


Artikel ini membawakan anda pengetahuan yang berkaitan tentang java terutamanya penerangan terperinci tentang aplikasi rekursif java penganalisis boleh merujuknya ia membantu semua orang.

Pembelajaran yang disyorkan: "tutorial video java"
Memandangkan tiada sedia dibuat alat, kemudian Tulis sendiri
Memandangkan kami terutamanya menggunakan PyCharm untuk pembangunan, kebetulan jetbrains turut menyediakan SDK untuk membangunkan pemalam, jadi tidak perlu memikirkan tahap UI.
Proses penggunaan adalah sangat mudah Anda hanya perlu mengimport pernyataan DDL untuk menjana kod Python yang diperlukan oleh Model.
Sebagai contoh, import DDL berikut:
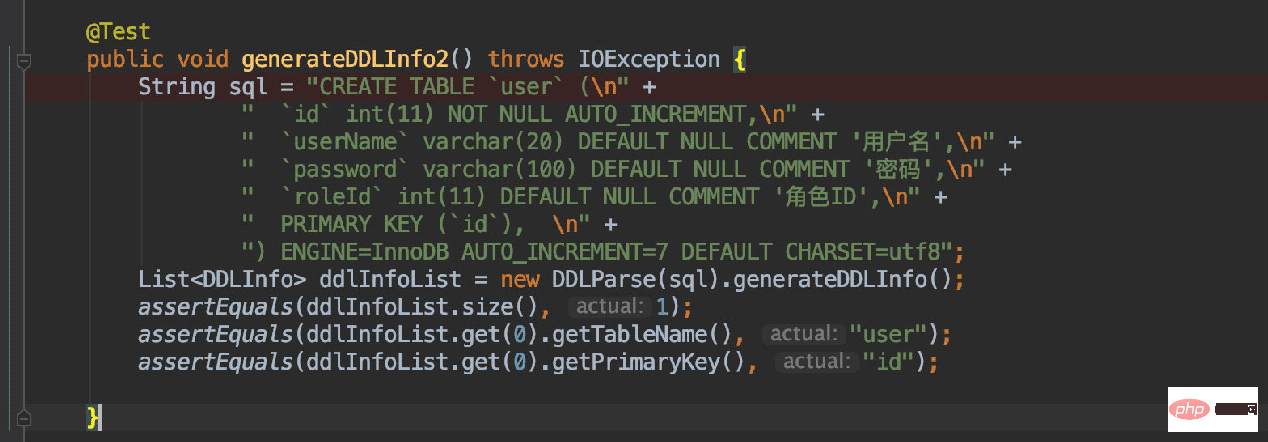
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码', `roleId` int(11) DEFAULT NULL COMMENT '角色ID', PRIMARY KEY (`id`), ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8
dan kod Python yang sepadan akan dihasilkan:
class User(db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
userName = db.Column(db.String) # 用户名
password = db.Column(db.String) # 密码
roleId = db.Column(db.Integer) # 角色IDBerhati-hati bandingkan fail sumber dan Kod sasaran akan mencari corak dengan mudah Ia tidak lebih daripada menghuraikan nama jadual, medan dan atribut medan (sama ada kunci utama, jenis, panjang), dan akhirnya menukarnya ke dalam templat. diperlukan oleh Python.
Sebelum saya mula, saya fikir ia adalah sangat mudah, tetapi sebenarnya, selepas saya mula, saya mendapati bahawa terdapat masalah berikut:
Ringkasnya, cara mengenal pasti maklumat utama dalam rentetan melalui satu siri peraturan juga adalah perkara yang dilakukan oleh Pelayan MySQL.
Sebelum kita mula menghuraikan DDL sebenarnya, mari kita lihat cara menghuraikan skrip mudah seterusnya:
x = 20
Menurut apa yang biasanya kita bangunkan Pengalaman, pernyataan ini dibahagikan kepada bahagian berikut:
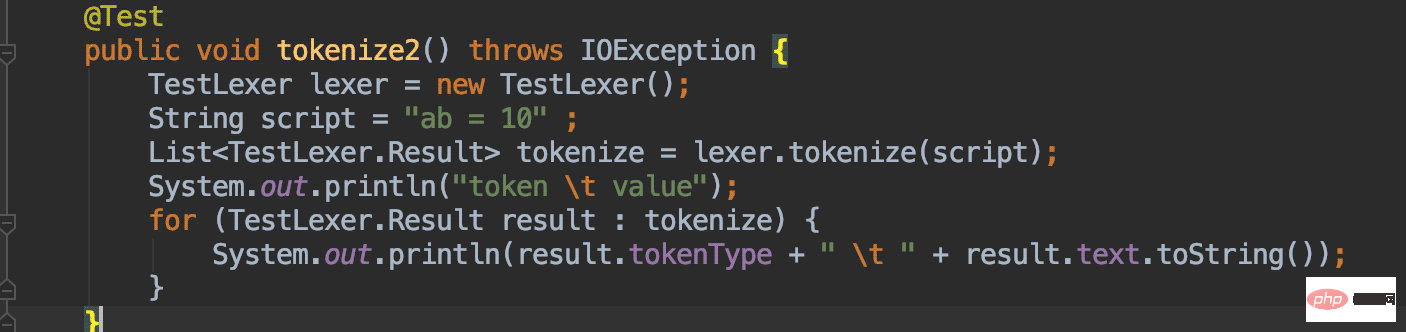
x mewakili pembolehubah = mewakili simbol tugasan 20 mewakili hasil tugasanJadi hasil penghuraian kami untuk skrip ini hendaklah:
VAR x
GE =
VAL 100
Proses penghuraian ini dipanggil "penghuraian leksikal" dalam prinsip kompilasi Anda mungkin sakit kepala apabila mendengar perkataan prinsip kompilasi (saya juga untuk skrip tadi, kita boleh write a very simple Penghurai leksikal menghasilkan keputusan seperti ini.
Sebelum bermula, mari kita fikirkan sebentar anda dapat melihat bahawa dalam hasil di atas, VAR mewakili pembolehubah dan GE mewakili simbol tugasan "=". , VAL Menunjukkan hasil tugasan Sekarang anda perlu fokus untuk mengingati tiga keadaan ini.
Apabila membaca dan menghuraikan aksara mengikut turutan, atur cara beralih ke sana ke mari antara keadaan ini, seperti yang ditunjukkan di bawah:
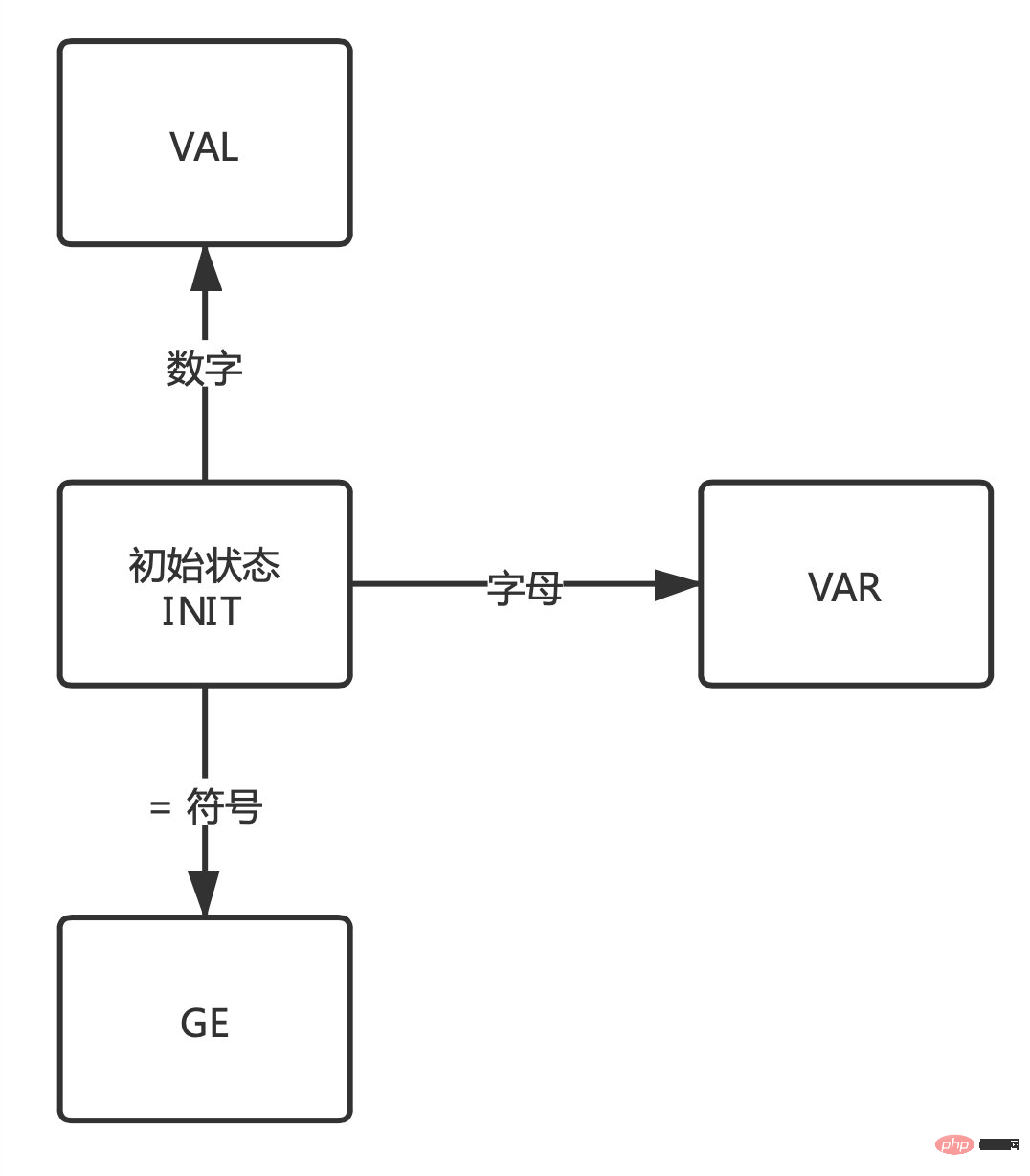
VAR keadaan apabila aksara ialah huruf. GE apabila aksara ialah simbol "=". 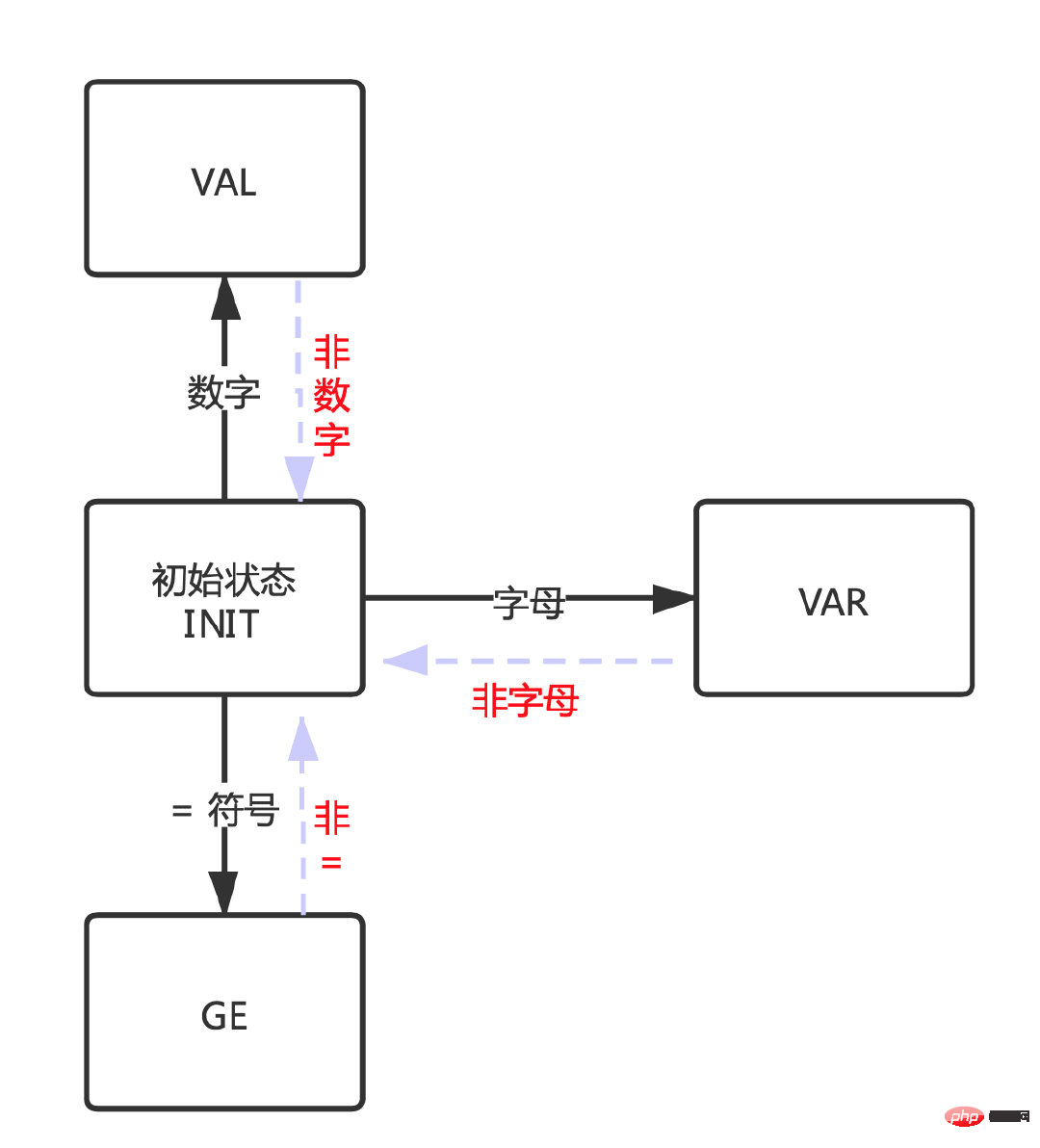
Begitu juga, apabila keadaan ini tidak berpuas hati, ia akan kembali ke keadaan awal untuk mengesahkan keadaan baharu semula.
Hanya melihat gambar itu agak abstrak, mari kita lihat terus pada kod teras:
public class Result{
public TokenType tokenType ;
public StringBuilder text = new StringBuilder();
} mula-mula mentakrifkan kelas hasil untuk mengumpul hasil analisis akhir TokenType sepadan dengan yang dalam gambar Ketiga-tiga negeri ini hanya diwakili oleh nilai penghitungan.
public enum TokenType {
INIT,
VAR,
GE,
VAL
}Pertama sepadan dengan gambar pertama: keadaan permulaan.
Anda perlu mentakrifkan TokenType untuk aksara yang sedang dihuraikan:
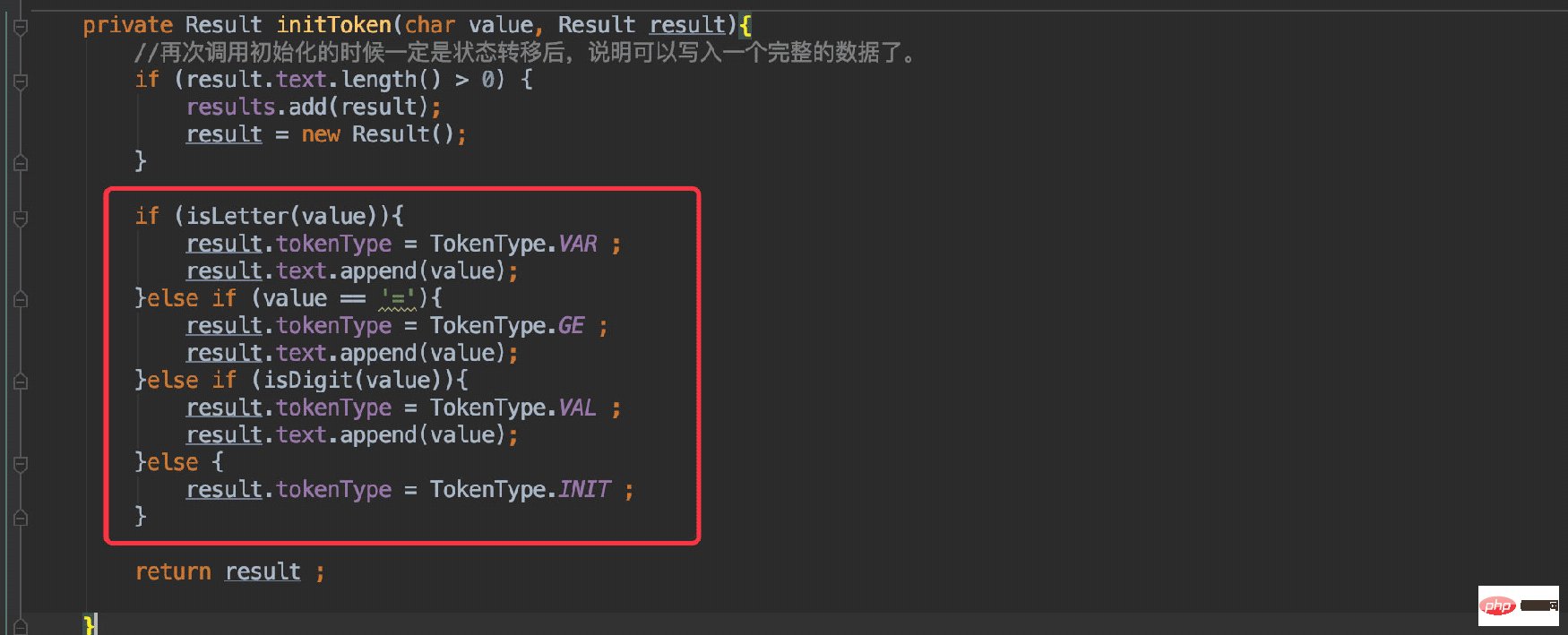
adalah konsisten dengan proses yang diterangkan dalam rajah dengan memberi negeri.
Kemudian sepadan dengan gambar kedua: peralihan antara keadaan.
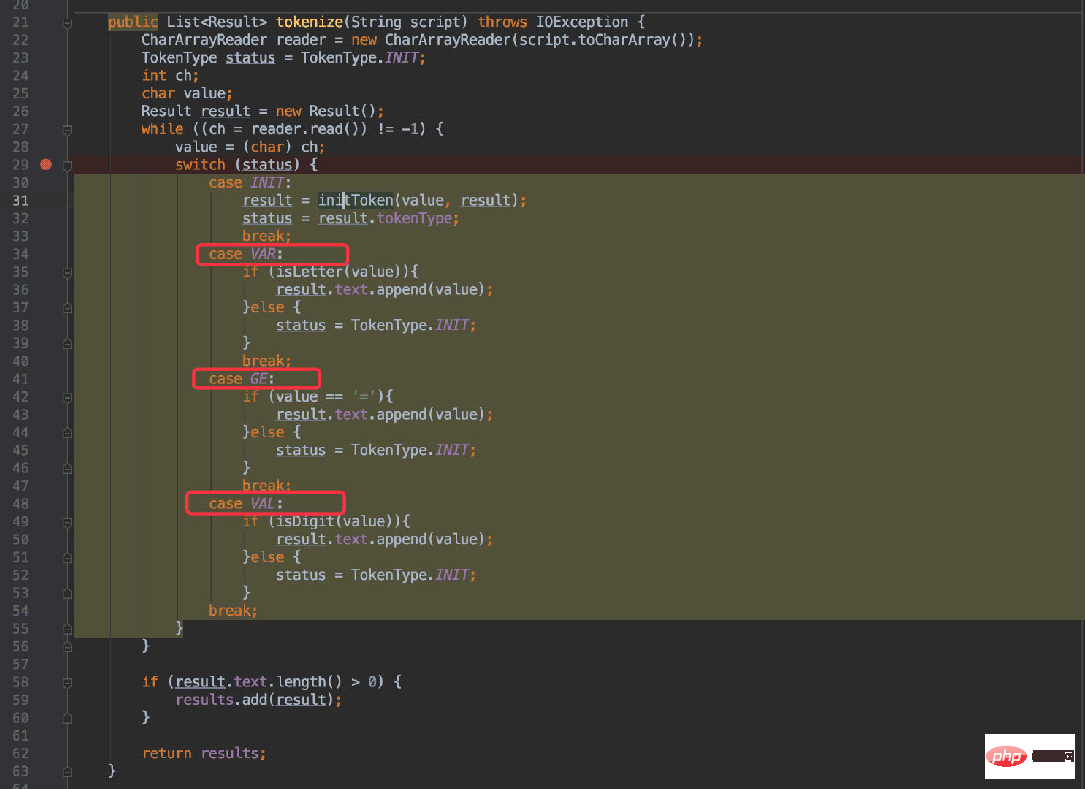
akan memasuki case berbeza mengikut keadaan berbeza dan menilai sama ada ia perlu melompat ke negeri lain dalam case yang berbeza (selepas memasuki keadaan INIT, ia akan menjana semula keadaan).
Contohnya: x = 20:
mula-mula akan memasuki keadaan VAR, dan kemudian aksara seterusnya ialah ruang Sememangnya, ia akan memasuki semula keadaan awal dalam baris 38 , menyebabkan watak seterusnya ditentukan semula. Watak = memasuki keadaan GE.
Apabila skrip ab = 30:
Watak pertama ialah a dan ia juga memasuki keadaan VAR, dan aksara kedua ialah b, yang masih merupakan huruf, jadi memasuki baris 36, keadaan tidak akan berubah Pada masa yang sama, tambahkan aksara b;
Adalah sia-sia untuk mengatakan lebih banyak saya cadangkan anda menjalankan ujian tunggal sendiri dan anda akan faham:
简单的解析完成后来看看DDL这样的脚本应当如何解析:
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码', `roleId` int(11) DEFAULT NULL COMMENT '角色ID', PRIMARY KEY (`id`), ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8
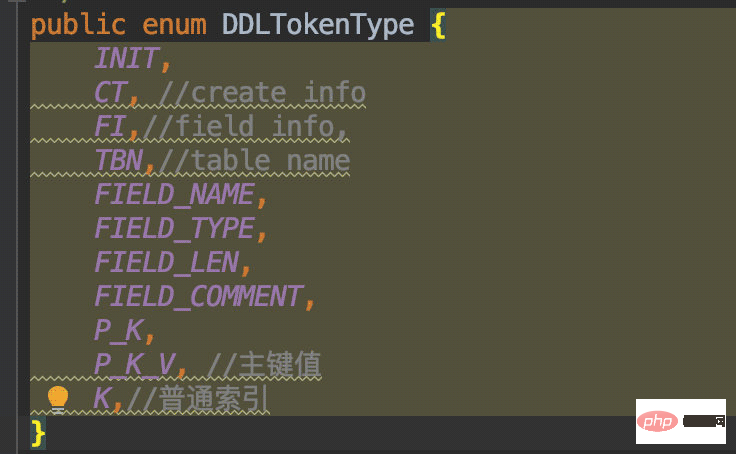
原理类似,首先还是要看出规律(也就是语法):
CREATE TABLE开头。)结尾。根据我们需要解析的数据种类,我这里定义了这个枚举:
然后在初始化类型时进行判断赋值:
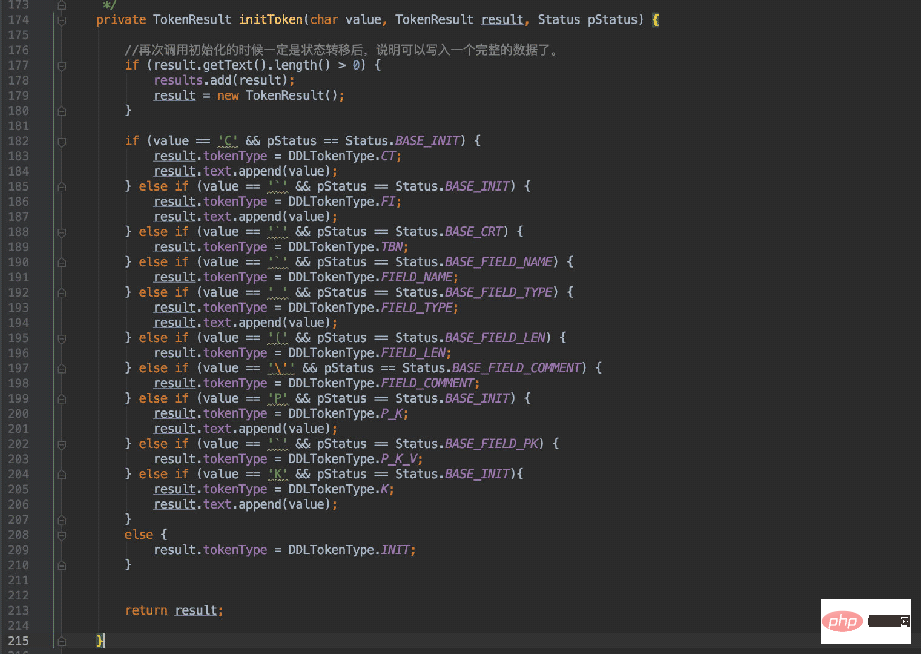
由于需要解析的数据不少,所以这里的判断条件自然也就多了。
针对于DDL的语法规则,我们这里还有需要有特殊处理的地方;比如解析具体字段信息时如何关联起来?
举个例子:
`userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码',
这里我们解析出来的数据得有一个映射关系:
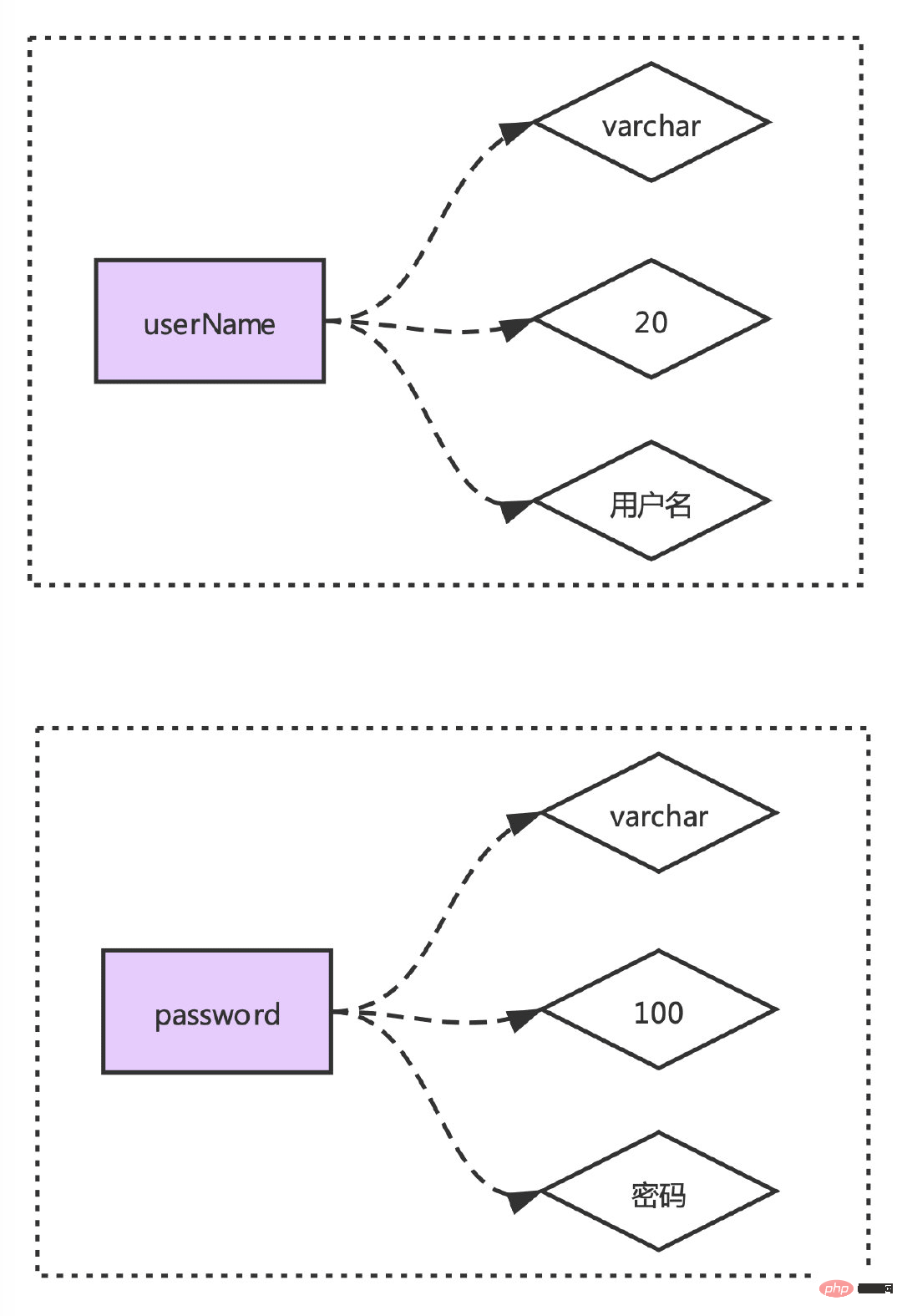
所以我们只能一个字段的全部信息解析完成并且关联好之后才能解析下一个字段。
于是这里我采用了递归的方式进行解析(不一定是最好的,欢迎大家提出更优的方案)。
} else if (value == '`' && pStatus == Status.BASE_INIT) {
result.tokenType = DDLTokenType.FI;
result.text.append(value);
}当当前字符为 ”`“ 符号时,将状态置为 “FI”(FieldInfo),同时当解析到为 “,” 符号时便进入递归处理。
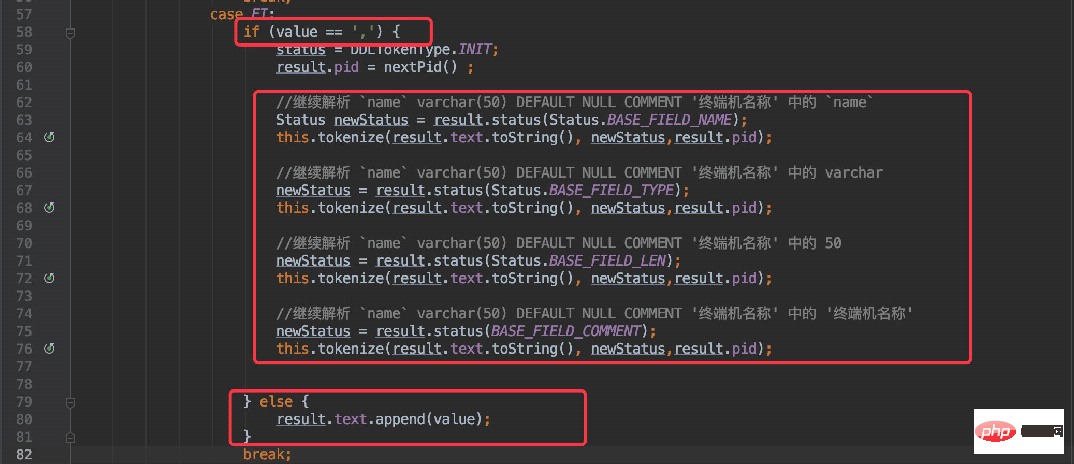
可以理解为将这一段字符串单独提取出来处理:
`userName` varchar(20) DEFAULT NULL COMMENT '用户名',
接着再将这段字符递归调用当前方法再次进行解析,这时便按照字段名称、类型、长度、注释的规则解析即可。
同时既然存在递归,还需要将子递归的数据关联起来,所以我在返回结果中新增了一个pid的字段,这个也容易理解。
默认值为 0,一旦递归后便自增 +1,保证每次递归的数据都是唯一的。
用同样的方法在解析主键时也是先将整个字符串提取出来:
PRIMARY KEY (`id`)
只不过是 “P” 打头 “)” 结尾。
} else if (value == 'P' && pStatus == Status.BASE_INIT) {
result.tokenType = DDLTokenType.P_K;
result.text.append(value);
}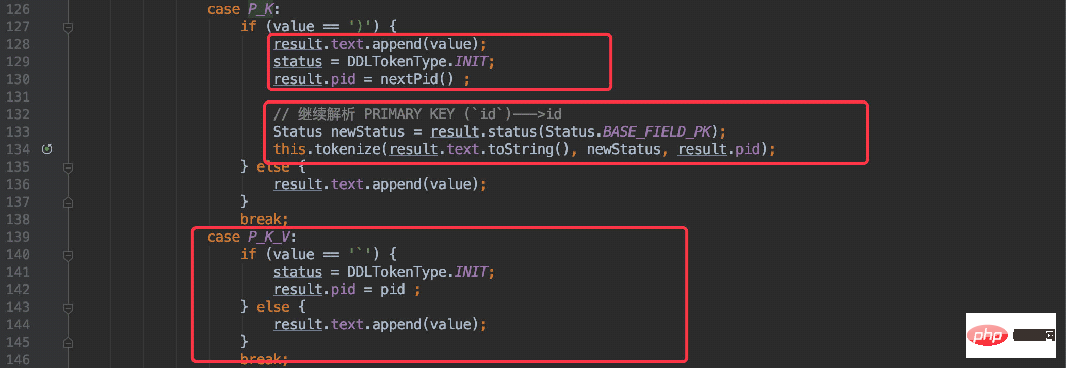
也是将整段字符串递归解析,再递归的过程中进行状态切换P_K ---> P_K_V最终获取到主键。
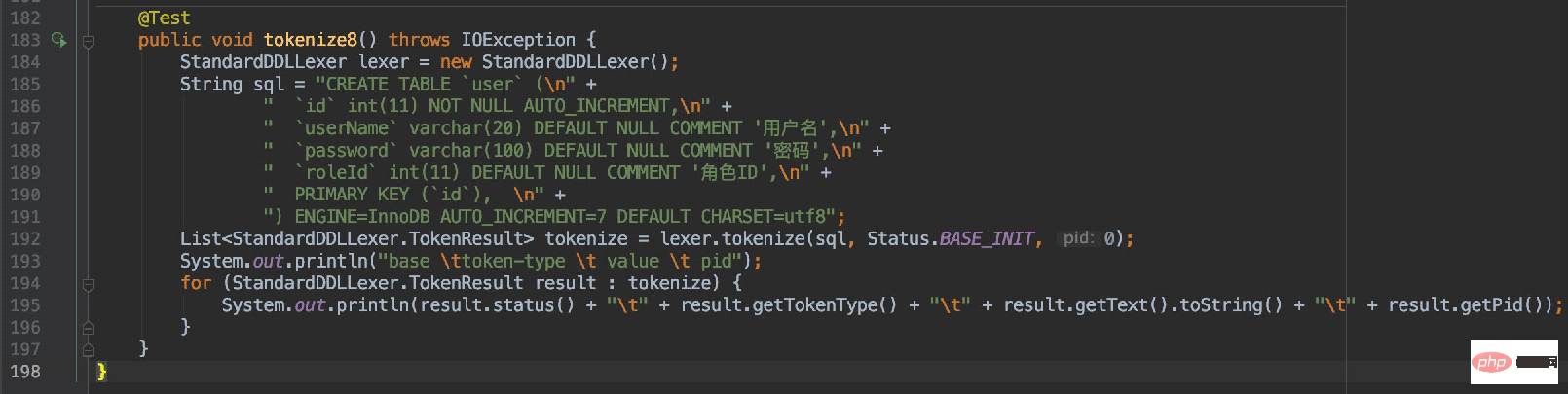
所以通过对刚才那段DDL解析得到的结果如下:
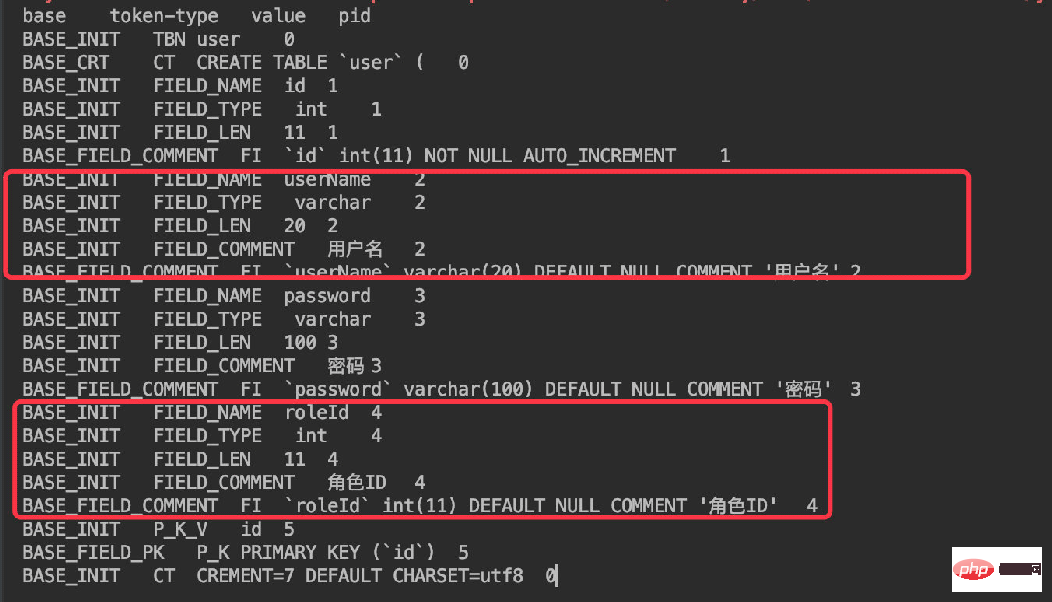
这样每个字段也通过了pid进行了区分关联。
所以现在只需要对这个词法解析器进行封装,便可以提供一个简单的API来获取表中的数据了。
推荐学习:《java视频教程》
Atas ialah kandungan terperinci Analisis terperinci aplikasi rekursif DDL penganalisis leksikal java. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!









![Tutorial teras JavaScript [operasi DOM BOM yang mesti diketahui JS]](https://img.php.cn/upload/course/000/000/041/61c56ae28d02a390.jpg)
![Video pengenalan TypeScript [boleh difahami walaupun tanpa mempelajari JavaScript]](https://img.php.cn/upload/course/000/000/068/6242c0fc4be39373.png)







![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



