



Mengapakah chatbot AI mengada-ada, dan bolehkah kita mempercayai sepenuhnya output mereka Untuk tujuan ini, kami bertanya kepada beberapa pakar dan menggali lebih mendalam Bagaimana model AI ini? bekerja untuk mencari jawapan.
Bot sembang AI seperti OpenAI's ChatGPT bergantung pada jenis kecerdasan buatan yang dipanggil kecerdasan "Model Bahasa Besar" (LLM) untuk menjana respons mereka . LLM ialah program komputer yang dilatih pada berjuta-juta sumber teks untuk membaca dan menjana bahasa tekstual "bahasa semula jadi", sama seperti manusia secara semula jadi menulis atau bercakap. Malangnya, mereka juga melakukan kesilapan.
Dalam kesusasteraan akademik, penyelidik AI sering memanggil kesilapan ini "halusinasi." Memandangkan topik itu telah menjadi arus perdana, label itu telah menjadi semakin kontroversi, kerana sesetengah orang percaya bahawa ia membentuk model AI (mencadangkan mereka mempunyai ciri seperti manusia), atau memberikannya kepada model AI apabila ia tidak sepatutnya membayangkan ini bahawa mereka boleh membuat pilihan mereka sendiri). Di samping itu, pencipta LLM komersial juga mungkin menggunakan ilusi sebagai alasan untuk menyalahkan model AI untuk keluaran yang salah dan bukannya bertanggungjawab ke atas output itu sendiri.
Namun, AI generatif adalah bidang yang sangat baharu, dan kita perlu meminjam metafora daripada idea sedia ada untuk menerangkan konsep yang sangat teknikal ini kepada orang ramai. Dalam kes ini, kami merasakan bahawa perkataan "konfabulasi", walaupun sama tidak sempurna, adalah metafora yang lebih baik daripada metafora "halusinasi." Dalam psikologi manusia, "fiksyen" merujuk kepada jurang dalam ingatan seseorang, dan otak mengisi pengalaman yang dilupakan dengan fakta fiksyen yang meyakinkan tanpa sengaja menipu orang lain. ChatGPT tidak beroperasi seperti otak manusia, tetapi istilah "fiksyen" boleh dikatakan metafora yang lebih baik kerana ia berfungsi berdasarkan prinsip mengisi jurang secara kreatif (daripada menipu secara sengaja), yang akan kita terokai di bawah.
Ini adalah masalah besar apabila bot AI menghasilkan maklumat palsu yang mungkin mempunyai kesan mengelirukan atau memfitnah. Baru-baru ini, The Washington Post melaporkan tentang seorang profesor undang-undang yang mendapati bahawa ChatGPT telah memasukkannya dalam senarai sarjana undang-undang yang mengganggu orang lain secara seksual. Tetapi perkara ini adalah palsu dan direka sepenuhnya oleh ChatGPT. Pada hari yang sama, Ars juga melaporkan bahawa seorang datuk bandar Australia mendapati bahawa dakwaan ChatGPT bahawa dia telah disabitkan dengan rasuah dan dipenjarakan juga adalah rekaan sepenuhnya.
Tidak lama selepas pelancaran ChatGPT, orang ramai mula menyokong penamatan enjin carian. Namun, pada masa yang sama, banyak kes rekaan ChatGPT mula tersebar luas di media sosial. Bot AI mencipta buku dan kajian yang tidak wujud, penerbitan yang tidak ditulis oleh profesor, kertas akademik palsu, petikan undang-undang palsu, ciri sistem Linux yang tidak wujud, maskot runcit yang tidak sebenar dan butiran teknikal yang tidak bermakna.
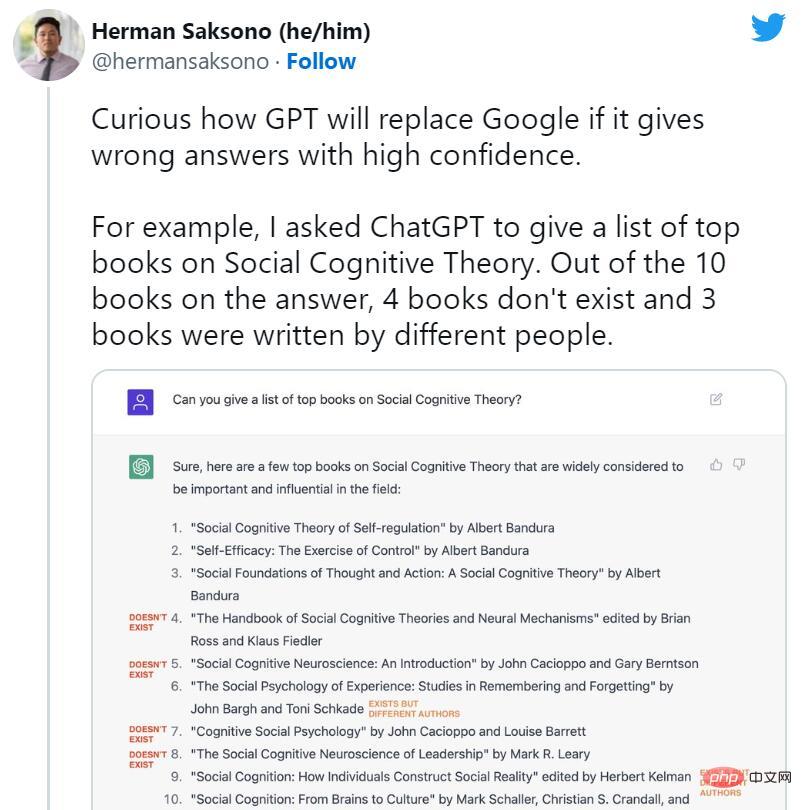
Walau bagaimanapun, walaupun ChatGPT cenderung untuk fib kasual, penindasannya terhadap fiksyen itulah sebabnya kita bercakap mengenainya hari ini. Sesetengah pakar menunjukkan bahawa ChatGPT secara teknikalnya adalah peningkatan berbanding GPT-3 biasa (model pendahulunya) kerana ia boleh menolak untuk menjawab beberapa soalan atau memberitahu anda apabila jawapannya mungkin tidak tepat.
Riley Goodside, pakar model bahasa berskala besar dan jurutera pantas di Skala AI, berkata, “Satu faktor utama kejayaan ChatGPT ialah ia berjaya menindas fiksyen dan menjadikan banyak masalah biasa tidak dapat disedari. ChatGPT secara ketara kurang cenderung untuk mengada-adakan ”
Jika digunakan sebagai alat sumbang saran, lompatan logik dan pura-pura ChatGPT boleh membawa kepada kejayaan kreatif. Tetapi apabila digunakan sebagai rujukan fakta, ChatGPT boleh mendatangkan mudarat sebenar, dan OpenAI mengetahui perkara ini.
Tidak lama selepas model itu dikeluarkan, Ketua Pegawai Eksekutif OpenAI Sam Altman menulis tweet, “ChatGPT adalah sangat terhad dalam fungsi, tetapi cukup baik dalam beberapa cara untuk mencipta Tera yang mengelirukan. Adalah satu kesilapan untuk bergantung padanya apa-apa yang penting sekarang; kami masih mempunyai banyak kerja untuk dilakukan dari segi keteguhan dan keaslian."
dalam tweet kemudian. Dalam artikel itu, dia juga menulis, "Ia tahu banyak, tetapi bahayanya adakah ia yakin secara membuta tuli dan salah untuk sebahagian besar masa."
Apa yang sedang berlaku?
Untuk memahami cara model GPT seperti ChatGPT atau Bing Chat adalah "fiksyen", kita mesti tahu cara model GPT berfungsi. Walaupun OpenAI masih belum mengeluarkan butiran teknikal untuk ChatGPT, Bing Chat atau GPT-4, kami menjangkakan akan melihat kertas penyelidikan yang memperkenalkan GPT-3 (pendahulunya) pada tahun 2020.
Penyelidik membina (melatih) model bahasa yang besar seperti GPT-3 dan GPT-4 dengan menggunakan proses yang dipanggil "pembelajaran tanpa pengawasan", yang bermaksud bahawa data yang mereka gunakan untuk melatih model itu tidak diberi anotasi atau tanda khas. Dalam proses ini, model diberi sejumlah besar teks (berjuta-juta buku, laman web, artikel, puisi, manuskrip dan sumber lain) dan berulang kali cuba meramalkan perkataan seterusnya dalam setiap urutan perkataan. Jika ramalan model hampir dengan perkataan seterusnya yang sebenar, rangkaian saraf mengemas kini parameternya untuk mengukuhkan corak yang membawa kepada ramalan itu.
Sebaliknya, jika ramalan tidak betul, model melaraskan parameter untuk meningkatkan prestasi dan mencuba lagi. Proses percubaan dan kesilapan ini, walaupun teknik yang dipanggil backpropagation, membolehkan model belajar daripada kesilapannya dan memperbaiki ramalannya secara beransur-ansur semasa latihan.
Oleh itu, GPT mempelajari perkaitan statistik antara perkataan dan konsep berkaitan dalam set data. Sesetengah, seperti ketua saintis OpenAI Ilya Sutskever, percaya bahawa model GPT pergi lebih jauh daripada ini dan membina model dalaman realiti supaya mereka boleh meramalkan token terbaik seterusnya dengan lebih tepat, tetapi idea ini menjadi kontroversi. Butiran tepat tentang cara model GPT mencadangkan token seterusnya dalam rangkaian neuralnya masih tidak pasti.

Dalam gelombang semasa model GPT, latihan teras ini (kini sering dipanggil "pra-latihan") hanya berlaku sekali sahaja. Selepas ini, seseorang boleh menggunakan rangkaian saraf terlatih dalam "mod inferens", yang membolehkan pengguna memasukkan input ke dalam rangkaian terlatih dan mendapatkan hasilnya. Semasa inferens, jujukan input kepada model GPT sentiasa disediakan oleh manusia, yang dipanggil "prompt". Gesaan menentukan output model, dan menukar gesaan walaupun sedikit boleh mengubah hasil yang dihasilkan oleh model secara drastik.
Sebagai contoh, jika anda menggesa GPT-3 "Mary had a", ia biasanya akan melengkapkan ayat dengan "little lamb". Ini kerana mungkin terdapat puluhan ribu contoh "Mary had a little lamb" dalam set data latihan GPT-3, menjadikannya output yang munasabah. Tetapi jika anda menambahkan lebih banyak konteks pada gesaan, seperti "Di hospital, Mary mengalami", keputusan akan berubah dan mengembalikan sesuatu seperti perkataan "bayi" atau "siri ujian".
Inilah yang menarik tentang ChatGPT, kerana ia disediakan sebagai perbualan dengan ejen, bukan hanya kerja penjanaan teks langsung. Dalam kes ChatGPT, gesaan input ialah keseluruhan perbualan anda dengan ChatGPT, bermula dengan soalan atau pernyataan pertama anda, termasuk sebarang arahan khusus yang diberikan kepada ChatGPT sebelum perbualan simulasi bermula. Semasa proses ini, ChatGPT mengekalkan memori jangka pendek (dipanggil "tetingkap konteks") mengenainya dan semua yang anda tulis, dan semasa ia "bercakap" dengan anda, ia cuba menyelesaikan tugas penjanaan teks perbualan.
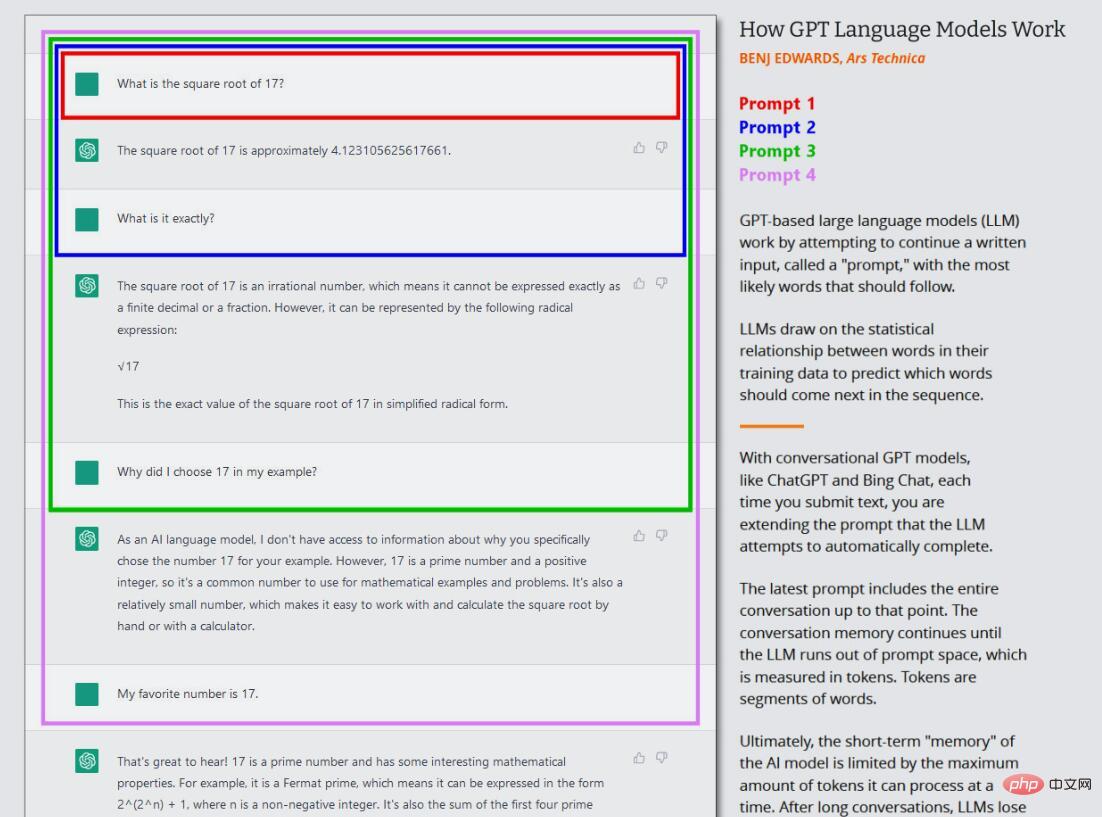
Tambahan pula, ChatGPT berbeza daripada GPT-3 biasa kerana ia juga dilatih mengenai teks perbualan yang ditulis oleh manusia. OpenAI menulis pada halaman keluaran ChatGPT awalnya, “Kami melatih model awal menggunakan penalaan halus yang diselia: jurulatih AI manusia menyediakan perbualan di mana mereka bertindak sebagai kedua-dua pihak — pengguna dan Pembantu AI bantu mereka mengarang respons mereka sendiri maklumat kembali ke dalam model. Melalui RLHF, OpenAI dapat menerapkan dalam model matlamat untuk "mengelakkan menjawab soalan yang tidak dapat dijawab dengan tepat." Ini membolehkan ChatGPT menghasilkan respons yang konsisten dengan fiksyen yang kurang daripada model asas. Tetapi maklumat yang tidak tepat masih boleh terlepas.
Mengapa ChatGPT menghasilkan fiksyen
Tingkah laku LLM kekal sebagai bidang penyelidikan yang aktif. Malah para penyelidik yang mencipta model GPT ini masih menemui ciri-ciri mengejutkan teknologi yang tidak diramalkan oleh sesiapa apabila ia mula-mula dibangunkan. Keupayaan GPT untuk melakukan banyak perkara menarik yang kita lihat sekarang, seperti terjemahan bahasa, pengaturcaraan dan bermain catur, pernah mengejutkan penyelidik.
Jadi apabila kami bertanya mengapa ChatGPT menghasilkan artifak, sukar untuk mencari jawapan teknikal yang tepat. Oleh kerana pemberat rangkaian saraf mempunyai elemen "kotak hitam", adalah sukar (atau bahkan mustahil) untuk meramalkan output tepatnya apabila diberi gesaan yang kompleks. Walau bagaimanapun, kita tahu beberapa sebab asas mengapa fiksyen berlaku.
Kunci untuk memahami keupayaan fiksyen ChatGPT ialah memahami peranannya sebagai mesin ramalan. Apabila ChatGPT membuat, ia mencari maklumat atau analisis yang tidak wujud dalam set data dan mengisi jurang dengan perkataan yang munasabah. ChatGPT sangat baik dalam membuat sesuatu kerana jumlah data yang perlu diproses dan keupayaannya untuk mengumpulkan konteks perkataan dengan baik, yang membantunya meletakkan mesej ralat dengan lancar ke dalam teks sekeliling.
Pembangun perisian Simon Willison berkata, "Saya rasa cara terbaik untuk berfikir tentang fiksyen ialah memikirkan sifat model bahasa besar: satu-satunya perkara yang mereka tahu bagaimana untuk melakukannya ialah memilih model terbaik seterusnya berdasarkan set latihan, berdasarkan kebarangkalian statistik "
Dalam kertas kerja 2021, tiga penyelidik dari Universiti Oxford dan OpenAI mengenal pasti dua jenis pembohongan utama yang boleh dihasilkan oleh LLM seperti ChatGPT. Yang pertama datang daripada bahan sumber yang tidak tepat dalam set data latihannya, seperti salah tanggapan biasa (mis., "memakan ayam belanda akan membuatkan anda mengantuk"). Yang kedua timbul daripada membuat inferens tentang situasi tertentu yang tidak wujud dalam set data latihannya; ini terletak di bawah label "halusinasi" yang dinyatakan sebelum ini.
Sama ada model GPT membuat tekaan liar bergantung pada apa yang dipanggil oleh penyelidik AI sebagai atribut "suhu", yang sering digambarkan sebagai tetapan "kreativiti". Jika kreativiti ditetapkan tinggi, model akan membuat tekaan liar jika ia ditetapkan rendah, ia akan mengeluarkan data secara deterministik berdasarkan set datanya.
Baru-baru ini, pekerja Microsoft Mikhail Parakhin bercakap di Twitter tentang kecenderungan Bing Chat untuk berhalusinasi dan apa yang menyebabkan halusinasi. Dia menulis, "Inilah yang saya cuba jelaskan sebelum ini: ilusi = kreativiti. Ia cuba menghasilkan kesinambungan kebarangkalian tertinggi rentetan menggunakan semua data yang diprosesnya. Ia biasanya betul. Kadang-kadang orang tidak pernah membuat kesinambungan sedemikian. "
Parakhin menambah bahawa lompatan kreatif yang gila inilah yang menjadikan LLM menarik. Anda boleh menahan halusinasi, tetapi anda akan mendapati ia sangat membosankan. Kerana ia sentiasa menjawab "Saya tidak tahu", atau hanya mengembalikan apa yang ada dalam hasil carian (yang juga kadangkala tidak betul). Apa yang hilang sekarang ialah nada: ia tidak sepatutnya kelihatan yakin dalam situasi ini. ”
Apabila memperhalusi model bahasa seperti ChatGPT, mengimbangi kreativiti dan ketepatan adalah satu cabaran Di satu pihak, keupayaan untuk menghasilkan respons kreatif menjadikan ChatGPT alat yang berkuasa untuk menjana idea baharu atau menghapuskan kesesakan penulis Ini juga menjadikan model itu lebih manusiawi Sebaliknya, apabila ia datang untuk menghasilkan maklumat yang boleh dipercayai dan mengelakkan fiksyen, ketepatan bahan sumber adalah penting untuk pembangunan model bahasa untuk mencari keseimbangan yang tepat antara kedua-duanya. Keseimbangan adalah cabaran berterusan, tetapi penting untuk membangunkan alat yang berguna dan boleh dipercayai
Terdapat juga isu pemampatan, yang GPT-3 pertimbangkan pada tahap petabyte semasa latihan. tetapi rangkaian saraf yang terhasil adalah sebahagian kecil daripada saiz Dalam artikel New Yorker yang dibaca secara meluas, pengarang Ted Chiang menyebutnya sebagai "rangkaian kabur JPEG Ini bermakna beberapa data latihan fakta hilang, tetapi GPT-3." untuk ini dengan mempelajari hubungan antara konsep, yang kemudiannya boleh digunakan untuk merumuskan semula susunan baru fakta tersebut, sama seperti seseorang yang mempunyai ingatan yang cacat berfungsi dari firasat , ia kadang-kadang menjadi salah, jika ia tidak tahu jawapannya, ia memberikan tekaan terbaiknya
Kami tidak boleh melupakan peranan gesaan dalam fiksyen: Apa yang anda berikan, ia memberi anda Jika anda memberinya bohong, ia akan cenderung bersetuju dengan anda dan " fikirkan" mengikut baris tersebut. Adalah penting untuk memulakan semula dengan gesaan baharu. ChatGPT adalah kebarangkalian, bermakna ia bersifat separa rawak dan perkara yang dikeluarkannya mungkin berubah antara sesi. .
Semua ini membawa kepada satu kesimpulan, satu kesimpulan yang OpenAI bersetuju dengan: ChatGPT, seperti yang direka pada masa ini, bukan sumber maklumat fakta yang boleh dipercayai dan tidak boleh dipercayai, Dr. Margaret Mitchell percaya, “ChatGPT boleh menjadi sangat berguna untuk perkara tertentu, seperti mengurangkan sekatan penulis atau. menghasilkan idea yang kreatif. Ia tidak dibina untuk kebenaran dan oleh itu tidak boleh menjadi kebenaran. Semudah itu. "
Memercayai bot sembang AI secara membuta tuli adalah satu kesilapan, tetapi itu mungkin berubah apabila teknologi asas bertambah baik. Sejak dikeluarkan pada November lalu, ChatGPT telah dinaik taraf beberapa kali, beberapa daripadanya termasuk peningkatan dalam ketepatan, dan keupayaan untuk menolak untuk menjawab soalan yang tidak diketahui jawapannya
Jadi bagaimanakah OpenAI merancang untuk menjadikan ChatGPT lebih tepat sejak beberapa tahun lalu OpenAI beberapa kali sepanjang bulan itu tetapi tidak menerima maklum balas, tetapi kami boleh menemui petunjuk daripada dokumen yang dikeluarkan oleh OpenAI dan laporan berita tentang percubaan syarikat untuk menyelaraskan ChatGPT dengan pekerja manusia
Seperti yang dinyatakan sebelum ini, salah satu sebab mengapa ChatGPT begitu berjaya adalah kerana latihannya yang meluas menggunakan RLHF. OpenAI menerangkan, "Untuk menjadikan model kami lebih selamat, lebih membantu dan lebih konsisten, kami menggunakan teknologi sedia ada yang dipanggil 'Pembelajaran Pengukuhan dengan Maklum Balas Manusia (RLHF).' Menurut petua yang diserahkan oleh pelanggan kepada API, penanda kami menyediakan demonstrasi tingkah laku model yang diingini dan mengisih beberapa output daripada model Kami kemudiannya menggunakan data ini untuk memperhalusi GPT-3,” kata Sutskever OpenAI melalui RLHF. Sutskever memberitahu Forbes dalam temu bual awal bulan ini, "Saya sangat berharap dengan menambah baik RLHF susulan ini, ia akan mengajarnya untuk tidak berhalusinasi." 🎜>
Dia menyambung, "Cara kami melakukan sesuatu hari ini ialah kami mengupah orang untuk mengajar rangkaian saraf kami cara bertindak balas, mengajar alat sembang cara bertindak balas Anda hanya berinteraksi dengannya dan ia melihat daripada reaksi anda, oh, bukan itu yang anda mahukan. Anda tidak berpuas hati dengan hasilnya, jadi anda harus melakukan sesuatu yang berbeza pada masa akan datang tidak bersetuju. Yann LeCun, ketua saintis kecerdasan buatan di Meta, percaya bahawa LLM semasa yang menggunakan seni bina GPT tidak dapat menyelesaikan masalah halusinasi. Tetapi terdapat kaedah baru muncul yang mungkin membawa ketepatan yang lebih tinggi kepada LLM di bawah seni bina semasa. Beliau menerangkan, "Salah satu pendekatan yang paling aktif dikaji untuk menambahkan realisme dalam LLM ialah penambahan perolehan—menyediakan model dengan dokumen luaran sebagai sumber dan konteks sokongan Dengan teknik ini, penyelidik berharap dapat mengajar model menggunakan dokumen luaran seperti Carian Google enjin, seperti penyelidik manusia, memetik sumber yang boleh dipercayai dalam jawapan mereka, mengurangkan pergantungan pada pengetahuan fakta yang tidak boleh dipercayai yang dipelajari semasa latihan model ”Bing Chat dan Google Bard sudah pun melakukan ini dengan carian web, tidak lama lagi. versi ChatGPT yang disokong pelayar juga akan dilaksanakan. Selain itu, pemalam ChatGPT direka bentuk untuk melengkapkan data latihan GPT-4 dengan mendapatkan maklumat daripada sumber luaran seperti web dan pangkalan data yang dibina khas. Penambahbaikan ini serupa dengan cara orang yang mempunyai ensiklopedia akan menerangkan fakta dengan lebih tepat berbanding orang yang tidak mempunyai ensiklopedia. Selain itu, model seperti GPT-4 boleh dilatih untuk menyedari apabila ia membuat bahan dan menyesuaikannya dengan sewajarnya. Mitchell percaya bahawa "terdapat beberapa perkara yang lebih mendalam yang boleh dilakukan oleh orang ramai untuk menjadikan ChatGPT dan perkara seperti itu lebih realistik dari awal, termasuk pengurusan data yang lebih canggih dan menggunakan pendekatan seperti PageRank untuk menyelaraskan data latihan dengan 'kepercayaan' Markah dipautkan ... dan model itu juga boleh diperhalusi untuk melindung nilai risiko apabila kurang yakin tentang respons." 
Atas ialah kandungan terperinci Mengapa ChatGPT dan Bing Chat sangat pandai memutar cerita. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Pendaftaran ChatGPT
Pendaftaran ChatGPT
 Ensiklopedia ChatGPT percuma domestik
Ensiklopedia ChatGPT percuma domestik
 Bagaimana untuk memasang chatgpt pada telefon bimbit
Bagaimana untuk memasang chatgpt pada telefon bimbit
 Bolehkah chatgpt digunakan di China?
Bolehkah chatgpt digunakan di China?
 Pengenalan kepada nama domain peringkat atas yang biasa digunakan
Pengenalan kepada nama domain peringkat atas yang biasa digunakan
 Apakah pengekodan yang digunakan di dalam komputer untuk memproses data dan arahan?
Apakah pengekodan yang digunakan di dalam komputer untuk memproses data dan arahan?
 busyboxv1.30.1 tidak boleh boot
busyboxv1.30.1 tidak boleh boot
 Bagaimana untuk menyelesaikan skrin biru 0x0000006b
Bagaimana untuk menyelesaikan skrin biru 0x0000006b








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



