


Artikel ini membawakan anda pengetahuan yang berkaitan tentang mysql, yang terutamanya memperkenalkan isu berkaitan tentang pengoptimuman pertanyaan biasa Mari kita lihat bersama-sama.

Pembelajaran yang disyorkan: tutorial video mysql
Selepas program dalam talian dan berjalan untuk tempoh masa, sekali jumlah data meningkat, lebih kurang Ia jarang merasakan bahawa sistem mempunyai kelewatan, membeku, dan lain-lain. Apabila masalah tersebut berlaku, pengaturcara atau arkitek perlu melakukan penalaan sistem Antaranya, sejumlah besar pengalaman praktikal menunjukkan bahawa walaupun terdapat banyak kaedah penalaan, mereka melibatkan Kandungan penalaan SQL masih merupakan bahagian yang sangat penting Artikel ini akan menggabungkan contoh untuk meringkaskan beberapa strategi pengoptimuman SQL yang mungkin terlibat dalam kerja; Boleh dikatakan bahawa untuk kebanyakan sistem, adalah perkara biasa untuk membaca lebih banyak dan menulis kurang, yang bermaksud bahawa SQL yang terlibat dalam pertanyaan adalah operasi frekuensi yang sangat tinggi; entri ke jadual ujian Data
Gunakan prosedur tersimpan berikut untuk mencipta kumpulan data untuk satu jadual, cuma gantikan jadual dengan jadual anda sendiriKemudian panggil stored procedure
Artikel ini telah menyediakan 3 jadual iaitu jadual pelajar, jadual kelas (kelas
), dan jadual akaun, setiap satu dengan 500,000, 10,000 dan 100,000 penyertaan. Data digunakan untuk ujian;create procedure addMyData() begin declare num int; set num =1; while num <= 100000 do insert into XXX_table values( replace(uuid(),'-',''),concat('测试',num),concat('cs',num),'123456' ); set num =num +1; end while; end ;
call addMyData();
1 Pengoptimuman pertanyaan paging
 Pertanyaan paging sering ditemui dalam pembangunan , di sana. ialah situasi di mana apabila bilangan paging sangat besar, pertanyaan selalunya sangat memakan masa Sebagai contoh, pertanyaan jadual pelajar, menggunakan pertanyaan SQL berikut, mengambil masa 0.2 saat; 🎜>
Pertanyaan paging sering ditemui dalam pembangunan , di sana. ialah situasi di mana apabila bilangan paging sangat besar, pertanyaan selalunya sangat memakan masa Sebagai contoh, pertanyaan jadual pelajar, menggunakan pertanyaan SQL berikut, mengambil masa 0.2 saat; 🎜>
Pengalaman praktikal memberitahu kami bahawa semakin jauh ke belakang, semakin rendah kecekapan pertanyaan paging Ini adalah masalah dengan pertanyaan paging, 
, pada masa ini anda memerlukan

10 Ingat rekod, hanya 400000 - 4 00010 rekod dikembalikan, rekod lain dibuang dan kos pengisihan pertanyaan sangat tinggi Idea pengoptimuman:
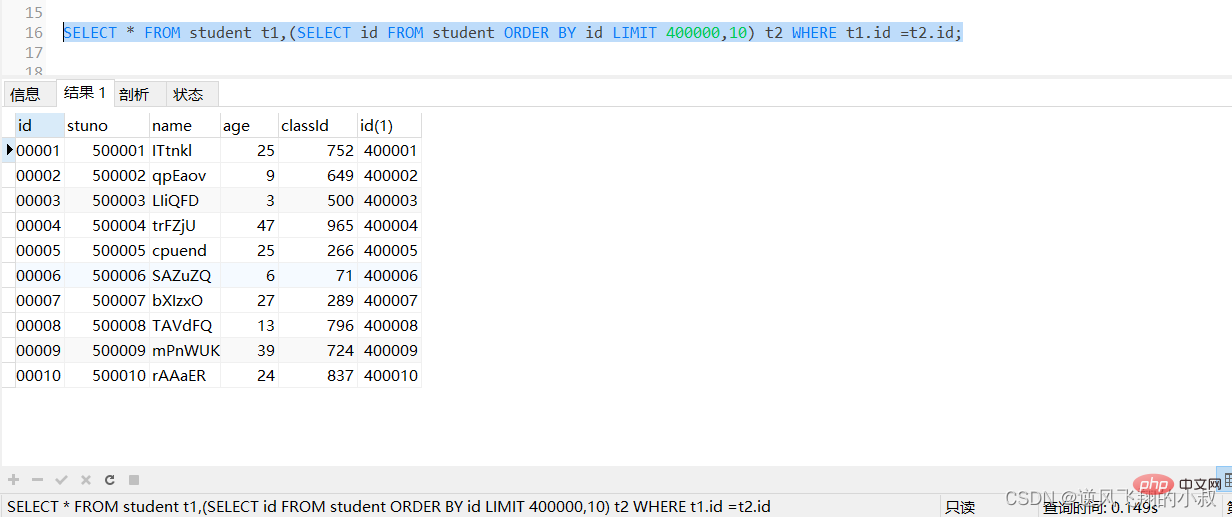
Lengkapkan operasi pengisihan dan halaman pada indeks, dan akhirnya kaitkan kembali ke lajur lain yang diperlukan untuk pertanyaan jadual asal berdasarkan kandungan kunci utamaSELECT * FROM student t1,(SELECT id FROM student ORDER BY id LIMIT 400000,10) t2 WHERE t1.id =t2.id;
执行上面的sql,可以看到响应时间有一定的提升;
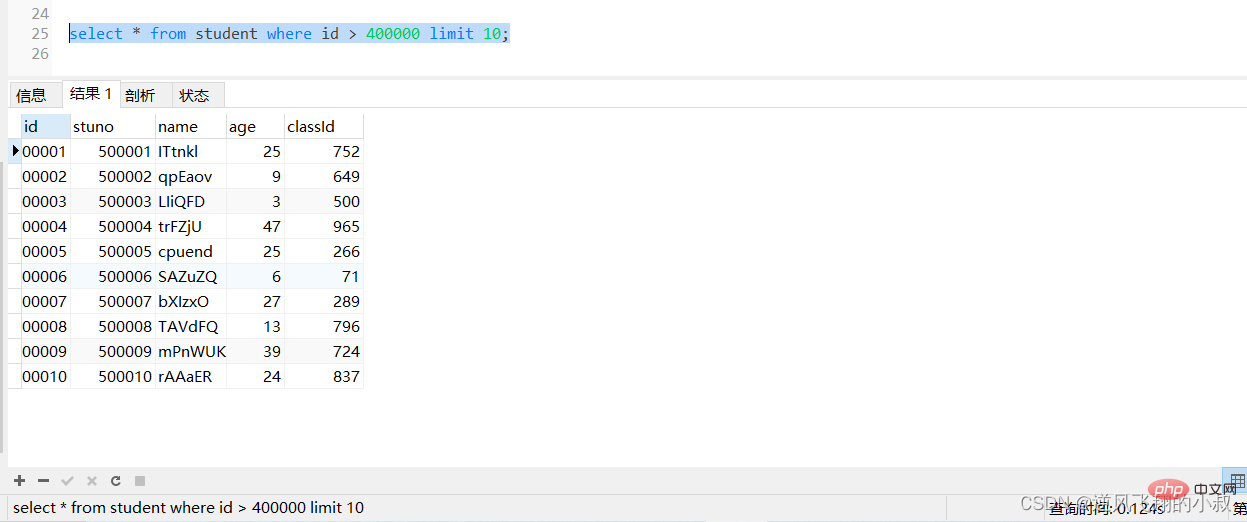
2)对于主键自增的表,可以把Limit 查询转换成某个位置的查询
select * from student where id > 400000 limit 10;
执行上面的sql,可以看到响应时间有一定的提升;
2、关联查询优化
在实际的业务开发过程中,关联查询可以说随处可见,关联查询的优化核心思路是,最好为关联查询的字段添加索引,这是关键,具体到不同的场景,还需要具体分析,这个跟mysql的引擎在执行优化策略的方案选择时有一定关系;
2.1 左连接或右连接
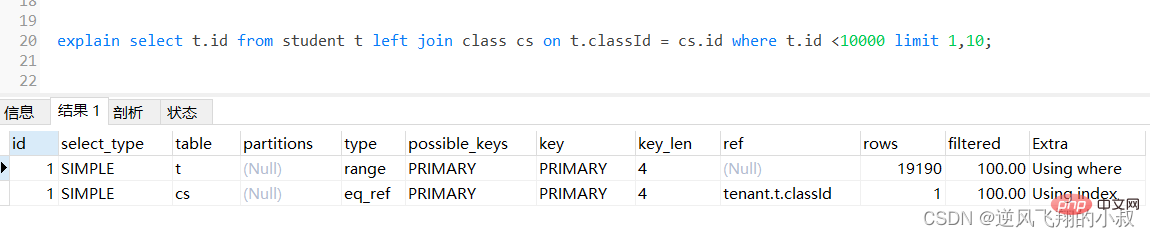
下面是一个使用left join 的查询,可以预想到这条sql查询的结果集非常大
select t.* from student t left join class cs on t.classId = cs.id;Salin selepas log masuk为了检查下sql的执行效率,使用explain做一下分析,可以看到,第一张表即left join左边的表student走了全表扫描,而class表走了主键索引,尽管结果集较大,还是走了索引;
针对这种场景的查询,思路如下:
- 让查询的字段尽量包含在主键索引或者覆盖索引中;
- 查询的时候尽量使用分页查询;
关于左连接(右连接)的explain结果补充说明
- 左连接左边的表一般为驱动表,右边的表为被驱动表;
- 尽可能让数据集小的表作为驱动表,减少mysql内部循环的次数;
- 两表关联时,explain结果展示中,第一栏一般为驱动表;
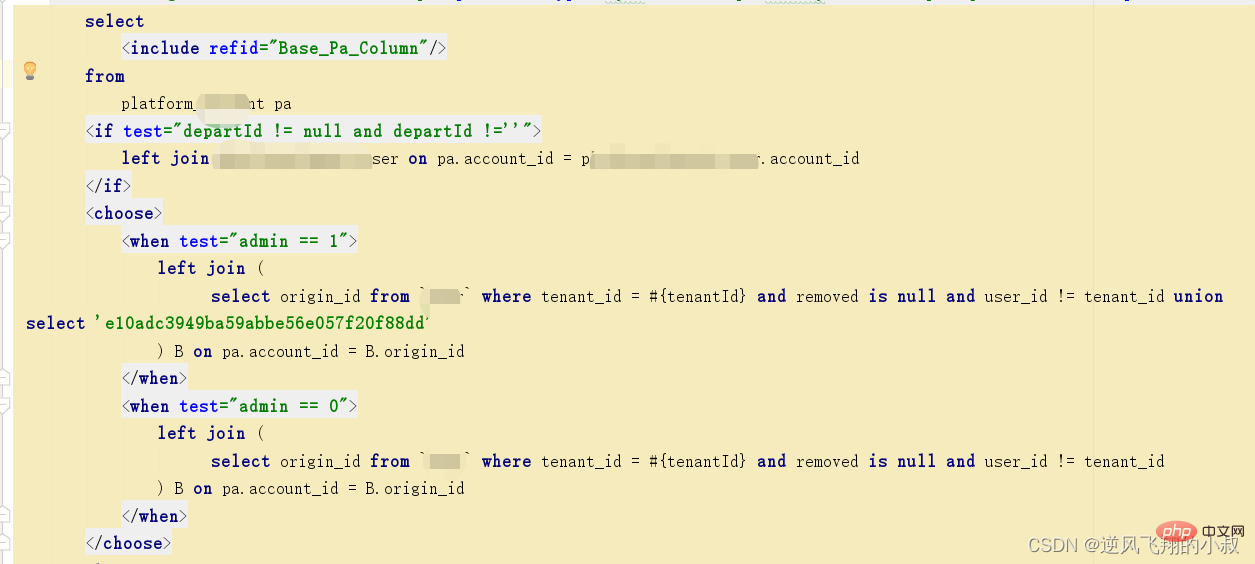
2.2 关联查询关联的字段建立索引
看下面的这条sql,其关联字段非表的主键,而是普通的字段;
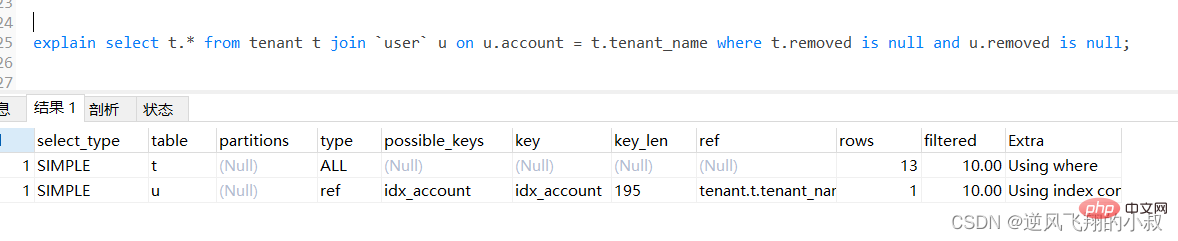
explain select u.* from tenant t left join `user` u on u.account = t.tenant_name where t.removed is null and u.removed is null;Salin selepas log masuk
通过explain分析可以发现,左边的表走了全表扫描,可以考虑给左边的表的tenant_name和user表的account 各自创建索引;
create index idx_name on tenant(tenant_name);
create index idx_account on `user`(account);
再次使用explain分析结果如下
可以看到第二行type变为ref,rows的数量优化比较明显。这是由左连接特性决定的,LEFT JOIN条件用于确定如何从右表搜索行,左边一定都有,所以右边是我们的关键点,一定需要建立索引 。
2.3 内连接关联的字段建立索引
我们知道,左连接和右连接查询的数据分别是完全包含左表数据,完全包含右表数据,而内连接(inner join 或join) 则是取交集(共有的部分),在这种情况下,驱动表的选择是由mysql优化器自动选择的;
在上面的基础上,首先移除两张表的索引
ALTER TABLE `user` DROP INDEX idx_account;
ALTER TABLE `tenant` DROP INDEX idx_name;使用explain语句进行分析
然后给user表的account字段添加索引,再次执行explain我们发现,user表竟然被当作是被驱动表了;
此时,如果我们给tenant表的tenant_name加索引,并移除user表的account索引,得出的结果竟然都没有走索引,再次说明,使用内连接的情况下,查询优化器将会根据自己的判断进行选择;
3、子查询优化
子查询在日常编写业务的SQL时也是使用非常频繁的做法,不是说子查询不能用,而是当数据量超出一定的范围之后,子查询的性能下降是很明显的,关于这一点,本人在日常工作中深有体会;
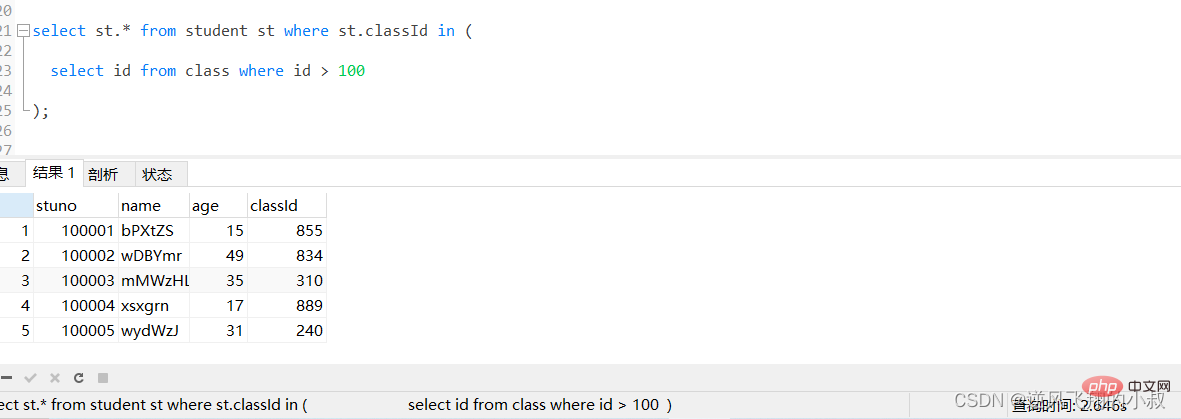
比如下面这条sql,由于student表数据量较大,执行起来耗时非常长,可以看到耗费了将近3秒;
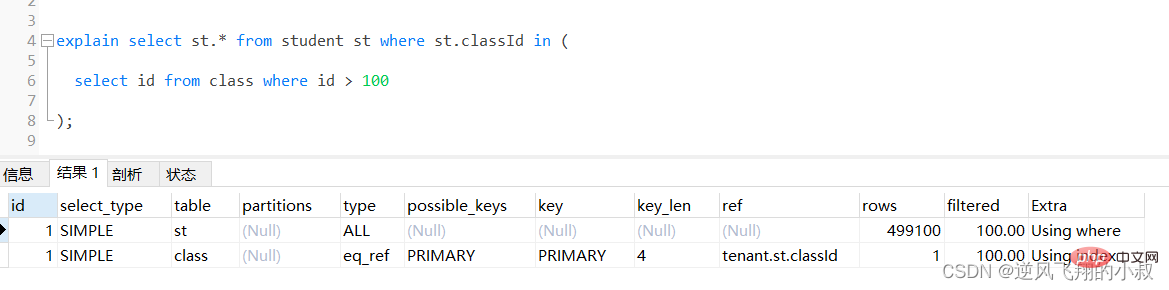
select st.* from student st where st.classId in ( select id from class where id > 100 );Salin selepas log masuk
通过执行explain进行分析得知,内层查询 id > 100的子查询尽管用上了主键索引,但是由于结果集太大,带入到外层查询,即作为in的条件时,查询优化器还是走了全表扫描;
针对上面的情况,可以考虑下面的优化方式
select st.id from student st join class cl on st.classId = cl.id where cl.id > 100;
子查询性能低效的原因
- 子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表 ,然后外层查询语句从临时表中查询记录,查询完毕后,再撤销这些临时表 。这样会消耗过多的CPU和IO资源,产生大量的慢查询;
- 子查询结果集存储的临时表,不论是内存临时表还是磁盘临时表都不能走索引 ,所以查询性能会受到一定的影响;
- 对于返回结果集比较大的子查询,其对查询性能的影响也就越大;
使用mysql查询时,可以使用连接(JOIN)查询来替代子查询。连接查询不需要建立临时表 ,其速度比子查询要快 ,如果查询中使用索引的话,性能就会更好,尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代;
一个真实的案例
在下面的这段sql中,优化前使用的是子查询,在一次生产问题的性能分析中,发现某个tenant_id下的数据达到了35万多,这样直接导致某个列表页面的接口查询耗时达到了5秒左右;
找到了问题的根源后,尝试使用上面的优化思路进行解决即可,优化后的sql大概如下,
4、排序(order by)优化
在mysql,排序主要有两种方式
- Using filesort : 通过表索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort
buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序;- Using index : 通过有序的索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高;
对于以上两种排序方式,Using index的性能高,而Using filesort的性能低,我们在优化排序操作时,尽量要优化为 Using index
4.1 使用age字段进行排序
由于age字段未加索引,查询结果按照age排序的时候发现使用了filesort,排序性能较低;
给age字段添加索引,再次使用order by时就走了索引;
4.2 使用多字段进行排序
通常在实际业务中,参与排序的字段往往不只一个,这时候,就可以对参与排序的多个字段创建联合索引;
如下根据stuno和age排序
给stuno和age添加联合索引
create index idx_stuno_age on `student`(stuno,age);
再次分析时结果如下,此时排序走了索引
关于多字段排序时的注意事项
1)排序时,需要满足最左前缀法则,否则也会出现 filesort;
Turutan indeks bersama yang kami buat di atas ialah stuno dan umur, iaitu, stuno di hadapan dan umur di belakang Apakah yang akan berlaku jika susunan isihan diterbalikkan semasa pertanyaan? Dengan menganalisis keputusan, didapati bahawa penyisihan fail telah digunakan; sambil mengekalkan pengisihan medan Apabila susunan kekal tidak berubah, secara lalai, jika kedua-duanya dalam tertib menaik atau menurun, tertib mengikut boleh menggunakan indeks Apakah yang berlaku jika satu dalam tertib menaik dan satu lagi dalam tertib menurun? Analisis mendapati bahawa failsort juga akan digunakan dalam kes ini; sangat serupa, dan perkara utama adalah seperti berikut:
kumpulan mengikut Walaupun tiada syarat penapis untuk menggunakan indeks, anda juga boleh menggunakan indeks secara terus
kumpulan mengikut isihan dahulu dan kemudian kumpulan. Ikut peraturan awalan kiri terbaik untuk pembinaan indeks; mempunyai, dan boleh ditulis dalam had di mana Jangan tulis syarat dalam memiliki; Kurangkan penggunaan pesanan dengan, jangan isih jika boleh, atau letakkan pengisihan dalam program. Pernyataan seperti Susun mengikut, kumpulan mengikut, dan berbeza menggunakan lebih banyak CPU, dan sumber CPU pangkalan data adalah sangat berharga
Jika sql mengandungi pernyataan pertanyaan seperti susunan mengikut, kumpulan mengikut, dan berbeza; set hasil ditapis mengikut keadaan di mana Sila simpan dalam 1000 baris, jika tidak, SQL akan menjadi sangat perlahan
5.1 Tambah indeks pada medan kumpulan dengan
Jika medan itu; tidak diindeks, keputusan analisis adalah seperti berikut Prestasi keputusan ini Jelas sekali tidak cekap
- Selepas menambah indeks ke stuno
- Tambahkan indeks bersama pada stuno dan umur
- Jika awalan kiri terbaik tidak diikuti, kumpulan mengikut prestasi akan menjadi kurang cekap
Situasi mengikut awalan kiri terbaik adalah seperti berikut
6 Pengoptimuman kiraan
kira() ialah fungsi agregat. Set hasil yang dikembalikan dinilai baris demi baris Jika parameter fungsi kiraan bukan NULL , nilai terkumpul ditambah dengan 1, jika tidak ia tidak ditambah, dan akhirnya nilai terkumpul dikembalikan; >
Penggunaan: kiraan (*), kiraan (kunci utama), kiraan (medan), kiraan (nombor)Penerangan terperinci beberapa cara menulis kiraan disenaraikan di bawah
Ringkasan nilai pengalamanDalam urutan kecekapan Lihat, kira(medan) < ; count(1) ≈ count(*), jadi cuba gunakan count(*)
Pembelajaran yang disyorkan:
tutorial video mysql
Atas ialah kandungan terperinci Penjelasan terperinci tentang strategi pengoptimuman pertanyaan biasa untuk MySql. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Label berkaitan:sumber:csdn.netArtikel sebelumnya:Penjelasan terperinci tentang penambahan MySQL, pemadaman, pengubahsuaian dan perangkap biasa Artikel seterusnya:Pengenalan Lanjutan MySQL kepada Indeks (Perkongsian Ringkasan)Kenyataan Laman Web iniKandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cnArtikel terbaru oleh pengarang































![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



