


Penterjemah |. Cui Hao
Penilai |. dan visual menunjukkan hasilnya.
Terdapat banyak gembar-gembur dalam dunia bioteknologi tertumpu pada penemuan dadah revolusioner. Lagipun, dekad yang lalu adalah zaman keemasan untuk bidang itu. Berbanding dekad sebelumnya, 73% lebih banyak ubat baharu telah diluluskan antara 2012 dan 2021 - peningkatan 25% daripada dekad sebelumnya. Ini termasuk imunoterapi untuk merawat kanser, terapi gen dan, sudah tentu, vaksin Covid. Dari aspek ini dapat dilihat bahawa industri farmaseutikal berjalan dengan baik. 
Itulah sebabnya ramai yang menaruh harapan pada kecerdasan buatan (AI), seperti pembelajaran mesin statistik, untuk membantu mempercepatkan pembangunan ubat baharu, daripada pengecaman sasaran awal kepada ujian. Walaupun beberapa sebatian telah dikenal pasti menggunakan pelbagai algoritma pembelajaran mesin, sebatian ini masih dalam penemuan awal atau peringkat pembangunan praklinikal. Janji kecerdasan buatan untuk merevolusikan penemuan dadah kekal sebagai janji yang menarik tetapi tidak ditunaikan.
Apakah kecerdasan buatan?
Untuk merealisasikan janji ini, adalah penting untuk memahami maksud kecerdasan buatan. Dalam beberapa tahun kebelakangan ini, istilah kecerdasan buatan telah menjadi istilah yang agak popular tanpa banyak kandungan teknikal. Jadi, apakah kecerdasan buatan sebenar?
Walaupun orang Bayesian dan penghubung telah mendapat banyak perhatian umum sepanjang dekad yang lalu, ahli simbol tidak begitu. Semiotik mencipta gambaran realistik dunia berdasarkan set peraturan untuk penaakulan logik. Sistem AI simbolik tidak mempunyai publisiti besar yang dinikmati oleh jenis AI lain, tetapi mereka mempunyai keupayaan unik dan penting yang tidak dimiliki oleh jenis lain: penaakulan automatik dan perwakilan pengetahuan.
Perwakilan pengetahuan bioperubatan
Malah, masalah perwakilan pengetahuan merupakan salah satu masalah terbesar dalam penemuan dadah. Perisian pangkalan data sedia ada, seperti pangkalan data hubungan atau pangkalan data graf, berjuang untuk mewakili dan memahami dengan tepat selok-belok biologi.Inilah yang TypeDB, perisian pangkalan data sumber terbuka, bertujuan untuk dicapai - untuk membolehkan pembangun mencipta perwakilan realistik bagi domain yang sangat kompleks yang boleh dieksploitasi oleh komputer untuk mendapatkan cerapan.
Sistem jenis TypeDB adalah berdasarkan konsep perhubungan entiti dan mewakili data yang disimpan dalam TypeDB. Ini menjadikannya cukup berkuasa untuk menangkap pengetahuan domain bioperubatan yang kompleks (melalui penaakulan jenis, hubungan bersarang, hubungan hiper, penaakulan peraturan, dll.), membolehkan saintis memperoleh cerapan dan mempercepatkan masa pembangunan ubat.
Ini digambarkan melalui contoh syarikat farmaseutikal besar yang bergelut selama lebih daripada lima tahun untuk memodelkan rangkaian penyakit menggunakan piawaian Web Semantik, tetapi berjaya melaksanakannya dalam masa tiga minggu sahaja selepas berhijrah ke TypeDB mencapai matlamat ini.
Sebagai contoh, model bioperubatan yang menerangkan protein, gen dan penyakit yang ditulis dalam TypeQL (bahasa pertanyaan TypeDB) akan kelihatan seperti ini:
Untuk contoh lengkap yang berfungsi, Sumber terbuka graf pengetahuan bioperubatan boleh didapati di Github. Ini dimuatkan daripada pelbagai sumber bioperubatan yang terkenal seperti Uniprot, Disgenet, Reactome dan lain-lain. Dengan data yang disimpan dalam TypeDB, anda boleh menjalankan pertanyaan yang menanyakan soalan seperti: Ubat manakah yang berinteraksi dengan gen yang berkaitan dengan virus SARS?define protein sub entity, owns uniprot-id, plays protein-disease-association:protein, plays encode:encoded-protein; gene sub entity, owns entrez-id, plays gene-disease-association:gene, plays encode:encoding-gene; disease sub entity, owns disease-name, plays gene-disease-association:disease, plays protein-disease-association:disease; encode sub relation, relates encoded-protein, relates encoding-gene; protein-disease-association sub relation, relates protein, relates disease; gene-disease-association sub relation, relates gene, relates disease; uniprot-id sub attribute, value string; entrez-id sub attribute, value string; disease-name sub attribute, value string;
Untuk menjawab soalan ini, kita boleh menggunakan pertanyaan berikut dalam TypeQL.
Menjalankan ini akan menyebabkan TypeDB mengembalikan data yang sepadan dengan kriteria pertanyaan. dan boleh divisualisasikan dalam TypeDB Studio seperti yang ditunjukkan di bawah, yang akan membantu memahami ubat berkaitan yang mungkin patut disiasat lanjut.通过自动推理,TypeDB也可以推断出数据库中不存在的知识。这是通过编写规则来完成的,这些规则构成了TypeDB中模式的一部分。例如,一个规则可以推断出一个基因和一种疾病之间的关联,如果该基因编码的蛋白质与该疾病有关。这样的规则将被写成:
rule inference-example:
when {
(encoding-gene: $gene, encoded-protein: $protein) isa encode;
(protein: $protein, disease: $disease) isa protein-disease-association;
} then {
(gene: $gene, disease: $disease) isa gene-disease-association;
};然后,如果我们要插入以下数据:
TypeDB将能够推断出基因和疾病之间的联系,即使没有插入到数据库中。在这种情况下,以下关系基因-疾病-关联将被推断出来。
match $gene isa gene, has gene-id "2"; $disease isa disease, has disease-name $dn; ; (gene: $gene, disease:$disease) isa gene-disease-assocation;
有了TypeDB对生物医学数据(符号)进行表示,再加上机器学习的上下文知识就可以让整个系统变得更加强大,从而增强洞察力。例如,可以通过药物探索管道发现有希望的目标。
寻找有希望的目标的方法是使用链接预测算法。TypeDB的规则引擎允许这样的ML模型执行,该模型通过推理推断对事实进行学习。这意味着从对平面的、无背景的数据学习转向对推理的、有背景的知识学习。其中一个好处是,根据领域的逻辑规则,预测可以被概括到训练数据的范围之外,并减少所需的训练数据量。
这样一个药物发现的工作流程如下:
1. 查询TypeDB,创建上下文知识的子图,利用TypeDB的全部表达能力。
2. 将子图转化为嵌入(embedding),并将这些嵌入到图学习算法中。
3. 预测结果(例如,作为基因-疾病关联之间的概率分数)可以被插入TypeDB,并用于验证/优先考虑某些目标。
有了数据库中的这些预测,我们可以提出更高层次的问题,利用这些预测与数据库中更广泛的背景知识。比如说:什么是最有可能成为黑色素瘤的基因目标,这些基因编码的蛋白质在黑色素细胞中如何表达?
用TypeQL写,这个问题看起来如下:
match $gene isa gene, has gene-id $gene-id; $protein isa protein; $cell isa cell, has cell-type "melanocytes"; $disease isa disease, has disease-name "melanoma"; ($gene, $protein) isa encode; ($protein, $cell) isa expression; ($gene, $disease) isa gene-disease-association, has prob $p; get $gene-id; sort desc $p;
这个查询的结果将是一个按概率分数排序的基因列表(如图学习者预测的):
{$gid "TOPGENE" isa gene-id;}
{$gid "BESTGENE" isa gene-id;}
{$gid "OTHERTARGET" isa gene-id;}
...然后,我们可以进一步研究这些基因,例如通过了解每个基因的生物学背景。比方说,我们想知道TOPGENE基因编码的蛋白质所处的组织。我们可以写下面的查询。
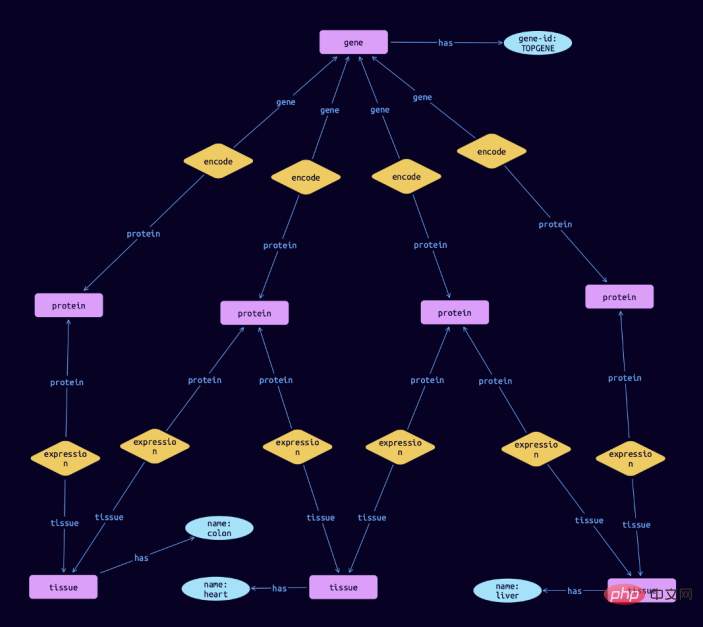
match $gene isa gene, has gene-id $gene-id; $gene-id "TOPGENE"; $protein isa protein; $tissue isa tissue, has name $name; $rel1 ($gene, $protein); $rel2 ($protein, $tissue);
在TypeDB Studio中可视化的结果,可以显示这个基因编码的蛋白质在结肠、心脏和肝脏中的表达:
世界迫切需要创造治疗破坏性疾病的解决方案,希望通过人工智能的创新建立一个更健康的世界,在这个世界中每种疾病都可以被治疗。人工智能作用于药物探索仍处于起步阶段,但是如果一旦实现将会让生物学释放出新的创新浪潮,并使21世纪真正成为属于它的纪元。
在这篇文章中,我们看了TypeDB是如何实现生物医学知识的符号化表示,以及如何改善ML来为药物探索做出贡献的。在药物探索中应用人工智能的科学家们使用TypeDB来分析疾病网络,更好地理解生物医学研究的复杂性,并发现新的和突破性的治疗方式。
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。
原文标题:Artificial Intelligence in Drug Discovery,作者:Tomás Sabat
Atas ialah kandungan terperinci Kecerdasan Buatan dalam Penemuan Perubatan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Aplikasi kecerdasan buatan dalam kehidupan
Aplikasi kecerdasan buatan dalam kehidupan
 Apakah konsep asas kecerdasan buatan
Apakah konsep asas kecerdasan buatan
 pengaturcaraan berbilang benang java
pengaturcaraan berbilang benang java
 Perbezaan antara berlabuh dan bertujuan
Perbezaan antara berlabuh dan bertujuan
 Bagaimana untuk membuka vt
Bagaimana untuk membuka vt
 Bagaimana untuk mendayakan pelayan TFTP
Bagaimana untuk mendayakan pelayan TFTP
 Kaedah pelaksanaan fungsi main balik dalam talian Python
Kaedah pelaksanaan fungsi main balik dalam talian Python
 Apakah kaedah untuk mencegah suntikan sql?
Apakah kaedah untuk mencegah suntikan sql?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



