


Artikel ini membawakan anda pengetahuan yang berkaitan tentang halaman data InnoDB dalam prinsip mysql, termasuk pengetahuan yang berkaitan tentang direktori halaman, pengepala halaman dan pengepala fail Saya harap ia akan membantu semua orang.

Ia adalah unit asas InnoDB mengurus ruang storan Saiz halaman secara amnya 16KB . InnoDBBanyak jenis 页 direka untuk tujuan berbeza, seperti halaman untuk menyimpan maklumat pengepala ruang jadual, halaman untuk menyimpan maklumat Insert Buffer, halaman untuk menyimpan maklumat INODE dan halaman untuk menyimpan log undo Halaman maklumat dan sebagainya dan sebagainya. Sudah tentu, jika anda belum mendengar mana-mana istilah yang saya nyatakan, fikirkan saya kentut~ Tetapi tidak mengapa kita tidak akan bercakap tentang jenis halaman ini hari ini Jenis halaman yang menyimpan rekod dalam jadual kami secara rasmi dipanggil halaman indeks (INDEX) Memandangkan kami masih belum memahami apa itu indeks, rekod dalam jadual ini adalah harian kami Ia dipanggil 数据 di mulut. jadi buat masa ini, mari kita hubungi halaman ini di mana rekod disimpan 数据页.
Ruang storan saiz 16KB yang diwakili oleh halaman data boleh dibahagikan kepada beberapa bahagian Bahagian yang berbeza mempunyai fungsi yang berbeza dalam rajah Ditunjukkan:
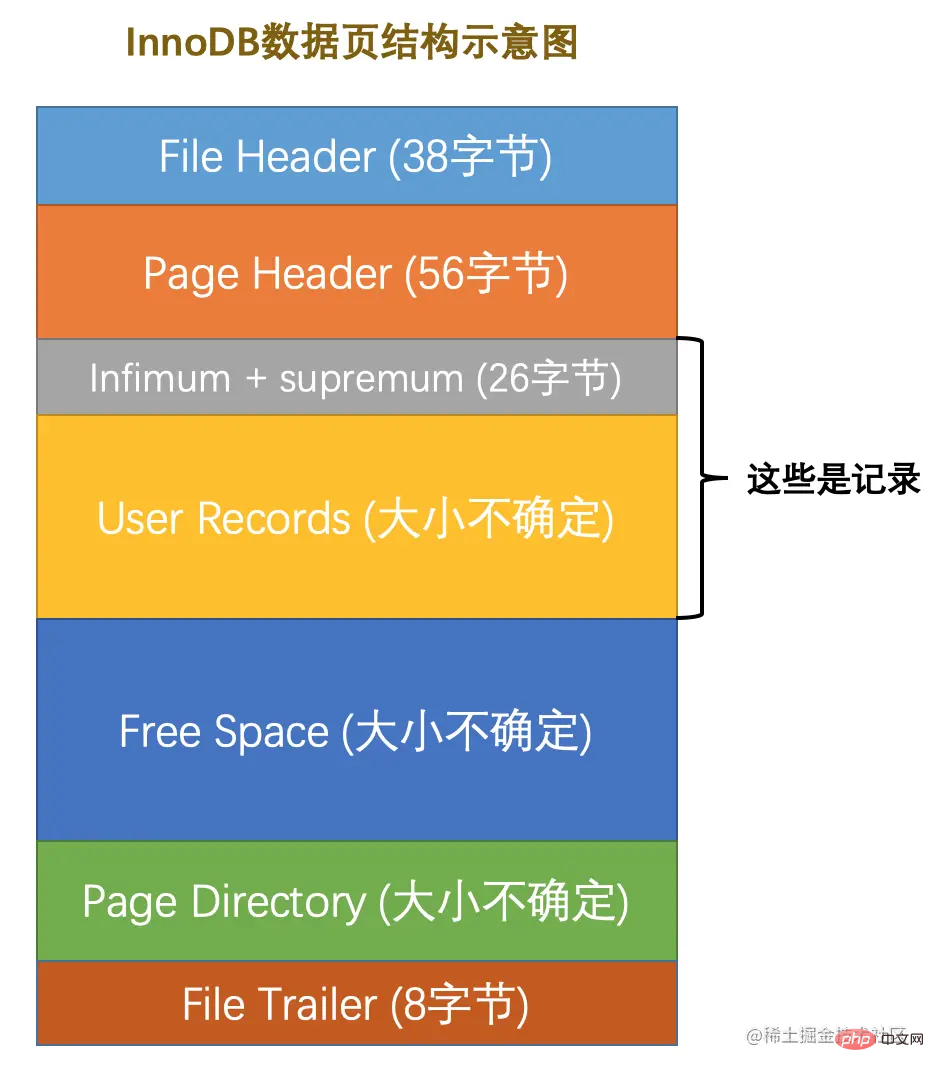
Seperti yang dapat dilihat daripada rajah, ruang storan InnoDB halaman data secara kasar dibahagikan kepada 7 bahagian dan beberapa bahagian occupy Bilangan bait ditentukan, tetapi bilangan bait yang diduduki oleh sesetengah bahagian tidak pasti. Di bawah ini kami menggunakan jadual untuk menerangkan secara kasar kandungan yang disimpan dalam 7 bahagian ini (sekilas pandang, kami akan membincangkannya secara terperinci kemudian):
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
File Header |
文件头部 |
38字节 |
页的一些通用信息 |
Page Header |
页面头部 |
56字节 |
数据页专有的一些信息 |
Infimum Supremum |
最小记录和最大记录 |
26字节 |
两个虚拟的行记录 |
User Records |
用户记录 | 不确定 | 实际存储的行记录内容 |
Free Space |
空闲空间 | 不确定 | 页中尚未使用的空间 |
Page Directory |
页面目录 | 不确定 | 页中的某些记录的相对位置 |
File Trailer |
文件尾部 |
8字节 |
校验页是否完整 |
Penyimpanan rekod dalam halaman
Antara 7 komponen halaman tersebut, rekod yang kami simpan sendiri adalah seperti yang kami tetapkan行格式 Simpan di bahagian User Records. Tetapi apabila kami mula-mula menjana halaman, sebenarnya tiada bahagian User Records Setiap kali kami memasukkan rekod, kami akan memohon ruang bersaiz rekod dari bahagian Free Space, iaitu ruang storan yang tidak digunakan, dan membahagikannya kepada. User Records bahagian, apabila semua ruang di bahagian Free Space digantikan dengan bahagian User Records, bermakna halaman ini telah habis Jika terdapat rekod baharu yang dimasukkan, anda perlu memohon untuk halaman baharu. Proses ini Rajah adalah seperti berikut:
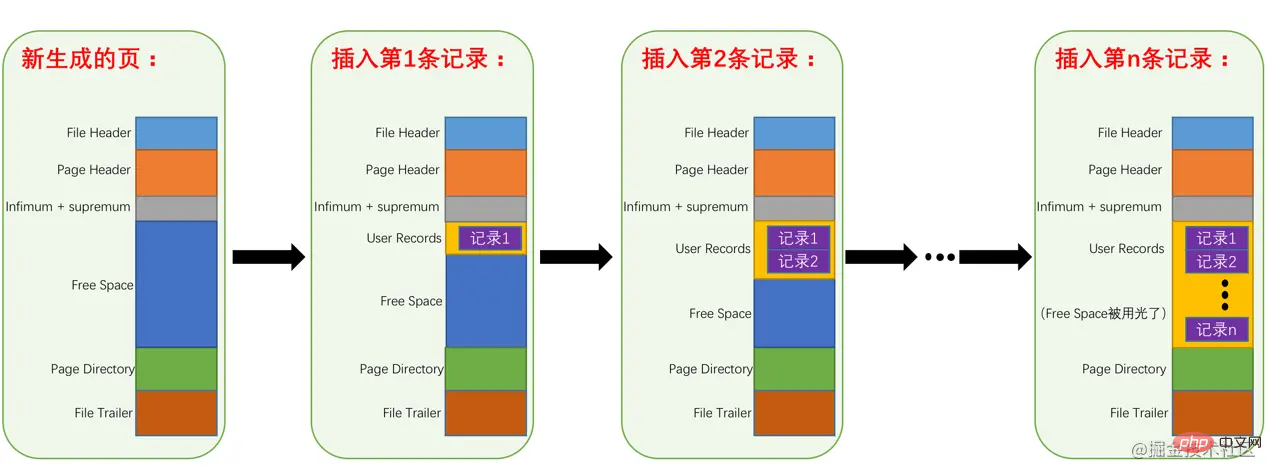
Untuk mengurus rekod ini dengan lebih baik dalam User Records, InnoDB telah menghabiskan banyak usaha usaha? Bukankah hanya untuk meletakkan rekod di bahagian User Records satu persatu mengikut format baris yang ditetapkan? Sebenarnya, kita perlu bermula dengan 记录头信息 format baris rekod.
Untuk kelancaran perkembangan cerita, kami mula-mula mencipta jadual:
mysql> CREATE TABLE page_demo( -> c1 INT, -> c2 INT, -> c3 VARCHAR(10000), -> PRIMARY KEY (c1) -> ) CHARSET=ascii ROW_FORMAT=Compact; Query OK, 0 rows affected (0.03 sec)
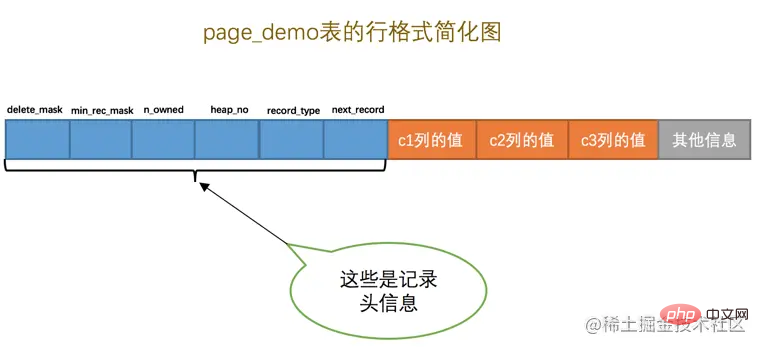
Jadual page_demo yang baru dibuat ini mempunyai 3 lajur , di mana lajur c1 dan c2 digunakan untuk menyimpan integer dan lajur c3 digunakan untuk menyimpan rentetan. Perlu diingatkan bahawa kami menentukan lajur c1 sebagai kunci utama, jadi dalam format baris tertentu, InnoDB tidak perlu mencipta apa yang dipanggil row_id untuk kami. Lajur disembunyikan. Dan kami menetapkan ascii set aksara dan Compact format baris untuk jadual ini. Jadi gambarajah format baris yang direkodkan dalam jadual ini adalah seperti ini:

Seperti yang anda lihat dari gambar, kami menandai secara khas data 5-bait 记录头信息 keluar , menunjukkan bahawa ia adalah sangat penting Mari kita semak semula makna umum setiap atribut dalam 记录头信息 ini (kami kini menggunakan format baris Compact untuk demonstrasi):
| 名称 | 大小(单位:bit) | 描述 |
|---|---|---|
预留位1 |
1 |
没有使用 |
预留位2 |
1 |
没有使用 |
delete_mask |
1 |
标记该记录是否被删除 |
min_rec_mask |
1 |
B 树的每层非叶子节点中的最小记录都会添加该标记 |
n_owned |
4 |
表示当前记录拥有的记录数 |
heap_no |
13 |
表示当前记录在记录堆的位置信息 |
record_type |
3 |
表示当前记录的类型,0表示普通记录,1表示B 树非叶节点记录,2表示最小记录,3表示最大记录 |
next_record |
16 |
表示下一条记录的相对位置 |
由于我们现在主要在唠叨记录头信息的作用,所以为了大家理解上的方便,我们只在page_demo表的行格式演示图中画出有关的头信息属性以及c1、c2、c3列的信息(其他信息没画不代表它们不存在啊,只是为了理解上的方便在图中省略了~),简化后的行格式示意图就是这样:
下边我们试着向page_demo表中插入几条记录:
mysql> INSERT INTO page_demo VALUES(1, 100, 'aaaa'), (2, 200, 'bbbb'), (3, 300, 'cccc'), (4, 400, 'dddd'); Query OK, 4 rows affected (0.00 sec) Records: 4 Duplicates: 0 Warnings: 0
为了方便大家分析这些记录在页的User Records部分中是怎么表示的,我把记录中头信息和实际的列数据都用十进制表示出来了(其实是一堆二进制位),所以这些记录的示意图就是:
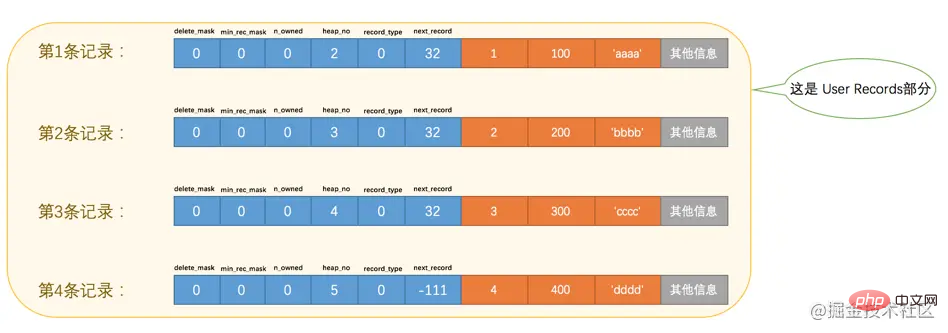
看这个图的时候需要注意一下,各条记录在User Records中存储的时候并没有空隙,这里只是为了大家观看方便才把每条记录单独画在一行中。我们对照着这个图来看看记录头信息中的各个属性是啥意思:
delete_mask
这个属性标记着当前记录是否被删除,占用1个二进制位,值为0的时候代表记录并没有被删除,为1的时候代表记录被删除掉了。
啥?被删除的记录还在页中么?是的,摆在台面上的和背地里做的可能大相径庭,你以为它删除了,可它还在真实的磁盘上[摊手](忽然想起冠希~)。这些被删除的记录之所以不立即从磁盘上移除,是因为移除它们之后把其他的记录在磁盘上重新排列需要性能消耗,所以只是打一个删除标记而已,所有被删除掉的记录都会组成一个所谓的垃圾链表,在这个链表中的记录占用的空间称之为所谓的可重用空间,之后如果有新记录插入到表中的话,可能把这些被删除的记录占用的存储空间覆盖掉。
min_rec_mask
B+树的每层非叶子节点中的最小记录都会添加该标记,什么是个B+树?什么是个非叶子节点?好吧,等会再聊这个问题。反正我们自己插入的四条记录的min_rec_mask值都是0,意味着它们都不是B+树的非叶子节点中的最小记录。
n_owned
这个暂时保密,稍后它是主角~
heap_no
这个属性表示当前记录在本页中的位置,从图中可以看出来,我们插入的4条记录在本页中的位置分别是:2、3、4、5。是不是少了点啥?是的,怎么不见heap_no值为0和1的记录呢?
这其实是设计InnoDB的大叔们玩的一个小把戏,他们自动给每个页里边儿加了两个记录,由于这两个记录并不是我们自己插入的,所以有时候也称为伪记录或者虚拟记录。这两个伪记录一个代表最小记录,一个代表最大记录,等一下哈~,记录可以比大小么?
是的,记录也可以比大小,对于一条完整的记录来说,比较记录的大小就是比较主键的大小。比方说我们插入的4行记录的主键值分别是:1、2、3、4,这也就意味着这4条记录的大小从小到大依次递增。
但是不管我们向页中插入了多少自己的记录,设计InnoDB的大叔们都规定他们定义的两条伪记录分别为最小记录与最大记录。这两条记录的构造十分简单,都是由5字节大小的记录头信息和8字节大小的一个固定的部分组成的,如图所示

由于这两条记录不是我们自己定义的记录,所以它们并不存放在页的User Records部分,他们被单独放在一个称为Infimum + Supremum的部分,如图所示:

从图中我们可以看出来,最小记录和最大记录的heap_no值分别是0和1,也就是说它们的位置最靠前。
record_type
这个属性表示当前记录的类型,一共有4种类型的记录,0表示普通记录,1表示B+树非叶节点记录,2表示最小记录,3表示最大记录。从图中我们也可以看出来,我们自己插入的记录就是普通记录,它们的record_type值都是0,而最小记录和最大记录的record_type值分别为2和3。
至于record_type为1的情况,我们之后在说索引的时候会重点强调的。
next_record
这玩意儿非常重要,它表示从当前记录的真实数据到下一条记录的真实数据的地址偏移量。比方说第一条记录的next_record值为32,意味着从第一条记录的真实数据的地址处向后找32个字节便是下一条记录的真实数据。如果你熟悉数据结构的话,就立即明白了,这其实是个链表,可以通过一条记录找到它的下一条记录。但是需要注意注意再注意的一点是,下一条记录指得并不是按照我们插入顺序的下一条记录,而是按照主键值由小到大的顺序的下一条记录。而且规定 Infimum记录(也就是最小记录) 的下一条记录就是本页中主键值最小的用户记录,而本页中主键值最大的用户记录的下一条记录就是 Supremum记录(也就是最大记录) ,为了更形象的表示一下这个next_record起到的作用,我们用箭头来替代一下next_record中的地址偏移量:
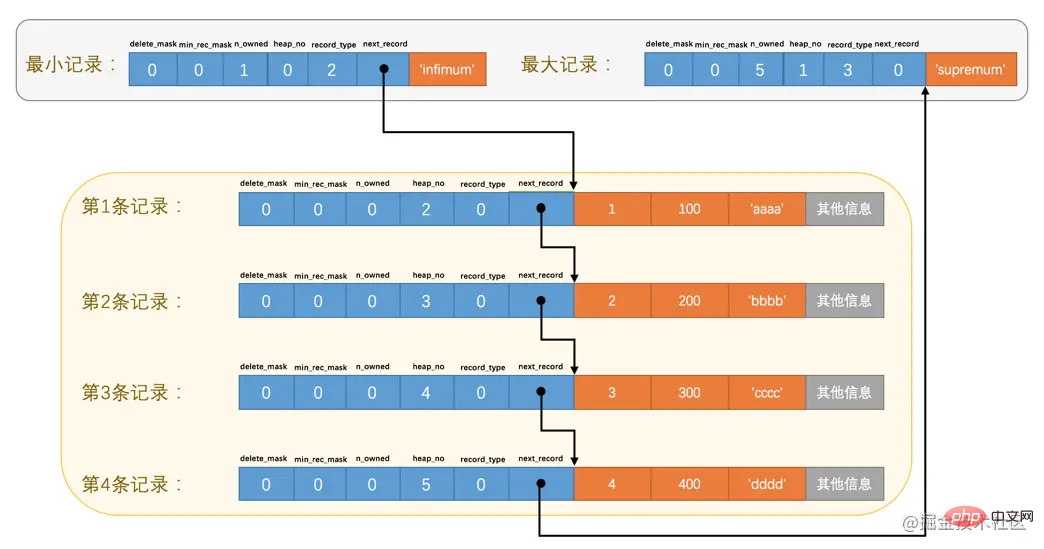
从图中可以看出来,我们的记录按照主键从小到大的顺序形成了一个单链表。最大记录的next_record的值为0,这也就是说最大记录是没有下一条记录了,它是这个单链表中的最后一个节点。如果从中删除掉一条记录,这个链表也是会跟着变化的,比如我们把第2条记录删掉:
mysql> DELETE FROM page_demo WHERE c1 = 2; Query OK, 1 row affected (0.02 sec)
删掉第2条记录后的示意图就是:

从图中可以看出来,删除第2条记录前后主要发生了这些变化:
delete_mask值设置为1。next_record值变为了0,意味着该记录没有下一条记录了。next_record指向了第3条记录。最大记录的n_owned值从5变成了4,关于这一点的变化我们稍后会详细说明的。所以,不论我们怎么对页中的记录做增删改操作,InnoDB始终会维护一条记录的单链表,链表中的各个节点是按照主键值由小到大的顺序连接起来的。
再来看一个有意思的事情,因为主键值为2的记录被我们删掉了,但是存储空间却没有回收,如果我们再次把这条记录插入到表中,会发生什么事呢?
mysql> INSERT INTO page_demo VALUES(2, 200, 'bbbb'); Query OK, 1 row affected (0.00 sec)
我们看一下记录的存储情况:
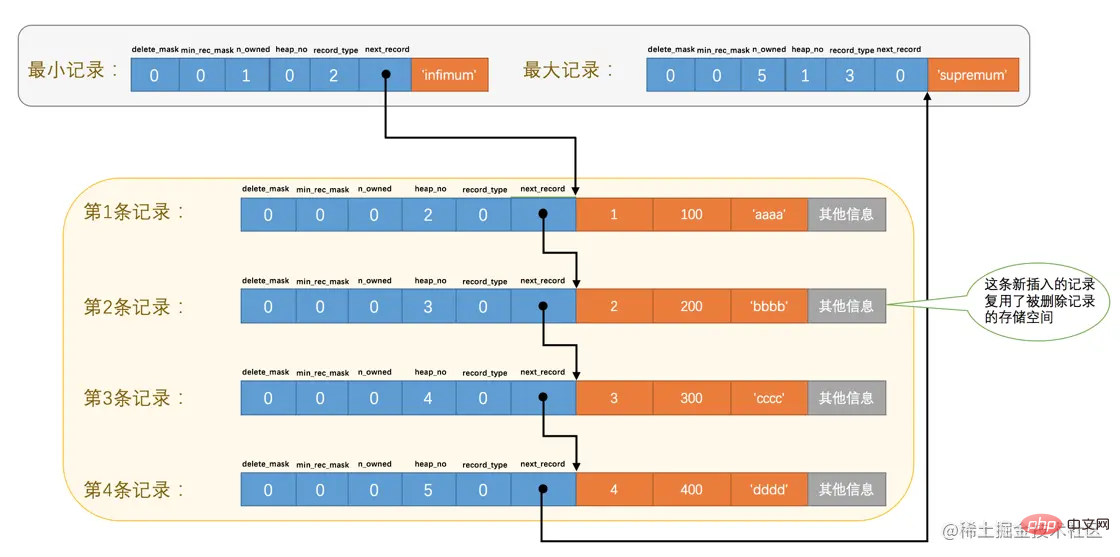
从图中可以看到,InnoDB并没有因为新记录的插入而为它申请新的存储空间,而是直接复用了原来被删除记录的存储空间。
现在我们了解了记录在页中按照主键值由小到大顺序串联成一个单链表,那如果我们想根据主键值查找页中的某条记录该咋办呢?比如说这样的查询语句:
SELECT * FROM page_demo WHERE c1 = 3;
最笨的办法:从Infimum记录(最小记录)开始,沿着链表一直往后找,总有一天会找到(或者找不到[摊手]),在找的时候还能投机取巧,因为链表中各个记录的值是按照从小到大顺序排列的,所以当链表的某个节点代表的记录的主键值大于你想要查找的主键值时,你就可以停止查找了,因为该节点后边的节点的主键值依次递增。
Kaedah ini tiada masalah apabila bilangan rekod yang disimpan dalam halaman adalah agak kecil, contohnya, jadual kami kini hanya mempunyai 4 rekod yang disisipkan oleh kami sendiri, jadi ia boleh dicari sehingga 4 kali rekod dilalui sekali, tetapi jika terdapat banyak rekod yang disimpan dalam halaman, carian sebegitu masih akan mengalami kehilangan prestasi, jadi kami katakan carian traversal ini ialah kaedah 笨. Tetapi siapakah pakcik-pakcik yang mereka InnoDB bolehkah mereka menggunakan kaedah bodoh seperti itu, mereka perlu merancang kaedah carian yang lebih baik.
Apabila kita biasanya ingin mencari sesuatu dalam buku, kita biasanya melihat senarai kandungan dahulu, mencari nombor halaman buku yang sepadan dengan kandungan yang perlu kita cari, dan kemudian pergi ke halaman yang sepadan nombor untuk melihat kandungan. Pakcik yang mereka InnoDB juga membuat direktori yang sama untuk rekod kami Proses pengeluaran mereka adalah seperti berikut:
akan semua rekod biasa (termasuk rekod maksimum dan minimum , tidak termasuk rekod yang ditanda. seperti yang dipadamkan) kepada beberapa kumpulan.
Atribut n_owned dalam maklumat pengepala rekod terakhir setiap kumpulan (iaitu rekod terbesar dalam kumpulan) menunjukkan bilangan rekod yang ada pada rekod, iaitu, yang Terdapat beberapa rekod dalam kumpulan.
Ekstrak alamat mengimbangi rekod terakhir setiap kumpulan secara berasingan dan simpannya mengikut urutan berhampiran penghujung 页 Tempat ini dipanggil Page Directory 页目录 (pada ketika ini anda harus kembali ke bahagian atas dan melihat gambar setiap bahagian halaman). Offset alamat ini dalam direktori halaman dipanggil 槽 (nama Inggeris: Slot), jadi direktori halaman terdiri daripada 槽.
Sebagai contoh, pada masa ini terdapat 6 rekod biasa dalam jadual page_demo akan membahagikannya kepada dua kumpulan Kumpulan pertama hanya mempunyai satu rekod minimum, dan yang kedua kumpulan Di tengah adalah baki 5 rekod, lihat rajah di bawah: InnoDB
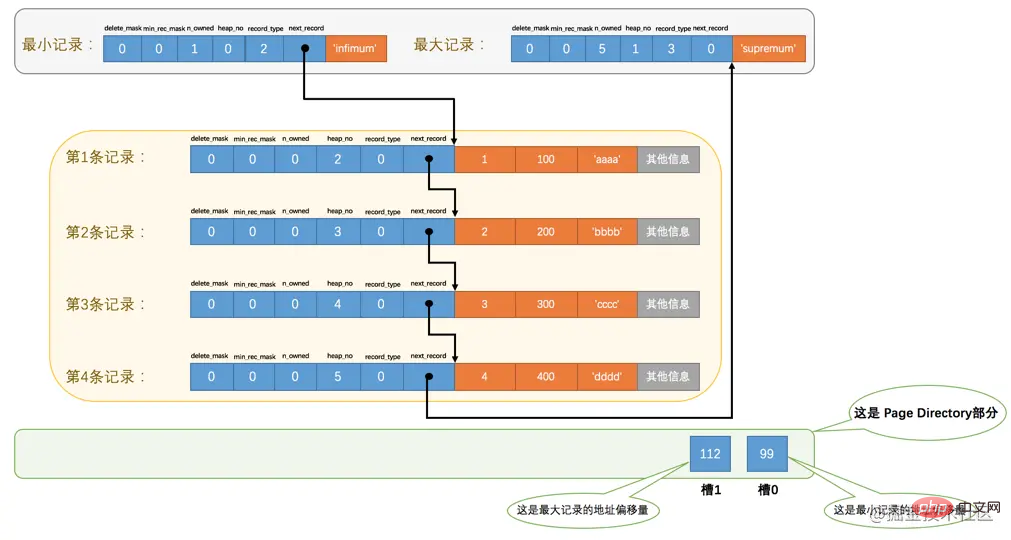
, yang bermaksud rekod kami dibahagikan kepada dua kumpulan Nilai dalam 页目录 ialah 槽1, yang mewakili offset alamat rekod terbesar (. iaitu dari halaman Bermula dari 0 bait, dikira hingga 112 bait); nilai dalam 112 ialah 槽0, yang mewakili alamat mengimbangi rekod terkecil. 99
dalam maklumat pengepala rekod minimum dan maksimum n_owned
n_owned, yang bermaksud Terdapat hanya 1 rekod dalam kumpulan yang berakhir dengan rekod minimum, iaitu rekod minimum itu sendiri. 1
n_owned, yang bermaksud hanya terdapat 5 rekod dalam kumpulan yang berakhir dengan rekod terbesar, termasuk rekod terbesar itu sendiri dan 5 kami memasukkan rekod diri kita. Offset alamat seperti 4
dan 99 sangat tidak intuitif Kami menggunakan anak panah untuk menunjuk kepada nombor dan bukannya nombor, yang lebih mudah untuk kami fahami, jadi selepas pengubahsuaian Gambarajah skematik adalah seperti ini: 112

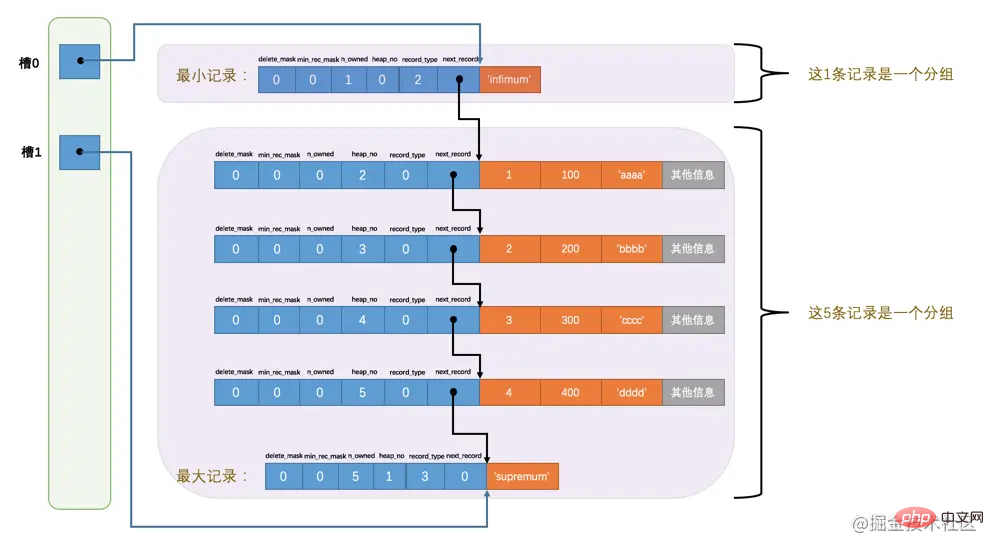
rekod terkecil 1, dan nilai n_owned rekod terbesar ialah n_owned Adakah terdapat sesuatu yang mencurigakan di sini? 5
mempunyai peraturan tentang bilangan rekod dalam setiap kumpulan: kumpulan yang mempunyai rekod terkecil hanya boleh mempunyai InnoDB1 rekod, bilangan rekod dalam kumpulan di mana rekod terbesar terletak hanya boleh antara 1~8 rekod, dan bilangan rekod dalam kumpulan yang tinggal hanya boleh berada dalam julat Ia adalah antara 4~8 bar. Oleh itu, pengumpulan dijalankan mengikut langkah berikut:
, dan maka rekod yang sepadan dengan slot akan ditemui Nilai 页目录 dinaikkan sebanyak 1, menunjukkan bahawa rekod lain telah ditambahkan pada kumpulan ini sehingga bilangan rekod dalam kumpulan ini bersamaan dengan 8. n_owned
在一个组中的记录数等于8个后再插入一条记录时,会将组中的记录拆分成两个组,一个组中4条记录,另一个5条记录。这个过程会在页目录中新增一个槽来记录这个新增分组中最大的那条记录的偏移量。
由于现在page_demo表中的记录太少,无法演示添加了页目录之后加快查找速度的过程,所以再往page_demo表中添加一些记录:
mysql> INSERT INTO page_demo VALUES(5, 500, 'eeee'), (6, 600, 'ffff'), (7, 700, 'gggg'), (8, 800, 'hhhh'), (9, 900, 'iiii'), (10, 1000, 'jjjj'), (11, 1100, 'kkkk'), (12, 1200, 'llll'), (13, 1300, 'mmmm'), (14, 1400, 'nnnn'), (15, 1500, 'oooo'), (16, 1600, 'pppp'); Query OK, 12 rows affected (0.00 sec) Records: 12 Duplicates: 0 Warnings: 0
哈,我们一口气又往表中添加了12条记录,现在页里边就一共有18条记录了(包括最小和最大记录),这些记录被分成了5个组,如图所示:
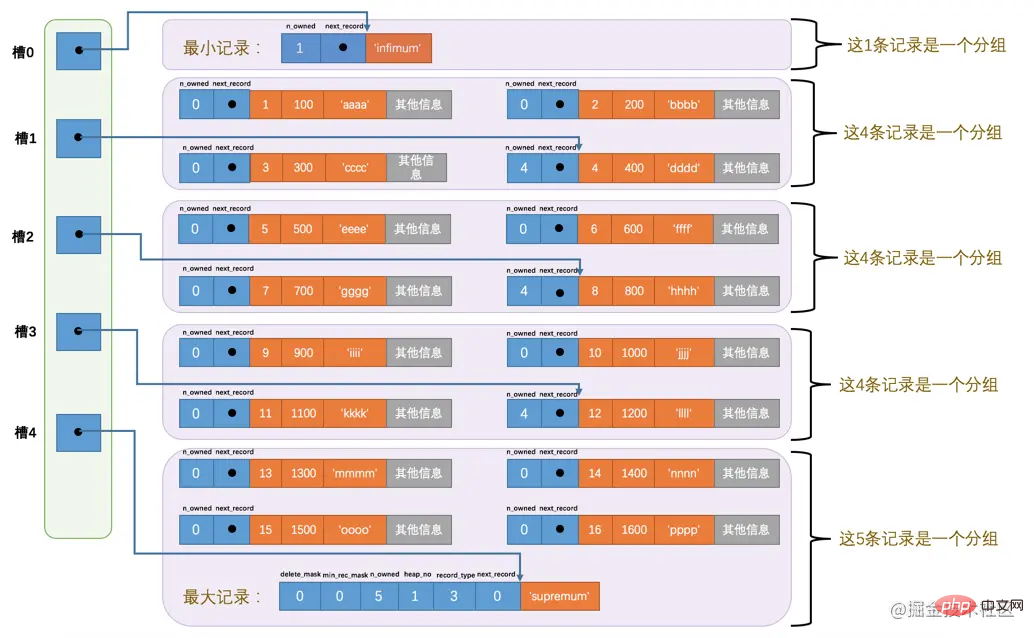
因为把16条记录的全部信息都画在一张图里太占地方,让人眼花缭乱的,所以只保留了用户记录头信息中的n_owned和next_record属性,也省略了各个记录之间的箭头,我没画不等于没有啊!现在看怎么从这个页目录中查找记录。因为各个槽代表的记录的主键值都是从小到大排序的,所以我们可以使用所谓的二分法来进行快速查找。5个槽的编号分别是:0、1、2、3、4,所以初始情况下最低的槽就是low=0,最高的槽就是high=4。比方说我们想找主键值为6的记录,过程是这样的:
计算中间槽的位置:(0+4)/2=2,所以查看槽2对应记录的主键值为8,又因为8 > 6,所以设置high=2,low保持不变。
重新计算中间槽的位置:(0+2)/2=1,所以查看槽1对应的主键值为4,又因为4 ,所以设置<code>low=1,high保持不变。
因为high - low的值为1,所以确定主键值为6的记录在槽2对应的组中。此刻我们需要找到槽2中主键值最小的那条记录,然后沿着单向链表遍历槽2中的记录。但是我们前边又说过,每个槽对应的记录都是该组中主键值最大的记录,这里槽2对应的记录是主键值为8的记录,怎么定位一个组中最小的记录呢?别忘了各个槽都是挨着的,我们可以很轻易的拿到槽1对应的记录(主键值为4),该条记录的下一条记录就是槽2中主键值最小的记录,该记录的主键值为5。所以我们可以从这条主键值为5的记录出发,遍历槽2中的各条记录,直到找到主键值为6的那条记录即可。由于一个组中包含的记录条数只能是1~8条,所以遍历一个组中的记录的代价是很小的。
所以在一个数据页中查找指定主键值的记录的过程分为两步:
通过二分法确定该记录所在的槽,并找到该槽所在分组中主键值最小的那条记录。
通过记录的next_record属性遍历该槽所在的组中的各个记录。
设计InnoDB的大叔们为了能得到一个数据页中存储的记录的状态信息,比如本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽等等,特意在页中定义了一个叫Page Header的部分,它是页结构的第二部分,这个部分占用固定的56个字节,专门存储各种状态信息,具体各个字节都是干嘛的看下表:
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
PAGE_N_DIR_SLOTS |
2字节 |
在页目录中的槽数量 |
PAGE_HEAP_TOP |
2字节 |
还未使用的空间最小地址,也就是说从该地址之后就是Free Space
|
PAGE_N_HEAP |
2字节 |
本页中的记录的数量(包括最小和最大记录以及标记为删除的记录) |
PAGE_FREE |
2字节 |
第一个已经标记为删除的记录地址(各个已删除的记录通过next_record也会组成一个单链表,这个单链表中的记录可以被重新利用) |
PAGE_GARBAGE |
2字节 |
已删除记录占用的字节数 |
PAGE_LAST_INSERT |
2字节 |
最后插入记录的位置 |
PAGE_DIRECTION |
2字节 |
记录插入的方向 |
PAGE_N_DIRECTION |
2字节 |
一个方向连续插入的记录数量 |
PAGE_N_RECS |
2字节 |
该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录) |
PAGE_MAX_TRX_ID |
8字节 |
修改当前页的最大事务ID,该值仅在二级索引中定义 |
PAGE_LEVEL |
2字节 |
当前页在B 树中所处的层级 |
PAGE_INDEX_ID |
8字节 |
索引ID,表示当前页属于哪个索引 |
PAGE_BTR_SEG_LEAF |
10字节 |
B 树叶子段的头部信息,仅在B 树的Root页定义 |
PAGE_BTR_SEG_TOP |
10字节 |
B 树非叶子段的头部信息,仅在B 树的Root页定义 |
Jika anda telah membaca artikel sebelum ini dengan teliti, anda mesti jelas tentang maksud dari PAGE_N_DIR_SLOTS hingga PAGE_LAST_INSERT dan PAGE_N_RECS Jika tidak, maaf, anda harus kembali dan membaca artikel sebelumnya . Jangan risau jika anda tidak memahami maklumat status yang lain Anda perlu makan satu gigitan pada satu masa dan belajar perkara sedikit demi sedikit (pastikan anda tenang dan jangan takut dengan kata nama ini). Di sini kita mula-mula bercakap tentang maksud PAGE_DIRECTION dan PAGE_N_DIRECTION:
PAGE_DIRECTION
Jika nilai kunci utama rekod yang baru dimasukkan lebih tinggi daripada Jika nilai kunci utama rekod adalah besar, kami mengatakan bahawa arah sisipan rekod ini adalah ke kanan, dan sebaliknya. Status yang digunakan untuk menunjukkan arah sisipan rekod terakhir ialah PAGE_DIRECTION.
PAGE_N_DIRECTION
Dengan mengandaikan bahawa arah memasukkan rekod baharu beberapa kali berturut-turut adalah sama, InnoDB akan memasukkan bilangan rekod sepanjang yang sama arah. Tuliskannya, nombor ini akan diwakili oleh status PAGE_N_DIRECTION. Sudah tentu, jika arah sisipan rekod terakhir berubah, nilai status ini akan dikosongkan dan dikira semula.
Mengenai atribut yang tidak kami sebutkan, saya tidak menyebutnya kerana anda tidak perlu mengetahuinya sekarang. Jangan risau, apabila kita selesai mempelajari kandungan berikut, apabila anda melihat ke belakang, semuanya akan menjadi begitu jelas.
Page Header yang dinyatakan di atas adalah khusus untuk pelbagai maklumat status yang direkodkan oleh 数据页, contohnya, berapa banyak rekod yang terdapat pada halaman? ? File Header yang kami huraikan sekarang adalah perkara biasa kepada pelbagai jenis halaman, yang bermaksud bahawa jenis halaman yang berbeza akan menggunakan File Header sebagai komponen pertama Ia menerangkan beberapa maklumat yang biasa kepada pelbagai halaman, seperti Sebutkan apa itu nombor halaman ini, siapa halaman sebelumnya dan halaman seterusnya? Bahagian ini menduduki bait 38 tetap dan terdiri daripada kandungan berikut:
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
FIL_PAGE_SPACE_OR_CHKSUM |
4字节 |
页的校验和(checksum值) |
FIL_PAGE_OFFSET |
4字节 |
页号 |
FIL_PAGE_PREV |
4字节 |
上一个页的页号 |
FIL_PAGE_NEXT |
4字节 |
下一个页的页号 |
FIL_PAGE_LSN |
8字节 |
页面被最后修改时对应的日志序列位置(英文名是:Log Sequence Number) |
FIL_PAGE_TYPE |
2字节 |
该页的类型 |
FIL_PAGE_FILE_FLUSH_LSN |
8字节 |
仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 |
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID |
4字节 |
页属于哪个表空间 |
Bedakan jadual ini, mari lihat beberapa bahagian penting pada masa ini:
FIL_PAGE_SPACE_OR_CHKSUM
Ini mewakili jumlah semak halaman semasa. Apakah checksum? Iaitu, untuk rentetan bait yang sangat panjang, kami akan menggunakan algoritma tertentu untuk mengira nilai yang lebih pendek untuk mewakili rentetan bait yang panjang Nilai yang agak pendek ini dipanggil 校验和. Dengan cara ini, sebelum membandingkan dua rentetan bait yang sangat panjang, mula-mula bandingkan jumlah semak bagi dua rentetan bait panjang ini Jika jumlah semak berbeza, dua rentetan bait panjang mestilah berbeza, jadi perbandingan langsung dikecualikan rentetan bait yang panjang.
FIL_PAGE_OFFSET
Setiap 页 mempunyai nombor halaman yang berasingan, sama seperti nombor kad pengenalan anda, InnoDB ditentukan oleh nombor halaman A 页 boleh diletakkan secara unik.
FIL_PAGE_TYPE
Ini mewakili jenis semasa 页 Seperti yang kami katakan sebelum ini, InnoDB membahagikan halaman kepada jenis yang berbeza untuk tujuan yang berbeza yang kami perkenalkan di atas sebenarnya adalah 数据页 untuk menyimpan rekod Sebenarnya, terdapat banyak jenis halaman lain, seperti yang ditunjukkan dalam jadual berikut:
| taip Nama | Hex | Penerangan | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
FIL_PAGE_TYPE_ALLOCATED |
0x0000 | Peruntukan terkini, belum digunakan lagi | ||||||||||||||||||||||||||||||||||||
FIL_PAGE_UNDO_LOG |
0x0002 td> | Buat asal halaman log | ||||||||||||||||||||||||||||||||||||
FIL_PAGE_INODE |
0x0003 | Nod maklumat segmen td> | ||||||||||||||||||||||||||||||||||||
FIL_PAGE_IBUF_FREE_LIST |
0x0004 | Sisipkan senarai percuma Penimbal | FIL_PAGE_IBUF_BITMAP |
0x0005 | Sisipkan Peta Bit Penampan | |||||||||||||||||||||||||||||||||
FIL_PAGE_TYPE_SYS |
0x0006 | Halaman sistem | ||||||||||||||||||||||||||||||||||||
FIL_PAGE_TYPE_TRX_SYS |
0x0007 td> | Data sistem transaksi | ||||||||||||||||||||||||||||||||||||
FIL_PAGE_TYPE_FSP_HDR |
0x0008 | Maklumat pengepala ruang jadual | ||||||||||||||||||||||||||||||||||||
FIL_PAGE_TYPE_XDES |
0x0009 | Halaman penerangan lanjutan | ||||||||||||||||||||||||||||||||||||
FIL_PAGE_TYPE_BLOB |
0x000A | Halaman limpahan | ||||||||||||||||||||||||||||||||||||
FIL_PAGE_INDEX |
0x45BF | Halaman indeks, yang kami panggil
|
Jenis halaman data tempat kami menyimpan rekod sebenarnya FIL_PAGE_INDEX, juga dikenali sebagai 索引页. Mengenai apa itu indeks, mari kita dengar penjelasan lain kali ~
FIL_PAGE_PREV dan FIL_PAGE_NEXT
Seperti yang kami tekankan sebelum ini, InnoDB berasaskan pada halaman. Untuk menyimpan data, kadangkala kami menyimpan jenis data tertentu yang menggunakan ruang yang sangat besar (contohnya, terdapat beribu-ribu rekod dalam jadual InnoDB Mungkin tidak boleh memperuntukkan yang sangat besar). ruang storan untuk banyak data sekali gus Jika ruang storan bertaburan ke dalam berbilang halaman terputus, halaman ini perlu dikaitkan FIL_PAGE_PREV dan FIL_PAGE_NEXT masing-masing mewakili nombor halaman sebelumnya dan halaman seterusnya. Dengan cara ini, banyak halaman disambungkan secara bersiri dengan mewujudkan senarai terpaut dua kali, tanpa memerlukan halaman ini disambungkan secara fizikal. Perlu diingatkan bahawa tidak semua jenis halaman mempunyai atribut halaman sebelumnya dan seterusnya, tetapi 数据页 yang kita bicarakan dalam episod ini (iaitu, halaman jenis FIL_PAGE_INDEX) mempunyai dua atribut ini. jadi semua halaman data sebenarnya adalah senarai berpaut dua, seperti ini:
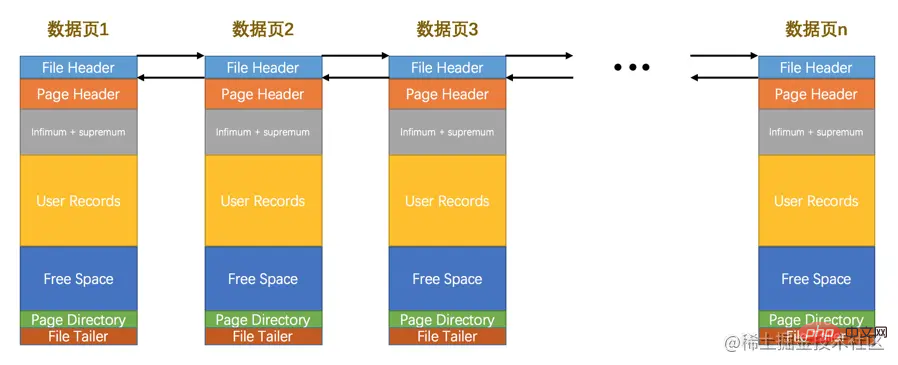
Kami tidak akan menggunakan atribut lain File Header untuk masa ini. Saya akan menyebutnya kemudian~
Kami tahu bahawa enjin storan InnoDB akan menyimpan data pada cakera, tetapi kelajuan cakera terlalu perlahan, jadi kami perlu menggunakan 页 sebagai Unit memuatkan data ke dalam memori untuk diproses Jika data dalam halaman diubah suai dalam memori, data perlu disegerakkan ke cakera pada masa tertentu selepas pengubahsuaian. Tetapi apakah yang perlu saya lakukan jika kuasa terputus separuh jalan melalui penyegerakan. Bukankah ini janggal? Untuk menyemak sama ada halaman itu lengkap (iaitu, sama ada terdapat situasi yang memalukan di mana hanya separuh daripada halaman disegerakkan semasa penyegerakan), pakcik yang mereka bentuk InnoDB menambah bahagian File Trailer pada akhir setiap halaman , yang terdiri daripada 8 terdiri daripada bait, boleh dibahagikan kepada 2 bahagian kecil:
4 bait pertama mewakili jumlah semak halaman
Bahagian ini ialah jumlah File Header Sepadan dengan jumlah semak dalam . Setiap kali halaman diubah suai dalam ingatan, jumlah semaknya mesti dikira sebelum penyegerakan Kerana File Header berada di hadapan halaman, jumlah semak akan disegerakkan ke cakera terlebih dahulu Apabila ia ditulis sepenuhnya, Jumlah semak juga akan ditulis ke penghujung halaman Jika penyegerakan penuh berjaya, jumlah semak pada permulaan dan penghujung halaman hendaklah konsisten. Jika kuasa terputus separuh jalan melalui penulisan, maka jumlah semak dalam File Header mewakili halaman yang diubah suai, dan jumlah semak dalam File Trailer mewakili halaman asal Perbezaan antara kedua-dua bermakna Ralat telah berlaku semasa penyegerakan.
4 bait terakhir mewakili kedudukan jujukan log (LSN) yang sepadan apabila halaman terakhir diubah suai
Bahagian ini juga untuk mengesahkan integriti halaman. Cuma Walau bagaimanapun, kami belum menyatakan maksud LSN lagi, jadi anda boleh mengabaikan atribut ini buat masa ini.
Ini File Trailer serupa dengan File Header dan biasa kepada semua jenis halaman.
InnoDB telah mereka bentuk halaman yang berbeza untuk tujuan yang berbeza Kami memanggil halaman yang digunakan untuk menyimpan rekod 数据页.
Sesuatu halaman data boleh dibahagikan secara kasar kepada 7 bahagian, iaitu
File Header, yang mewakili beberapa maklumat umum halaman, mengambil kira satu tetap 38 bait. Page Header, mewakili beberapa maklumat eksklusif untuk halaman data, menduduki 56 bait tetap. Infimum Supremum, dua rekod pseudo maya, masing-masing mewakili rekod minimum dan maksimum dalam halaman, menduduki bait 26 tetap. User Records: Bahagian yang sebenarnya menyimpan rekod yang kami masukkan, saiznya tidak tetap. Free Space: Bahagian halaman yang tidak digunakan, saiznya tidak pasti. Page Directory: Kedudukan relatif beberapa rekod dalam halaman, iaitu alamat mengimbangi setiap slot dalam halaman Saiz tidak tetap Lebih banyak rekod dimasukkan, lebih banyak ruang yang diperlukan oleh bahagian ini naik. File Trailer: digunakan untuk menyemak sama ada halaman itu lengkap, menduduki 8 bait tetap. Terdapat atribut next_record dalam maklumat pengepala setiap rekod, supaya semua rekod dalam halaman disatukan menjadi satu 单链表.
InnoDB akan membahagikan rekod dalam halaman kepada beberapa kumpulan, dan alamat mengimbangi rekod terakhir dalam setiap kumpulan akan disimpan dalam 槽 sebagai Page Directory , jadi sangat pantas untuk mencari rekod berdasarkan kunci utama dalam halaman Ia terbahagi kepada dua langkah:
Tentukan slot di mana rekod terletak melalui kaedah dikotomi. .
Lelaran melalui rekod dalam kumpulan tempat slot terletak melalui atribut next_record bagi rekod.
Bahagian File Header setiap halaman data mempunyai nombor halaman sebelumnya dan seterusnya, jadi semua halaman data akan membentuk satu 双链表.
Untuk memastikan integriti halaman disegerakkan dari memori ke cakera, jumlah semak data dalam halaman dan pengubahsuaian terakhir halaman akan disimpan pada permulaan dan akhir daripada nilai halaman LSN Jika nilai semak dan LSN pengepala dan ekor tidak berjaya disahkan, ini bermakna terdapat masalah dengan proses penyegerakan.
Pembelajaran yang disyorkan: tutorial video mysql
Atas ialah kandungan terperinci Kajian mendalam tentang halaman data InnoDB Prinsip MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



