer menambah baik prestasi perceptron berbilang lapisan analisis mendalam. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk memecahkan penyulitan fail zip
Bagaimana untuk memecahkan penyulitan fail zip fail srt
fail srt apa itu drivergenius
apa itu drivergenius Bagaimana untuk menyelesaikan masalah bahawa pemproses cetak tidak wujud
Bagaimana untuk menyelesaikan masalah bahawa pemproses cetak tidak wujud Perbezaan antara mysql dan sql_server
Perbezaan antara mysql dan sql_server Apakah alat ujian java?
Apakah alat ujian java? Cara menggunakan setrequestproperty
Cara menggunakan setrequestproperty Platform manakah yang lebih baik untuk perdagangan mata wang maya?
Platform manakah yang lebih baik untuk perdagangan mata wang maya?




















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



