


ChatGPT ialah model bahasa terbaharu yang dikeluarkan oleh OpenAI, yang merupakan peningkatan ketara berbanding GPT-3 pendahulunya. Sama seperti kebanyakan model bahasa berskala besar, ChatGPT boleh menjana teks dalam gaya yang berbeza dan untuk tujuan yang berbeza, dengan prestasi yang lebih baik dalam ketepatan, perincian naratif dan koheren kontekstual. Ia mewakili generasi terbaru model bahasa besar daripada OpenAI dan direka bentuk dengan fokus yang kuat pada interaktiviti.
OpenAI menggunakan gabungan pembelajaran penyeliaan dan pengukuhan untuk menala ChatGPT, dengan komponen pembelajaran pengukuhan menjadikan ChatGPT unik. OpenAI menggunakan kaedah latihan "Pembelajaran Pengukuhan dengan Maklum Balas Manusia" (RLHF), yang menggunakan maklum balas manusia dalam latihan untuk meminimumkan output yang tidak membantu, diherotkan atau berat sebelah.
Artikel ini akan menganalisis batasan GPT-3 dan sebab ia timbul daripada proses latihan. Ia juga akan menerangkan prinsip RLHF dan memahami cara ChatGPT menggunakan RLHF untuk mengatasinya masalah yang wujud dalam soalan GPT-3, dan akhirnya batasan pendekatan ini akan diterokai.
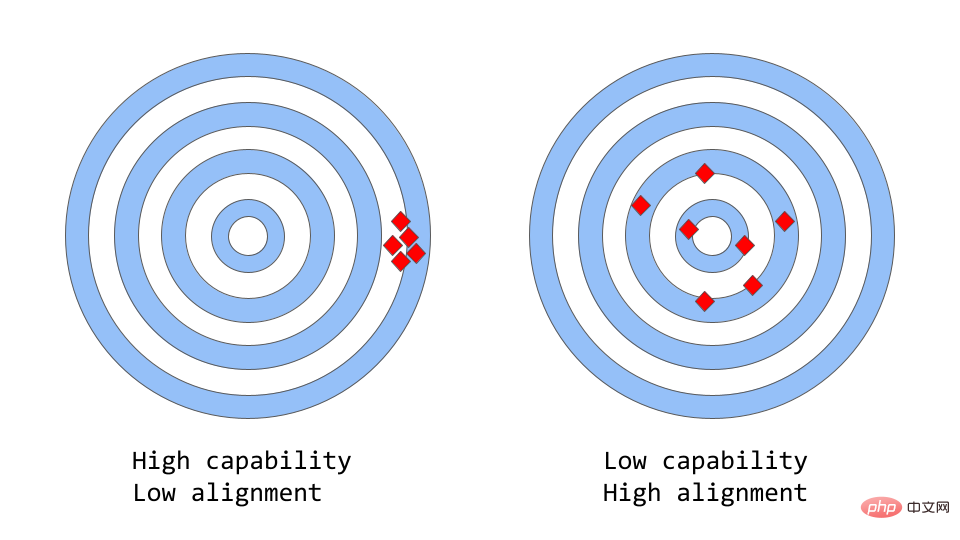
"Konsistensi vs. Keupayaan" boleh Fikirkan daripadanya sebagai analogi yang lebih abstrak tentang "ketepatan vs ketepatan".
Dalam pembelajaran mesin, keupayaan model merujuk kepada keupayaan model untuk melaksanakan tugas atau set tugas tertentu. Keupayaan model biasanya dinilai dengan sejauh mana ia dapat mengoptimumkan fungsi objektifnya. Sebagai contoh, model yang digunakan untuk meramalkan harga pasaran mungkin mempunyai fungsi objektif yang mengukur ketepatan ramalan model. Sesuatu model dianggap mempunyai keupayaan yang tinggi untuk berprestasi jika ia boleh meramalkan perubahan tambang dengan tepat dari semasa ke semasa.
Konsistensi memfokuskan pada perkara yang sebenarnya anda mahu model itu lakukan, bukan perkara yang dilatih untuk dilakukan. Persoalan yang dibangkitkan ialah "sama ada fungsi objektif memenuhi jangkaan", berdasarkan sejauh mana matlamat dan tingkah laku model memenuhi jangkaan manusia. Katakan anda ingin melatih pengelas burung untuk mengklasifikasikan burung sebagai "burung pipit" atau "robin", menggunakan kehilangan logaritma sebagai objektif latihan, dan matlamat utama ialah ketepatan pengelasan yang sangat tinggi. Model mungkin mempunyai kerugian log yang rendah, iaitu model lebih berkebolehan tetapi kurang tepat pada set ujian Ini adalah contoh ketidakkonsistenan, di mana model dapat mengoptimumkan matlamat latihan tetapi tidak konsisten dengan matlamat akhir.
GPT-3 asal ialah model tidak seragam. Model bahasa besar seperti GPT-3 dilatih pada sejumlah besar data teks daripada Internet dan mampu menjana teks seperti manusia, tetapi mereka mungkin tidak selalu menghasilkan output yang sepadan dengan jangkaan manusia. Malah, fungsi objektifnya ialah taburan kebarangkalian ke atas urutan perkataan, digunakan untuk meramalkan perkataan seterusnya dalam urutan itu.
Tetapi dalam aplikasi sebenar, tujuan model ini adalah untuk melaksanakan beberapa bentuk kerja kognitif yang berharga, dan terdapat jurang antara cara model ini dilatih dan bagaimana ia dijangka akan digunakan Perbezaan yang jelas. Walaupun secara matematik, mesin yang mengira taburan statistik bagi urutan perkataan mungkin merupakan pilihan yang cekap untuk bahasa pemodelan, manusia menjana bahasa dengan memilih urutan teks yang paling sesuai dengan situasi tertentu, menggunakan pengetahuan latar belakang yang diketahui dan membantu dalam proses ini. Ini boleh menjadi masalah apabila model bahasa digunakan dalam aplikasi yang memerlukan tahap kepercayaan atau kebolehpercayaan yang tinggi, seperti sistem perbualan atau pembantu peribadi yang bijak.
Walaupun model besar yang dilatih pada jumlah data yang besar ini telah menjadi sangat berkuasa sejak beberapa tahun kebelakangan ini, mereka sering gagal memenuhi potensi mereka apabila digunakan dalam amalan untuk membantu menjadikan kehidupan orang ramai lebih mudah. Isu konsistensi dalam model bahasa besar sering menunjukkan dirinya sebagai:
Tetapi dari manakah datangnya isu konsistensi? Adakah cara model bahasa dilatih itu sendiri terdedah kepada ketidakkonsistenan?
Ramalan token seterusnya dan pemodelan bahasa bertopeng ialah teknologi teras yang digunakan untuk melatih model bahasa. Dalam pendekatan pertama, model diberikan urutan perkataan sebagai input dan diminta untuk meramalkan perkataan seterusnya dalam urutan tersebut. Jika anda memberikan model ayat input:
"Kucing itu duduk di atas"
ia mungkin meramalkan perkataan seterusnya sebagai "tikar", "kerusi" atau " floor" kerana perkataan ini muncul dengan kebarangkalian yang tinggi dalam konteks sebelumnya; model bahasa sebenarnya dapat menilai kemungkinan setiap perkataan yang mungkin diberikan pada urutan sebelumnya.
Kaedah pemodelan bahasa bertopeng ialah varian ramalan Token Seterusnya di mana beberapa perkataan dalam ayat input digantikan dengan token khas, seperti [MASK]. Model kemudian diminta untuk meramalkan perkataan yang betul yang harus dimasukkan ke dalam kedudukan topeng. Jika anda memberikan model satu ayat:
"[MASK] terletak pada "
ia mungkin meramalkan bahawa perkataan yang harus diisi dalam kedudukan TOPENG adalah "kucing" dan "anjing" ".
Salah satu kelebihan fungsi objektif ini ialah ia membolehkan model mempelajari struktur statistik bahasa, seperti urutan perkataan biasa dan pola penggunaan perkataan. Ini selalunya membantu model menjana teks yang lebih semula jadi dan fasih, dan merupakan langkah penting dalam fasa pra-latihan setiap model bahasa.
Walau bagaimanapun fungsi objektif ini juga boleh menyebabkan masalah, terutamanya kerana model tidak dapat membezakan antara ralat penting dan ralat tidak penting. Satu contoh yang sangat mudah ialah jika anda memberi contoh ayat:
"Empayar Rom [MASK] dengan pemerintahan Augustus
ia mungkin meramalkan MASK The kedudukan hendaklah diisi dengan "mula" atau "berakhir" kerana kebarangkalian berlakunya kedua-dua perkataan ini adalah sangat tinggi.
Secara amnya, strategi latihan ini mungkin membawa kepada prestasi model bahasa yang tidak konsisten pada beberapa tugas yang lebih kompleks, sebagai model yang hanya dilatih untuk meramal perkataan seterusnya dalam urutan teks Beberapa lebih tinggi -perwakilan peringkat maknanya mungkin tidak semestinya dipelajari. Oleh itu, model ini sukar untuk digeneralisasikan kepada tugasan yang memerlukan pemahaman bahasa yang lebih mendalam.
Penyelidik sedang mengkaji pelbagai kaedah untuk menyelesaikan masalah ketekalan dalam model bahasa besar. ChatGPT adalah berdasarkan model asal GPT-3, tetapi ia dilatih lebih lanjut menggunakan maklum balas manusia untuk membimbing proses pembelajaran untuk menangani ketidakkonsistenan dalam model. Teknologi khusus yang digunakan ialah RLHF yang disebutkan di atas. ChatGPT ialah model pertama yang menggunakan teknologi ini dalam senario dunia sebenar.
Jadi bagaimanakah ChatGPT menggunakan maklum balas manusia untuk menyelesaikan masalah konsistensi?
Kaedah ini secara amnya merangkumi tiga langkah berbeza:
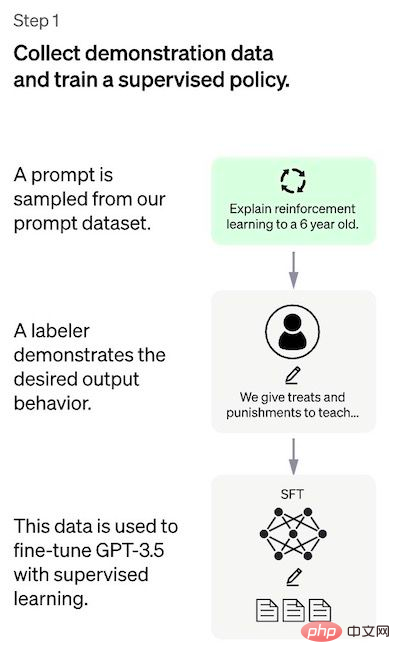
Langkah pertama ialah mengumpul data untuk melatih Model dasar yang diselia.
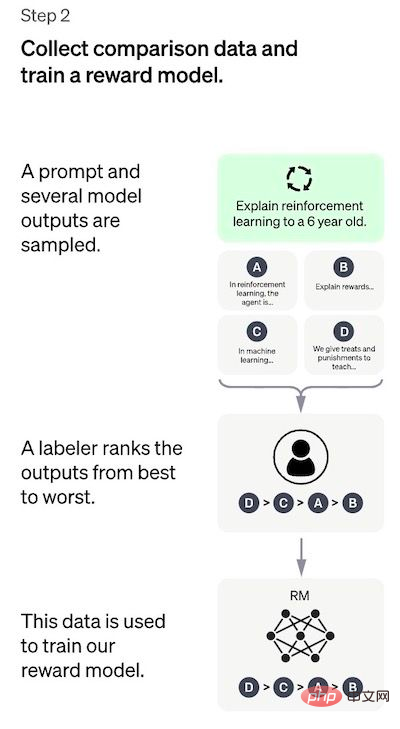
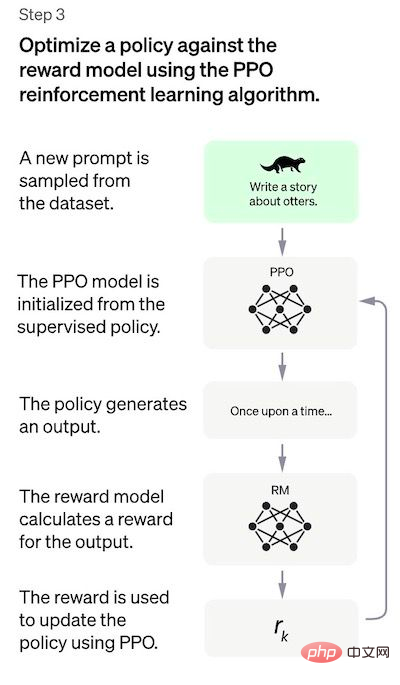
Untuk mencipta bot sembang universal seperti ChatGPT, pembangun menala di atas "model kod" dan bukannya model teks biasa. Disebabkan jumlah data yang terhad dalam langkah ini, model SFT yang diperoleh melalui proses ini mungkin mengeluarkan teks yang masih tidak membimbangkan pengguna, dan sering mengalami persoalan yang tidak konsisten. Masalahnya di sini ialah langkah pembelajaran yang diselia mempunyai kos kebolehskalaan yang tinggi. Untuk mengatasi masalah ini, strategi yang digunakan adalah dengan meminta annotator manusia mengisih keluaran berbeza model SFT untuk mencipta model RM, dan bukannya meminta anotor manusia mencipta lebih besar yang diperhalusi. model. Langkah 2: Melatih model ganjaran Matlamat langkah ini adalah untuk mempelajari fungsi objektif secara langsung daripada data tersebut. Tujuan fungsi ini adalah untuk menjaringkan output model SFT, yang mewakili betapa diinginkan output ini kepada manusia. Ini sangat mencerminkan keutamaan khusus dari anotor manusia yang dipilih dan garis panduan biasa yang mereka setuju untuk ikuti. Akhirnya, proses ini akan menghasilkan sistem yang meniru keutamaan manusia daripada data. Cara ia berfungsi ialah: Penjelasan lebih mudah untuk mengisih output daripada menandai dari awal, dan prosesnya boleh menjadi lebih cekap untuk dikembangkan . Dalam amalan, bilangan gesaan yang dipilih adalah sekitar 30-40k dan termasuk kombinasi berbeza keluaran yang diisih. Langkah 3: Penalaan halus model SFT menggunakan model PPO Dalam langkah ini pembelajaran pengukuhan diterapkan dengan mengoptimumkan model RM untuk menala model SFT. Algoritma khusus yang digunakan dipanggil pengoptimuman dasar proksimal (PPO), dan model penalaan dipanggil model pengoptimuman dasar proksimal. Apakah itu PPO? Ciri-ciri utama algoritma ini adalah seperti berikut: Penilaian Prestasi Model dinilai berdasarkan tiga kriteria: Kebergunaan: Nilaikan keupayaan model untuk mengikuti arahan pengguna dan mengekstrapolasi arahan. Regression prestasi pada set data ini boleh dikurangkan dengan banyak dengan helah yang dipanggil pencampuran pra-latihan: dikira dengan mencampurkan kecerunan model SFT dan model PPO semasa latihan model PPO melalui penurunan kecerunan Kemas kini kecerunan. Kelemahan kaedah Keutamaan pencatat manual yang menjana data demo; Bacaan berkaitan:
Penyelidik yang mereka bentuk kajian dan menulis huraian label;
Selain batasan "endogen" yang jelas ini, kaedah ini juga mempunyai beberapa kelemahan dan masalah lain yang perlu diselesaikan:
Atas ialah kandungan terperinci Terangkan secara ringkas prinsip kerja di sebalik ChatGPT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



