


Artikel ini membawakan anda pengetahuan yang berkaitan tentang jadual data terutamanya berkongsi kaedah sub-jadual mengimbangi diri untuk menyelesaikan kecondongan data. Saya harap ia dapat membantu semua orang.
Artikel ini terutamanya menerangkan jadual data aplikasi sistem token B-side untuk menyelesaikan masalah peningkatan volum data perniagaan dan sedia ada condong data Senario utama ialah masalah condong data satu-ke-banyak
Pertama, mari kita terangkan secara ringkas latar belakang perniagaan Token B. Sistem token B digunakan dalam senario pemasaran untuk mengikat ramai pengguna kepada satu token dan kemudian mengikat token kepada promosi untuk mencapai pemasaran pembezaan dan ketepatan Umumnya, kitaran hayat token adalah bersamaan dengan promosi ini.
Hubungan antara token dan pengguna token ialah hubungan satu dengan banyak Sistem token awal yang digunakan jed untuk membahagikan Perpustakaan mempunyai 2 serpihan Ia telah dikembangkan sekali untuk mencapai 8 serpihan, dan bilangan baris data yang disimpan mencapai 120 juta
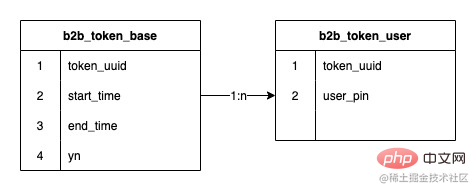
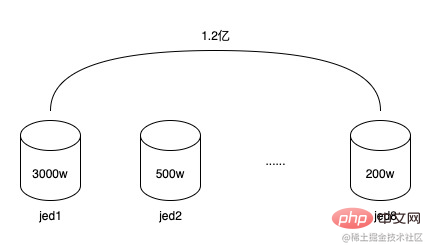
120 juta data, diedarkan dalam 8 sub-pangkalan data, dengan purata 15 juta dalam setiap sub-pangkalan data, tetapi kerana medan sub-pangkalan data menggunakan ID token (token_uuid), ada yang mempunyai sedikit pengguna token, hanya beberapa ribu hingga 10,000, ada yang mempunyai ramai pengguna token, 1 juta hingga 1.5 juta, jumlah bilangan token tidak banyak, hanya kira-kira 20,000, jadi data wujud Cenderung, sesetengah sub-pangkalan data mempunyai lebih daripada 30 juta data, dan sesetengah sub-pangkalan data mungkin hanya mempunyai beberapa juta, yang telah mula membawa kepada penurunan dalam prestasi membaca dan menulis pangkalan data. Dan kerana struktur data jadual perhubungan pengguna token adalah sangat mudah, walaupun terdapat banyak baris data, ia tidak mengambil banyak ruang. Jumlah ruang yang diduduki bagi 8 sub-pangkalan data adalah kurang daripada 20G. Pada masa yang sama, kitaran hayat token pada asasnya adalah sama dengan promosi Selepas token menyampaikan satu atau beberapa promosi, ia perlahan-lahan akan tamat tempoh dan dibuang, dan token baharu akan terus dibuat pada masa hadapan. Jadi token yang telah tamat tempoh ini boleh diarkibkan.
Pada masa yang sama, disebabkan perkembangan perniagaan B-side, terdapat lebih banyak permintaan perniagaan Melalui komunikasi dengan perniagaan, saya mengetahui bahawa sistem pemilihan automatik akan dilancarkan pada masa akan datang secara automatik membuat token dan memilih orang yang sesuai untuk promosi Pada masa hadapan Kenaikan data bulanan adalah kira-kira 30 juta Jika ia berjalan selama satu tahun, ia akan meningkat sebanyak 360 juta juta. Seni bina reka bentuk semasa sama sekali tidak dapat memenuhi keperluan perniagaan.
Pada masa yang sama, pada masa ini terdapat fungsi untuk menanyakan pengguna di bawah token dalam halaman berdasarkan ID token, tetapi ia hanya untuk operasi pihak pengurusan dan tidak digunakan dengan kerap.
Menghadapi prestasi membaca dan menulis pangkalan data yang semakin menurun , serta keperluan pertumbuhan perniagaan, kini menghadapi masalah berikut:
Bagaimana untuk menyelesaikan masalah terlalu banyak baris data dalam satu jadual
Skim sub-pangkalan data semasa mempunyai kecondongan data yang serius
Jika kita dapat mengatasi pertumbuhan data masa hadapan
Secara amnya, untuk menangani masalah pertama, ia biasanya memecah pangkalan data dan pemecahan, dan pada masa ini kami mempunyai 8 pangkalan data serpihan, dan 8 sub-pangkalan data menduduki kurang daripada 20G ruang Sumber pangkalan data tunggal sangat terbuang, jadi kami tidak akan mempertimbangkan untuk menambah lebih banyak sub-pangkalan data sama sekali, jadi pembahagian jadual adalah penyelesaiannya.
Biasanya terdapat dua cara untuk membahagikan data kepada jadual: jadual menegak dan jadual mendatar.
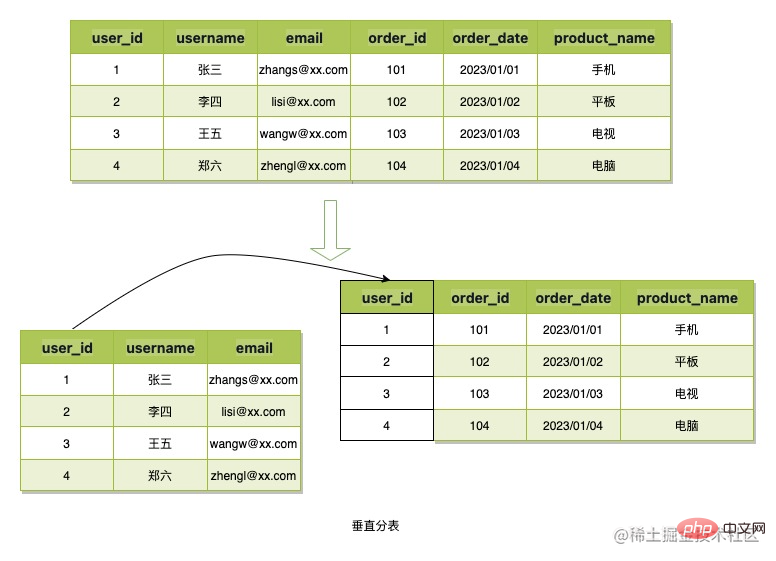
Pemisahan jadual menegak merujuk kepada pemisahan lajur data dan kemudian menggunakan kunci utama atau medan perniagaan lain untuk perkaitan, dengan itu mengurangkan ruang yang diduduki oleh data jadual tunggal atau mengurangkan lebihan. Untuk storan sisa, struktur data adegan token B adalah mudah dan data mengambil sedikit ruang, jadi kaedah pemisahan jadual ini tidak akan digunakan.
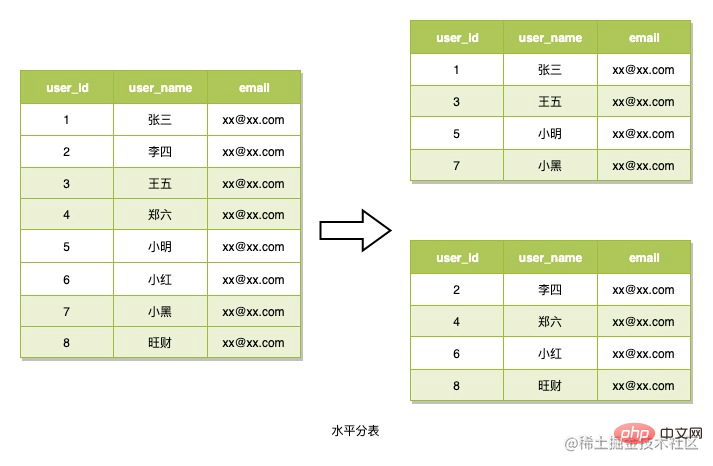
Pembahagian jadual mendatar merujuk kepada pembahagian baris data kepada berbilang jadual menggunakan algoritma penghalaan Data juga dibaca berdasarkan algoritma penghalaan ini semasa membaca biasanya digunakan untuk menangani senario di mana struktur data tidak kompleks tetapi terdapat sejumlah besar baris data. Inilah yang kita akan gunakan. Apa yang perlu diambil kira apabila menggunakan kaedah ini ialah cara mereka bentuk algoritma penghalaan Kaedah ini juga digunakan di sini untuk membahagikan jadual.
Terdapat banyak cara untuk menggunakan algoritma penghalaan jadual data dalam industri Salah satunya ialah menggunakan cincang yang konsisten, pilih Untuk medan sub-jadual yang sesuai, nilai selepas pencincangan nilai medan adalah tetap Gunakan nilai ini untuk mendapatkan nombor siri tetap melalui operasi modulo atau bitwise, dengan itu menentukan jadual mana data disimpan.
Kebanyakan aplikasi yang lebih biasa seperti sub-perpustakaan menggunakan pencincangan yang konsisten Dengan mengira nilai medan sub-pustaka secara serta-merta, ia dinilai kepunyaan sub-pustaka data itu dan kemudian memutuskan sub-pustaka mana yang hendak disimpan. data ke dalam atau membaca data daripada . Jika medan sub-pangkalan data tidak dinyatakan semasa pertanyaan, permintaan pertanyaan perlu dihantar ke semua sub-pangkalan data pada masa yang sama, dan akhirnya hasilnya diringkaskan.
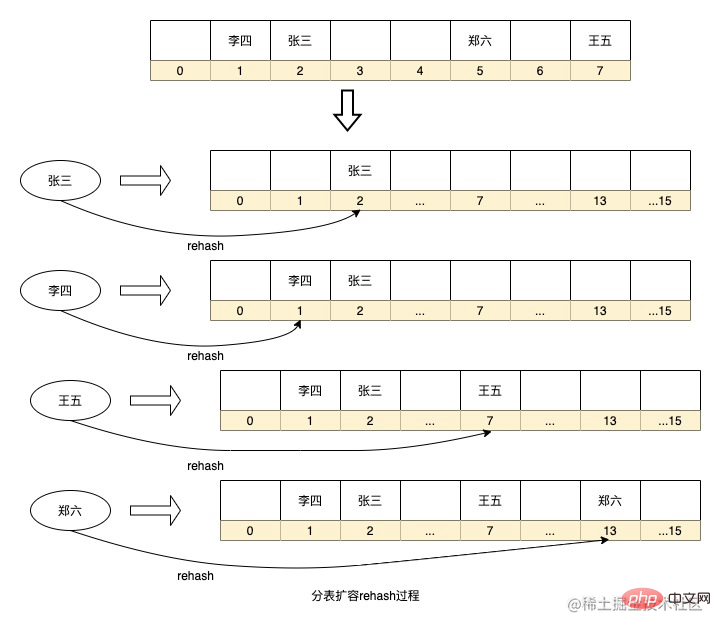
Selain itu, struktur data HashMap seperti kod java sebenarnya merupakan strategi pembahagian jadual bagi algoritma cincang yang konsisten, dengan mencincang kekunci, ia menentukan nombor siri data yang akan disimpan dalam tatasusunan digunakan dalam HashMap bukan modulo Daripada mendapatkan nombor siri, operasi bitwise digunakan Kaedah ini juga menentukan bahawa pengembangan HashMap adalah berdasarkan saiz 2 kepada kuasa x peluang di masa hadapan.
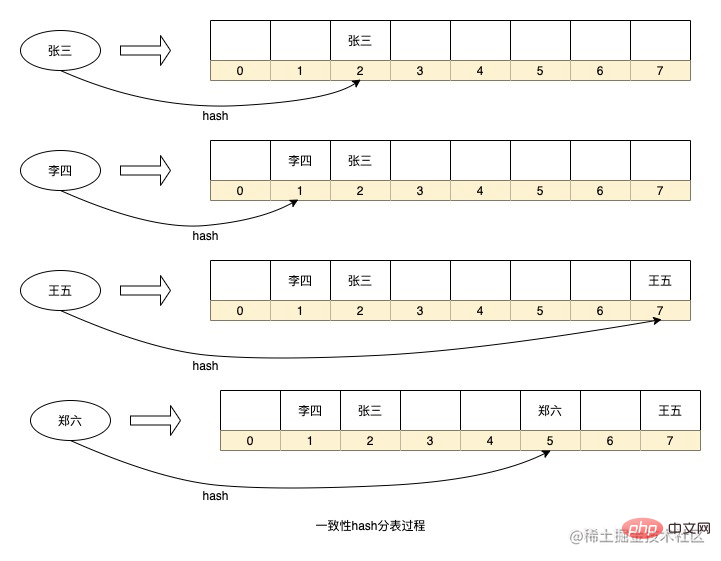
Di atas adalah proses penyimpanan Hash data yang dipermudahkan dalam HashMap Sudah tentu, saya telah meninggalkan beberapa butiran Sebagai contoh, setiap nod dalam HashMap ialah senarai terpaut (terlalu banyak konflik akan menyebabkan akan menjadi pokok merah-hitam). Apabila digunakan dalam senario kami, setiap nombor siri boleh dianggap sebagai jadual data.
Kelebihan algoritma penghalaan di atas ialah strategi penghalaan adalah mudah, dan tidak perlu menambah ruang storan tambahan untuk pengiraan masa nyata Walau bagaimanapun, terdapat juga masalah yang jika anda ingin mengembangkan kapasiti, anda perlu mencincang semula data sejarah untuk penghijrahan, seperti pembahagian pangkalan data Jika perpustakaan menambah sub-pangkalan data, semua data perlu dikira semula ke dalam sub-pangkalan data pengembangan HashMap juga akan melakukan rehash untuk mengira semula nombor jujukan daripada kunci dalam tatasusunan. Jika jumlah data terlalu besar, proses pengiraan ini akan mengambil masa yang lama. Pada masa yang sama, jika terdapat terlalu sedikit jadual data, atau medan yang dipilih untuk sharding mempunyai diskret yang rendah, ia akan menyebabkan data condong.
Terdapat juga algoritma sub-jadual yang mengoptimumkan proses pencincangan ini yang konsisten Kaedah ini mengabstrakkan banyak nod maya antara nod entiti algoritma cincang yang konsisten untuk memukul data pada nod maya ini, dan setiap nod entiti sebenarnya bertanggungjawab ke atas data nod maya bersebelahan dengan nod entiti lain dalam arah lawan jam nod entiti. Kelebihan kaedah ini ialah jika anda perlu mengembangkan kapasiti dan menambah nod, nod tambahan akan diletakkan di mana-mana pada gelang, dan ia hanya akan menjejaskan data nod bersebelahan mengikut arah jam nod Hanya sebahagian data dalam nod perlu dipindahkan ke Hanya memasangnya pada nod baharu ini, yang sangat mengurangkan proses rehash. Pada masa yang sama, disebabkan bilangan nod maya yang banyak, data juga boleh diedarkan dengan lebih sekata pada cincin Selagi nod fizikal diletakkan di lokasi yang sesuai, masalah kecondongan data boleh diselesaikan setakat yang mungkin. .
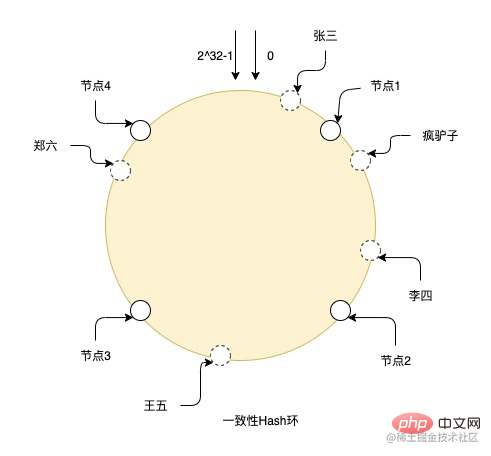
Contohnya, gambar menunjukkan proses pencincangan gelang Hash yang konsisten Terdapat nod dari 0 hingga 2^32-1 dalam keseluruhan gelang dan garis pepejal adalah nod sebenar, yang lain adalah semua nod maya Zhang San jatuh ke nod maya pada gelang melalui pencincangan, dan kemudian mencari nod sebenar mengikut arah jam dari kedudukan nod maya nod sebenar, jadi Crazy Donkey dan Li Si menyimpan Pada nod 2, Wang Wu berada pada nod 3, dan Zheng Liu berada pada nod 4.
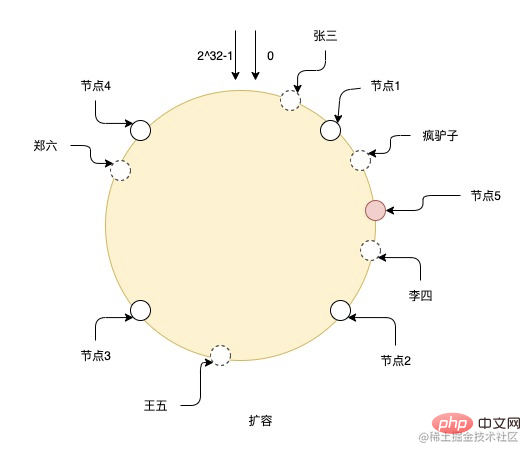
Selepas mengembangkan kapasiti nod 5, data antara nod 1 dan nod 5 perlu dipindahkan ke nod 5, dan data nod lain tidak perlu berubah. Tetapi seperti yang anda lihat dalam rajah, menambah hanya satu nod ini dengan mudah boleh membawa kepada data tidak sekata yang bertanggungjawab untuk setiap nod Contohnya, nod 2 dan nod 5 bertanggungjawab untuk data yang lebih sedikit daripada nod lain, jadi lebih baik untuk mengembangkan nod. kapasiti adalah lebih baik untuk mengembangkan kapasiti secara eksponen supaya data boleh terus kekal seragam.
Berbalik kepada senario perniagaan token B, saya perlu dapat mencapai tuntutan berikut
Pertama sekali, sharding jadual mendatar mesti digunakan untuk menyelesaikan masalah volum data yang berlebihan dalam satu jadual
Ia perlu dapat menyokong pertanyaan paging pengguna berdasarkan token
Memandangkan kenaikan data perniagaan semasa ialah 30 juta, tetapi kemungkinan pertumbuhan perniagaan yang berterusan pada masa hadapan tidak diketepikan, bilangan sub-jadual perlu dapat untuk menyokong pengembangan masa hadapan
Bilangan baris data terlalu tinggi dan akan dikembangkan pada masa hadapan. Ia mesti dipastikan bahawa tiada pemindahan data diperlukan atau kos pemindahan data adalah rendah
Masalah kecondongan data perlu diselesaikan untuk memastikan prestasi keseluruhan tidak berkurangan akibat volum data yang berlebihan dalam satu jadual
Berdasarkan permintaan di atas, lihat dahulu soalan b Jika anda ingin menyokong pertanyaan paging pengguna berdasarkan token, anda perlu memastikan bahawa semua pengguna di bawah token berada pada jadual yang sama untuk menyokong pertanyaan paging Algoritma ringkasan dan gabungan adalah terlalu kompleks, dan terlalu banyak jadual akan mengurangkan prestasi pertanyaan. Walaupun fungsi pertanyaan juga boleh disediakan dengan menggunakan data heterogen, ia hanya untuk sebilangan kecil permintaan pertanyaan pihak pengurusan untuk melaksanakan heterogeniti data Kosnya agak tinggi tetapi faedahnya tidak jelas, dan ia juga membazir sumber. Oleh itu, medan sub-jadual hanya boleh ditentukan menggunakan ID token.
Seperti yang dinyatakan di atas, bilangan ID token tidaklah besar, dan bilangan pengguna di bawah token berjulat dari 10,000 hingga 1 juta Hanya menggunakan pencincangan yang konsisten dan menggunakan ID token sebagai strategi penggolongan akan membawa kepada kecondongan data adalah serius. , dan kos pemindahan data juga tinggi semasa pengembangan masa hadapan.
Walau bagaimanapun, menggunakan gelang cincang yang konsisten akan membawa kepada pengembangan terbaik pada masa hadapan dengan gandaan 2. Jika tidak, sesetengah nod akan bertanggungjawab untuk lebih banyak nod maya dan sesetengah nod akan bertanggungjawab untuk lebih sedikit nod maya , mengakibatkan Data tidak sekata. Walau bagaimanapun, apabila berkomunikasi dengan rakan sekerja pangkalan data, bilangan jadual data dalam satu pangkalan data tidak boleh terlalu banyak, jika tidak, ia akan memberi tekanan yang besar pada pangkalan data Kaedah cincin cincang yang konsisten boleh mengembangkan kapasiti dua atau tiga kali, yang akan menyebabkan bilangan sub-jadual untuk mencapai satu nilai yang sangat tinggi.
Berdasarkan isu di atas, selepas memutuskan untuk menggunakan ID token sebagai sub-jadual, kami perlu menumpukan pada cara menyokong pengembangan dinamik dan menyelesaikan masalah kecondongan data .
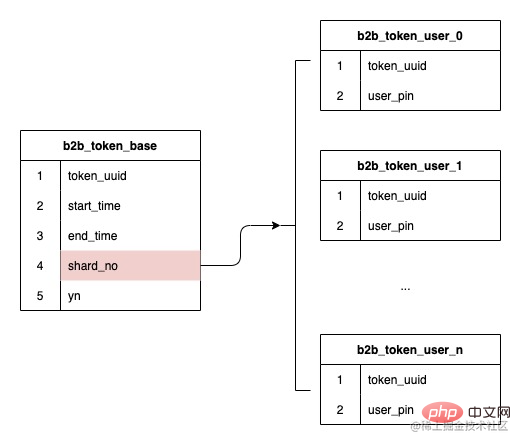

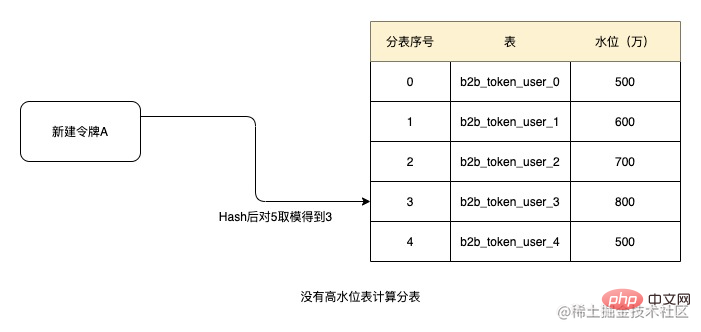
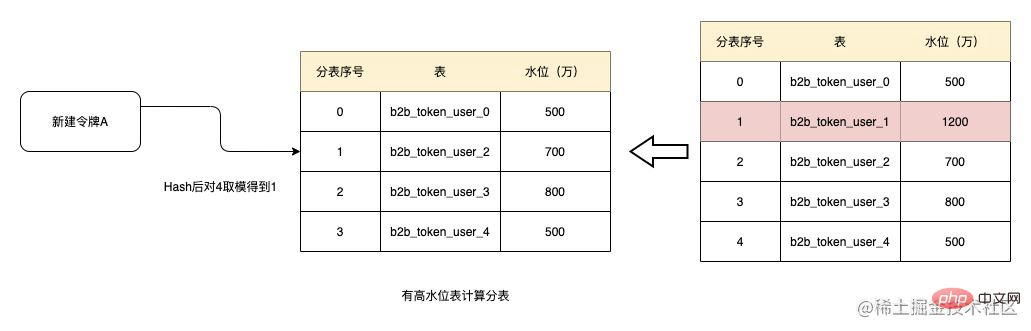
Pemantauan ambang paras air dan pengembangan
Pada masa ini, ambang paras air masih ditetapkan secara manual. Anda hanya boleh menetapkan satu dan melaraskannya dengan betul selepas penggera. Walau bagaimanapun, sebenarnya, sistem secara automatik boleh memantau turun naik dalam prestasi baca dan tulis antara muka Didapati apabila kebanyakan ekspresi mencapai tahap tinggi, prestasi baca dan tulis antara muka tidak berubah dengan ketara meningkatkan ambang secara automatik untuk membentuk ambang pintar.
Apabila terdapat perubahan ketara dalam prestasi baca dan tulis antara muka dan didapati bahawa kebanyakan jadual telah mencapai ambang, penggera akan dikeluarkan yang menunjukkan bahawa pengembangan kapasiti perlu dipertimbangkan.
Tiada peluru perak untuk menyelesaikan masalah sesuai dengan keadaan kita sekarang Untuk perniagaan dan senario, tidak ada baik atau buruk, cuma sesuai atau tidak.
Atas ialah kandungan terperinci Peluasan pengetahuan: kaedah pemisahan jadual mengimbangi sendiri untuk menyelesaikan senget data. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menyambung ke pangkalan data dalam vb
Bagaimana untuk menyambung ke pangkalan data dalam vb
 Bagaimana untuk membuka panel kawalan win11
Bagaimana untuk membuka panel kawalan win11
 kunci vs2010
kunci vs2010
 Aliran pasaran mata wang riak
Aliran pasaran mata wang riak
 Apakah pengoptimuman topologi
Apakah pengoptimuman topologi
 Bagaimana untuk menyelesaikan masalah yang tomcat tidak dapat memaparkan halaman
Bagaimana untuk menyelesaikan masalah yang tomcat tidak dapat memaparkan halaman
 Kaedah BigDecimal untuk membandingkan saiz
Kaedah BigDecimal untuk membandingkan saiz
 Padam medan jadual
Padam medan jadual











![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



