


Prestasi menakjubkan ChatGPT dalam senario beberapa pukulan dan sifar pukulan telah menjadikan penyelidik lebih bertekad bahawa "pra-latihan" adalah laluan yang betul.
Model Asas Pralatih (PFM) dianggap sebagai asas untuk pelbagai tugas hiliran di bawah mod data yang berbeza, iaitu berdasarkan data berskala besar, BERT, GPT-3, Pra -model asas yang terlatih seperti MAE, DALLE-E dan ChatGPT dilatih untuk menyediakan permulaan parameter yang munasabah untuk aplikasi hiliran.
Idea pra-latihan di sebalik PFM memainkan peranan penting dalam penerapan model besar, yang berbeza daripada penggunaan konvolusi sebelumnya dan Modul rekursif menggunakan kaedah yang berbeza untuk pengekstrakan ciri Kaedah pra-latihan generatif (GPT) menggunakan Transformer sebagai pengekstrak ciri untuk melakukan latihan autoregresif pada set data yang besar.
Memandangkan PFM telah mencapai kejayaan besar dalam pelbagai bidang, sejumlah besar kaedah, set data dan penunjuk penilaian telah dicadangkan dalam kertas kerja yang diterbitkan dalam beberapa tahun kebelakangan ini BERT. Kajian menyeluruh menjejaki proses pembangunan ChatGPT.
Baru-baru ini, penyelidik dari Beihang University, Michigan State University, Lehigh University, Nanyang Technological Institute, Duke dan banyak lagi universiti dan syarikat terkenal di dalam dan luar negara bersama-sama menulis artikel mengenai ramalan Kajian semula model asas latihan ini menyediakan kemajuan penyelidikan terkini dalam bidang teks, imej dan graf, serta cabaran dan peluang semasa dan akan datang.

Pautan kertas: https://arxiv.org/pdf/2302.09419.pdf
Penyelidikan Kami mula-mula menyemak komponen asas dan pra-latihan pemprosesan bahasa semula jadi, penglihatan komputer, dan pembelajaran graf kemudian membincangkan PFM lanjutan lain untuk model data lain dan PFM bersatu dengan mengambil kira kualiti dan kuantiti data dan prinsip asas penyelidikan PFM , termasuk kecekapan model dan pemampatan, keselamatan dan privasi akhirnya, artikel itu menyenaraikan beberapa kesimpulan utama, termasuk hala tuju penyelidikan masa depan, cabaran dan isu terbuka;
Model asas pra-latihan (PFM) merupakan bahagian penting dalam membina sistem kecerdasan buatan dalam era data besar Tiga bidang kecerdasan buatan utama pemprosesan bahasa semula jadi (NLP), penglihatan komputer (CV) dan pembelajaran graf (GL) telah dikaji dan digunakan secara meluas.
PFM ialah model umum yang berkesan dalam pelbagai bidang atau dalam tugas merentas domain, menunjukkan potensi besar dalam pembelajaran perwakilan ciri dalam pelbagai tugas pembelajaran, seperti klasifikasi teks, Penjanaan teks, imej pengelasan, pengesanan objek dan pengelasan graf, dsb.
PFM menunjukkan prestasi cemerlang dalam melatih pelbagai tugas dengan korpora berskala besar dan memperhalusi tugas berskala kecil yang serupa, membolehkan untuk memulakan pemprosesan data yang pantas.
PFM adalah berdasarkan teknologi pra-latihan, yang bertujuan untuk menggunakan sejumlah besar data dan tugas untuk melatih model umum, yang boleh diperhalusi dengan mudah dalam aplikasi hiliran yang berbeza.
Idea pra-latihan berpunca daripada pembelajaran pemindahan dalam tugasan CV Selepas menyedari keberkesanan pra-latihan dalam bidang CV, orang ramai mula menggunakan teknologi pra-latihan untuk meningkatkan prestasi model dalam bidang lain. Apabila teknik pra-latihan digunakan dalam bidang NLP, model bahasa (LM) yang terlatih dengan baik boleh menangkap pengetahuan yang kaya yang bermanfaat untuk tugas hiliran, seperti kebergantungan jangka panjang, hubungan hierarki, dsb.
Di samping itu, kelebihan ketara pra-latihan dalam bidang NLP ialah data latihan boleh datang daripada mana-mana korpus teks tidak berlabel, iaitu, terdapat jumlah latihan yang tidak terhad. dalam data proses pra-latihan.
Pra-latihan awal ialah kaedah statik, seperti NNLM dan Word2vec, yang sukar disesuaikan dengan persekitaran semantik yang berbeza, penyelidik kemudiannya mencadangkan teknologi pra-latihan dinamik, seperti BERT dan XLNet tunggu.

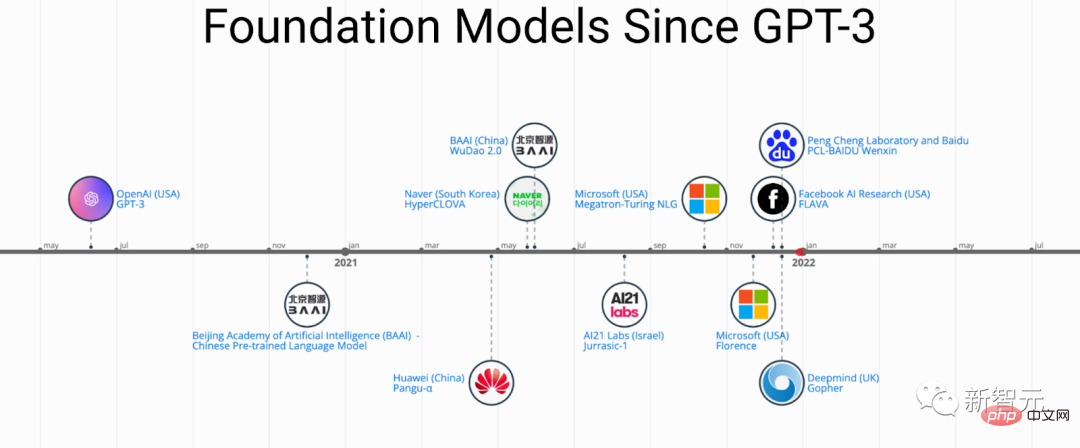
Sejarah dan evolusi PFM dalam bidang NLP, CV dan GL
Berdasarkan pra-latihan PFM teknologi menggunakan korpora besar untuk mempelajari perwakilan semantik umum Dengan pengenalan karya perintis ini, pelbagai PFM telah muncul dan digunakan untuk tugas dan aplikasi hiliran.
Kes aplikasi PFM yang terkenal ialah ChatGPT yang popular baru-baru ini.
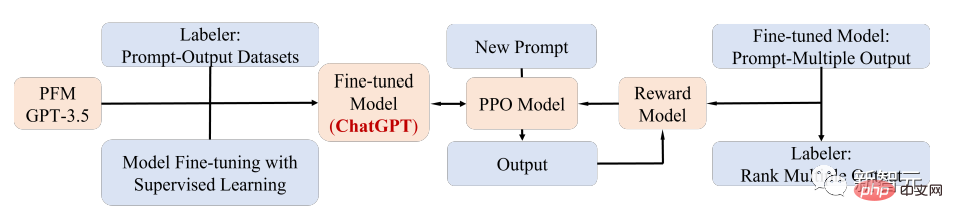
ChatGPT ialah Transformer pra-latihan generatif, iaitu GPT-3.5, selepas latihan pada korpus campuran teks dan kod. Diperoleh melalui penalaan halus; ChatGPT menggunakan teknologi maklum balas manusia (RLHF), yang kini merupakan kaedah yang paling menjanjikan untuk memadankan LM besar dengan niat manusia.
Prestasi unggul ChatGPT mungkin membawa kepada titik kritikal dalam transformasi paradigma latihan setiap jenis PFM, iaitu, aplikasi teknologi penjajaran arahan, termasuk pembelajaran pengukuhan ( RL), penalaan segera dan rantaian pemikiran, dan akhirnya ke arah kecerdasan buatan umum.
Dalam artikel ini, penyelidik terutamanya mengkaji PFM berkaitan teks, imej dan graf, yang juga merupakan kaedah klasifikasi penyelidikan yang agak matang.
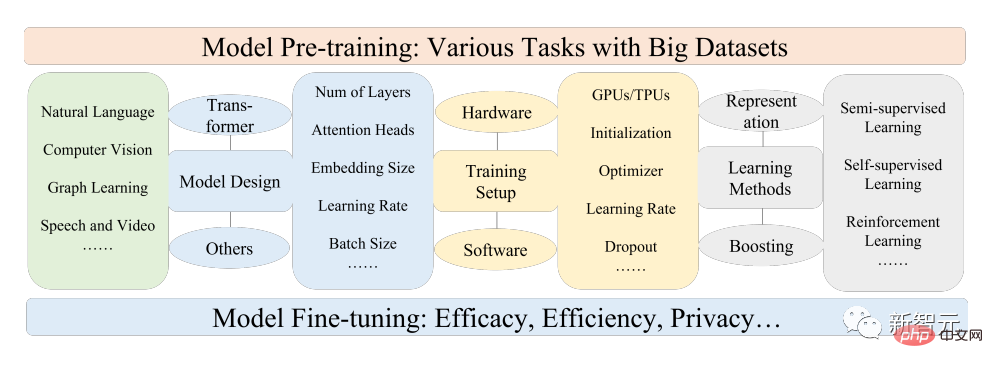
Untuk teks, model bahasa boleh mencapai pelbagai tugas dengan meramal perkataan atau watak seterusnya, contohnya, PFM boleh digunakan untuk terjemahan mesin, sistem menjawab soalan, pemodelan topik, analisis sentimen, dsb.
Untuk imej, serupa dengan PFM dalam teks, set data berskala besar digunakan untuk melatih model besar yang sesuai untuk pelbagai tugasan CV.
Untuk graf, idea pra-latihan yang serupa juga digunakan untuk mendapatkan PFM, yang boleh digunakan untuk banyak tugas hiliran.
Selain PFM untuk domain data tertentu, artikel itu juga menyemak dan menerangkan beberapa PFM lanjutan lain, seperti PFM untuk suara, video dan data merentas domain serta PFM berbilang modal .
Di samping itu, trend gabungan besar PFM yang mampu mengendalikan pelbagai modaliti muncul, iaitu apa yang dipanggil PFM bersatu mula-mula mentakrifkan konsep PFM bersatu, dan kemudian PFM bersatu yang paling maju dalam penyelidikan baru-baru ini disemak, termasuk OFA, UNIFIED-IO, FLAVA, BEiT-3, dsb.
Berdasarkan ciri-ciri PFM sedia ada dalam ketiga-tiga bidang ini, penyelidik membuat kesimpulan bahawa PFM mempunyai dua kelebihan utama berikut:
1 . Hanya penalaan halus minimum diperlukan untuk meningkatkan prestasi model pada tugas hiliran; 2. PFM telah lulus ujian dari segi kualiti.
Daripada membina model dari awal untuk menyelesaikan masalah yang sama, pilihan yang lebih baik ialah menggunakan PFM pada set data yang berkaitan dengan tugas.
Prospek besar PFM telah memberi inspirasi kepada banyak kerja berkaitan untuk memfokuskan pada isu seperti kecekapan model, keselamatan dan pemampatan.
Ciri-ciri ulasan ini ialah:
Para penyelidik menjejaki hasil penyelidikan terkini mengenai PFM dalam NLP, CV dan Perkembangan dalam GL diringkaskan dengan kukuh, dibincangkan dan disediakan dengan refleksi tentang reka bentuk PFM biasa dan kaedah pra-latihan dalam tiga bidang aplikasi utama ini.Rujukan: https://arxiv.org/abs/2302.09419
Atas ialah kandungan terperinci Daripada BERT ke ChatGPT, tinjauan menyeluruh sembilan institusi penyelidikan terkemuka termasuk Universiti Beihang: 'model asas pra-latihan' yang telah kami usahakan bersama selama ini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



