



Pembelajaran yang disyorkan: tutorial video mysql
Untuk arahan seterusnya, kami mula-mula membuat Perkara berikut table (MySQL5.7) mempunyai sejumlah 5 medan (a, b, c, d, e), antaranya a ialah kunci utama dan satu diwakili oleh b , c, indeks bersama yang terdiri daripada d, enjin storan ialah InnoDB, masukkan tiga keping data ujian. Sangat mengesyorkan diri anda untuk mencuba semua pernyataan dalam artikel ini dalam MySQL.
CREATE TABLE `test` ( `a` int NOT NULL AUTO_INCREMENT, `b` int DEFAULT NULL, `c` int DEFAULT NULL, `d` int DEFAULT NULL, `e` int DEFAULT NULL, PRIMARY KEY(`a`), KEY `idx_abc` (`b`,`c`,`d`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (1, 2, 3, 4, 5); INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (2, 2, 3, 4, 5); INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (3, 2, 3, 4, 5);
Pada masa ini, jika kita melaksanakan pernyataan SQL berikut, adakah anda fikir indeks akan digunakan?
SELECT b, c, d FROM test WHERE d = 2;
Jika anda mengikut prinsip padanan paling kiri (hanya dinyatakan seperti dalam indeks bersama, mulakan padanan dari medan paling kiri, jika medan dalam keadaan sepadan dengan susunan kiri ke kanan dalam indeks bersama , pergi Indeks, jika tidak, ia tidak akan pergi Ia boleh difahami dengan mudah bahawa indeks bersama (a, b, c) adalah bersamaan dengan mencipta indeks, (a, b) indeks dan (a, b, c) indeks) . EXPLAIN

Kembali pertanyaan jadual
Daripada struktur storan indeks di atas, kita dapat melihat bahawa pada pokok indeks kunci primer, melalui kunci primer, ia boleh dilakukan sekali gus Cari data yang kami perlukan dengan cepat. Ini adalah sangat intuitif, kerana kunci utama disimpan bersama-sama dengan rekod baris Setelah kunci utama terletak, rekod yang mengandungi semua medan yang anda cari terletak. 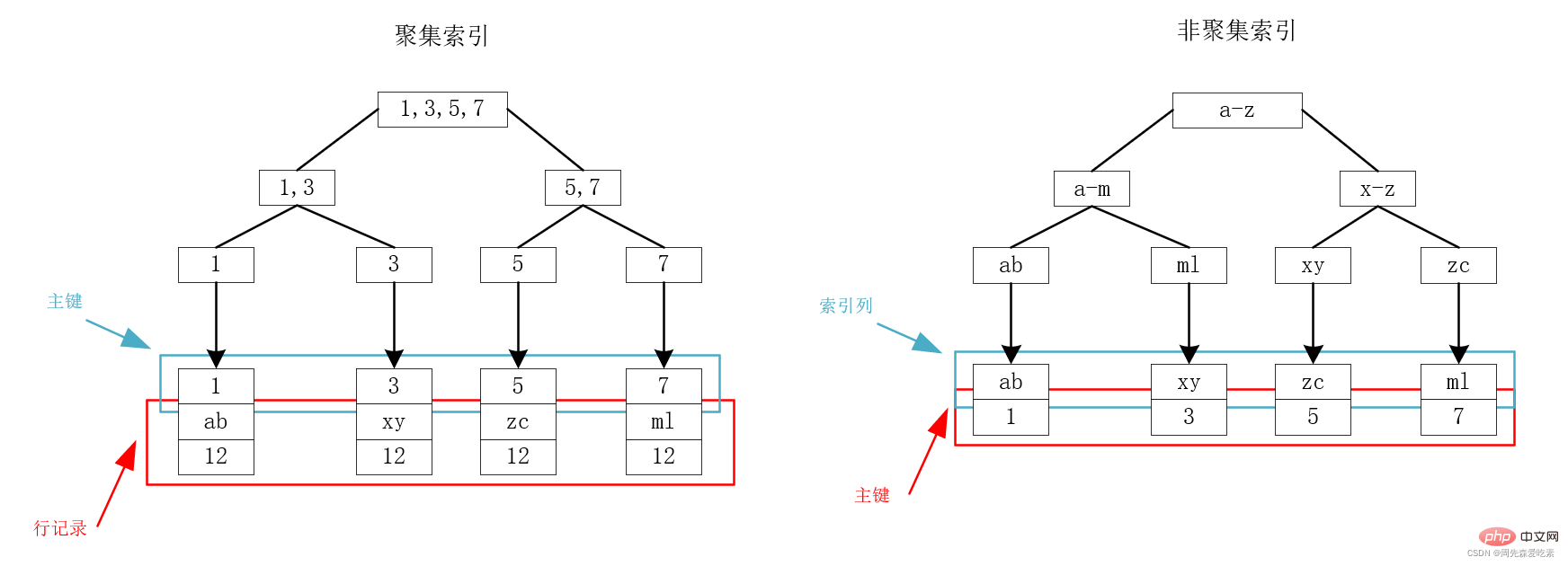
, jadi apabila medan yang kami tanyakan dalam b, c dan d, kami tidak akan kembali ke jadual pokok sekali.
bermaksud bahawa dalam indeks bersama, indeks lajur paling kiri diberi keutamaan. Perkara yang sama berlaku untuk indeks bersama pada berbilang medan. Sebagai contoh, indeks(a,b,c) indeks bersama adalah bersamaan dengan mencipta indeks lajur tunggal, (a,b) indeks bersama dan (a,b,c) indeks bersama. (b,c,d)
EXPLAIN SELECT * FROM test WHERE b = 1;

EXPLAIN SELECT * FROM test WHERE b = 1 and c = 2 and d = 3;

接着,我们尝试一条不符合最左原则的查询,它也如图预期一样,走了全表扫描。
EXPLAIN SELECT * FROM test WHERE d = 3;

我们先来看下面两个语句,他们的输出如下。
EXPLAIN SELECT b, c from test WHERE b = 1 and c = 1; EXPLAIN SELECT b, d from test WHERE d = 1;
id|select_type|table|partitions|type|possible_keys|key |key_len|ref |rows|filtered|Extra | --+-----------+-----+----------+----+-------------+-------+-------+-----------+----+--------+-----------+ 1|SIMPLE |test | |ref |idx_bcd |idx_bcd|10 |const,const| 1| 100.0|Using index| i d|select_type|table|partitions|type |possible_keys|key |key_len|ref|rows|filtered|Extra | --+-----------+-----+----------+-----+-------------+-------+-------+---+----+--------+------------------------+ 1|SIMPLE |test | |index|idx_bcd |idx_bcd|15 | | 3| 33.33|Using where; Using index|
显然第一条语句是符合最左匹配的,因此type为ref,但是第二条并不符合最左匹配,但是也不是全表扫描,这是因为此时这表示扫描整个索引树。
具体来看,index 代表的是会对整个索引树进行扫描,如例子中的,列 d,就会导致扫描整个索引树。ref 代表 mysql 会根据特定的算法查找索引,这样的效率比 index 全扫描要高一些。但是,它对索引结构有一定的要求,索引字段必须是有序的。而联合索引就符合这样的要求,联合索引内部就是有序的,你可以理解为order by b,c,d这种排序规则,先根据字段b排序,再根据字段c排序,以此类推。这也解释了,为什么需要遵守最左匹配原则,当最左列有序才能保证右边的索引列有序。
因此,我们总结最后的原则为,若符合最左覆盖原则,则走ref这种索引;若不符合最左匹配原则,但是符合覆盖索引(index),就可以扫描整个索引树,从而找到覆盖索引对应的列,避免回表;若不符合最左匹配原则,也不符合覆盖索引(如本例的select *),则需要扫描整个索引树,并且回表查询行记录,此时,查询优化器认为这样两次查找索引树,还不如全表扫描来得快(因为联合索引此时不符合最左匹配原则,要不普通索引查询慢得多),因此,此时会走全表扫描。
减少开销。建一个联合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
覆盖索引。对联合索引(col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那么MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
效率高。索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select from table where col1=1 and col2=2 and col3=3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W10%=100w条数据,然后再回表从100w条数据中找到符合col2=2 and col3= 3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w10% 10% *10%=1w,效率提升可想而知!
推荐学习:mysql视频教程
Atas ialah kandungan terperinci Contoh terperinci prinsip padanan paling kiri indeks MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!






























![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



