


Artikel ini membawa anda pengetahuan yang berkaitan tentang kumpulan Penampan dalam MySQL, termasuk halaman data, senarai percuma halaman cache, senarai siram, Bahagian senarai LRU, dll. Saya harap ia akan membantu semua orang.

Melalui perbualan sebelum ini, kita tahu bahawa untuk jadual yang menggunakan InnoDB sebagai enjin penyimpanan, sama ada ia digunakan Indeks yang menyimpan data pengguna (termasuk indeks berkelompok dan indeks sekunder), atau pelbagai data sistem, semuanya disimpan dalam 页 dalam bentuk 表空间, dan apa yang dipanggil 表空间 hanyalah InnoDB Abstraksi satu atau beberapa fail sebenar pada sistem fail, yang bermaksud bahawa data kami masih disimpan pada cakera. Tetapi semua orang juga tahu bahawa kelajuan cakera adalah perlahan seperti kura-kura, bagaimana ia layak mendapat CPU yang "cepat seperti angin dan sepantas kilat"? Jadi InnoDB apabila enjin storan memproses permintaan pelanggan, apabila ia perlu mengakses data halaman tertentu, ia akan memuatkan semua data halaman lengkap ke dalam memori, iaitu, walaupun kita hanya perlu akses satu rekod halaman , yang juga memerlukan memuatkan keseluruhan halaman data ke dalam ingatan terlebih dahulu. Selepas keseluruhan halaman dimuatkan ke dalam memori, akses baca dan tulis boleh dilakukan Selepas akses baca dan tulis selesai, tidak perlu tergesa-gesa untuk melepaskan ruang memori yang sepadan dengan halaman, tetapi untuk 缓存 itu, supaya. akan ada permintaan lagi pada masa hadapan. Apabila mengakses halaman ini, anda boleh menyimpan cakera IO overhed.
Pakcik yang mereka bentuk InnoDB untuk menyimpan cache halaman dalam cakera, dalam pelayan MySQL Apabila ia dimulakan, ia digunakan pada sistem pengendalian untuk sekeping memori bersebelahan Mereka memberikan sekeping memori ini nama, dipanggil Buffer Pool (nama Cina ialah 缓冲池). Jadi berapa besarnya? Ini sebenarnya bergantung pada konfigurasi mesin kami Jika anda seorang yang kaya dan anda mempunyai 512G ingatan, anda boleh memperuntukkan beberapa ratus G sebagai Buffer Pool Sudah tentu, jika anda tidak begitu kaya, anda boleh menetapkan a tetapan yang lebih kecil~ Lalai Sekiranya Buffer Pool hanya bersaiz 128M. Sudah tentu, jika anda tidak suka ini 128M terlalu besar atau terlalu kecil, anda boleh mengkonfigurasi nilai parameter innodb_buffer_pool_size semasa memulakan pelayan, yang mewakili saiz Buffer Pool, seperti ini:
[server] innodb_buffer_pool_size = 268435456
di mana , unit 268435456 ialah bait, iaitu, saya nyatakan saiz Buffer Pool menjadi 256M. Perlu diingat bahawa Buffer Pool tidak boleh terlalu kecil, dan nilai minimum ialah 5M (apabila lebih kecil daripada nilai ini, ia akan ditetapkan secara automatik kepada 5M).
Buffer Pool adalah sama dengan saiz halaman lalai pada cakera, kedua-duanya adalah 16KB. Untuk mengurus halaman cache ini dengan lebih baik dalam Buffer Pool, bapa saudara yang mereka bentuk InnoDB mencipta beberapa yang dipanggil 控制信息 untuk setiap halaman cache Maklumat kawalan ini termasuk nombor ruang jadual dan nombor halaman yang dimiliki halaman tersebut. , alamat halaman cache dalam Buffer Pool, maklumat nod senarai terpaut, beberapa maklumat kunci dan maklumat LSN (kita akan bercakap tentang kunci dan LSN secara terperinci kemudian, tetapi boleh diabaikan buat masa ini), dan sudah tentu beberapa maklumat kawalan lain , kami tidak akan pergi ke butiran di sini, mari pilih yang penting~
Saiz memori yang diduduki oleh maklumat kawalan yang sepadan dengan setiap halaman cache adalah sama, jadi kami akan menduduki jumlah yang sama ingatan sebagai maklumat kawalan yang sepadan dengan setiap halaman Sekeping memori dipanggil 控制块 Terdapat surat-menyurat satu-dengan-satu antara blok kawalan dan halaman cache blok kawalan disimpan di hadapan Kolam Penampan, dan halaman cache disimpan di bahagian belakang Kolam Penampan Jadi keseluruhan ruang memori yang sepadan dengan Buffer Pool kelihatan seperti ini:
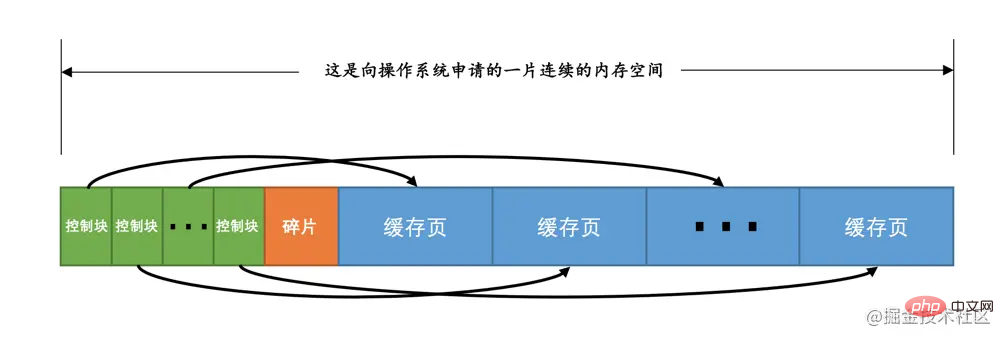 <.>
<.>
antara blok kawalan dan halaman cache? Fikirkan, setiap blok kawalan sepadan dengan halaman cache Selepas memperuntukkan blok kawalan dan halaman cache yang mencukupi, ruang yang tinggal mungkin tidak mencukupi untuk sepasang blok kawalan dan halaman cache, jadi secara semula jadi ia tidak akan digunakan di sini sedikit ruang memori yang tidak digunakan dipanggil 碎片. Sudah tentu, jika anda menetapkan saiz 碎片 dengan betul, Buffer Pool~碎片 mungkin tidak dijana.
Petua: Setiap blok kawalan menduduki lebih kurang 5% daripada saiz halaman cache Dalam versi MySQL 5.7.21, saiz setiap blok kawalan ialah 808 bait. Saiz innodb_buffer_pool_size yang kami tetapkan tidak termasuk ruang memori yang diduduki oleh bahagian blok kawalan ini, maksudnya, apabila InnoDB menggunakan ruang memori berterusan daripada sistem pengendalian untuk Buffer Pool, ruang memori berterusan ini secara amnya akan menjadi 5 lebih besar daripada. nilai innodb_buffer_pool_size %about.
Apabila kita mula-mula memulakan pelayan MySQL, kita perlu melengkapkan proses permulaan Buffer Pool, iaitu operasi pertama Sistem menggunakan Buffer Pool ruang memori dan kemudian membahagikannya kepada pasangan blok kawalan dan halaman cache. Walau bagaimanapun, tiada halaman cakera sebenar dicache dalam Buffer Pool pada masa ini (kerana ia belum digunakan kemudian, semasa program berjalan, halaman pada cakera akan terus dicache dalam Buffer Pool). Jadi persoalannya ialah, apabila membaca halaman dari cakera ke dalam Buffer Pool, di manakah ia harus diletakkan dalam halaman cache? Atau bagaimana untuk membezakan halaman cache dalam Buffer Pool yang mana yang percuma dan mana yang telah digunakan? Kami lebih baik merekodkan halaman cache dalam Kumpulan Penampan yang tersedia pada masa ini, 控制块 yang sepadan dengan halaman cache berguna Kami boleh menggunakan blok kawalan yang sepadan dengan semua halaman cache percuma sebagai nod ia ke dalam senarai terpaut, yang juga boleh dipanggil free链表 (atau senarai terpaut percuma). Semua halaman cache dalam Buffer Pool yang baru dimulakan adalah percuma, jadi blok kawalan yang sepadan dengan setiap halaman cache akan ditambahkan pada free链表 Andaikan bilangan halaman cache yang boleh dimuatkan dalam Buffer Pool ini ialah n, rendering penambahan free链表 adalah seperti ini:
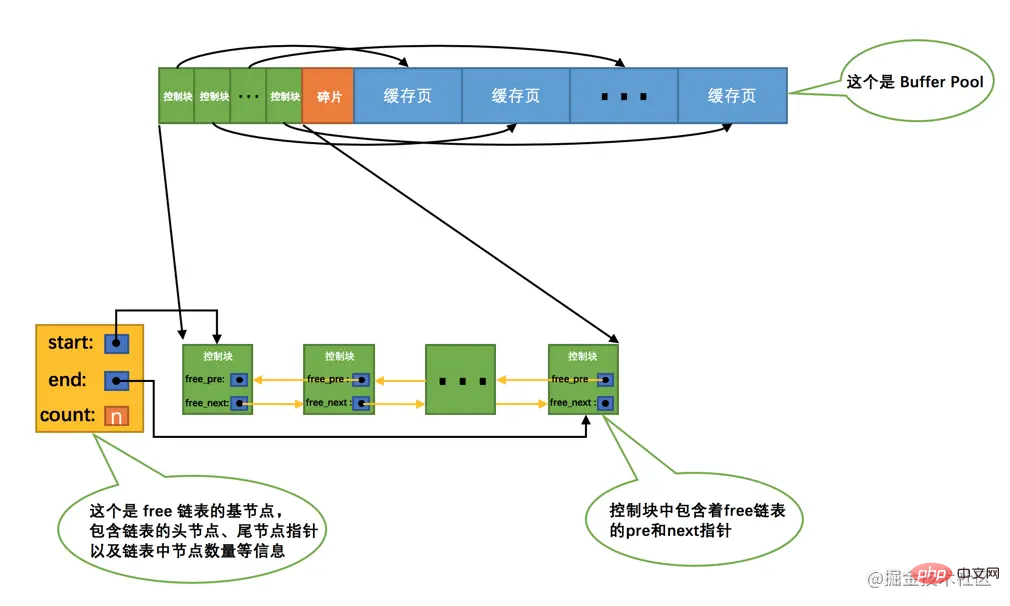
Seperti yang dapat dilihat dari gambar, untuk menguruskan free链表 ini, kami mencipta ini secara khas senarai terpaut A 基节点 ditakrifkan, yang mengandungi maklumat seperti alamat nod kepala, alamat nod ekor dan bilangan nod dalam senarai terpaut semasa. Apa yang perlu diperhatikan di sini ialah ruang memori yang diduduki oleh nod asas senarai terpaut tidak termasuk dalam ruang memori berterusan besar yang digunakan untuk Buffer Pool, tetapi sekeping ruang memori yang berasingan digunakan.
Petua: Ruang memori yang diduduki oleh nod asas senarai terpaut tidak besar Dalam versi MySQL5.7.21, setiap nod asas hanya menduduki 40 bait. Kami akan memperkenalkan banyak senarai terpaut yang berbeza kemudian. Kaedah peruntukan memori nod asas mereka dan nod asas senarai terpaut percuma semuanya digunakan secara berasingan untuk ruang memori 40-bait, yang tidak termasuk dalam aplikasi untuk Kolam Penampan dalam ruang memori bersebelahan yang besar.
Dengan ini free链表, segalanya akan menjadi lebih mudah Setiap kali halaman perlu dimuatkan dari cakera ke dalam Buffer Pool, cache percuma akan diambil dari halaman free链表 dan isikan. maklumat 控制块 yang sepadan dengan halaman cache (iaitu, ruang jadual di mana halaman itu terletak, nombor halaman dan maklumat lain), dan kemudian alih keluar nod free链表 yang sepadan dengan halaman cache daripada senarai terpaut halaman cache telah digunakan~
Kami berkata sebelum ini apabila kami perlu mengakses data dalam halaman tertentu, Halaman itu akan dimuatkan dari cakera ke dalam Buffer Pool jika halaman sudah berada dalam Buffer Pool, anda boleh menggunakannya secara langsung. Kemudian timbul persoalan, bagaimana kita tahu sama ada halaman itu berada dalam Buffer Pool? Adakah perlu untuk merentasi setiap halaman cache dalam Buffer Pool dalam urutan? Tidakkah meletihkan untuk merentasi begitu banyak halaman cache dalam satu Buffer Pool?
Mengimbas kembali, kami sebenarnya meletakkan halaman berdasarkan 表空间号 页号, yang bermaksud bahawa 表空间号 页号 ialah key dan 缓存页 yang sepadan dengan value Bagaimana pula dengan cepat mencari key? Haha, itu mesti jadual hash~value
Petua: Apa? Jangan beritahu saya anda tidak tahu apa itu jadual hash? Artikel kami bukan tentang jadual cincang Jika anda tidak tahu cara melakukannya, cari buku tentang struktur data dan baca ~ Apa? Tidakkah anda boleh membaca buku di luar? Jangan risau, tunggu saya ~Jadi kita boleh menggunakan
sebagai 表空间号 页号, key sebagai 缓存页 untuk mencipta jadual cincang, apabila kita perlu mengakses data daripada halaman tertentu, Mula-mula, semak sama ada terdapat halaman cache yang sepadan mengikut value dalam jadual cincang Jika ada, hanya gunakan halaman cache secara terus Jika tidak, kemudian pilih halaman cache percuma daripada 表空间号 页号 dan kemudian simpan ke cakera Halaman yang sepadan dimuatkan ke lokasi halaman cache. free链表
Jika kami mengubah suai data halaman cache dalam Buffer Pool, maka ia akan menjadi tidak konsisten dengan halaman pada cakera dan cache sedemikian halaman juga akan Dikenali sebagai 脏页 (nama Inggeris: dirty page). Sudah tentu, cara paling mudah ialah menyegerakkannya ke halaman yang sepadan pada cakera dengan serta-merta setiap kali pengubahsuaian berlaku, tetapi kerap menulis data ke cakera akan menjejaskan prestasi program dengan serius (lagipun, cakera adalah perlahan seperti penyu). Jadi setiap kali kami mengubah suai halaman cache, kami tidak tergesa-gesa untuk menyegerakkan pengubahsuaian pada cakera dengan segera, tetapi menyegerakkannya pada titik tertentu pada masa hadapan Bagi titik masa penyegerakan ini, kami akan menerangkannya kemudian, jadi jangan 'Jangan risau sekarang. Ha~
Tetapi jika ia tidak disegerakkan ke cakera dengan segera, bagaimana kita tahu halaman mana dalam Buffer Pool adalah 脏页 dan halaman mana yang tidak pernah diubah suai semasa menyegerakkan lagi nanti? Anda tidak boleh menyegerakkan semua halaman cache ke cakera Jika Buffer Pool ditetapkan kepada saiz yang besar, seperti 300G, maka menyegerakkan begitu banyak data sekaligus akan menjadi sangat perlahan! Oleh itu, kita perlu mencipta satu lagi senarai terpaut untuk menyimpan halaman kotor Blok kawalan yang sepadan dengan halaman cache yang diubah suai akan ditambahkan pada senarai terpaut sebagai nod, kerana halaman cache yang sepadan dengan nod senarai terpaut perlu dimuat semula ke dalam. cakera. , jadi ia juga dipanggil flush链表. Struktur senarai terpaut adalah serupa dengan free链表 Anggapkan bahawa bilangan halaman kotor dalam Buffer Pool pada masa tertentu ialah n, maka flush链表 yang sepadan kelihatan seperti ini:
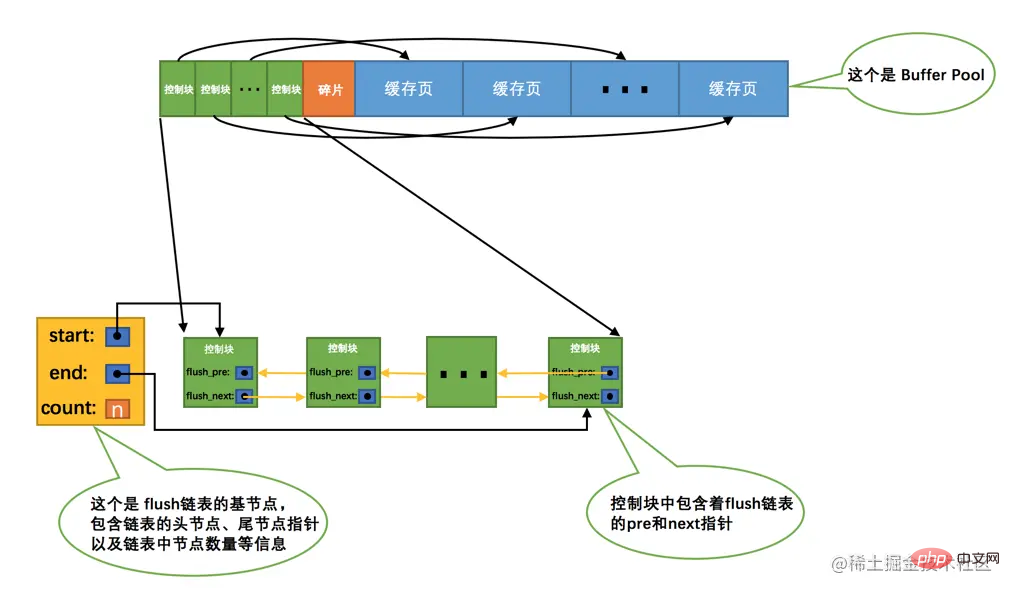
Dilema cache yang tidak mencukupi
Buffer PoolSaiz memori yang sepadan adalah terhad jika saiz memori diduduki oleh halaman yang perlu dicache melebihi saiz Buffer Pool, Iaitu, tidakkah memalukan apabila tiada lagi halaman cache percuma dalam free链表 Apakah yang perlu kita lakukan jika ini berlaku? Sudah tentu, beberapa halaman cache lama dialih keluar daripada Buffer Pool, dan kemudian halaman baharu dimasukkan ke dalam~ Jadi persoalannya, halaman cache yang manakah harus dialih keluar?
Untuk menjawab soalan ini, kami juga perlu kembali kepada niat asal untuk menyediakan Buffer Pool Kami hanya mahu mengurangkan interaksi IO dengan cakera telah dikemas kini setiap kali apabila halaman diakses dalam Buffer Pool. Anggapkan bahawa kami telah melawat halaman n secara keseluruhan, maka bilangan kali halaman yang dilawati telah berada dalam cache dibahagikan dengan n adalah apa yang dipanggil 缓存命中率 jangkaan kami adalah untuk menjadikan 缓存命中率 itu lebih tinggi lebih baik~ Dari perspektif ini Mari kita mulakan dan fikirkan kembali senarai sembang WeChat kami Yang di atas adalah yang sering digunakan baru-baru ini, dan yang di belakang adalah yang jarang digunakan baru-baru ini. Jika senarai hanya boleh memuatkan bilangan kenalan yang terhad, anda akan meletakkan kenalan yang telah digunakan baru-baru ini dengan sangat kerap Adakah saya perlu menyimpan kenalan yang kerap digunakan atau yang jarang digunakan baru-baru ini? Tidak masuk akal, sudah tentu saya meninggalkan yang sering digunakan baru-baru ini ~
Senarai terpaut LRU yang mudah
menguruskan halaman cache Buffer Pool atas sebab yang sama tiada lagi ruang kosong dalam Buffer Pool Apabila halaman cache dicache, adalah perlu untuk menghapuskan beberapa halaman cache yang jarang digunakan baru-baru ini. Walau bagaimanapun, bagaimanakah kita mengetahui halaman cache yang sering digunakan baru-baru ini dan yang mana yang jarang digunakan? Haha, senarai terpaut ajaib berguna sekali lagi. daripada LRU). : Paling Kurang Digunakan Baru-baru ini). Apabila kita perlu mengakses halaman tertentu, kita boleh mengendalikan 按照最近最少使用 seperti ini: LRU链表LRU链表
Apabila caching halaman, Buffer Pool yang sepadan dengan halaman cache dimasukkan ke dalam kepala senarai terpaut sebagai nod. Buffer Pool控制块
halaman yang sepadan ke kepala Buffer Pool. 控制块LRU链表
ialah Halaman cache yang paling tidak digunakan baru-baru ini ~ Jadi apabila halaman cache percuma dalam LRU链表 habis, pergi sahaja ke penghujung LRU链表 dan cari beberapa halaman cache untuk dihapuskan Ia sangat mudah, tsk...Buffer PoolLRU链表 Senarai dipautkan LRU bagi kawasan yang dibahagikan
Masih terlalu awal untuk bergembira
yang mudah di atas menemui masalah tidak lama selepas menggunakannya, kerana terdapat dua situasi yang memalukan:Situasi 1: InnoDB menyediakan perkhidmatan yang kelihatan bertimbang rasa - 预读 (nama Inggeris: read ahead). Apa yang dipanggil 预读 bermakna InnoDB berpendapat bahawa halaman tertentu mungkin dibaca selepas melaksanakan permintaan semasa, jadi ia memuatkannya ke dalam Buffer Pool lebih awal. Mengikut kaedah pencetus yang berbeza, 预读 boleh dibahagikan kepada dua jenis berikut:
Prabacaan linear
Pakcik yang mereka bentuk InnoDB menyediakan sistem pembolehubah innodb_read_ahead_threshold, jika akses berjujukan ke halaman dalam kawasan tertentu (extent) melebihi nilai pembolehubah sistem ini, permintaan 异步 untuk membaca semua halaman di kawasan seterusnya hingga Buffer Pool akan dicetuskan. Ambil perhatian bahawa 异步Membaca bermakna memuatkan halaman prabaca ini daripada cakera tidak akan menjejaskan pelaksanaan biasa urutan pekerja semasa. Nilai innodb_read_ahead_threshold pembolehubah sistem ini menjadi lalai kepada 56 Kami boleh melaraskan secara langsung nilai pembolehubah sistem ini melalui parameter permulaan apabila pelayan bermula atau semasa pelayan berjalan Walau bagaimanapun, sila gunakan SET GLOBAL perintah untuk melaraskannya.
Petua: Bagaimanakah InnoDB melaksanakan bacaan tak segerak? Pada platform Windows atau Linux, anda boleh menghubungi terus antara muka AIO yang disediakan oleh kernel sistem pengendalian Dalam sistem pengendalian seperti Unix yang lain, kaedah simulasi antara muka AIO digunakan untuk mencapai bacaan tak segerak untuk membiarkan utas lain membaca Dapatkan halaman yang perlu dibaca lebih awal. Jika anda tidak memahami perenggan di atas, maka tidak perlu memahaminya. Ia tiada kaitan dengan topik kami Anda hanya perlu tahu bahawa bacaan tak segerak tidak akan menjejaskan pelaksanaan biasa utas kerja semasa. Sebenarnya, proses ini melibatkan cara sistem pengendalian mengendalikan isu IO dan berbilang benang. Cari buku tentang sistem pengendalian dan bacanya. Adakah penulisan sistem pengendalian sukar difahami? Tidak mengapa, tunggu saya ~
prabacaan rawak
Jika 13 halaman berturut-turut di kawasan tertentu telah di-cache dalam Buffer Pool, tanpa mengira halaman ini Sama ada ia dibaca secara berurutan atau tidak, ia akan mencetuskan permintaan 异步 untuk membaca semua halaman di kawasan ini ke Buffer Pool. Pakcik yang mereka InnoDB juga menyediakan innodb_random_read_ahead pembolehubah sistem nilai lalainya ialah OFF, yang bermaksud InnoDB tidak mendayakan prabacaan rawak secara lalai Tetapkan nilai pembolehubah ini kepada SET GLOBAL dengan mengubah suai parameter permulaan atau terus menggunakan perintah ON.
预读 pada asalnya adalah perkara yang baik Jika halaman yang dibaca dalam Buffer Pool berjaya digunakan, ia boleh meningkatkan kecekapan pelaksanaan pernyataan. Tetapi bagaimana jika ia tidak digunakan? Halaman prabaca ini akan diletakkan di kepala senarai terpaut LRU, tetapi jika kapasiti Buffer Pool tidak besar pada masa ini dan banyak halaman prabaca tidak digunakan, ini akan menyebabkan berada di ekor LRU链表 Beberapa halaman cache akan dihapuskan dengan cepat, juga dikenali sebagai 劣币驱逐良币, yang akan mengurangkan kadar hit cache dengan banyak.
Situasi 2: Sesetengah rakan mungkin menulis beberapa pernyataan pertanyaan yang perlu mengimbas keseluruhan jadual (seperti pertanyaan yang tidak mencipta indeks yang sesuai atau tidak mempunyai klausa WHERE sama sekali).
Apakah maksud mengimbas keseluruhan jadual? Ini bermakna semua halaman di mana jadual terletak akan diakses! Dengan mengandaikan bahawa terdapat banyak rekod dalam jadual ini, jadual akan menduduki banyak 页 Apabila halaman ini perlu diakses, semuanya akan dimuatkan ke dalam Buffer Pool, yang bermaksud, klik, telah diganti sekali, dan pernyataan pertanyaan lain perlu dimuatkan dari cakera ke Buffer Pool apabila dilaksanakan. Kekerapan pelaksanaan penyataan imbasan jadual penuh jenis ini tidak tinggi Setiap kali ia dilaksanakan, halaman cache dalam Buffer Pool mesti diganti dengan serius ini menjejaskan penggunaan Buffer Pool oleh pertanyaan lain, sekali gus mengurangkan masa diperlukan. Buffer Pool
: Buffer Pool
mungkin tidak semestinya digunakan. Buffer Pool
pada masa yang sama, halaman yang mempunyai kekerapan penggunaan yang sangat tinggi itu boleh disingkirkan daripada Buffer Pool. Buffer Pool
membahagikan InnoDB ini kepada dua bahagian mengikut kadar tertentu iaitu: LRU链表
, atau 热数据. young区域
, atau 冷数据. old区域
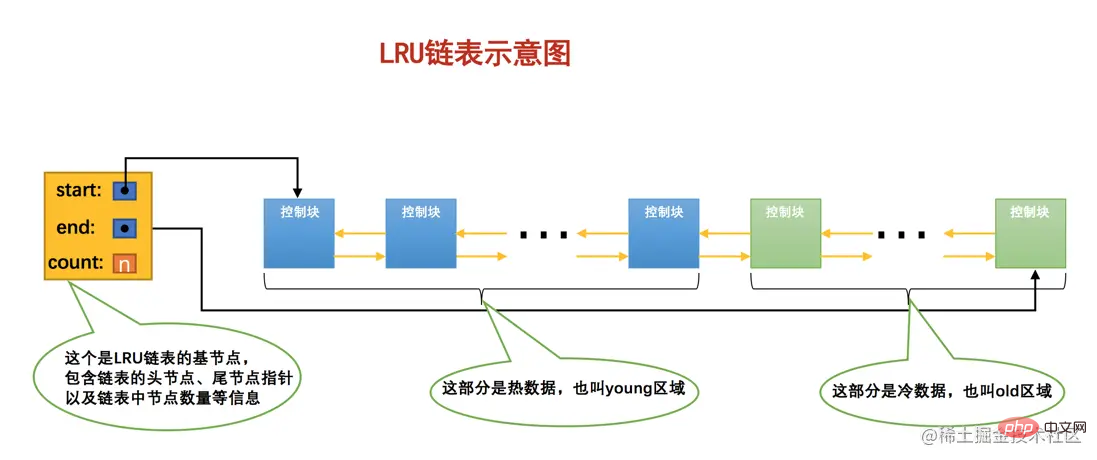
大家要特别注意一个事儿:我们是按照某个比例将LRU链表分成两半的,不是某些节点固定是young区域的,某些节点固定是old区域的,随着程序的运行,某个节点所属的区域也可能发生变化。那这个划分成两截的比例怎么确定呢?对于InnoDB存储引擎来说,我们可以通过查看系统变量innodb_old_blocks_pct的值来确定old区域在LRU链表中所占的比例,比方说这样:
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_pct'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_old_blocks_pct | 37 | +-----------------------+-------+ 1 row in set (0.01 sec)
从结果可以看出来,默认情况下,old区域在LRU链表中所占的比例是37%,也就是说old区域大约占LRU链表的3/8。这个比例我们是可以设置的,我们可以在启动时修改innodb_old_blocks_pct参数来控制old区域在LRU链表中所占的比例,比方说这样修改配置文件:
[server] innodb_old_blocks_pct = 40
这样我们在启动服务器后,old区域占LRU链表的比例就是40%。当然,如果在服务器运行期间,我们也可以修改这个系统变量的值,不过需要注意的是,这个系统变量属于全局变量,一经修改,会对所有客户端生效,所以我们只能这样修改:
SET GLOBAL innodb_old_blocks_pct = 40;
有了这个被划分成young和old区域的LRU链表之后,设计InnoDB的大叔就可以针对我们上边提到的两种可能降低缓存命中率的情况进行优化了:
针对预读的页面可能不进行后续访问情况的优化
设计InnoDB的大叔规定,当磁盘上的某个页面在初次加载到Buffer Pool中的某个缓存页时,该缓存页对应的控制块会被放到old区域的头部。这样针对预读到Buffer Pool却不进行后续访问的页面就会被逐渐从old区域逐出,而不会影响young区域中被使用比较频繁的缓存页。
针对全表扫描时,短时间内访问大量使用频率非常低的页面情况的优化
在进行全表扫描时,虽然首次被加载到Buffer Pool的页被放到了old区域的头部,但是后续会被马上访问到,每次进行访问的时候又会把该页放到young区域的头部,这样仍然会把那些使用频率比较高的页面给顶下去。有同学会想:可不可以在第一次访问该页面时不将其从old区域移动到young区域的头部,后续访问时再将其移动到young区域的头部。回答是:行不通!因为设计InnoDB的大叔规定每次去页面中读取一条记录时,都算是访问一次页面,而一个页面中可能会包含很多条记录,也就是说读取完某个页面的记录就相当于访问了这个页面好多次。
咋办?全表扫描有一个特点,那就是它的执行频率非常低,谁也不会没事儿老在那写全表扫描的语句玩,而且在执行全表扫描的过程中,即使某个页面中有很多条记录,也就是去多次访问这个页面所花费的时间也是非常少的。所以我们只需要规定,在对某个处在old区域的缓存页进行第一次访问时就在它对应的控制块中记录下来这个访问时间,如果后续的访问时间与第一次访问的时间在某个时间间隔内,那么该页面就不会被从old区域移动到young区域的头部,否则将它移动到young区域的头部。上述的这个间隔时间是由系统变量innodb_old_blocks_time控制的,你看:
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_time'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | innodb_old_blocks_time | 1000 | +------------------------+-------+ 1 row in set (0.01 sec)
这个innodb_old_blocks_time的默认值是1000,它的单位是毫秒,也就意味着对于从磁盘上被加载到LRU链表的old区域的某个页来说,如果第一次和最后一次访问该页面的时间间隔小于1s(很明显在一次全表扫描的过程中,多次访问一个页面中的时间不会超过1s),那么该页是不会被加入到young区域的~ 当然,像innodb_old_blocks_pct一样,我们也可以在服务器启动或运行时设置innodb_old_blocks_time的值,这里就不赘述了,你自己试试吧~ 这里需要注意的是,如果我们把innodb_old_blocks_time的值设置为0,那么每次我们访问一个页面时就会把该页面放到young区域的头部。
Ringkasnya, ia adalah tepat kerana senarai terpaut LRU dibahagikan kepada dua bahagian: kawasan young dan old, dan pembolehubah sistem innodb_old_blocks_time ditambah, mekanisme prabacaan dan jadual penuh imbasan didayakan Masalah kadar capan cache yang dikurangkan ditindas, kerana halaman baca hadapan yang tidak digunakan dan halaman imbasan jadual penuh hanya akan diletakkan dalam kawasan old, tanpa menjejaskan halaman cache dalam kawasan young.
Optimumkan lagi senarai terpaut LRU
LRU链表Adakah ini sahaja? Tidak, masih awal~ Untuk halaman cache di kawasan young, setiap kali kita mengakses halaman cache, kita perlu mengalihkannya ke kepala LRU链表 Lagipun, bukankah ini terlalu mahal? 🎜> kawasan Halaman yang dicache adalah semua data panas, iaitu, ia mungkin kerap diakses. Bukankah buruk untuk melakukan operasi pergerakan nod pada young dengan begitu kerap? Ya, untuk menyelesaikan masalah ini, kami sebenarnya boleh mencadangkan beberapa strategi pengoptimuman Contohnya, hanya halaman cache yang diakses yang terletak di belakang LRU链表 dalam kawasan young akan dialihkan ke pengepala 1/4, yang boleh mengurangkan. Laraskan kekerapan LRU链表 untuk meningkatkan prestasi (iaitu, jika nod yang sepadan dengan halaman cache berada dalam LRU链表 dalam kawasan young, ia tidak akan dialihkan ke senarai terpaut 1/4 apabila halaman cache diakses semula kepala). LRU
Petua: Apabila kami memperkenalkan prabacaan rawak sebelum ini, kami berkata bahawa jika terdapat 13 halaman berturut-turut di kawasan tertentu dalam Buffer Pool, prabacaan rawak akan dicetuskan ketat. (Malangnya, inilah yang dikatakan oleh dokumentasi MySQL [tunjuk tangan] Malah, 13 halaman ini juga diperlukan untuk menjadi halaman yang sangat panas merujuk kepada halaman ini berada di 1/4 pertama daripada keseluruhan kawasan muda.Adakah terdapat sebarang langkah pengoptimuman lain untuk
? Memanglah ada kalau belajar bersungguh-sungguh takde masalah nak tulis kertas atau buku Tapi lagipun ini artikel yang memperkenalkan ilmu asas kalau terlalu panjang memang tak boleh tahan juga akan mempengaruhi pengalaman membaca semua orang. Jadi itu sudah cukup jika anda ingin mengetahui lebih banyak pengetahuan pengoptimuman, pergi ke kod sumber sendiri atau ketahui lebih lanjut tentang LRU链表 senarai terpaut~ Tetapi tidak kira bagaimana anda mengoptimumkan, jangan lupa niat asal kami. : untuk menambah baik MySQLKadar serangan cache Kolam PenampanLRU. Beberapa senarai terpaut lain
, seperti Buffer Pool digunakan untuk mengurus halaman yang dinyahmampat, InnoDB digunakan untuk mengurus halaman mampat yang belum dinyahmampat, setiap elemen dalam 链表 mewakili senarai terpaut, dan ia membentuk apa yang dipanggil unzip LRU链表 untuk pemampatan Halaman ini menyediakan ruang memori, dsb. Bagaimanapun, untuk mengurus ini dengan lebih baik zip clean链表 telah memperkenalkan pelbagai senarai terpaut atau struktur data lain Kaedah penggunaan khusus tidak akan membosankan jika anda berminat untuk mempelajari lebih lanjut , anda boleh menemui beberapa buku yang lebih mendalam atau Lihat sahaja kod sumber, atau anda boleh datang kepada saya terus ~ zip free数组伙伴系统Buffer Pool Petua: Kami belum bercakap tentang halaman mampatan dalam InnoDB secara mendalam di semua, dan senarai yang dipautkan di atas hanyalah untuk kesempurnaan Seks Dengan cara ini, jangan tertekan jika anda tidak dapat memahaminya, kerana saya tidak berniat untuk memperkenalkannya kepada anda langsung.
Terdapat benang khusus di latar belakang yang bertanggungjawab untuk menyegarkan halaman kotor ke cakera sekali-sekala, supaya ia tidak menjejaskan pemprosesan permintaan biasa oleh benang pengguna. Terdapat dua laluan muat semula utama: menyegarkan sebahagian halaman daripadaMuat semula halaman kotor ke cakera
Benang latar belakang akan mengimbas beberapa halaman secara berkala bermula dari akhir LRU链表 Bilangan halaman yang diimbas boleh ditentukan melalui pembolehubah sistem
. LRU链表innodb_lru_scan_depthBUF_FLUSH_LRU
Benang latar belakang juga akan memuat semula beberapa halaman secara berkala dari flush链表 ke cakera Kadar muat semula bergantung pada sama ada sistem sangat sibuk pada masa itu. Cara menyegarkan halaman ini dipanggil
flush链表BUF_FLUSH_LIST
perlu disiram ke cakera secara serentak (interaksi dengan cakera adalah sangat. perlahan, yang akan melambatkan pemprosesan permintaan pengguna) kelajuan). Kaedah menyegarkan satu halaman ke cakera ini dipanggil Buffer Pool. LRU链表
当然,有时候系统特别繁忙时,也可能出现用户线程批量的从flush链表中刷新脏页的情况,很显然在处理用户请求过程中去刷新脏页是一种严重降低处理速度的行为(毕竟磁盘的速度慢的要死),这属于一种迫不得已的情况,不过这得放在后边唠叨redo日志的checkpoint时说了。
我们上边说过,Buffer Pool本质是InnoDB向操作系统申请的一块连续的内存空间,在多线程环境下,访问Buffer Pool中的各种链表都需要加锁处理啥的,在Buffer Pool特别大而且多线程并发访问特别高的情况下,单一的Buffer Pool可能会影响请求的处理速度。所以在Buffer Pool特别大的时候,我们可以把它们拆分成若干个小的Buffer Pool,每个Buffer Pool都称为一个实例,它们都是独立的,独立的去申请内存空间,独立的管理各种链表,独立的吧啦吧啦,所以在多线程并发访问时并不会相互影响,从而提高并发处理能力。我们可以在服务器启动的时候通过设置innodb_buffer_pool_instances的值来修改Buffer Pool实例的个数,比方说这样:
[server] innodb_buffer_pool_instances = 2
这样就表明我们要创建2个Buffer Pool实例,示意图就是这样:
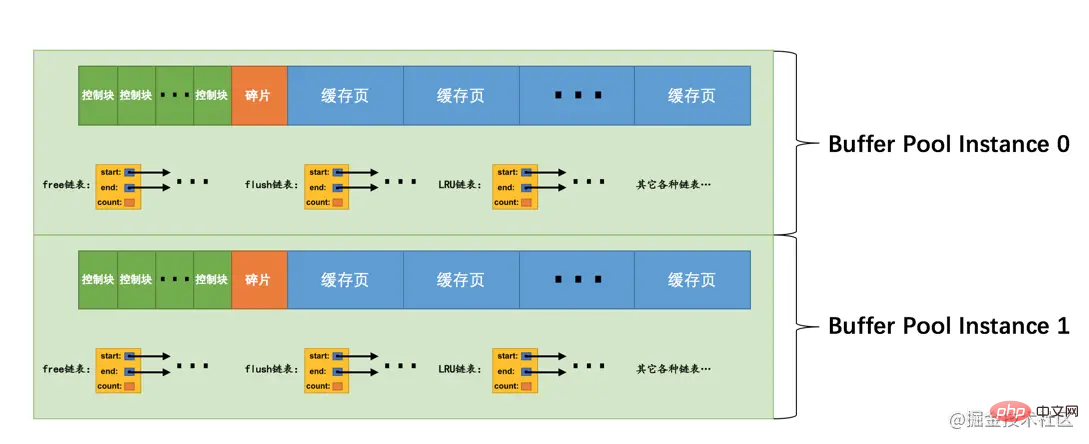
小贴士: 为了简便,我只把各个链表的基节点画出来了,大家应该心里清楚这些链表的节点其实就是每个缓存页对应的控制块!
那每个Buffer Pool实例实际占多少内存空间呢?其实使用这个公式算出来的:
innodb_buffer_pool_size/innodb_buffer_pool_instances
也就是总共的大小除以实例的个数,结果就是每个Buffer Pool实例占用的大小。
不过也不是说Buffer Pool实例创建的越多越好,分别管理各个Buffer Pool也是需要性能开销的,设计InnoDB的大叔们规定:当innodb_buffer_pool_size的值小于1G的时候设置多个实例是无效的,InnoDB会默认把innodb_buffer_pool_instances 的值修改为1。而我们鼓励在Buffer Pool大于或等于1G的时候设置多个Buffer Pool实例。
在MySQL 5.7.5之前,Buffer Pool的大小只能在服务器启动时通过配置innodb_buffer_pool_size启动参数来调整大小,在服务器运行过程中是不允许调整该值的。不过设计MySQL的大叔在5.7.5以及之后的版本中支持了在服务器运行过程中调整Buffer Pool大小的功能,但是有一个问题,就是每次当我们要重新调整Buffer Pool大小时,都需要重新向操作系统申请一块连续的内存空间,然后将旧的Buffer Pool中的内容复制到这一块新空间,这是极其耗时的。所以设计MySQL的大叔们决定不再一次性为某个Buffer Pool实例向操作系统申请一大片连续的内存空间,而是以一个所谓的chunk为单位向操作系统申请空间。也就是说一个Buffer Pool实例其实是由若干个chunk组成的,一个chunk就代表一片连续的内存空间,里边儿包含了若干缓存页与其对应的控制块,画个图表示就是这样:
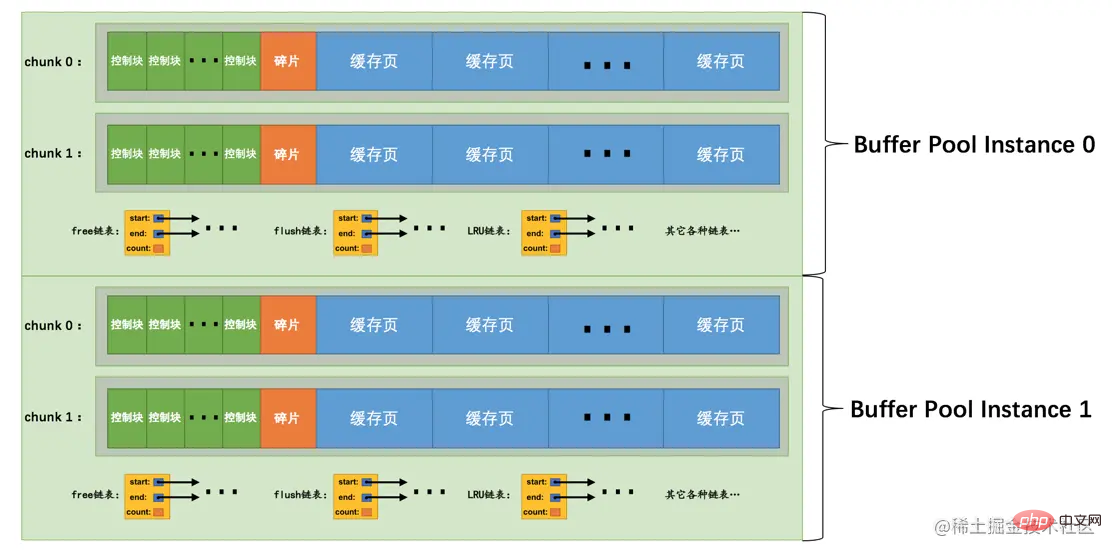
上图代表的Buffer Pool就是由2个实例组成的,每个实例中又包含2个chunk。
正是因为发明了这个chunk的概念,我们在服务器运行期间调整Buffer Pool的大小时就是以chunk为单位增加或者删除内存空间,而不需要重新向操作系统申请一片大的内存,然后进行缓存页的复制。这个所谓的chunk的大小是我们在启动操作MySQL服务器时通过innodb_buffer_pool_chunk_size启动参数指定的,它的默认值是134217728,也就是128M。不过需要注意的是,innodb_buffer_pool_chunk_size的值只能在服务器启动时指定,在服务器运行过程中是不可以修改的。
小贴士: 为什么不允许在服务器运行过程中修改innodb_buffer_pool_chunk_size的值?还不是因为innodb_buffer_pool_chunk_size的值代表InnoDB向操作系统申请的一片连续的内存空间的大小,如果你在服务器运行过程中修改了该值,就意味着要重新向操作系统申请连续的内存空间并且将原先的缓存页和它们对应的控制块复制到这个新的内存空间中,这是十分耗时的操作! 另外,这个innodb_buffer_pool_chunk_size的值并不包含缓存页对应的控制块的内存空间大小,所以实际上InnoDB向操作系统申请连续内存空间时,每个chunk的大小要比innodb_buffer_pool_chunk_size的值大一些,约5%。
innodb_buffer_pool_size必须是innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的倍数(这主要是想保证每一个Buffer Pool实例中包含的chunk数量相同)。
假设我们指定的innodb_buffer_pool_chunk_size的值是128M,innodb_buffer_pool_instances的值是16,那么这两个值的乘积就是2G,也就是说innodb_buffer_pool_size的值必须是2G或者2G的整数倍。比方说我们在启动MySQL服务器是这样指定启动参数的:
mysqld --innodb-buffer-pool-size=8G --innodb-buffer-pool-instances=16
默认的innodb_buffer_pool_chunk_size值是128M,指定的innodb_buffer_pool_instances的值是16,所以innodb_buffer_pool_size的值必须是2G或者2G的整数倍,上边例子中指定的innodb_buffer_pool_size的值是8G,符合规定,所以在服务器启动完成之后我们查看一下该变量的值就是我们指定的8G(8589934592字节):
mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+------------+ | Variable_name | Value | +-------------------------+------------+ | innodb_buffer_pool_size | 8589934592 | +-------------------------+------------+ 1 row in set (0.00 sec)
如果我们指定的innodb_buffer_pool_size大于2G并且不是2G的整数倍,那么服务器会自动的把innodb_buffer_pool_size的值调整为2G的整数倍,比方说我们在启动服务器时指定的innodb_buffer_pool_size的值是9G:
mysqld --innodb-buffer-pool-size=9G --innodb-buffer-pool-instances=16
那么服务器会自动把innodb_buffer_pool_size的值调整为10G(10737418240字节),不信你看:
mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+-------------+ | Variable_name | Value | +-------------------------+-------------+ | innodb_buffer_pool_size | 10737418240 | +-------------------------+-------------+ 1 row in set (0.01 sec)
如果在服务器启动时,innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的值已经大于innodb_buffer_pool_size的值,那么innodb_buffer_pool_chunk_size的值会被服务器自动设置为innodb_buffer_pool_size/innodb_buffer_pool_instances的值。
比方说我们在启动服务器时指定的innodb_buffer_pool_size的值为2G,innodb_buffer_pool_instances的值为16,innodb_buffer_pool_chunk_size的值为256M:
mysqld --innodb-buffer-pool-size=2G --innodb-buffer-pool-instances=16 --innodb-buffer-pool-chunk-size=256M
由于256M × 16 = 4G,而4G > 2G,所以innodb_buffer_pool_chunk_size值会被服务器改写为innodb_buffer_pool_size/innodb_buffer_pool_instances的值,也就是:2G/16 = 128M(134217728字节),不信你看:
mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+------------+ | Variable_name | Value | +-------------------------+------------+ | innodb_buffer_pool_size | 2147483648 | +-------------------------+------------+ 1 row in set (0.01 sec) mysql> show variables like 'innodb_buffer_pool_chunk_size'; +-------------------------------+-----------+ | Variable_name | Value | +-------------------------------+-----------+ | innodb_buffer_pool_chunk_size | 134217728 | +-------------------------------+-----------+ 1 row in set (0.00 sec)
Buffer Pool的缓存页除了用来缓存磁盘上的页面以外,还可以存储锁信息、自适应哈希索引等信息,这些内容等我们之后遇到了再详细讨论哈~
设计MySQL的大叔贴心的给我们提供了SHOW ENGINE INNODB STATUS语句来查看关于InnoDB存储引擎运行过程中的一些状态信息,其中就包括Buffer Pool的一些信息,我们看一下(为了突出重点,我们只把输出中关于Buffer Pool的部分提取了出来):
mysql> SHOW ENGINE INNODB STATUS\G (...省略前边的许多状态) ---------------------- BUFFER POOL AND MEMORY ---------------------- Total memory allocated 13218349056; Dictionary memory allocated 4014231 Buffer pool size 786432 Free buffers 8174 Database pages 710576 Old database pages 262143 Modified db pages 124941 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 6195930012, not young 78247510485 108.18 youngs/s, 226.15 non-youngs/s Pages read 2748866728, created 29217873, written 4845680877 160.77 reads/s, 3.80 creates/s, 190.16 writes/s Buffer pool hit rate 956 / 1000, young-making rate 30 / 1000 not 605 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 710576, unzip_LRU len: 118 I/O sum[134264]:cur[144], unzip sum[16]:cur[0] -------------- (...省略后边的许多状态) mysql>
我们来详细看一下这里边的每个值都代表什么意思:
Total memory allocated:代表Buffer Pool向操作系统申请的连续内存空间大小,包括全部控制块、缓存页、以及碎片的大小。
Dictionary memory allocated:为数据字典信息分配的内存空间大小,注意这个内存空间和Buffer Pool没啥关系,不包括在Total memory allocated中。
Buffer pool size:代表该Buffer Pool可以容纳多少缓存页,注意,单位是页!
Free buffers:代表当前Buffer Pool还有多少空闲缓存页,也就是free链表中还有多少个节点。
Database pages: mewakili bilangan halaman dalam senarai terpaut LRU, termasuk bilangan nod dalam kawasan young dan old.
Old database pages: mewakili bilangan nod dalam kawasan LRU senarai terpaut old.
Modified db pages: mewakili bilangan halaman kotor, iaitu bilangan nod dalam flush链表.
Pending reads: Bilangan halaman menunggu untuk dimuatkan daripada cakera ke dalam Buffer Pool.
Apabila bersedia untuk memuatkan halaman daripada cakera, ia akan memperuntukkan halaman cache dan blok kawalannya yang sepadan terlebih dahulu dalam Buffer Pool untuk halaman ini, dan kemudian menambah blok kawalan ini pada LRU's old Pengepala kawasan, tetapi halaman cakera sebenar belum dimuatkan pada masa ini, dan nilai Pending reads akan dinaikkan sebanyak 1.
Pending writes LRU: Bilangan halaman yang akan dipadamkan ke cakera daripada senarai terpaut LRU.
Pending writes flush list: Bilangan halaman yang akan dipadamkan ke cakera daripada senarai terpaut flush.
Pending writes single page: Bilangan halaman yang akan disiram ke cakera sebagai satu halaman.
Pages made young: mewakili bilangan nod dalam senarai terpaut LRU yang telah berpindah dari kawasan old ke kepala kawasan young.
Perlu diingatkan di sini bahawa setiap kali nod bergerak dari kawasan old ke kepala kawasan young, nilai Pages made young akan dinaikkan sebanyak 1. Maksudnya, jika nod pada asalnya berada di kawasan young, kerana ia memenuhi keperluan berada di belakang 1/4 daripada kawasan young, ia juga akan dialihkan ke kepala kawasan young pada kali seterusnya anda melawat halaman ini , tetapi proses ini tidak akan menghasilkan nilai Pages made young Tambah 1.
Page made not young: Apabila nilai innodb_old_blocks_time ditetapkan kepada lebih besar daripada 0, akses pertama atau akses seterusnya kepada nod dalam kawasan old tidak menepati masa Apabila ia tidak boleh dialihkan ke kepala kawasan young kerana sekatan, nilai Page made not young akan dinaikkan sebanyak 1.
Perlu diingatkan di sini bahawa untuk nod dalam kawasan young, jika ia tidak dialihkan ke kepala kawasan young kerana ia berada pada 1/4 daripada kawasan young, akses sedemikian Ia tidak meningkatkan nilai Page made not young sebanyak 1.
youngs/s: mewakili bilangan nod yang dialihkan dari kawasan old ke kepala kawasan young sesaat.
non-youngs/s: mewakili bilangan nod yang tidak boleh bergerak dari kawasan old ke kepala kawasan young sesaat kerana had masa tidak dipenuhi.
Pages read, created, written: mewakili bilangan halaman yang dibaca, dicipta dan ditulis. Diikuti dengan kadar baca, cipta, tulis.
Buffer pool hit rate: Menunjukkan berapa kali halaman telah dicache ke Buffer Pool secara purata 1000 kali dalam tempoh yang lalu.
young-making rate: Menunjukkan bahawa dalam tempoh masa tertentu pada masa lalu, halaman tersebut telah dilawati secara purata sebanyak 1,000 kali dan bilangan lawatan yang memindahkan halaman tersebut ke kepala young kawasan.
Satu perkara yang perlu diberi perhatian oleh semua orang ialah bilangan kali halaman itu dialihkan ke kepala kawasan young yang dikira di sini bukan sahaja termasuk bilangan kali ia dialihkan daripada old kawasan ke kepala kawasan young, tetapi juga dari Bilangan kali kawasan young dipindahkan ke kepala kawasan young (apabila melawat nod di kawasan young, selagi nod berada 1/4 di belakang kawasan young, ia akan dialihkan ke young kepala kawasan).
not (young-making rate): Menunjukkan bahawa dalam tempoh masa tertentu pada masa lalu, halaman itu telah dilawati secara purata sebanyak 1,000 kali dan berapa banyak lawatan yang tidak mengalihkan halaman itu ke kepala daripada kawasan young.
Satu perkara yang semua orang perlu beri perhatian ialah bilangan kali halaman tidak dialihkan ke pengepala kawasan young yang dikira di sini bukan sahaja termasuk akses ke kawasan innodb_old_blocks_time disebabkan oleh tetapan pembolehubah sistem old Bilangan kali nod tidak dialihkan ke kawasan young dan bilangan kali nod tidak dialihkan ke kepala kawasan young kerana ia berada dalam kawasan. 1/4 pertama daripada kawasan young.
LRU len: mewakili bilangan nod dalam LRU链表.
unzip_LRU: mewakili bilangan nod dalam unzip_LRU链表 (memandangkan kita belum bercakap tentang senarai terpaut ini secara khusus, nilainya boleh diabaikan buat masa ini).
I/O sum: Jumlah bilangan halaman cakera yang dibaca dalam 50 saat yang lalu.
I/O cur: Bilangan halaman cakera sedang dibaca.
I/O unzip sum: Bilangan halaman dinyahmampat dalam 50 saat terakhir.
I/O unzip cur: Bilangan halaman yang dinyahmampatkan.
磁盘太慢,用内存作为缓存很有必要。
Buffer Pool本质上是InnoDB向操作系统申请的一段连续的内存空间,可以通过innodb_buffer_pool_size来调整它的大小。
Buffer Pool向操作系统申请的连续内存由控制块和缓存页组成,每个控制块和缓存页都是一一对应的,在填充足够多的控制块和缓存页的组合后,Buffer Pool剩余的空间可能产生不够填充一组控制块和缓存页,这部分空间不能被使用,也被称为碎片。
InnoDB使用了许多链表来管理Buffer Pool。
free链表中每一个节点都代表一个空闲的缓存页,在将磁盘中的页加载到Buffer Pool时,会从free链表中寻找空闲的缓存页。
为了快速定位某个页是否被加载到Buffer Pool,使用表空间号 + 页号作为key,缓存页作为value,建立哈希表。
在Buffer Pool中被修改的页称为脏页,脏页并不是立即刷新,而是被加入到flush链表中,待之后的某个时刻同步到磁盘上。
LRU链表分为young和old两个区域,可以通过innodb_old_blocks_pct来调节old区域所占的比例。首次从磁盘上加载到Buffer Pool的页会被放到old区域的头部,在innodb_old_blocks_time间隔时间内访问该页不会把它移动到young区域头部。在Buffer Pool没有可用的空闲缓存页时,会首先淘汰掉old区域的一些页。
我们可以通过指定innodb_buffer_pool_instances来控制Buffer Pool实例的个数,每个Buffer Pool实例中都有各自独立的链表,互不干扰。
自MySQL 5.7.5版本之后,可以在服务器运行过程中调整Buffer Pool大小。每个Buffer Pool实例由若干个chunk组成,每个chunk的大小可以在服务器启动时通过启动参数调整。
可以用下边的命令查看Buffer Pool的状态信息:
SHOW ENGINE INNODB STATUS\G
推荐学习:mysql视频教程
Atas ialah kandungan terperinci Pemahaman mendalam tentang prinsip MySQL: Buffer pool (penjelasan grafik dan teks terperinci). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



