


Potongan imej merujuk kepada mengekstrak latar depan yang tepat dalam imej. Kaedah automatik semasa cenderung untuk mengekstrak semua objek yang menonjol dalam imej secara sembarangan. Dalam makalah ini, penulis mencadangkan tugas baharu yang dipanggil Reference Image Matting (RIM), yang merujuk kepada mengekstrak tikar alfa terperinci bagi objek tertentu, yang paling sesuai dengan penerangan bahasa semula jadi yang diberikan. Walau bagaimanapun, kaedah asas visual yang popular adalah terhad kepada tahap pembahagian, mungkin disebabkan oleh kekurangan set data RIM berkualiti tinggi. Untuk mengisi jurang ini, pengarang telah menubuhkan RefMatte, set data mencabar berskala besar pertama, dengan mereka bentuk sintesis imej yang komprehensif dan enjin penjanaan ekspresi untuk menjana imej sintetik berdasarkan prospek tikar berkualiti tinggi awam semasa, dengan logik fleksibiliti dan sifat terpelbagai yang dilabel semula. .
RefMatte terdiri daripada 230 kategori objek, 47,500 imej, 118,749 entiti kawasan ekspresi dan 474,996 ungkapan, dan boleh dikembangkan lagi dengan mudah pada masa hadapan. Selain itu, penulis juga membina set ujian dunia sebenar yang terdiri daripada 100 imej semula jadi menggunakan anotasi frasa yang dijana secara buatan untuk menilai lagi keupayaan generalisasi model RIM. Mula-mula, tugas RIM dalam dua konteks, berasaskan segera dan berasaskan ekspresi, telah ditakrifkan, dan kemudian beberapa kaedah tikar imej biasa dan reka bentuk model tertentu telah diuji. Keputusan ini memberikan pandangan empirikal tentang batasan kaedah sedia ada serta penyelesaian yang mungkin. Adalah dipercayai bahawa tugas baharu RIM dan set data baharu RefMatte akan membuka hala tuju penyelidikan baharu dalam bidang ini dan mempromosikan penyelidikan masa depan.

Tajuk kertas: Merujuk Padatan Imej
Alamat kertas: https:// arxiv.org/abs/2206.0514 9
Alamat kod : https://github.com/JizhiziLi/RI M
Jenis imej merujuk kepada mengekstrak tikar ahpha lembut pada latar depan dalam imej semula jadi, yang bermanfaat untuk pelbagai Aplikasi hiliran seperti persidangan video, pengeluaran pengiklanan dan promosi e-dagang. Kaedah tikar biasa boleh dibahagikan kepada dua kumpulan: 1) kaedah berasaskan input tambahan, seperti trimap, dan 2) kaedah tikar automatik yang mengekstrak latar depan tanpa campur tangan manusia. Walau bagaimanapun, yang pertama tidak sesuai untuk senario aplikasi automatik, dan yang kedua biasanya terhad kepada kategori objek tertentu, seperti orang, haiwan atau semua objek penting. Cara melakukan tikar imej terkawal bagi objek sewenang-wenangnya, iaitu, untuk mengekstrak tikar alfa objek tertentu yang paling sepadan dengan penerangan bahasa semula jadi yang diberikan, masih menjadi masalah untuk diterokai.
Tugas yang dipacu oleh bahasa seperti pembahagian ungkapan merujuk (RES), pembahagian imej merujuk (RIS), jawapan soalan visual (VQA) dan pemahaman ungkapan merujuk (REC) telah diterokai secara meluas. Kemajuan besar telah dicapai dalam bidang ini berdasarkan banyak set data seperti ReferIt, Google RefExp, RefCOCO, VGPhraseCut dan Cops-Ref. Sebagai contoh, kaedah RES bertujuan untuk membahagikan objek arbitrari yang ditunjukkan oleh huraian bahasa semula jadi. Walau bagaimanapun, topeng yang diperoleh adalah terhad kepada tahap pembahagian tanpa butiran halus disebabkan oleh imej resolusi rendah dan anotasi topeng kasar dalam set data. Oleh itu, ia tidak mungkin digunakan dalam adegan yang memerlukan pemadanan alfa terperinci bagi objek latar depan.

Untuk mengisi kekosongan ini, penulis mencadangkan tugasan baharu yang dipanggil "Referring Image Matting (RIM)" dalam kertas kerja ini. RIM merujuk kepada pengekstrakan objek latar depan khusus dalam imej yang paling sepadan dengan penerangan bahasa semula jadi yang diberikan, bersama-sama dengan tikar alfa berkualiti tinggi yang terperinci. Berbeza daripada tugasan yang diselesaikan oleh dua kaedah tikar di atas, RIM menyasarkan pada tikar imej terkawal bagi objek sewenang-wenang dalam imej yang ditunjukkan oleh penerangan linguistik. Ia mempunyai kepentingan praktikal dalam bidang aplikasi perindustrian dan membuka hala tuju penyelidikan baharu untuk akademik.
Untuk mempromosikan penyelidikan RIM, penulis menubuhkan set data pertama bernama RefMatte, yang terdiri daripada 230 kategori objek, 47,500 imej dan 118,749 entiti kawasan ekspresi serta alfa matte berkualiti tinggi yang sepadan dan 474,996 ekspresi.
Khususnya, untuk membina set data ini, pengarang mula-mula menyemak semula banyak set data tikar awam yang popular, seperti AM-2k, P3M-10k, AIM-500, SIM dan melabelkannya secara manual untuk pemeriksaan teliti setiap objek . Penulis juga menggunakan pelbagai model pra-latihan berasaskan pembelajaran mendalam untuk menjana pelbagai atribut bagi setiap entiti, seperti jantina manusia, umur dan jenis pakaian. Penulis kemudiannya mereka bentuk enjin penjanaan komposisi dan ekspresi yang komprehensif untuk menjana imej komposit dengan kedudukan mutlak dan relatif yang munasabah, dengan mengambil kira objek latar depan yang lain. Akhir sekali, penulis mencadangkan beberapa bentuk logik ungkapan yang menggunakan atribut visual yang kaya untuk menjana penerangan bahasa yang berbeza. Tambahan pula, pengarang mencadangkan set ujian dunia sebenar RefMatte-RW100, yang mengandungi 100 imej yang mengandungi objek berbeza dan ekspresi beranotasi manusia, untuk menilai keupayaan generalisasi kaedah RIM. Gambar di atas menunjukkan beberapa contoh.
Untuk menjalankan penilaian yang adil dan menyeluruh terhadap kaedah terkini dalam tugasan yang berkaitan, penulis menanda arasnya pada RefMatte dalam dua tetapan berbeza, iaitu tetapan berasaskan pembayang dan tetapan berasaskan ekspresi, dalam bentuk huraian linguistik. Memandangkan kaedah perwakilan direka khusus untuk tugasan pembahagian, masih terdapat jurang apabila menggunakannya secara langsung pada tugas RIM.
Untuk menyelesaikan masalah ini, penulis mencadangkan dua strategi untuk menyesuaikannya untuk RIM, iaitu 1) mereka bentuk dengan teliti pengepala potongan ringan bernama CLIPmat di atas CLIPSeg untuk menjana hasil tikar alfa berkualiti tinggi sambil mengekalkan hujungnya- saluran paip boleh dilatih ke hujung; 2) Beberapa kaedah matan berasaskan imej kasar yang berasingan disediakan sebagai penapis selepas untuk menambah baik hasil segmentasi/matan. Keputusan eksperimen yang meluas 1) menunjukkan nilai set data RefMatte yang dicadangkan untuk penyelidikan tugasan RIM, 2) mengenal pasti peranan penting bentuk penerangan bahasa 3) mengesahkan keberkesanan strategi penyesuaian yang dicadangkan;
Sumbangan utama kajian ini adalah tiga kali ganda. 1) Tentukan tugas baharu yang dipanggil RIM, yang bertujuan untuk mengenal pasti dan mengekstrak mat alfa objek latar depan khusus yang paling sesuai dengan perihalan bahasa semula jadi yang diberikan 2) Wujudkan kumpulan data skala besar pertama RefMatte, yang terdiri daripada 47,500 imej dan 118,749 wilayah ekspresi; entiti, dengan tikar alfa berkualiti tinggi dan ekspresi kaya; 3) Kaedah terkini yang mewakili telah ditanda aras dalam dua tetapan berbeza menggunakan dua strategi yang disesuaikan dengan RIM untuk RefMatte Tested dan memperoleh beberapa cerapan berguna.

Dalam bahagian ini, saluran paip untuk membina RefMatte (Bahagian 3.1 dan Bahagian 3.2) dan tetapan tugas (Bahagian 3.3) akan bahagian yang diperkenalkan) dan statistik set data (bahagian 3.5). Imej di atas menunjukkan beberapa contoh RefMatte. Selain itu, pengarang membina set ujian dunia sebenar yang terdiri daripada 100 imej semula jadi yang dianotasi dengan huraian bahasa kaya berlabel secara manual (Bahagian 3.4).
Untuk menyediakan entiti tikar berkualiti tinggi yang mencukupi untuk membantu membina set data RefMatte, penulis menyemak semula set data tikar yang tersedia pada masa ini untuk menapis set data yang memenuhi keperluan prospek. Semua entiti calon kemudiannya dilabelkan secara manual dengan kategori mereka dan atributnya dianotasi menggunakan berbilang model pra-latihan berasaskan pembelajaran mendalam.
Pra-pemprosesan dan penapisan
Disebabkan sifat tugas tikar imej, semua entiti calon hendaklah beresolusi tinggi dan mempunyai kejelasan dalam tikar alfa dan butiran halus. Tambahan pula, data harus tersedia secara terbuka melalui lesen terbuka dan tanpa kebimbangan privasi untuk memudahkan penyelidikan masa depan. Untuk keperluan ini, pengarang menggunakan semua imej latar depan daripada AM-2k, P3M-10k dan AIM-500. Khususnya, untuk P3M-10k, pengarang menapis imej dengan lebih daripada dua tika latar depan melekit untuk memastikan setiap entiti dikaitkan dengan hanya satu tika latar depan. Untuk set data lain yang tersedia, seperti SIM, DIM dan HATT, pengarang menapis imej latar depan tersebut dengan wajah yang boleh dikenal pasti dalam kalangan contoh manusia. Pengarang juga menapis imej latar depan yang mempunyai resolusi rendah atau mempunyai tikar alfa berkualiti rendah. Jumlah akhir entiti ialah 13,187. Untuk imej latar belakang yang digunakan dalam langkah sintesis seterusnya, pengarang memilih semua imej dalam BG-20k.
Anotasi nama kategori entiti
Memandangkan kaedah potong automatik sebelumnya cenderung untuk mengekstrak semua objek latar depan yang menonjol daripada imej, mereka tidak Entiti memberikan nama (kategori) khusus . Walau bagaimanapun, untuk tugas RIM, nama entiti diperlukan untuk menerangkannya. Pengarang melabelkan setiap entiti dengan nama kategori peringkat kemasukan, yang mewakili nama yang paling biasa digunakan orang untuk entiti tertentu. Di sini, strategi separa automatik digunakan. Khususnya, pengarang menggunakan pengesan Mask RCNN dengan tulang belakang ResNet-50-FPN untuk mengesan dan melabel nama kelas secara automatik bagi setiap tika latar depan, dan kemudian memeriksa dan membetulkannya secara manual. RefMatte mempunyai sejumlah 230 kategori. Di samping itu, pengarang menggunakan WordNet untuk menjana sinonim bagi setiap nama kategori untuk meningkatkan kepelbagaian. Pengarang menyemak sinonim secara manual dan menggantikan beberapa daripadanya dengan sinonim yang lebih munasabah.
Beri anotasi atribut entiti
Untuk memastikan semua entiti mempunyai atribut visual yang kaya untuk menyokong pembentukan ekspresi kaya, pengarang menganotasi semua entiti dengan warna, atribut entiti manusia seperti jantina, umur, dan jenis pakaian. Penulis juga menggunakan strategi separa automatik untuk menjana hartanah tersebut. Untuk menjana warna, pengarang mengelompokkan semua nilai piksel imej latar depan, mencari nilai yang paling biasa dan memadankannya dengan warna tertentu dalam warna web. Untuk jantina dan umur, penulis menggunakan model pra-terlatih. Gunakan akal untuk menentukan kumpulan umur berdasarkan umur yang diramalkan. Untuk jenis pakaian, penulis menggunakan model yang telah dilatih. Tambahan pula, diilhamkan oleh klasifikasi latar depan, pengarang menambah atribut yang menonjol atau tidak ketara dan telus atau legap kepada semua entiti, kerana atribut ini juga penting dalam tugasan tikar imej. Akhirnya, setiap entiti mempunyai sekurang-kurangnya 3 atribut, dan entiti manusia mempunyai sekurang-kurangnya 6 atribut.
Berdasarkan entiti potongan yang dikumpul dalam bahagian sebelumnya, penulis mencadangkan enjin sintesis imej dan enjin penjanaan ekspresi untuk membina set data RefMatte. Cara mengatur entiti yang berbeza untuk membentuk imej sintetik yang munasabah, dan pada masa yang sama menjana ungkapan semantik yang jelas, betul dari segi tatabahasa, kaya dan mewah untuk menerangkan entiti dalam imej sintetik ini adalah kunci untuk membina RefMatte, dan ia juga mencabar. Untuk tujuan ini, penulis mentakrifkan enam hubungan kedudukan untuk menyusun entiti yang berbeza dalam imej sintetik dan menggunakan bentuk logik yang berbeza untuk menghasilkan ungkapan yang sesuai.
Enjin komposisi imej
Untuk mengekalkan resolusi tinggi entiti sambil menyusunnya dalam hubungan kedudukan yang munasabah, pengarang menggunakan dua atau tiga untuk setiap entiti imej komposit . Penulis mentakrifkan enam hubungan kedudukan: kiri, kanan, atas, bawah, depan, dan belakang. Untuk setiap perhubungan, imej latar depan pertama kali dijana dan digubah melalui pengadunan alfa dengan imej latar belakang daripada BG-20k. Khususnya, untuk perhubungan kiri, kanan, atas dan bawah, pengarang memastikan bahawa tiada oklusi dalam keadaan latar depan untuk mengekalkan butirannya. Untuk perhubungan sebelum dan selepas, oklusi antara kejadian latar depan disimulasikan dengan melaraskan kedudukan relatifnya. Pengarang menyediakan beg perkataan calon untuk mewakili setiap perhubungan.
Enjin penjanaan ekspresi
Untuk menyediakan kaedah ekspresi yang kaya untuk entiti dalam imej sintetik, pengarang mentakrifkan tiga takrifan untuk setiap entiti daripada perspektif bentuk logik yang berbeza yang ditakrifkan . c) di atas ) ditunjukkan. 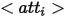
 2.3 Pemisahan set data dan tetapan tugas
2.3 Pemisahan set data dan tetapan tugas
Dataset mempunyai sejumlah 13,187 entiti kusut, di mana 11,799 digunakan untuk membina set latihan ,1,388 untuk set ujian. Bagaimanapun, kategori set latihan dan ujian tidak seimbang kerana kebanyakan entiti tergolong dalam kategori manusia atau haiwan. Secara khusus, antara 11,799 entiti dalam set latihan, terdapat 9,186 manusia, 1,800 haiwan, dan 813 objek. Dalam set ujian 1,388 entiti, terdapat 977 manusia, 200 haiwan, dan 211 objek. Untuk mengimbangi kategori, pengarang mereplikasi entiti untuk mencapai nisbah 5:1:1 manusia:haiwan:objek. Oleh itu, terdapat 10,550 manusia, 2,110 haiwan, dan 2,110 objek dalam set latihan, dan 1,055 manusia, 211 haiwan, dan 211 objek dalam set ujian.
Untuk menjana imej untuk RefMatte, pengarang memilih satu set 5 manusia, 1 haiwan dan 1 objek daripada pembahagian latihan atau ujian dan memasukkannya ke dalam enjin sintesis imej. Bagi setiap kumpulan dalam pembahagian latihan atau ujian, penulis menghasilkan 20 imej untuk membentuk set latihan dan 10 imej untuk membentuk set ujian. Nisbah perhubungan kiri/kanan:atas/bawah:depan/belakang ditetapkan kepada 7:2:1. Bilangan entiti dalam setiap imej ditetapkan kepada 2 atau 3. Untuk konteks, pengarang sentiasa memilih 2 entiti untuk mengekalkan resolusi tinggi bagi setiap entiti. Selepas proses ini, terdapat 42,200 imej latihan dan 2,110 imej ujian. Untuk meningkatkan lagi kepelbagaian gabungan entiti, kami memilih entiti dan perhubungan secara rawak daripada semua calon untuk membentuk 2800 imej latihan dan 390 imej ujian lagi. Akhirnya, terdapat 45,000 imej sintetik dalam set latihan dan 2,500 imej dalam set ujian.Tetapan tugas
Untuk menanda aras pendekatan RIM yang diberikan bentuk penerangan bahasa yang berbeza, pengarang menyediakan dua tetapan dalam RefMatte:
Berasaskan Prompt settin: Penerangan teks dalam tetapan ini ialah gesaan, iaitu nama kategori peringkat kemasukan bagi entiti Contohnya, gesaan dalam gambar di atas ialah bunga, manusia dan alpaca; tetapan: Penerangan teks dalam tetapan ini ialah ungkapan yang dijana dalam bahagian sebelumnya, dipilih daripada ungkapan asas, ungkapan kedudukan mutlak dan ungkapan kedudukan relatif. Beberapa contoh juga boleh dilihat pada gambar di atas. 2.4 Set ujian dunia sebenar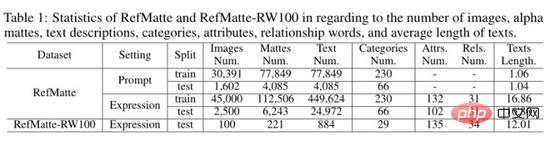
Pengarang mengira statistik set ujian RefMatte dan set ujian RefMatte-RW100 seperti yang ditunjukkan dalam jadual di atas. Untuk tetapan berasaskan segera, memandangkan perihalan teks ialah nama kategori peringkat kemasukan, pengarang mengalih keluar imej dengan berbilang entiti yang tergolong dalam kategori yang sama untuk mengelakkan kesimpulan yang tidak jelas. Oleh itu, dalam tetapan ini, terdapat 30,391 imej dalam set latihan dan 1,602 imej dalam set ujian. Nombor, perihalan teks, kategori, atribut dan perhubungan potongan alfa ditunjukkan dalam jadual di atas masing-masing. Dalam tetapan berasaskan segera, purata panjang teks ialah kira-kira 1, kerana biasanya terdapat hanya satu perkataan bagi setiap kategori, manakala dalam tetapan berasaskan ungkapan ia adalah lebih besar, iaitu kira-kira 16.8 dalam RefMatte dan kira-kira 16.8 dalam RefMatte-RW100 ialah 12.

Pengarang juga menghasilkan awan perkataan bagi gesaan, sifat dan perhubungan dalam RefMatte dalam imej di atas. Seperti yang dapat dilihat, set data mempunyai sebahagian besar manusia dan haiwan kerana ia adalah perkara biasa dalam tugasan tikar imej. Atribut yang paling biasa dalam RefMatte ialah maskulin, kelabu, lutsinar dan menonjol, manakala kata hubungan lebih seimbang.
Disebabkan perbezaan tugas antara RIM dan RIS/RES, hasil penggunaan kaedah RIS/RES secara langsung kepada RIM adalah tidak optimistik. Untuk menyelesaikan masalah ini, penulis mencadangkan dua strategi untuk menyesuaikannya untuk RIM:
1) Menambah kepala tikar: Reka bentuk kepala tikar ringan di atas model sedia ada untuk menghasilkan tikar alfa berkualiti tinggi, sambil mengekalkan hujung- saluran paip boleh dilatih ke hujung. Khususnya, pengarang mereka bentuk penyahkod tikar ringan di atas CLIPSeg, dipanggil CLIPMat
2) Menggunakan penapis tikar: Pengarang menggunakan kaedah tikar berasingan berdasarkan imej kasar sebagai penapis bahagian belakang untuk mempertingkatkan lagi segmentasi/ hasil matting kaedah di atas. Secara khusus, pengarang melatih GFM dan P3M, memasukkan imej dan imej kasar sebagai penapisan potongan.
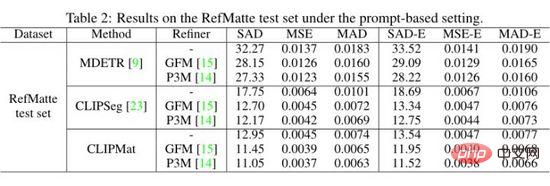
Pengarang menilai MDETR, CLIPSeg dan CLIPMat pada tetapan berasaskan petunjuk pada set ujian RefMatte dan membentangkan keputusan kuantitatif dalam jadual di atas. Dapat dilihat bahawa berbanding dengan MDETR dan CLIPSeg, CLIPMat berprestasi terbaik tanpa mengira sama ada penapisan potongan digunakan atau tidak Sahkan keberkesanan menambah pengepala potongan untuk menyesuaikan CLIPSeg untuk tugas RIM. Tambahan pula, menggunakan salah satu daripada dua penapisan potongan boleh meningkatkan lagi prestasi ketiga-tiga kaedah tersebut.
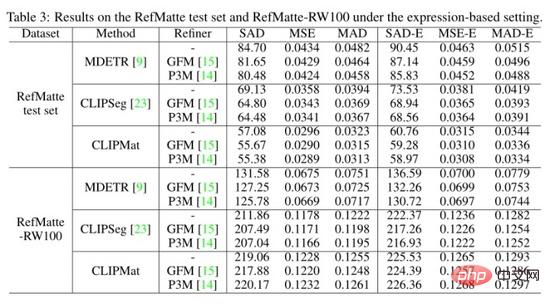
Pengarang juga menilai tiga kaedah di bawah tetapan berasaskan ekspresi pada set ujian RefMatte dan RefMatte-RW100 dan menunjukkan keputusan kuantitatif dalam jadual di atas. CLIPMat sekali lagi menunjukkan keupayaan yang baik untuk mengekalkan lebih banyak butiran pada set ujian RefMatte. Kaedah peringkat tunggal seperti CLIPSeg dan CLIPMat ketinggalan di belakang kaedah dua peringkat, iaitu MDETR, apabila diuji pada RefMatte-RW100, mungkin disebabkan oleh keupayaan pengesan MDETR yang lebih baik untuk memahami semantik silang modal.
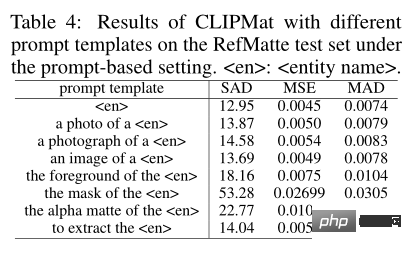
Untuk menyiasat kesan borang input segera, pengarang menilai prestasi templat gesaan yang berbeza. Selain templat tradisional yang digunakan, pengarang juga telah menambah lebih banyak templat yang direka khusus untuk tugasan tikar imej, seperti latar depan/topeng/alpha matte
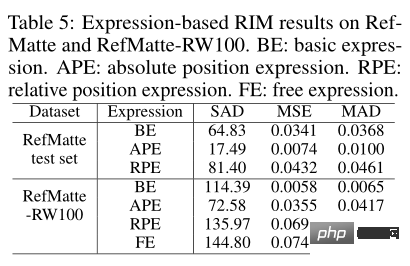
Memandangkan artikel ini memperkenalkan pelbagai jenis ungkapan dalam tugasan, anda boleh melihat kesan setiap jenis pada prestasi potongan. Seperti yang ditunjukkan dalam jadual di atas, model CLIPMat berprestasi terbaik telah diuji pada set ujian RefMatte dan model MDETR telah diuji pada RefMatte-RW100.
Dalam kertas kerja ini, kami mencadangkan tugasan baharu yang dipanggil Reference Image Matting (RIM) dan membina dataset berskala besar RefMatte. Penulis menyesuaikan kaedah perwakilan sedia ada pada tugas RIM yang berkaitan dan mengukur prestasi mereka melalui eksperimen yang meluas pada RefMatte. Keputusan eksperimen kertas ini memberikan pandangan berguna ke dalam reka bentuk model, kesan penerangan teks dan jurang domain antara imej sintetik dan sebenar. Penyelidikan RIM boleh memanfaatkan banyak aplikasi praktikal seperti penyuntingan imej interaktif dan interaksi manusia-komputer. RefMatte boleh memudahkan penyelidikan dalam bidang ini. Walau bagaimanapun, jurang domain sintetik kepada sebenar mungkin mengakibatkan generalisasi terhad kepada imej dunia sebenar.
Atas ialah kandungan terperinci Pembelajaran mendalam mempunyai perangkap baru! Universiti Sydney mencadangkan tugas silang modal baharu, menggunakan teks untuk membimbing potongan imej. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



