


Artikel ini membawa anda pengetahuan yang berkaitan tentang mysql terutamanya isu berkaitan pengindeksan, termasuk kandungan yang berkaitan tentang prinsip pengoptimuman indeks. Saya harap Bermanfaat kepada semua orang.

Pembelajaran yang disyorkan: tutorial video mysql
Kata Pengantar: Saya percaya semua orang tahu bahawa indeks boleh bertambah baik dengan ketara Kelajuan perolehan MySQL, tetapi apabila anda benar-benar menulis SQL dalam kerja harian anda, adakah anda benar-benar mempertimbangkan bagaimana SQL ini boleh menggunakan indeks untuk meningkatkan kecekapan pelaksanaan? Blog ini memperkenalkan 20 prinsip pengoptimuman indeks secara terperinci Selagi anda boleh menggunakannya pada bila-bila masa dalam kerja anda, saya percaya bahawa SQL yang anda tulis boleh mencapai indeks dan sangat cekap.
Indeks boleh meningkatkan kelajuan perolehan semula MySQL. Indeks adalah seperti jadual kandungan dalam buku Untuk membolehkan kita mencari data yang kita inginkan dengan lebih cepat, berikut adalah pengenalan kepada indeks yang biasa digunakan dalam MySQL.
(1) Indeks biasa
<.>Ini adalah indeks yang paling asas, ia tidak mempunyai sekatan.Bagaimana untuk menggunakan?
//方式1 ALTER TABLE table_name ADD INDEX index_name ( column )
//方式2 CREATE INDEX index_name ON table_name (column_name)
(2 ) Indeks unik
adalah serupa dengan indeks biasa, kecuali nilai lajur indeks mestilah unik, tetapi nilai nol dibenarkan. Jika ia adalah indeks komposit, gabungan nilai lajur mestilah satu.Bagaimana untuk menggunakan?
//方式1 ALTER TABLE table_name ADD UNIQUE [indexName] (column)
//方式2 CREATE UNIQUE INDEX index_name ON table_name (column_name)
( 3) Indeks kunci utama
Ia ialah indeks unik khas yang tidak membenarkan nilai nol. Secara amnya, jika kunci utama ditentukan semasa membuat jadual, indeks kunci utama akan dicipta secara automatik tidak boleh digunakan untuk mencipta indeks kunci utama.Bagaimana untuk menggunakan?
//方式1 ALTER TABLE table_name ADD PRIMARY KEY ( column )
(1) Indeks berkelompok
Indeks berkelompok, juga dipanggil indeks berkelompok, semua data wujud dalam indeks berkelompok, dan nod daun secara langsung sepadan dengan data, dari peringkat pertengahan Baris indeks halaman indeks secara langsung sepadan dengan halaman data. Kunci utama dalam enjin storan InnoDB mencipta indeks berkelompok secara lalai, dan hanya satu indeks berkelompok boleh dibuat untuk setiap jadual. Susunan indeks rekod adalah sama dengan susunan fizikal, yang lebih sesuai untuk antara dan dan susunan mengikut operasi. InnoDBNod daun indeks berkelompok menyimpan rekod baris Oleh itu, InnoDB mesti mempunyai dan hanya satu indeks berkelompok:
(1) Jika jadual mentakrifkan PK, Maka. PK ialah indeks berkelompok; (2) Jika jadual tidak mentakrifkan PK, lajur pertama bukan NULL ialah indeks berkelompok; (3) Jika tidak, InnoDB akan mencipta tersembunyi row-id digunakan sebagai indeks berkelompok Suara Suara: Jadi pertanyaan PK sangat pantas dan rekod baris terletak terus.Sebagai contoh, jadual adalah seperti kamus Xinhua yang kami gunakan sebelum ini, indeks berkelompok adalah seperti direktori pinyin, dan nombor halaman di mana setiap perkataan disimpan ialah alamat fizikal kami data. Jika kita ingin menanyakan perkataan "Wow", kita hanya perlu menanyakan nombor halaman yang sepadan dengan perkataan "Wow" dalam katalog Pinyin Kamus Xinhua, dan kita boleh menanyakan lokasi perkataan yang sepadan "Wow", dan perkataan A-Z yang sepadan dengan katalog Pinyin Susunannya adalah sama dengan susunan A-Z bagi aksara yang sebenarnya disimpan dalam Kamus Xinhua Jika kita mempunyai aksara Cina baharu, dan aksara pertama pada permulaan Pinyin ialah B, maka apabila ia dimasukkan, ia mesti disisipkan selepas aksara A mengikut susunan direktori Pinyin .
(2) Indeks tidak berkelompok
Indeks tidak berkelompok, juga dipanggil indeks tidak berkelompok dan indeks tambahan, semua direktori data dan indeks disimpan secara berasingan nod tidak menyimpan keseluruhan baris data tertentu (nod daun tidak menghala terus ke halaman data), tetapi menyimpan nilai kunci utama baris ini.
Susunan indeks rekod tiada kaitan dengan susunan fizikal. Setiap jadual boleh mempunyai berbilang indeks bukan berkelompok, yang memerlukan lebih banyak cakera dan memori Berbilang indeks akan menjejaskan kelajuan sisipan dan kemas kini.Suara: Indeks tidak berkelompok perlu disoal semula ke jadual, mula-mula cari nilai kunci utama, dan kemudian cari rekod baris Kerana pepohon indeks perlu diimbas dua kali, prestasinya adalah lebih rendah daripada mengimbas pokok indeks sekali.
Malah, mengikut definisi, indeks selain daripada indeks berkelompok ialah indeks bukan berkelompok, tetapi orang ramai ingin membahagikan indeks bukan berkelompok kepada indeks biasa, indeks unik dan indeks teks penuh. Jika kita perlu membandingkan indeks tidak berkelompok dengan sesuatu dalam kehidupan sebenar, maka indeks tidak berkelompok adalah seperti kamus radikal Kamus Xinhua, dan susunan strukturnya tidak semestinya konsisten dengan susunan penyimpanan sebenar.
联合索引又叫复合索引,对表上的多个字段同时建立的索引(有顺序,ABC,ACB是完全不同的两种联合索引。)以联合索引(a,b,c)为例,建立这样的索引相当于建立了索引a、ab、abc三个索引。
遵循最左前缀原则(必须带着最左边的列做条件才能命中索引),且从出现范围开始索引失效;
当遇到范围查询(>、<、between、like)就会停止匹配。也就是:
#这样a,b可以用到(a,b,c),c不可以 select * from t where a=1 and b>1 and c =1;</p> <p>这条语句只有 a,b 会用到索引,c 都不能用到索引。</p> <pre class="brush:php;toolbar:false">create index mix_ind on 表名 (id,name,email); select * from 表名 where id = 123; # 命中索引 select * from 表名 where id = 123 and name = 'pamela'; # 命中索引 select * from 表名 where id > 123 and name = 'pamela'; # id命中,name不命中索引,因为出现范围 select * from 表名 where id = 123 and email = 'pamela@123.com'; # 命中索引 select * from 表名 where email = 'pamela@123.com'; # 不命中索引,因为条件中没有id select * from 表名 where name='pamela' and email = 'pamela@123.com'; # 不命中
A:select * from student where age = 16 and name = '小张' B:select * from student where name = '小张' and sex = '男' C:select * from student where name = '小张' and sex = '男' and age = 18 D:select * from student where age > 20 and name = '小张' E:select * from student where age != 15 and name = '小张'
A遵从最左匹配原则,age是在最左边,所以A走索引;
B直接从name开始,没有遵从最左匹配原则,所以不走索引;
C虽然从name开始,但是有索引最左边的age,mysql内部会自动转成where age = '18' and name = '小张' and sex = '男' 这种,所以还是遵从最左匹配原则;
D这个是因为age>20是范围,范围字段会结束索引对范围后面索引字段的使用,所以只有走了age这个索引;
E这个虽然遵循最左匹配原则,但是不走索引,因为!= 不走索引;
question1:如何给下列sql语句加上联合索引?
select * from test where a = 1 and b = 1 and c = 1;
answer:
咱们一看,直接加索引(a,b,c)就可以了,其实不然,也不能说这个答案不对,只能说这个答案不够完整。因为mysql在执行的时候会经历优化器过程,所以会把sql语句自动优化成符合索引的顺序,所以索引(a,b,c) (a,c,b) 或者是(c,b,a)都是可以的,那我们究竟如何确定索引呢?这个就得根据实际情况来了,比如a字段是表示性别的,只有0,1和2三个值来表示 未知,男,女三种性别,那么把a字段放在联合索引的最后会比较合适,反正哪个字段的内容重复率越高,就把哪个字段往联合索引的后面放。
question2:如何给下列sql语句加上索引?
SELECT * FROM table WHERE a > 1 and b = 2;
answer:
如果咱们建立索引(a,b),那么a>1是可以走到索引的,但是b=2就没法走到索引了。但是如果咱们建立索引(b,a),那么sql语句会被自动优化成 where b=2 and a> 1,这样a和b都能走到索引,所以建立索引(b,a)比较合适
使用聚集索引(主键或第一个唯一索引)就不会回表,非聚集索引就会回表。当select的数据列被所建索引覆盖时不需要回表,可以直接取得数据。
覆盖索引是select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖。覆盖索引在查询过程中不需要回表。只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表速度更快。
覆盖索引其核心就是只从辅助索引要数据。那么, 普通索引(单字段)和联合索引,以及唯一索引都能实现覆盖索引的作用。explain的输出结果Extra字段为Using index时,能够触发索引覆盖。
create index ind_id on 表名(id); # 对id字段创建了索引 select id from 表名 where id > 100; # 覆盖索引:在查找一条数据的时候,命中索引,不需要再回表 select max(id) from 表名 where id > 100; # 覆盖索引:在查找一条数据的时候,命中索引,不需要再回表 select count(id) from 表名 where id > 100; # 覆盖索引:在查找一条数据的时候,命中索引,不需要再回表 select name from 表名 where id > 100; # 相对慢
(1) 如何实现索引覆盖?
常见的方法是:将被查询的字段,建立到联合索引里去。
select id,name from user where name='shenjian';

能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
Extra:Using index。
(2)哪些场景可以利用索引覆盖来优化SQL?
场景1:全表count查询优化
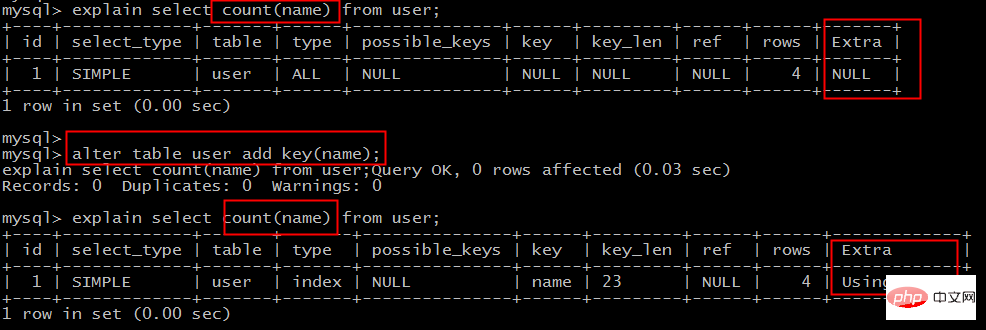
原表为:user(PK id, name, sex);不能利用索引覆盖
select count(name) from user;
添加索引,就能够利用索引覆盖提效
alter table user add key(name);
场景2:列查询回表优化
这个例子不再赘述,将单列索引(name)升级为联合索引(name, sex),即可避免回表。
场景3:分页查询
将单列索引(name)升级为联合索引(name, sex),也可以避免回表。
前缀索引说白了就是对文本的前几个字符(具体是几个字符在建立索引时指定)建立索引,这样建立起来的索引更小,所以查询更快。
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
MySQL 前缀索引能有效减小索引文件的大小,提高索引的速度。但是前缀索引也有它的坏处:MySQL 不能在 ORDER BY 或 GROUP BY 中使用前缀索引,也不能把它们用作覆盖索引(Covering Index)。
深入理解 index merge 是使用索引进行优化的重要基础之一。理解了 index merge 技术,我们才知道应该如何在表上建立索引。
为什么会有index merge?
我们的 where 中可能有多个条件(或者join)涉及到多个字段,它们之间进行 AND 或者 OR,那么此时就有可能会使用到 index merge 技术。index merge 技术如果简单的说,其实就是:对多个索引分别进行条件扫描,然后将它们各自的结果进行合并(intersect/union)。
MySQL5.0之前,一个表一次只能使用一个索引,无法同时使用多个索引分别进行条件扫描。但是从5.1开始,引入了 index merge 优化技术,对同一个表可以使用多个索引分别进行条件扫描。
索引合并是指分别创建的两个索引,在某一次查询中临时合并成一条索引。
# 索引合并 create index ind_id on 表名(id); create index ind_email on 表名(email); select * from 表名 where id=100 or email = 'pamela@123.com' # 索引合并,临时把两个索引ind_id和ind_email合并成一个索引
(1)索引下推简介
索引条件下推(Index Condition Pushdown),简称ICP。MySQL5.6新添加,用于优化数据的查询。 通过索引下推对于非主键索引进行优化,可有效减少回表次数,从而提高效率。
如果没有索引下推优化(或称ICP优化),当进行索引查询时,首先根据索引来查找记录,然后再根据where条件来过滤记录;在支持ICP优化后,MySQL会在取出索引的同时,判断是否可以进行where条件过滤再进行索引查询,也就是说提前执行where的部分过滤操作,在某些场景下,可以大大减少回表次数,从而提升整体性能。
当你不使用ICP,通过使用非主键索引(普通索引or二级索引)进行查询,存储引擎通过索引检索数据,然后返回给MySQL服务器,服务器再判断是否符合条件。
使用ICP,当存在索引的列做为判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器。
(2)适用场景
当需要整表扫描,e.g.:range,ref,eq_ref....
适用InnoDB引擎和MyISAM引擎查询(5.6版本不适用分区查询,5.7版本可以用于分区表查询)。
InnoDB引擎仅仅适用二级索引。(原因InnoDB聚簇索引将整行数据读到InnoDB缓冲区)。
子查询条件不能下推。触发条件不能下推,调用存储过程条件不能下推。
查询的条件字段尽量用索引字段
and条件相连,有一列有索引就会命中索引,加快查询速度;or条件相连,所有列都有索引才能命中索引,加快查询速度;
create index mix_ind on 表名 (id); select * from 表名 where id = 123 and name = 'pamela'; # 有一列有索引,速度快 select * from 表名 where id = 123 or name = 'pamela'; # 不是所有列都有索引,速度慢
select * from doc where title like '%XX'; --不能使用索引 select * from doc where title like 'XX%'; --非前导模糊查询,可以使用索引
因为页面搜索严禁左模糊或者全模糊,如果需要可以使用搜索引擎来解决。
union能够命中索引,并且MySQL 耗费的 CPU 最少。
select * from doc where status=1 union all select * from doc where status=2;
in能够命中索引,查询优化耗费的 CPU 比 union all 多,但可以忽略不计,一般情况下建议使用 in。
select * from doc where status in (1, 2);
or 新版的 MySQL(MySQL5.0后) 索引合并能够命中索引,查询优化耗费的 CPU 比 in多,不建议频繁用or。
select * from doc where status = 1 or status = 2
补充:有些地方说在where条件中使用or,索引会失效,造成全表扫描,这是个误区:
要求where子句使用的所有字段,都必须建立索引;
如果数据量太少,mysql制定执行计划时发现全表扫描比索引查找更快,所以会不使用索引;
确保mysql版本5.0以上,且查询优化器开启了index_merge_union=on, 也就是变量optimizer_switch里存在index_merge_union且为on。
负向条件有:!=、<>、not in、not exists、not like 等。
例如下面SQL语句:
select * from doc where status != 1 and status != 2;
可以优化为 in 查询:
select * from doc where status in (0,3,4);
如果在(a,b,c)三个字段上建立联合索引,那么他会自动建立 a| (a,b) | (a,b,c)组索引。联合索引遵循最左前缀原则(必须带着最左边的列做条件才能命中索引),且从出现范围开始索引失效;
create index mix_ind on 表名 (id,name,email); select * from 表名 where id = 123; # 命中索引 select * from 表名 where id > 123; # 不命中索引,因为出现范围 select * from 表名 where id = 123 and name = 'pamela'; # 命中索引 select * from 表名 where id > 123 and name = 'pamela'; # 不命中索引,因为出现范围 select * from 表名 where id = 123 and email = 'pamela@123.com'; # 命中索引 select * from 表名 where email = 'pamela@123.com'; # 不命中索引,因为条件中没有id select * from 表名 where name='pamela' and email = 'pamela@123.com'; # 不命中索引,因为条件中没有id
登录业务需求,SQL语句如下:
select uid, login_time from user where login_name=? andpasswd=?
可以建立(login_name, passwd)的联合索引。因为业务上几乎没有passwd 的单条件查询需求,而有很多login_name 的单条件查询需求,所以可以建立(login_name, passwd)的联合索引,而不是(passwd, login_name)。
范围条件有:<、<=、>、>=、between等。
索引最多用于一个范围列,如果查询条件中有两个范围列则无法全用到索引。
假如有联合索引 (empno、title、fromdate),那么下面的 SQL 中 emp_no 可以用到索引,而title 和 from_date 则使用不到索引。
select * from employees.titles where emp_no < 10010' and title='Senior Engineer'and from_date between '1986-01-01' and '1986-12-31'
例如下面的 SQL 语句,即使 date 上建立了索引,也会全表扫描:
select * from doc where YEAR(create_time) <= '2016';
可优化为值计算,如下:
select * from doc where create_time <= '2016-01-01';
比如下面的 SQL 语句:
select * from order where date < = CURDATE();
可以优化为:
select * from order where date < = '2018-01-2412:00:00';
字符串类型不加单引号会导致索引失效,因为mysql会自己做类型转换,相当于在索引列上进行了操作。
如果 phone 字段是 varchar 类型,则下面的 SQL 不能命中索引。
select * from user where phone=13800001234
可以优化为:
select * from user where phone='13800001234';
更新会变更 B+ 树,更新频繁的字段建立索引会大大降低数据库性能。
“性别”这种区分度不大的属性,建立索引是没有什么意义的,不能有效过滤数据,性能与全表扫描类似。
一般区分度在80%以上的时候就可以建立索引,区分度可以使用 count(distinct(列名))/count(*) 来计算。
覆盖索引:查询的列和所建立的索引的列个数相同,字段相同。
被查询的列,数据能从索引中取得,而不用通过行定位符 row-locator 再到 row 上获取,即“被查询列要被所建的索引覆盖”,这能够加速查询速度。
例如登录业务需求,SQL语句如下。
select uid, login_time from user where login_name=? and passwd=?
可以建立(login_name, passwd, login_time)的联合索引,由于 login_time 已经建立在索引中了,被查询的 uid 和 login_time 就不用去 row 上获取数据了,从而加速查询。
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时,尽量使用not null 约束以及默认值。
order by 最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现file_sort 的情况,影响查询性能。
例如对于语句 where a=? and b=? order by c,可以建立联合索引(a,b,c)。
如果索引中有范围查找,那么索引有序性无法利用,如 WHERE a>10 ORDER BY b;,索引(a,b)无法排序。
对列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果该列在前10个或20个字符内,可以做到既使得前缀索引的区分度接近全列索引,那么就不要对整个列进行索引。因为短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作,减少索引文件的维护开销。可以使用count(distinct leftIndex(列名, 索引长度))/count(*) 来计算前缀索引的区分度。
但缺点是不能用于 ORDER BY 和 GROUP BY 操作,也不能用于覆盖索引。
不过很多时候没必要对全字段建立索引,根据实际文本区分度决定索引长度即可。
MySQL 并不是跳过 offset 行,而是取 offset+N 行,然后返回放弃前 offset 行,返回 N 行,那当 offset 特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈值的页数进行 SQL 改写。
示例如下,先快速定位需要获取的id段,然后再关联:
select a.* from 表1 a,(select id from 表1 where 条件 limit100000,20 ) b where a.id=b.id;
比如如下 SQL 语句:
select * from user where login_name=?;
可以优化为:
select * from user where login_name=? limit 1
自己明确知道只有一条结果,但数据库并不知道,明确告诉它,让它主动停止游标移动。
Jenis data medan yang perlu dicantumkan mesti konsisten Apabila membuat pertanyaan berbilang jadual, pastikan itu medan yang berkaitan perlu mempunyai indeks.
Contohnya: sambung kiri ditentukan oleh sebelah kiri, dan data di sebelah kiri mesti ada, jadi sebelah kanan ialah titik utama kami, dan indeks mesti dibina di sebelah kanan. Sudah tentu, jika indeks berada di sebelah kiri, anda boleh menggunakan right join.
consts: Terdapat paling banyak satu baris yang sepadan (kunci utama atau indeks unik) dalam satu jadual, dan data boleh dibaca semasa fasa pengoptimuman.
ruj: Gunakan indeks biasa.
julat: Lakukan pengambilan julat pada indeks.
Apabila type=index, semua fail indeks fizikal diimbas, yang sangat perlahan.
Jangan fikir bahawa indeks unik mempengaruhi kelajuan sisipan Kehilangan kelajuan ini boleh diabaikan, tetapi peningkatan dalam kelajuan carian adalah jelas. Di samping itu, walaupun kawalan pengesahan yang sangat lengkap dilaksanakan pada lapisan aplikasi, selagi tiada indeks unik, mengikut undang-undang Murphy, data kotor pasti akan dijana.
Lebih banyak indeks, lebih baik Jika anda fikir anda memerlukan pertanyaan, bina indeks sahaja. Adalah lebih baik untuk mempunyai kurang daripada terlalu banyak, kerana indeks akan menggunakan ruang dan serius memperlahankan kemas kini dan penambahan baharu.
Tentang indeks unik dan percaya bahawa keunikan perniagaan perlu diselesaikan pada lapisan aplikasi melalui "semak dahulu dan masukkan kemudian".
Pengoptimuman pramatang, mula mengoptimumkan tanpa memahami sistem.
Kunci utama secara automatik mencipta indeks yang unik.
Lajur yang sering muncul sebagai syarat pertanyaan dalam pernyataan WHERE atau ORDER BY perlu diindeks.
Medan yang dikaitkan dengan jadual lain dalam pertanyaan, perhubungan kunci asing diindeks.
Lajur yang sering digunakan dalam fungsi agregat perlu diindeks, seperti fungsi agregat seperti min(), max(), dll.
Jangan buat indeks untuk lajur yang kerap ditambah, dipadam atau diubah suai. .
Terdapat sejumlah besar lajur pendua yang tidak diindeks.
Jangan buat indeks jika terdapat terlalu sedikit rekod jadual Kerana data yang kurang, masa untuk menanya semua data mungkin diperlukan daripada melintasi indeks dan indeks. mungkin tidak menghasilkan kesan pengoptimuman.
Pembelajaran yang disyorkan: tutorial video mysql
Atas ialah kandungan terperinci Ringkaskan dan susun mata pengetahuan pengoptimuman indeks MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!


















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



