


Penjanaan imej perspektif baharu (NVS) ialah bidang aplikasi penglihatan komputer Dalam pertandingan SuperBowl 1998, RI CMU menunjukkan NVS diberikan penglihatan stereo berbilang kamera (MVS) Pada masa itu, teknologi ini dipindahkan ke Amerika Syarikat Sebuah stesen TV sukan, tetapi ia tidak dikomersialkan pada akhirnya; Syarikat Penyiaran BBC British melabur dalam penyelidikan dan pembangunan untuk ini, tetapi ia tidak benar-benar dikomersialkan.
Dalam bidang rendering berasaskan imej (IBR), aplikasi NVS mempunyai cabang iaitu rendering berasaskan imej mendalam (DBIR). Di samping itu, TV 3D, yang sangat popular pada tahun 2010, juga perlu mendapatkan kesan stereoskopik binokular daripada video monokular, tetapi disebabkan ketidakmatangan teknologi, ia tidak menjadi popular pada akhirnya. Pada masa itu, kaedah berasaskan pembelajaran mesin telah pun mula dikaji Contohnya, Youtube menggunakan kaedah carian imej untuk mensintesis peta kedalaman.
Beberapa tahun lalu saya memperkenalkan aplikasi pembelajaran mendalam dalam NVS: Kaedah penjanaan imej perspektif baharu berdasarkan pembelajaran mendalam
Terkini perenggan Dari masa ke masa, Medan Sinaran Neural (NeRF) telah menjadi paradigma yang berkesan untuk mewakili pemandangan dan mensintesis imej fotorealistik, dan aplikasinya yang paling langsung ialah NVS. Had utama NeRF tradisional ialah ia selalunya tidak dapat menghasilkan pemaparan berkualiti tinggi pada sudut pandangan baharu yang jauh berbeza daripada sudut pandangan latihan. Berikut ialah perbincangan tentang kaedah generalisasi NeRF Pengenalan asas prinsip NeRF diabaikan di sini. Jika anda berminat, sila rujuk kertas ulasan:
Kertas [2] mencadangkan kedalaman sejagat Rangkaian saraf MVSNeRF, mencapai generalisasi rentas adegan, membuat kesimpulan medan sinaran yang dibina semula daripada hanya tiga paparan input berdekatan. Kaedah ini menggunakan volum imbasan satah (digunakan secara meluas dalam penglihatan stereo berbilang paparan) untuk penaakulan pemandangan yang sedar geometri dan menggabungkannya dengan pemaparan volum berasaskan fizikal untuk pembinaan semula medan sinaran saraf.
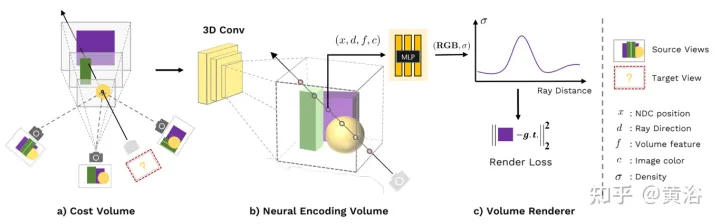
Kaedah ini memanfaatkan kejayaan MVS mendalam untuk menggunakan konvolusi 3D pada volum kos untuk melatih rangkaian neural yang boleh digeneralisasikan untuk tugas pembinaan semula 3D. Tidak seperti kaedah MVS, yang hanya melakukan inferens kedalaman pada entiti kos sedemikian, rangkaian ini melakukan inferens pada geometri pemandangan dan rupa serta mengeluarkan medan sinaran saraf, dengan itu membolehkan sintesis paparan. Khususnya, menggunakan CNN 3D, voxel pengekodan adegan neural dibina semula (daripada voxel asal), yang terdiri daripada ciri neural voxel yang mengekodkan geometri pemandangan tempatan dan maklumat rupa. Kemudian, perceptron berbilang lapisan (MLP) menyahkod ketumpatan volum dan sinaran pada lokasi berturut-turut sewenang-wenang dalam volum yang dikodkan menggunakan ciri saraf yang diinterpolasi secara trilinear. Pada asasnya, volum pengekodan ialah perwakilan saraf tempatan medan sinaran setelah dianggarkan, ia boleh digunakan terus (membuang CNN 3D) untuk perarakan sinar yang boleh dibezakan untuk pemaparan akhir.
Berbanding dengan kaedah MVS sedia ada, MVSNeRF mendayakan pemaparan saraf yang boleh dibezakan, melatih tanpa pengawasan 3D dan mengoptimumkan masa inferens untuk meningkatkan lagi kualiti. Berbanding dengan kaedah pemaparan saraf sedia ada, seni bina seperti MVS secara semula jadi mampu membuat penaakulan korespondensi silang pandangan, yang membantu membuat generalisasi kepada adegan ujian yang tidak kelihatan dan membawa kepada pembinaan semula dan pemaparan adegan saraf yang lebih baik.
Rajah 1 ialah gambaran keseluruhan MVSNeRF: (a) Berdasarkan parameter kamera, ledingkan pertama (transformasi homografi) ciri imej 2D pada sapuan satah (plane sweep) untuk membina ontologi; varians Jumlah kos mengekodkan perubahan penampilan imej antara paparan input yang berbeza, mengambil kira perubahan penampilan yang disebabkan oleh geometri pemandangan dan kesan cahaya dan gelap yang berkaitan dengan pandangan (b) CNN 3D kemudiannya digunakan untuk membina semula voxel pengekodan saraf; ciri saraf; 3D CNN ialah UNet 3D yang boleh menyimpulkan dan menyebarkan maklumat penampilan pemandangan secara berkesan, menghasilkan volum pengekodan adegan yang bermakna Nota: Jumlah pengekodan ini adalah ramalan tanpa pengawasan dan disimpulkan menggunakan pemaparan volum dalam latihan hujung ke hujung; piksel imej asal digabungkan ke peringkat regresi volum seterusnya, supaya frekuensi tinggi yang hilang melalui pensampelan rendah boleh dipulihkan; sifat akhirnya diberikan oleh perjalanan sinar yang boleh dibezakan.
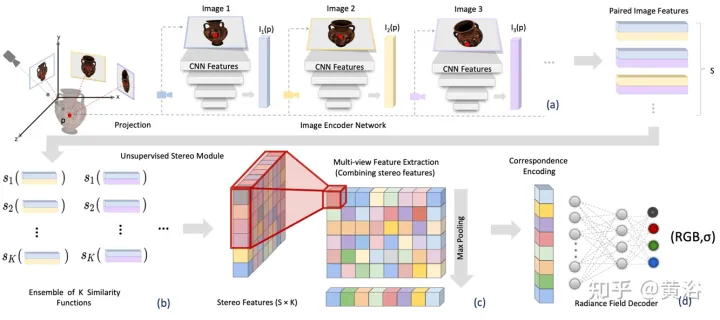
Makalah [3] mencadangkan Medan Sinaran Stereo (SRF), kaedah sintesis pandangan saraf terlatih hujung-ke-hujung yang boleh digeneralisasikan kepada adegan baharu dan hanya memerlukan pandangan jarang semasa ujian. Idea teras ialah seni bina saraf yang diilhamkan oleh kaedah stereo berbilang paparan klasik (MVS) untuk menganggar titik permukaan dengan mencari kawasan imej yang serupa dalam imej stereo. Masukkan 10 paparan ke dalam rangkaian pengekod dan ekstrak ciri berbilang skala. Multilayer Perceptrons (MLPs) menggantikan tampung imej klasik atau padanan ciri, menghasilkan ensemble skor persamaan. Dalam SRF, setiap titik 3D diberikan pengekodan rakan stereoskopiknya dalam imej input, dan warna serta ketumpatannya diramalkan terlebih dahulu. Pengekodan ini dipelajari secara tersirat melalui himpunan persamaan berpasangan - mensimulasikan penglihatan stereo klasik.
Dengan parameter kamera yang diketahui, diberikan satu set imej rujukan N, SRF meramalkan warna dan ketumpatan titik 3D. Bina model SRF 〈🎜〉f〈🎜〉, serupa dengan kaedah penglihatan stereo berbilang paparan klasik: (1) Untuk mengekod kedudukan titik, tayangkannya ke dalam setiap paparan rujukan dan bina deskriptor ciri setempat; Jika pada permukaan dan foto adalah konsisten, deskriptor ciri harus sepadan antara satu sama lain padanan ciri disimulasikan dengan fungsi yang dipelajari yang mengekodkan ciri semua paparan rujukan; . Rajah 2 memberikan gambaran keseluruhan tentang SRF: (a) mengekstrak ciri imej; (b) mensimulasikan proses mencari ketekalan foto melalui fungsi persamaan yang dipelajari, dan mendapatkan matriks ciri tiga dimensi (SFM); Matriks ciri berbilang paparan (MFM); (d) Pengumpulan maksimum memperoleh pengekodan padat surat-menyurat dan warna, yang dinyahkodkan untuk mendapatkan ketumpatan warna dan volum.
 Kertas [4] mencadangkan DietNeRF, perwakilan adegan saraf 3D yang dianggarkan daripada beberapa imej. Ia memperkenalkan kehilangan konsistensi semantik tambahan yang menggalakkan pemaparan realistik pose baharu.
Kertas [4] mencadangkan DietNeRF, perwakilan adegan saraf 3D yang dianggarkan daripada beberapa imej. Ia memperkenalkan kehilangan konsistensi semantik tambahan yang menggalakkan pemaparan realistik pose baharu.
Apabila hanya beberapa paparan tersedia dalam NeRF, masalah pemaparan tidak dikekang melainkan ditetapkan secara ketat, NeRF sering mengalami penyelesaian yang merosot. Seperti yang ditunjukkan dalam Rajah 3: (A) Apabila mengambil 100 pemerhatian objek daripada pose sampel seragam, NeRF menganggarkan perwakilan yang terperinci dan tepat, membenarkan sintesis paparan berkualiti tinggi semata-mata daripada konsistensi berbilang paparan; 8 pandangan, meletakkan sasaran dalam medan berhampiran kamera latihan, pemasangan NeRF yang sama membawa kepada salah jajaran dan kemerosotan sasaran dalam pose berhampiran kamera latihan (C) Apabila penyelarasan, penyederhanaan, Apabila dilaraskan dan dimulakan semula dengan tangan, NeRF boleh menumpu tetapi tidak lagi menangkap butiran halus; (D) Tanpa pengetahuan awal tentang objek yang serupa, sintesis paparan pemandangan tunggal tidak dapat menyelesaikan kawasan yang tidak diperhatikan dengan munasabah.
 Rajah 4 ialah gambarajah skematik kerja DietNeRF: Berdasarkan prinsip "dari mana-mana sudut, objek ialah objek itu", DietNeRF memantau medan sinaran dalam sebarang postur (kamera DietNeRF ); kemudian memaksimumkan persamaan dengan perwakilan pandangan kebenaran tanah.
Rajah 4 ialah gambarajah skematik kerja DietNeRF: Berdasarkan prinsip "dari mana-mana sudut, objek ialah objek itu", DietNeRF memantau medan sinaran dalam sebarang postur (kamera DietNeRF ); kemudian memaksimumkan persamaan dengan perwakilan pandangan kebenaran tanah.
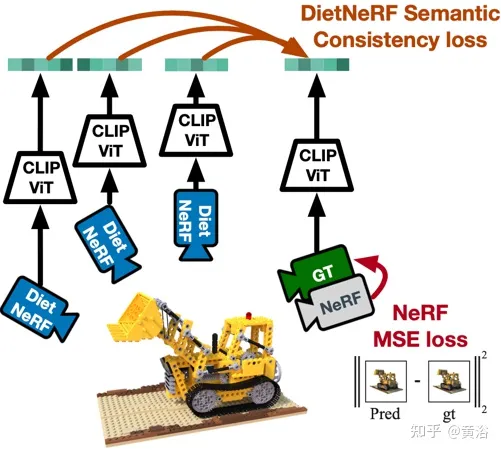 Malah, pengetahuan awal semantik pemandangan yang dipelajari oleh pengekod imej 2D paparan tunggal boleh mengekang perwakilan 3D. DietNeRF dilatih daripada koleksi ratusan juta foto 2D satu paparan yang dilombong daripada web di bawah pengawasan bahasa semula jadi: (1) memaparkan dengan betul diberikan paparan input yang diberikan daripada pose yang sama, (2) memadankan semantik peringkat tinggi merentas berbeza rawak menimbulkan harta. Fungsi kehilangan semantik boleh mengawasi model DietNeRF daripada pose sewenang-wenangnya.
Malah, pengetahuan awal semantik pemandangan yang dipelajari oleh pengekod imej 2D paparan tunggal boleh mengekang perwakilan 3D. DietNeRF dilatih daripada koleksi ratusan juta foto 2D satu paparan yang dilombong daripada web di bawah pengawasan bahasa semula jadi: (1) memaparkan dengan betul diberikan paparan input yang diberikan daripada pose yang sama, (2) memadankan semantik peringkat tinggi merentas berbeza rawak menimbulkan harta. Fungsi kehilangan semantik boleh mengawasi model DietNeRF daripada pose sewenang-wenangnya.
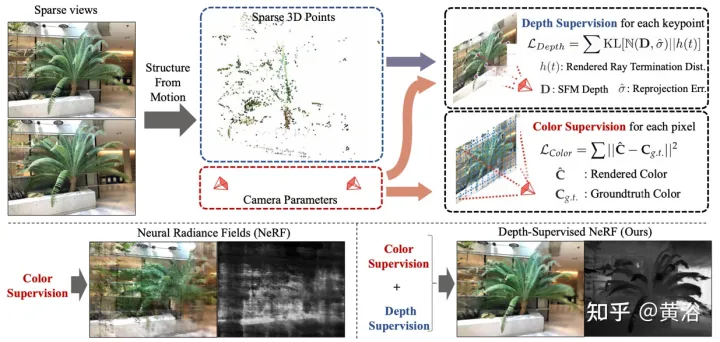
Kertas [5] mencadangkan DS-NeRF, yang menggunakan kehilangan medan sinaran pembelajaran dan menggunakan penyeliaan peta kedalaman sedia dibuat, seperti ditunjukkan dalam Rajah 5. Terdapat hakikat bahawa saluran paip NeRF semasa memerlukan imej dengan pose kamera yang diketahui, yang biasanya dianggarkan melalui Structure from Motion (SFM). Yang penting, SFM juga menghasilkan mata 3D yang jarang digunakan semasa latihan sebagai penyeliaan kedalaman "percuma": menambahkan kerugian yang menggalakkan taburan kedalaman penamatan sinar untuk memadankan titik utama 3D tertentu, termasuk Ketidakpastian kedalaman.
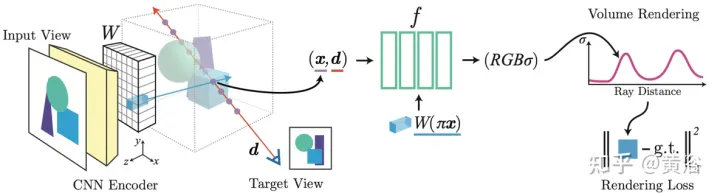
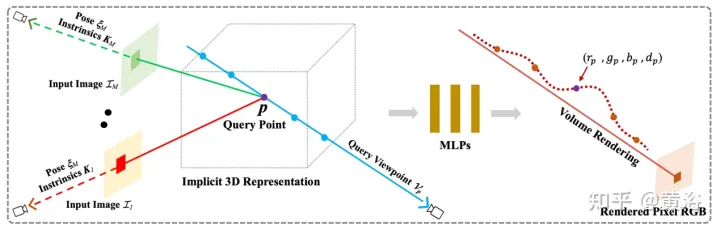
Kertas [6] mencadangkan pixelNeRF, rangka kerja pembelajaran untuk meramalkan perwakilan adegan saraf berterusan berdasarkan satu atau lebih imej input. Ia memperkenalkan kaedah konvolusi sepenuhnya untuk melaraskan seni bina NeRF pada input imej, membolehkan rangkaian dilatih merentasi berbilang adegan untuk mempelajari pengetahuan awal sesuatu adegan, supaya ia boleh meneruskan daripada set pandangan yang jarang (sekurang-kurangnya satu) dalam cara suapan ke hadapan. Dengan memanfaatkan kaedah pemaparan volum NeRF, pixelNeRF boleh dilatih terus daripada imej tanpa pengawasan 3D tambahan.
Secara khususnya, pixelNeRF terlebih dahulu mengira grid ciri imej konvolusi sepenuhnya (grid ciri) daripada imej input dan melaraskan NeRF pada imej input. Kemudian, bagi setiap titik ruang pertanyaan 3D x dan arah pandangan d yang diminati dalam sistem koordinat paparan, ciri imej yang sepadan diambil sampel melalui unjuran dan interpolasi dwilinear. Spesifikasi pertanyaan dihantar bersama-sama dengan ciri imej ke rangkaian NeRF yang mengeluarkan ketumpatan dan warna, di mana ciri imej spatial dimasukkan sebagai baki kepada setiap lapisan. Apabila berbilang imej tersedia, input mula-mula dikodkan ke dalam perwakilan terpendam setiap sistem koordinat kamera, yang digabungkan dalam lapisan perantaraan sebelum meramalkan warna dan ketumpatan. Latihan model adalah berdasarkan kehilangan pembinaan semula antara imej kebenaran asas dan paparan volum yang diberikan. Rangka kerja
pixelNeRF ditunjukkan dalam Rajah 6: untuk titik pertanyaan 3D x sepanjang arah pandangan d, sinar kamera sasaran, daripada volum ciri WEkstrak ciri imej yang sepadan; kemudian hantar ciri tersebut bersama-sama dengan koordinat spatial ke rangkaian NeRF f output RGB dan nilai ketumpatan digunakan untuk pemaparan volum dan dibandingkan dengan piksel sasaran nilai; koordinat x dan d berada dalam sistem koordinat kamera paparan input.
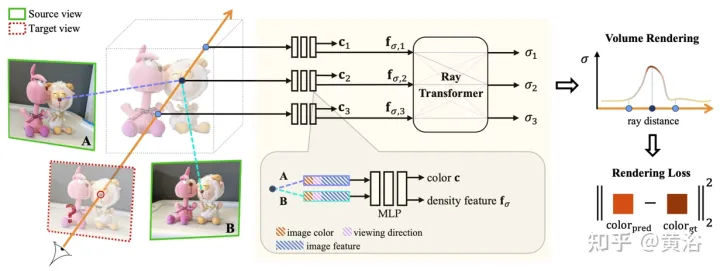
Rendering berasaskan imej (IBR). Tidak seperti perwakilan adegan saraf, yang mengoptimumkan setiap fungsi adegan untuk pemaparan, IBRNet mempelajari fungsi interpolasi pandangan umum yang digeneralisasikan kepada adegan baharu. Masih menggunakan pemaparan volum klasik untuk mensintesis imej, ia boleh dibezakan sepenuhnya dan dilatih dengan imej pose berbilang paparan sebagai penyeliaan.
Pengubah sinar mempertimbangkan ciri ketumpatan ini di sepanjang keseluruhan sinar untuk mengira nilai ketumpatan skalar bagi setiap sampel, membolehkan penaakulan keterlihatan pada skala spatial yang lebih besar. Secara berasingan, modul pengadunan warna memperoleh warna bergantung pada paparan bagi setiap sampel menggunakan ciri 2D dan vektor penglihatan pandangan sumber. Akhir sekali, pemaparan volum mengira nilai warna akhir untuk setiap sinar. Rajah 7 ialah gambaran keseluruhan IBRNet: 1) Untuk memaparkan paparan sasaran (imej bertanda "?"), mula-mula kenal pasti satu set paparan sumber bersebelahan (contohnya, paparan bertanda A dan B) dan ekstrak imej Ciri-ciri; 2) Kemudian, untuk setiap sinar dalam paparan sasaran, gunakan IBRNet (kawasan berlorek kuning) untuk mengira satu set warna dan ketumpatan sampel di sepanjang sinar secara khusus, untuk setiap sampel, agregat warna dan ketumpatan yang sepadan dari yang bersebelahan paparan sumber Maklumat (warna imej, ciri dan arah tontonan), hasilkan warnac dan ciri ketumpatannya kemudian, gunakan pengubah sinar pada ciri ketumpatan semua sampel pada sinar untuk meramalkan nilai ketumpatan. 3) Akhir sekali, gunakan pemaparan volum untuk mengumpul warna dan ketumpatan di sepanjang sinar. Pada warna imej yang dibina semula, latihan kehilangan L2 hujung ke hujung boleh dilakukan.
Rajah 8 menunjukkan kerja ramalan ketumpatan warna + volum IBRNet untuk kedudukan 5D berterusan: pertama, ciri imej 2D yang diekstrak daripada semua paparan sumber dimasukkan ke dalam MLP serupa dengan PointNet, dan maklumat tempatan dan global diagregatkan untuk menghasilkan berbilang -lihat persepsi Ciri dan pemberat pengumpulan, gunakan pemberat untuk menumpukan ciri, melakukan penaakulan keterlihatan berbilang pandangan, dan mendapatkan ciri ketumpatan dan bukannya meramalkan secara langsung ketumpatan σ sampel 5D tunggal, modul pengubah sinar digunakan untuk mengumpulkan semua maklumat sampel; sepanjang sinar Modul pengubah memperoleh ciri ketumpatan untuk semua sampel pada sinar dan meramalkan ketumpatannya modul pengubah sinar membolehkan penaakulan geometri dalam julat yang lebih panjang dan meningkatkan ramalan ketumpatan, ciri persepsi berbilang pandangan dibandingkan dengan sinar pertanyaan Arah tontonan paparan sumber disambungkan kepada input kepada rangkaian kecil untuk meramalkan set pemberat harmonik, dan warna output c ialah purata wajaran warna imej paparan sumber.
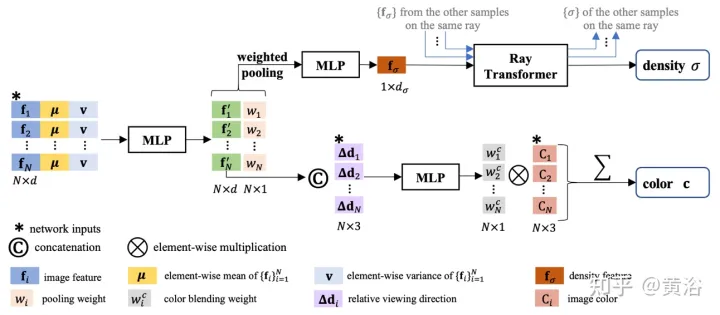
Satu lagi perkara yang perlu ditambah di sini: Tidak seperti NeRF yang menggunakan arah tontonan mutlak, IBRNet menganggap arah tontonan berbanding paparan sumber, iaitu d dan Perbezaan antara di, Δd=d−di. Δd lebih kecil, yang biasanya bermaksud warna paparan sasaran lebih berkemungkinan serupa dengan warna paparan sumber yang sepadan i, dan begitu juga sebaliknya.
Bidang Sinaran Am (GRF) yang dicadangkan dalam kertas [8] mencirikan dan menjadikan sasaran dan adegan 3D hanya daripada pemerhatian 2D. Rangkaian memodelkan geometri 3D sebagai medan sinaran sejagat, mengambil set imej 2D, pose ekstrinsik kamera dan parameter intrinsik sebagai input, membina perwakilan dalaman untuk setiap titik dalam ruang 3D, dan kemudian menjadikan penampilan dan geometri yang sepadan dilihat dari mana-mana kedudukan. Perkara utama ialah mempelajari ciri setempat bagi setiap piksel imej 2D dan kemudian menayangkan ciri ini kepada titik 3D, dengan itu menjana perwakilan titik yang serba boleh dan kaya. Tambahan pula, mekanisme perhatian disepadukan untuk mengagregat ciri piksel berbilang paparan 2D untuk mempertimbangkan secara tersirat isu oklusi visual.
Rajah 9 ialah gambarajah skematik GRF: GRF memproyeksikan setiap titik 3D p kepada setiap imej input M, mengumpul setiap satu daripada setiap paparan Ciri-ciri piksel diagregatkan dan dimasukkan ke MLP, yang menyimpulkan warna dan ketumpatan volum 〈🎜〉p〈🎜〉.
 GRF terdiri daripada empat bahagian: 1) pengekstrak ciri untuk setiap piksel 2D, penyahkod pengekod berasaskan CNN 2) penukaran ciri 2D kepada unjuran semula ruang 3D; Agregator berasaskan perhatian untuk mendapatkan ciri universal mata 3D; 4) NeRF pemapar saraf.
GRF terdiri daripada empat bahagian: 1) pengekstrak ciri untuk setiap piksel 2D, penyahkod pengekod berasaskan CNN 2) penukaran ciri 2D kepada unjuran semula ruang 3D; Agregator berasaskan perhatian untuk mendapatkan ciri universal mata 3D; 4) NeRF pemapar saraf.
Memandangkan tiada nilai kedalaman yang dipasangkan dengan imej RGB, tiada cara untuk menentukan titik permukaan 3D tertentu yang dimiliki oleh ciri piksel itu. Dalam modul unjuran semula, ciri piksel dianggap sebagai perwakilan setiap kedudukan di sepanjang sinar dalam ruang 3D. Secara rasmi, memandangkan titik 3D, pandangan 2D yang memerhati, dan pose kamera dan parameter intrinsik, ciri piksel 2D yang sepadan boleh diambil melalui operasi unjuran semula.
Dalam pengagregat ciri, mekanisme perhatian mempelajari pemberat unik untuk semua ciri input dan kemudian mengagregatkannya bersama-sama. Melalui MLP, ketumpatan warna dan volum titik 3D boleh disimpulkan.
Kertas [9] mencadangkan RegNeRF untuk menyelaraskan geometri dan rupa tompok imej yang diberikan daripada sudut pandangan yang tidak diperhatikan, dan menyepuh ruang pensampelan cahaya semasa latihan. Selain itu, model aliran ternormal digunakan untuk menyelaraskan warna sudut pandangan yang tidak diperhatikan.
Rajah 10 ialah gambaran keseluruhan model RegNeRF: memandangkan satu set imej input (kamera biru), NeRF mengoptimumkan kehilangan pembinaan semula bagaimanapun, untuk input yang jarang, ini membawa kepada penyelesaian yang merosot; Pandangan yang dicerap masa hadapan (kamera merah) diambil sampel dan tompok imej yang diberikan daripada pandangan ini dilaraskan untuk geometri dan penampilan secara lebih khusus, untuk medan sinaran tertentu, sinar dipancarkan melalui pemandangan dan tompok imej dipaparkan dari sudut pandangan yang tidak diperhatikan ; , tampalan imej RGB yang diramalkan disalurkan melalui model aliran normal terlatih dan kebarangkalian log yang diramalkan dimaksimumkan, dengan itu menyelaraskan penampilan terpaksa pada tampalan kedalaman yang diberikan, yang boleh diselaraskan pendekatannya kepada 3D; perwakilan yang konsisten walaupun untuk input yang jarang memberikan pandangan baharu yang realistik.
 Kertas [10] mengkaji kaedah ekstrapolasi pandangan baharu dan bukannya sintesis imej beberapa sampel, iaitu, (1) imej latihan boleh menggambarkan sasaran dengan baik, ( 2) Terdapat perbezaan yang ketara antara pengedaran sudut pandangan latihan dan sudut pandangan ujian, yang dipanggil RapNeRF (RAy Priors NeRF).
Kertas [10] mengkaji kaedah ekstrapolasi pandangan baharu dan bukannya sintesis imej beberapa sampel, iaitu, (1) imej latihan boleh menggambarkan sasaran dengan baik, ( 2) Terdapat perbezaan yang ketara antara pengedaran sudut pandangan latihan dan sudut pandangan ujian, yang dipanggil RapNeRF (RAy Priors NeRF).
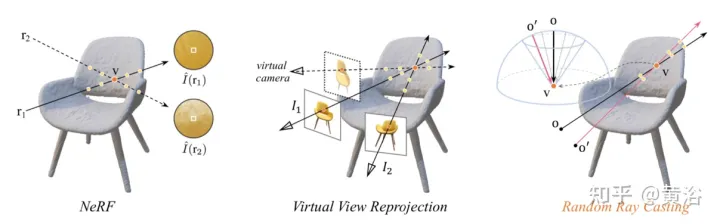
Wawasan kertas [10] ialah rupa wujud mana-mana unjuran yang kelihatan bagi permukaan 3D hendaklah konsisten. Oleh itu, ia mencadangkan strategi pancaran sinar rawak yang membolehkan pandangan ghaib dilatih dengan pandangan dilihat. Selain itu, kualiti pemaparan paparan ekstrapolasi boleh dipertingkatkan lagi berdasarkan atlas sinar prakiraan di sepanjang garis penglihatan sinar pemerhatian. Had utama ialah RapNeRF mengeksploitasi konsistensi berbilang paparan untuk menghapuskan kesan korelasi pandangan yang kuat.
Penjelasan intuitif tentang strategi pancaran sinar rawak ditunjukkan dalam Rajah 11: Dalam gambar kiri, terdapat dua sinar yang memerhati titik 3-D v, r1 terletak dalam ruang latihan, dan r2 jauh. jauh dari sinar latihan; pertimbangkan fungsi hanyut dan pemetaan pengedaran ke NeRF 〈🎜〉Fc:(r,f)→c , yang sinaran di sepanjang beberapa sampel di sepanjang r2 akan menjadi tidak tepat operasi pengumpulan sinaran di sepanjang r2 warna Lebih berkemungkinan memberikan anggaran warna songsang bagi v imej tengah ialah unjuran semula paparan maya mudah yang mengikut formula NeRF untuk mengira sinar piksel yang terlibat, mencari sinar yang sepadan dengan sinar maya mengenai titik 3D yang sama dari sinar latihan pool , sangat menyusahkan dalam latihan; dalam gambar di sebelah kanan, untuk sinar latihan tertentu (diunjurkan dari o dan melalui v), strategi Random Ray Casting (RRC) menjana sinar ghaib dalam a kon Sinar maya (diunjurkan daripada o′ dan melalui v) kemudiannya diberikan label pseudo dalam talian berdasarkan sinar latihan RRC menyokong latihan sinar ghaib dengan sinar yang dilihat.
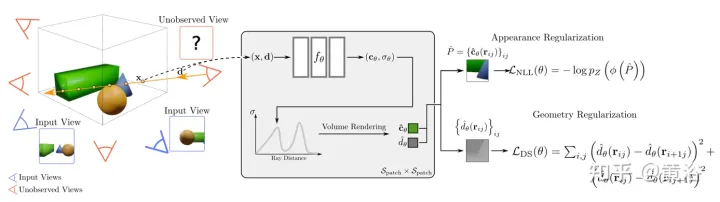
I, arah pemerhatian d, asal kamera o dan nilai Kedalaman tz , dan sinar cahaya r=o+td . Di sini, pasangan NeRF pra-latihan tz diprakira dan disimpan.
Andaikanv=o+tzd mewakili titik permukaan 3D terdekat yang dipukul oleh r. Semasa fasa latihan, pertimbangkan v sebagai asal baharu dan hantar sinar secara rawak daripada v dalam kon, yang garis tengahnya ialah vektor vo¯ =− tzd. Ini boleh dicapai dengan mudah dengan menukar 〈🎜〉vo¯ kepada ruang sfera dan memperkenalkan beberapa gangguan rawak Δφ dan Δθ kepada φ dan θ. Di sini, φ dan θ ialah azimut dan sudut dongakan bagi vo¯ masing-masing. Δφ dan Δθ diambil secara seragam daripada selang pratakrif [−η, η]. Daripada ini kita mendapat θ′=θ+Δθ dan φ′=φ+Δφ. Oleh itu, sinar maya boleh dipancarkan dari asal rawak o' yang juga melalui v. Dengan cara ini, nilai sebenar keamatan warna I(r) boleh dianggap sebagai token pseudo I~(r′). NeRF Asas menggunakan "pembenaman arah" untuk mengekod kesan pencahayaan tempat kejadian. Proses pemasangan pemandangan menjadikan MLP ramalan warna terlatih sangat bergantung pada arah pandangan. Untuk interpolasi pandangan baharu ini tidak menjadi masalah. Walau bagaimanapun, ini mungkin tidak sesuai untuk ekstrapolasi paparan baharu kerana beberapa perbezaan antara latihan dan pengedaran cahaya ujian. Idea naif adalah dengan hanya mengalih keluar pembenaman arah (ditandakan sebagai "NeRF w/o dir"). Walau bagaimanapun, ini sering menghasilkan artifak imej seperti riak yang tidak dijangka dan warna yang tidak licin. Ini bermakna arah tontonan cahaya mungkin juga berkaitan dengan kelancaran permukaan.
Kertas [10] mengira atlas sinar dan menunjukkan bahawa ia boleh meningkatkan lagi kualiti pemaparan pandangan yang diekstrapolasi tanpa melibatkan masalah pandangan yang diinterpolasi. Atlas sinar adalah serupa dengan atlas tekstur, tetapi ia menyimpan arah sinar global untuk setiap bucu 3D.
Khususnya, untuk setiap imej (cth., imej
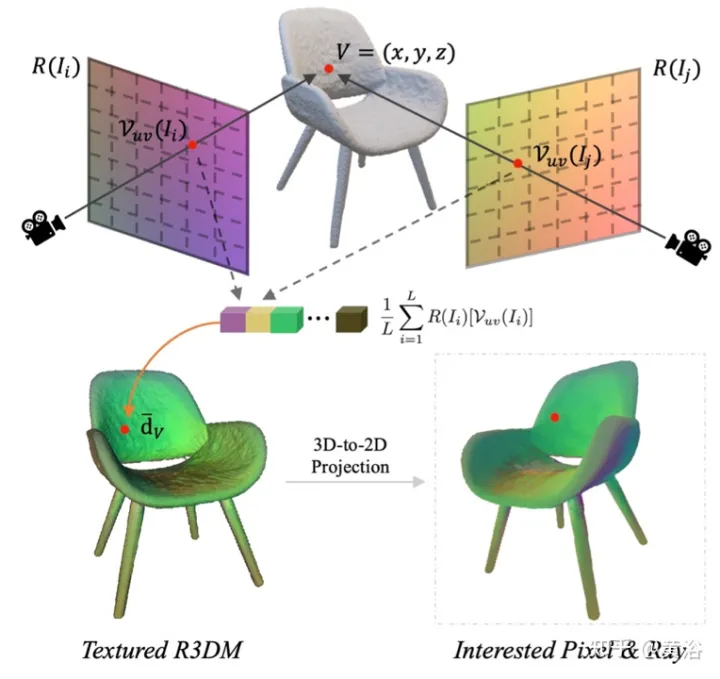
I), arah tontonan sinarnya diambil untuk semua lokasi spatial, sekali gus menghasilkan peta sinar. Ekstrak jejaring 3D kasar (R3DM) daripada NeRF terlatih dan arah sinar peta ke bucu 3D. Mengambil puncak V=(x,y,z) sebagai contoh, arah cahaya globalnya d¯V hendaklah dinyatakan sebagai
di mana K ialah parameter dalaman kamera, Γw2c(Ii) ialah matriks transformasi sistem koordinat dunia kamera bagi imej Ii, Vuv (Ii) ialah kedudukan unjuran 2-D bagi bucu V dalam imej Ii, dan L ialah bilangan imej latihan dalam pembinaan semula bucu V. Untuk setiap piksel pose kamera sewenang-wenangnya, menayangkan jejaring 3D dengan tekstur peta sinar (R3DM) ke dalam 2D memperoleh sinar global sebelum 〈🎜〉d¯ .
Rajah 12 ialah gambarajah skematik atlas cahaya: iaitu, menangkap atlas cahaya daripada lampu latihan dan menggunakannya untuk menambah tekstur pada jejaring 3D kasar (R3DM) kerusi R( Ii) ialah peta cahaya bagi imej latihan Ii.
d¯ piksel kepentingan I(r) untuk menggantikan kedudukannya dalam Fc d dalam , lakukan ramalan warna. Kebarangkalian mekanisme alternatif ini berlaku ialah 0.5. Semasa fasa ujian, sinaran c sampel x adalah lebih kurang:
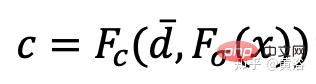
Fσ(x):x→(σ,f).
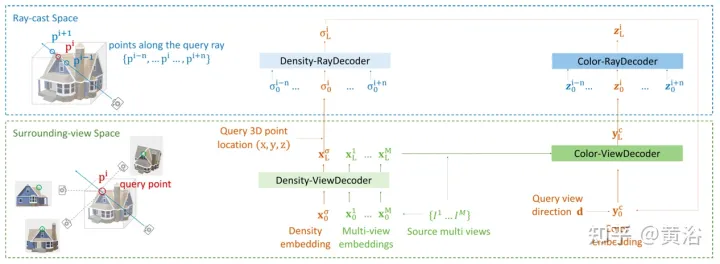
NeRF Asal mengoptimumkan setiap perwakilan adegan secara bebas, tanpa perlu meneroka maklumat yang dikongsi antara babak, dan memakan masa. Untuk menyelesaikan masalah ini, penyelidik telah mencadangkan model seperti PixelNeRF dan MVSNeRF, yang menerima pelbagai pandangan pemerhati sebagai input bersyarat dan mempelajari medan sinaran saraf sejagat. Mengikut prinsip reka bentuk divide-and-conquer, ia terdiri daripada dua komponen bebas: pengekstrak ciri CNN untuk satu imej dan MLP sebagai rangkaian NeRF. Untuk penglihatan stereo satu paparan, dalam model ini, CNN memetakan imej ke grid ciri dan MLP memetakan koordinat 5D pertanyaan dan ciri CNN yang sepadan dengan ketumpatan volum tunggal dan warna RGB bergantung pada paparan. Untuk penglihatan stereo berbilang paparan, memandangkan CNN dan MLP tidak dapat mengendalikan sebarang bilangan paparan input, koordinat dan ciri yang sepadan dalam setiap sistem koordinat paparan diproses terlebih dahulu secara bebas dan perwakilan perantaraan berhawa dingin bagi setiap paparan diperoleh. Seterusnya, model berasaskan pengumpulan tambahan digunakan untuk mengagregatkan perwakilan perantaraan paparan dalam rangkaian NeRF ini. Dalam tugas pemahaman 3D, berbilang paparan memberikan maklumat tambahan tentang pemandangan. Kertas [11] mencadangkan rangka kerja Transformer penyahkod pengekod TransNeRF untuk mencirikan pemandangan medan sinaran saraf. TransNeRF boleh meneroka perhubungan yang mendalam antara berbilang paparan dan mengagregatkan maklumat berbilang paparan ke dalam perwakilan pemandangan berasaskan koordinat melalui mekanisme perhatian NeRF berasaskan Transformer tunggal. Di samping itu, TransNeRF mempertimbangkan maklumat yang sepadan bagi ruang sinaran dan ruang paparan persisian untuk mempelajari ketekalan geometri tempatan bagi bentuk dan rupa dalam tempat kejadian. Seperti yang ditunjukkan dalam Rajah 13, TransNeRF memaparkan titik 3D yang ditanya dalam sinar tontonan sasaran TransNeRF termasuk: 1) Dalam ruang persisian, penyahkod paparan ketumpatan (Dekoder Paparan Ketumpatan) dan Dekoder Paparan Warna (. Color-ViewDecoder) menggabungkan paparan sumber dan maklumat ruang pertanyaan((x,y,z),d) ke dalam ketumpatan terpendam dan perwakilan warna bagi titik pertanyaan 3D 2) Dalam ruang siaran sinaran; penyahkod sinar ketumpatan (Dekoder Sinar Ketumpatan) dan penyahkod sinar warna (Dekoder Sinar Warna) digunakan untuk meningkatkan ketumpatan pertanyaan dan perwakilan warna dengan mempertimbangkan titik bersebelahan di sepanjang sinar pandangan sasaran. Akhir sekali, ketumpatan volum dan warna arah bagi titik 3D pertanyaan pada garis penglihatan sasaran diperoleh daripada TransNeRF.
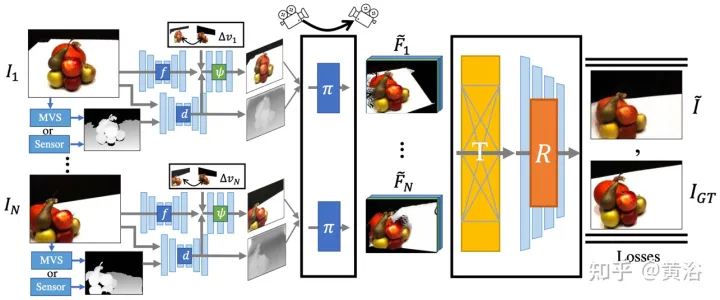
FWD menganggarkan kedalaman setiap paparan input, membina awan titik ciri terpendam, dan kemudian mensintesis paparan baharu melalui pemapar awan titik. Untuk mengurangkan masalah ketidakkonsistenan antara pemerhatian dari sudut pandangan yang berbeza, ciri berkaitan sudut pandangan diperkenalkan ke awan titik untuk memodelkan keputusan berkaitan sudut pandang. Satu lagi modul gabungan berasaskan Transformer menggabungkan ciri-ciri daripada berbilang input dengan berkesan. Modul penghalusan yang boleh mengecat kawasan yang hilang dan meningkatkan lagi kualiti gubahan. Keseluruhan model dilatih hujung ke hujung, meminimumkan kehilangan fotometri dan persepsi, kedalaman pembelajaran dan ciri yang mengoptimumkan kualiti sintesis.
Rajah 14 ialah gambaran keseluruhan FWD: diberikan satu set imej yang jarang, gunakan rangkaian ciri f (berdasarkan seni bina BigGAN), MLP ciri berkaitan paparan ψ dan Rangkaian dalam d membina awan titik (termasuk maklumat geometri dan semantik paparan) Pi untuk setiap imej Ii; , d Ambil MVS (berdasarkan PatchmatchNet) anggaran kedalaman atau kedalaman sensor sebagai input dan mundurkan kedalaman yang diperhalusi berdasarkan ciri imej Fi dan perubahan paparan relatif Δv (berdasarkan arah paparan ternormal vi dan vt, iaitu dari titik ke tengah paparan input i dan pandangan sasaran t), Regress ciri piksel demi piksel Fi′ hingga f dan ψ; gunakan pemapar awan titik yang boleh dibezakan π (percikan) ke Awan titik diunjurkan dan diberikan kepada paparan sasaran, iaitu F~i dan bukannya mengagregatkan awan titik pandangan secara langsung sebelum membuat, Transformer T menggabungkan hasil pemaparan daripada sebarang bilangan input dan Menggunakan modul penghalusan R penyahkodan menjana hasil imej akhir, yang secara semantik dan geometri membaiki kawasan input yang tidak kelihatan, membetulkan ralat setempat yang disebabkan oleh kedalaman yang tidak tepat, dan bertambah baik berdasarkan semantik yang terkandung dalam peta ciri Kualiti persepsi model yang dilatih menggunakan kehilangan fotometrik dan kehilangan kandungan.
Kaedah sedia ada menggunakan ciri imej tempatan untuk membina semula objek 3D, menayangkan ciri imej input pada titik 3D pertanyaan untuk meramalkan warna dan ketumpatan, dengan itu membuat kesimpulan bentuk dan rupa 3D. Model bersyarat imej ini berfungsi dengan baik untuk memaparkan peta perspektif sasaran yang hampir dengan perspektif input. Walau bagaimanapun, apabila perspektif sasaran bergerak terlalu banyak, kaedah ini boleh menyebabkan oklusi ketara pada paparan input, menyebabkan kualiti menurun dengan mendadak dan menyebabkan ramalan kabur.
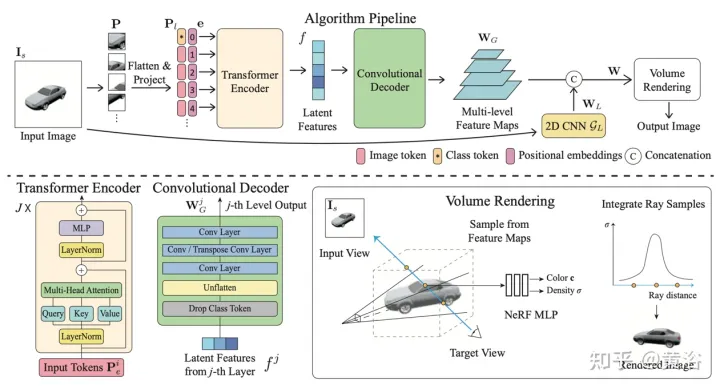
Untuk menyelesaikan masalah di atas, kertas [13] mencadangkan kaedah yang menggunakan ciri global dan tempatan untuk membentuk perwakilan 3D termampat. Ciri global dipelajari daripada Transformer visual, manakala ciri tempatan diekstrak daripada rangkaian konvolusi 2D. Untuk mensintesis paparan baharu, rangkaian MLP dilatih untuk mencapai pemaparan volum berdasarkan perwakilan 3D yang dipelajari. Perwakilan ini membolehkan pembinaan semula kawasan ghaib tanpa memerlukan kekangan yang dikuatkuasakan seperti simetri atau sistem koordinat kanonik.
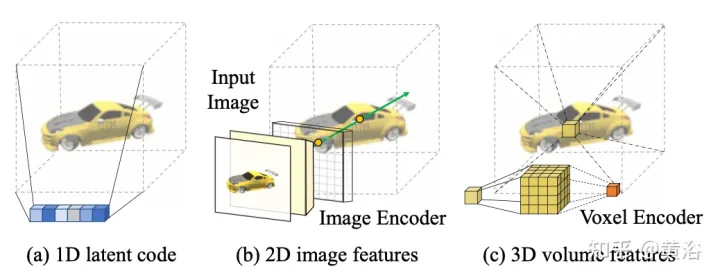
Memandangkan satu imej Adakah di kamera, tugasnya adalah untuk mensintesis pandangan baharu Ia pada kamera t. Jika titik 3D x boleh dilihat dalam imej sumber, warnanya Is(π(x)) boleh digunakan secara langsung, dengan π mewakili unjuran dalam paparan sumber, menunjukkan bahawa titik itu boleh dilihat dalam paparan baharu. Jika x tersumbat, gunakan maklumat selain daripada warna π(x) yang diunjurkan. Seperti yang ditunjukkan dalam Rajah 15, terdapat tiga penyelesaian yang mungkin untuk mendapatkan maklumat jenis ini: (a) General NeRF ialah kaedah berasaskan kod terpendam 1D yang mengekodkan maklumat sasaran 3D dalam vektor 1D Memandangkan titik 3D yang berbeza berkongsi kod yang sama bias induktif ialah Had; (b) Kaedah berasaskan imej 2D membina semula mana-mana titik 3D daripada ciri imej piksel demi piksel menggalakkan kualiti pemaparan yang lebih baik di kawasan yang boleh dilihat dan lebih cekap dari segi pengiraan, tetapi pemaparan menjadi kabur untuk kawasan yang tidak kelihatan. c) ) Kaedah berasaskan voxel 3D menganggap sasaran 3-D sebagai koleksi voxel, dan menggunakan lilitan 3-D untuk menjana warna RGB dan vektor ketumpatan σ, yang menghasilkan lebih pantas dan menggunakan sepenuhnya 3D sebelum untuk menghasilkan geometri ghaib, tetapi peleraian pemaparan terhad disebabkan saiz voxel dan medan penerimaan terhad.
Rajah 6 ialah gambaran keseluruhan kaedah pemaparan hibrid tempatan global [13]: Pertama, imej input dibahagikan kepada N=8×8 blok imej P; Setiap tampalan imej diratakan dan ditayangkan secara linear ke token imej (token) P1; set ciri terpendam f; Kemudian, gunakan penyahkod konvolusi untuk menyahkod ciri terpendam ke dalam peta ciri berbilang peringkat WG sebagai tambahan kepada ciri global, gunakan model CNN 2D yang lain untuk dapatkan ciri imej tempatan; akhirnya, Ciri pensampelan untuk pemaparan volum menggunakan model MLP NeRF.
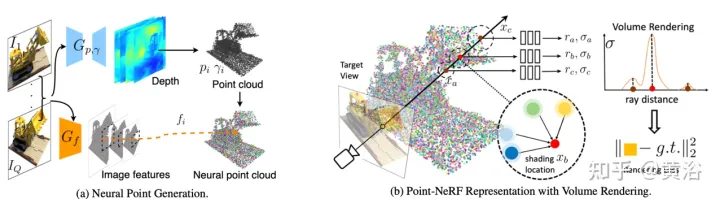
Kertas [14] mencadangkan Point-NeRF, yang menggabungkan kelebihan NeRF dan MVS dan menggunakan awan titik 3D saraf dan ciri saraf yang berkaitan untuk memodelkan medan sinaran. Point-NeRF boleh dihasilkan dengan berkesan dengan mengagregatkan ciri titik saraf berhampiran permukaan tempat kejadian dalam saluran paip pemaparan berasaskan sinar. Selain itu, inferens langsung daripada rangkaian dalam yang telah terlatih memulakan Point-NeRF untuk menjana awan titik neural boleh diperhalusi untuk melebihi kualiti visual NeRF dan melatih 30 kali lebih pantas. Point-NeRF digabungkan dengan kaedah pembinaan semula 3D yang lain dan mengamalkan mekanisme pertumbuhan dan pemangkasan, iaitu, berkembang di kawasan ketumpatan volum tinggi dan pemangkasan dalam ketumpatan volum rendah, untuk mengoptimumkan data awan titik yang dibina semula.
Gambaran keseluruhan Point-NeRF ditunjukkan dalam Rajah 17: (a) Daripada imej berbilang paparan, Point-NeRF menjana kedalaman untuk setiap paparan dengan CNN 3D dan 2D CNN berasaskan volum kos daripada input imej. Ekstrak ciri 2D; selepas mengagregatkan peta kedalaman, dapatkan medan sinaran berasaskan titik, di mana setiap titik mempunyai kedudukan spatial, keyakinan, dan ciri imej yang tidak diunjurkan; Kira cahaya dan gelap berhampiran awan titik saraf pada setiap kedudukan terang dan gelap, Point-NeRF mengagregatkan ciri dari jiran titik saraf Knya dan mengira sinaran dan ketumpatan isipadu, kemudian menjumlahkan sinaran dengan pengumpulan ketumpatan isipadu. Keseluruhan proses boleh dilatih hujung ke hujung, dan medan sinaran berasaskan titik boleh dioptimumkan melalui kehilangan pemaparan.
GRAF (Bidang Sinaran Generatif) [18] ialah model penjanaan medan sinaran, yang dicapai dengan memperkenalkan diskriminator berdasarkan pelbagai skala tampalan. Sintesis imej sedar 3D beresolusi tinggi manakala latihan model hanya memerlukan imej 2D yang diambil oleh kamera pose yang tidak diketahui.
Matlamatnya adalah untuk mempelajari model untuk mensintesis adegan baharu dengan melatih imej yang tidak diproses. Lebih khusus lagi, rangka kerja lawan digunakan untuk melatih model generatif medan sinaran (GRAF).
Rajah 18 menunjukkan gambaran keseluruhan model GRAF: penjana menggunakan matriks kamera K, pose kamera ξ, mod pensampelan 2D ν dan kod bentuk/penampilan sebagai input dan ramalkan patch imej P′; P ′ dibandingkan dengan tampalan P yang diekstrak daripada imej sebenar I semasa inferens, untuk setiap satu Ramalkan nilai warna untuk setiap piksel imej; walau bagaimanapun, operasi ini terlalu mahal pada masa latihan, jadi tampalan tetap saiz K×K piksel diramalkan, dengan penskalaan dan putaran rawak , untuk keseluruhan medan Sinaran menyediakan kecerunan.
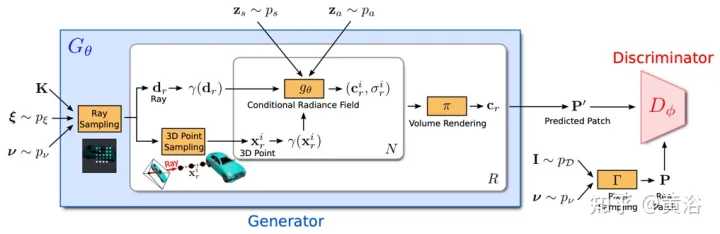 Tentukan pusat dan skala s tampalan K×K maya yang akan dijana. Pusat tampalan rawak datang daripada taburan seragam ke atas domain imej Ω, manakala skala tampalan s datang daripada taburan seragam, di mana W dan H mewakili lebar dan ketinggian imej sasaran. Pembolehubah bentuk dan rupa masing-masing diambil sampel daripada taburan bentuk dan rupa. Dalam eksperimen, kedua-duanya dan menggunakan taburan Gaussian standard.
Tentukan pusat dan skala s tampalan K×K maya yang akan dijana. Pusat tampalan rawak datang daripada taburan seragam ke atas domain imej Ω, manakala skala tampalan s datang daripada taburan seragam, di mana W dan H mewakili lebar dan ketinggian imej sasaran. Pembolehubah bentuk dan rupa masing-masing diambil sampel daripada taburan bentuk dan rupa. Dalam eksperimen, kedua-duanya dan menggunakan taburan Gaussian standard.
Medan sinaran diwakili oleh rangkaian neural yang bersambung sepenuhnya dalam, di mana parameter θ memetakan pengekodan kedudukan kedudukan 3D
x dan arah tontonan d kepada nilai warna RGB c dan ketumpatan volum σ:
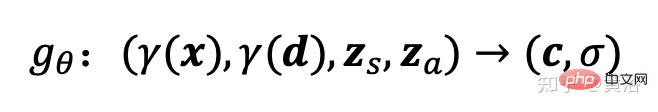 di sini
di sini
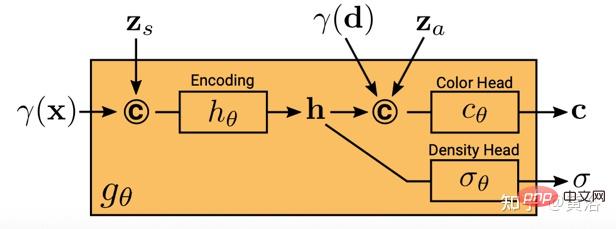
gθ bergantung pada dua kod pendam tambahan: kod bentuk zs menentukan bentuk sasaran dan kod penampilan za menentukan penampilan. Di sini gθ dipanggil medan sinaran bersyarat, dan strukturnya ditunjukkan dalam Rajah 19: Pertama, kod bentuk dikira berdasarkan kod kedudukan dan kod bentuk x h; Kepala ketumpatanσθ menukar pengekodan ini kepada ketumpatan volum σ ialah warna pada kedudukan 3D yang diramalkan x c, pengekodan kedudukan dan kod ketara h dan d 🎜> za disatukan dan vektor yang dihasilkan diluluskan ke header warna cθ; 🎜> dan kod rupa, digalakkan Kekonsistenan berbilang paparan dan pemisahan bentuk dan rupa ini menggalakkan rangkaian menggunakan dua kod terpendam untuk memodelkan bentuk dan rupa secara berasingan, dan membolehkannya diproses secara berasingan semasa inferens.
Pendiskriminasi dilaksanakan sebagai rangkaian saraf konvolusional, menggabungkan patch yang diramalkan P′ dengan pengagihan data imej sebenar pD Saya tampung yang diekstrak P sebagai perbandingan. Untuk mengekstrak tampalan K×K daripada imej sebenar I, pertama daripada pengedaran yang sama pv yang digunakan untuk ekstrak patch penjana di atas Ekstrak v=(u,s); kemudian, tanya I pada koordinat imej 2D P(u,s) melalui interpolasi dwilinear, dan sampel tampung sebenar P. Gunakan Γ(I,v) untuk mewakili operasi pensampelan dwilinear ini.
Percubaan mendapati bahawa satu diskriminasi dengan pemberat yang dikongsi adalah mencukupi untuk semua tampung, walaupun tampalan diambil sampel di lokasi rawak pada skala yang berbeza. Nota: Skala menentukan medan penerimaan tampalan. Oleh itu, untuk memudahkan latihan, mulakan dengan tampung medan penerimaan yang lebih besar untuk menangkap konteks global. Kemudian, tampalan dengan medan penerimaan yang lebih kecil diambil secara progresif untuk memperhalusi butiran setempat.
GIRAFFE[19] digunakan untuk menjana adegan dalam cara yang boleh dikawal dan realistik semasa melatih imej mentah tidak berstruktur. Sumbangan utama adalah dalam dua aspek: 1) Gabungan perwakilan pemandangan 3D dimasukkan terus ke dalam model generatif untuk mencapai sintesis imej yang lebih terkawal. 2) Gabungkan perwakilan 3D eksplisit ini dengan saluran paip pemaparan saraf untuk membolehkan inferens yang lebih pantas dan imej yang lebih realistik. Untuk tujuan ini, perwakilan pemandangan ialah gabungan untuk menjana medan ciri saraf , seperti yang ditunjukkan dalam Rajah 20: Untuk kamera yang diambil secara rawak, imej ciri adegan itu diberikan kelantangan berdasarkan yang berasingan. medan ciri; rangkaian pemaparan saraf 2D akan Imej ciri ditukar kepada imej RGB hanya digunakan semasa latihan, dan proses pembentukan imej boleh dikawal semasa ujian, termasuk pose kamera, pose sasaran dan bentuk dan penampilan sasaran; sebagai tambahan, model diperluaskan di luar skop data latihan, sebagai contoh, Adegan yang mengandungi lebih banyak objek daripada dalam imej latihan boleh disintesis.
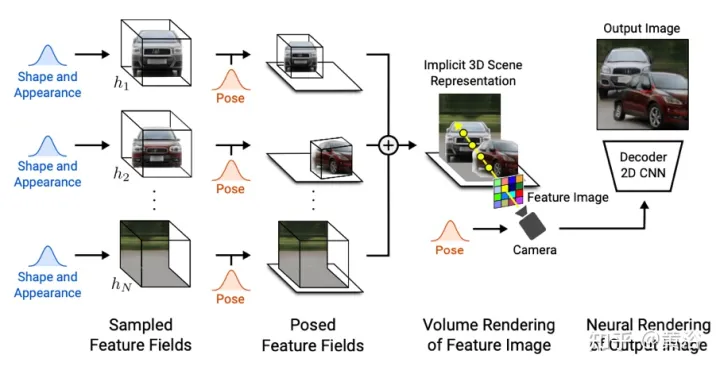
Menjadikan kelantangan pemandangan kepada imej ciri resolusi yang agak rendah, menjimatkan masa dan pengiraan. Penyampai saraf memproses imej ciri ini dan mengeluarkan hasil akhir. Dengan cara ini, kaedah ini boleh mendapatkan imej berkualiti tinggi dan skala kepada adegan sebenar. Apabila dilatih mengenai koleksi imej mentah tidak berstruktur, kaedah ini membenarkan sintesis imej terkawal bagi adegan tunggal dan berbilang objek.
Apabila menggabungkan adegan, terdapat dua situasi yang perlu dipertimbangkan: N tetap dan N berubah (yang terakhir ialah latar belakang). Dalam amalan, latar belakang diwakili menggunakan perwakilan yang sama seperti sasaran, kecuali skala dan parameter terjemahan ditetapkan merentas keseluruhan pemandangan dan berpusat di sekitar asal ruang adegan.
Berat operator pemaparan 2D memetakan imej ciri kepada imej sintetik akhir, yang boleh diparameterkan sebagai CNN 2D dengan pengaktifan ReLU yang bocor, dan digabungkan dengan 3x 3 konvolusi dan pensampelan jiran terdekat untuk meningkatkan resolusi spatial Kadar. Lapisan terakhir menggunakan operasi sigmoid untuk mendapatkan ramalan imej akhir. Rajah skematiknya ditunjukkan dalam Rajah 21.
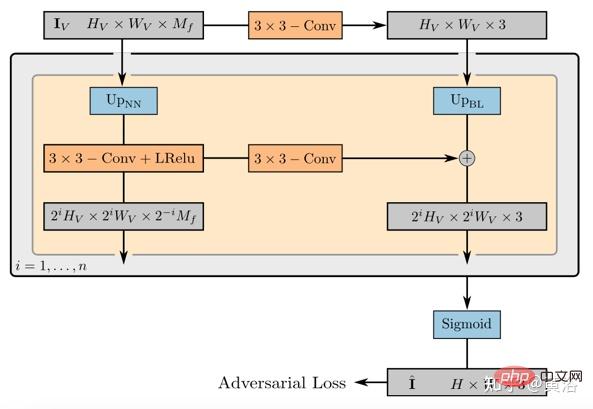
Pendiskriminasi juga merupakan CNN dengan pengaktifan ReLU yang bocor.
Atas ialah kandungan terperinci Perspektif baharu tentang penjanaan imej: membincangkan kaedah generalisasi berasaskan NeRF. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah kemahiran yang diperlukan untuk bekerja dalam industri PHP?
Apakah kemahiran yang diperlukan untuk bekerja dalam industri PHP?
 fail biasa
fail biasa
 Bagaimana untuk menangani ketinggalan komputer riba dan tindak balas yang perlahan
Bagaimana untuk menangani ketinggalan komputer riba dan tindak balas yang perlahan
 Bagaimana untuk menetapkan status luar talian pada Douyin
Bagaimana untuk menetapkan status luar talian pada Douyin
 Penggunaan arahan sumber dalam linux
Penggunaan arahan sumber dalam linux
 Bolehkah syiling BAGS disimpan lama?
Bolehkah syiling BAGS disimpan lama?
 Bagaimana untuk mendapatkan data dalam html
Bagaimana untuk mendapatkan data dalam html
 Apa yang perlu dilakukan jika imej terbenam tidak dipaparkan sepenuhnya
Apa yang perlu dilakukan jika imej terbenam tidak dipaparkan sepenuhnya








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



