


Artikel ini membawakan anda pengetahuan yang berkaitan tentang Python, yang terutamanya memperkenalkan pengetahuan yang berkaitan tentang perangkak secara ringkasnya, crawler ialah nama untuk proses menggunakan program untuk mendapatkan data di Internet, saya harap ia membantu semua orang.

Perangkak hanyalah nama untuk proses menggunakan program untuk mendapatkan data di Internet.
Jika kita ingin mendapatkan data pada rangkaian, kita perlu memberikan perangkak alamat tapak web (biasanya dipanggil URL dalam program), perangkak menghantar permintaan HTTP kepada pelayan halaman web sasaran, dan pelayan memulangkan data Kepada klien (iaitu perangkak kami), perangkak kemudian melakukan satu siri operasi seperti menghurai dan menyimpan data.
Crawler boleh menjimatkan masa kita Sebagai contoh, jika saya ingin mendapatkan 250 filem Douban teratas, jika kita tidak menggunakan crawler, kita perlu memasukkan URL terlebih dahulu. Filem Douban pada penyemak imbas, dan klien ( Penyemak imbas) mencari alamat IP pelayan halaman web Douban Movie melalui analisis, dan kemudian mewujudkan sambungan dengannya Pelayar mencipta permintaan HTTP dan menghantarnya ke pelayan Filem Douban . Selepas pelayan menerima permintaan, ia mengekstrak senarai Top250 daripada pangkalan data , merangkumkannya ke dalam respons HTTP, dan kemudian mengembalikan hasil tindak balas kepada penyemak imbas dan kami melihat data. Perangkak kami juga berdasarkan proses ini, tetapi ia ditukar kepada bentuk kod.
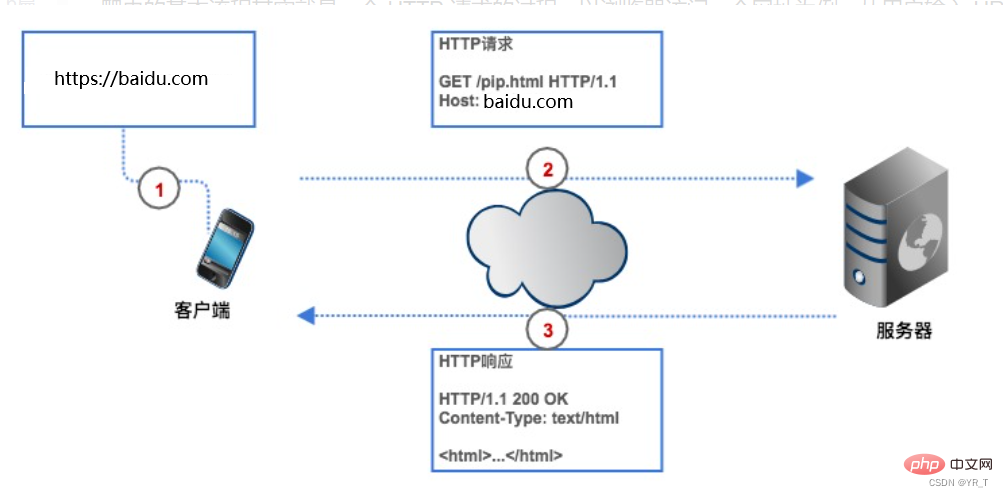
Permintaan HTTP terdiri daripada baris permintaan, pengepala permintaan, baris kosong dan kandungan permintaan.

Baris permintaan terdiri daripada tiga bahagian:
1. Kaedah permintaan, kaedah permintaan biasa ialah GET, POST, PUT, DELETE, HEAD
2. Laluan sumber yang pelanggan ingin dapatkan
3. Ia adalah nombor versi protokol HTTP yang digunakan oleh klien
Pengepala permintaan ialah penerangan tambahan bagi permintaan yang dihantar oleh pelanggan kepada pelayan, seperti identiti pelawat, yang akan dibincangkan di bawah .
Ibu permintaan ialah data yang diserahkan oleh pelanggan kepada pelayan, seperti maklumat akaun dan kata laluan yang pengguna perlu tambah semasa log masuk. Pengepala permintaan dan isi permintaan dipisahkan oleh baris kosong. Badan permintaan tidak termasuk dalam semua permintaan Contohnya, GET umum tidak mempunyai badan permintaan.
Gambar di atas ialah permintaan HTTP POST yang dihantar ke pelayan apabila penyemak imbas log masuk ke Douban Nama pengguna dan kata laluan ditentukan dalam badan permintaan.
Format respons HTTP sangat serupa dengan format permintaan, dan juga terdiri daripada baris respons, pengepala respons, baris kosong dan badan respons.

Barisan respons juga mengandungi tiga bahagian, iaitu nombor versi HTTP pelayan, kod status respons dan perihalan status.
Terdapat jadual kod status di sini, sepadan dengan maksud setiap kod status



Bahagian 2 Ia adalah pengepala respons Pengepala respons sepadan dengan pengepala permintaan Ia adalah beberapa arahan tambahan untuk respons oleh pelayan, seperti apakah format kandungan respons, berapa lama kandungan respons, bilakah itu. dikembalikan kepada klien, malah beberapa maklumat kuki akan diletakkan dalam pengepala respons.
Bahagian ketiga ialah badan respons, iaitu data respons sebenar Data ini sebenarnya adalah kod sumber HTML halaman web.
Perangkak boleh menggunakan banyak bahasa seperti Python, C++, dll., tetapi saya rasa Python adalah yang paling mudah,
kerana Python mempunyai perpustakaan siap pakai , telah dikapsulkan dengan hampir sempurna
Walaupun C++ juga mempunyai perpustakaan siap pakai, perangkaknya masih agak khusus. walaupun pada yang sama Keserasian antara versi pengkompil yang berbeza tidak kukuh, jadi ia tidak begitu mudah untuk digunakan. Jadi hari ini kami terutamanya memperkenalkan perangkak python.
cmd run: permintaan pemasangan pip untuk permintaan pemasangan.
Kemudian masukkan
permintaan import pada IDLE atau pengkompil (secara peribadi mengesyorkan VS Code atau Pycharm) untuk dijalankan Jika tiada ralat dilaporkan, pemasangan berjaya.
Kaedah untuk memasang kebanyakan perpustakaan ialah: pip install xxx (nama perpustakaan)
| requests.request() | 构造一个请求,支撑一下各方法的基本方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
requests.head() |
获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch( ) | 向HTML网页提交局部修改请求,对应于HTTP的PATCT |
| requests.delete() | 向HTML网页提交删除请求,对应于HTTP的DELETE |
r = requests.get(url)
termasuk dua objek penting:
Bina objek Permintaan yang meminta sumber daripada pelayan; mengembalikan objek Respons yang mengandungi sumber pelayan
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式(如果header中不存在charset,则认为编码为ISO-8859-1) |
| r.apparent_encoding | 从内容中分析的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
permintaan ialah pustaka perangkak yang paling asas boleh membuat terjemahan mudah
Saya akan meletakkan struktur projek projek perangkak kecil yang saya buat Kod sumber lengkap boleh dimuat turun melalui sembang peribadi dengan saya.
Berikut ialah kod sumber bahagian terjemahan
import requests
def English_Chinese():
url = "https://fanyi.baidu.com/sug"
s = input("请输入要翻译的词(中/英):")
dat = {
"kw":s
}
resp = requests.post(url,data = dat)# 发送post请求
ch = resp.json() # 将服务器返回的内容直接处理成json => dict
resp.close()
dic_lenth = len(ch['data'])
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])Penjelasan kod terperinci:
Import modul permintaan dan tetapkan url ke URL halaman web terjemahan Baidu.
Kemudian hantar permintaan melalui kaedah pos, dan kemudian taipkan hasil yang dikembalikan ke dalam dic (kamus), tetapi kali ini kami mencetaknya dan mendapati ia seperti ini.

Ini ialah senarai dalam kamus dalam kamus, mungkin kelihatan seperti ini
{ xx:xx , xx:[ {xx:xx} , {xx:xx} , {xx:xx} , {xx:xx} ] }
Tempat yang saya tandakan dengan warna merah adalah maklumat yang kita perlukan.
Andaikan terdapat n kamus dalam senarai bertanda biru, kita boleh mendapatkan nilai n melalui fungsi len(),
dan gunakan gelung for untuk melintasi untuk mendapatkan hasilnya.
dic_lenth = len(ch['data']
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])Baiklah, itu sahaja perkongsian hari ini, bye~
Hei? Saya terlupa satu perkara, izinkan saya memberi anda kod lain untuk merangkak cuaca!
# -*- coding:utf-8 -*-
import requests
import bs4
def get_web(url):
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59"}
res = requests.get(url, headers=header, timeout=5)
# print(res.encoding)
content = res.text.encode('ISO-8859-1')
return content
def parse_content(content):
soup = bs4.BeautifulSoup(content, 'lxml')
'''
存放天气情况
'''
list_weather = []
weather_list = soup.find_all('p', class_='wea')
for i in weather_list:
list_weather.append(i.text)
'''
存放日期
'''
list_day = []
i = 0
day_list = soup.find_all('h1')
for each in day_list:
if i <= 6:
list_day.append(each.text.strip())
i += 1
# print(list_day)
'''
存放温度:最高温度和最低温度
'''
tem_list = soup.find_all('p', class_='tem')
i = 0
list_tem = []
for each in tem_list:
if i == 0:
list_tem.append(each.i.text)
i += 1
elif i > 0:
list_tem.append([each.span.text, each.i.text])
i += 1
# print(list_tem)
'''
存放风力
'''
list_wind = []
wind_list = soup.find_all('p', class_='win')
for each in wind_list:
list_wind.append(each.i.text.strip())
# print(list_wind)
return list_day, list_weather, list_tem, list_wind
def get_content(url):
content = get_web(url)
day, weather, tem, wind = parse_content(content)
item = 0
for i in range(0, 7):
if item == 0:
print(day[i]+':\t')
print(weather[i]+'\t')
print("今日气温:"+tem[i]+'\t')
print("风力:"+wind[i]+'\t')
print('\n')
item += 1
elif item > 0:
print(day[i]+':\t')
print(weather[i] + '\t')
print("最高气温:"+tem[i][0]+'\t')
print("最低气温:"+tem[i][1] + '\t')
print("风力:"+wind[i]+'\t')
print('\n')[Cadangan berkaitan: Tutorial video Python3]
Atas ialah kandungan terperinci Fahami perangkak Python dalam satu artikel. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



