



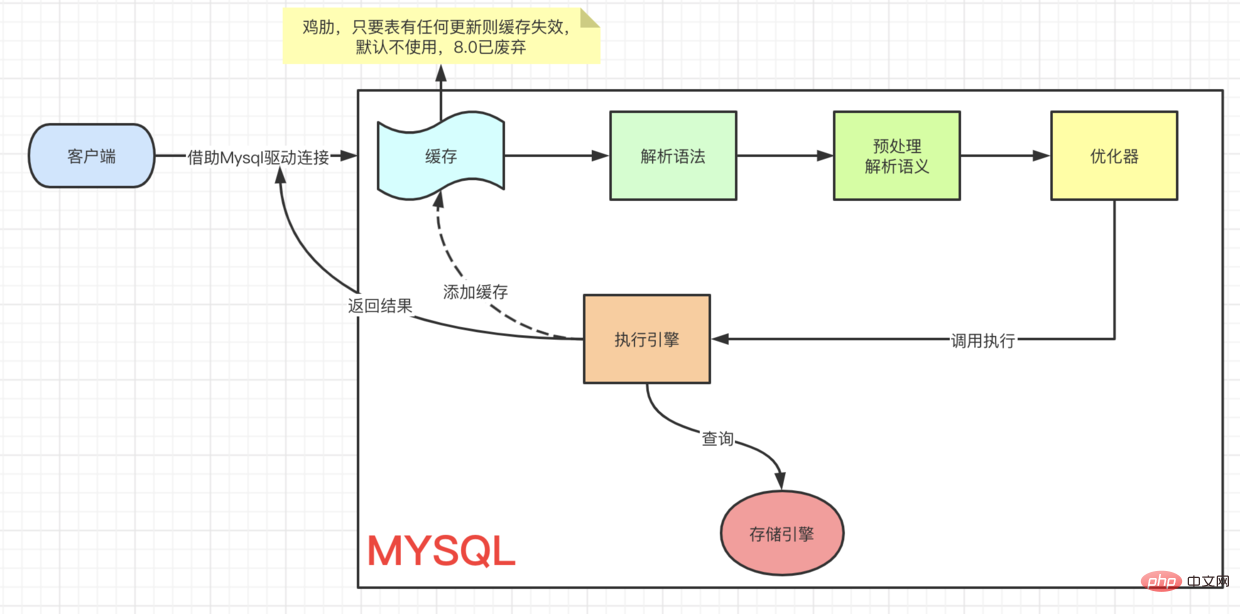
update的执行 从客户端 => ··· => 执行引擎 是一样的流程,都要先查到这条数据,然后再去更新。要想理解 UPDATE 流程我们先来看看,Innodb的架构模型。
上一张 MYSQL 官方InnoDB架构图:
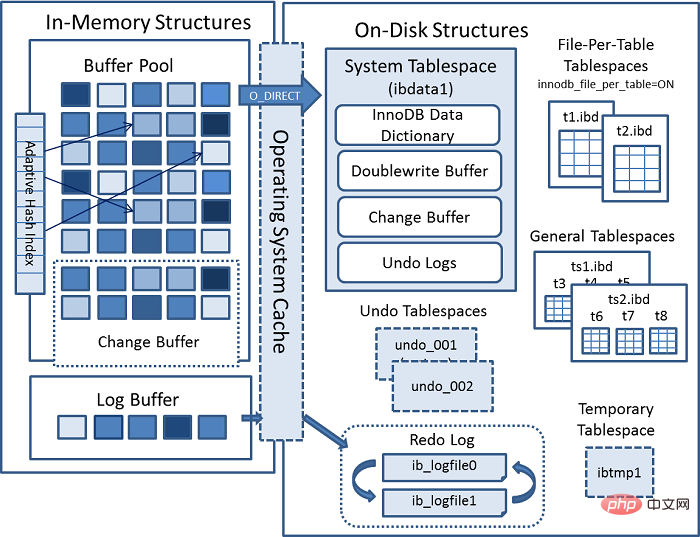
连接器(JDBC、ODBC等) =>
[MYSQL 内部
[Connection Pool] (授权、线程复用、连接限制、内存检测等) => [SQL Interface] (DML、DDL、Views等) [Parser] (Query Translation、Object privilege) [Optimizer] (Access Paths、 统计分析) [Caches & Buffers] => [Pluggable Storage Engines]复制代码
]
=> [File]
这里有个关键点,当我们去查询数据时候会先 拿着我们当前查询的 page 去 buffer pool 中查询 当前page是否在缓冲池中。如果在,则直接获取。
而如果是update操作时,则会直接修改 Buffer中的值。这个时候,buffer pool中的数据就和我们磁盘中实际存储的数据不一致了,称为脏页。每隔一段时间,Innodb存储引擎就会把脏页数据刷入磁盘。一般来说当更新一条数据,我们需要将数据给读取到buffer中修改,然后写回磁盘,完成一次 落盘IO 操作。
为了提高update的操作性能,Mysql在内存中做了优化,可以看到,在架构图的缓冲池中有一块区域叫做:change buffer。顾名思义,给change后的数据,做buffer的,当更新一个没有 unique index 的数据时,直接将修改的数据放到 change buffer,然后通过 merge 操作完成更新,从而减少了那一次 落盘的IO 操作。
没有唯一索引的数据更新时,为什么必须要没有唯一索引的数据更新时才能直接放入change buffer呢?如果是有唯一约束的字段,我们在更新数据后,可能更新的数据和已经存在的数据有重复,所以只能从磁盘中把所有数据读出来比对才能确定唯一性。写多读少 的时候,就可以通过 增加 innodb_change_buffer_max_size 来调整 change buffer在buffer pool 中所占的比例,默认25(即:25%)有四种情况:
redo log写满的时候,merge到磁盘谈到redo,就要谈到innodb的 crash safe,使用 WAL 的方式实现(write Ahead Logging,在写之前先记录日志)
这样就可以在,当数据库崩溃的后,直接从 redo log中恢复数据,保证数据的正确性
redo log 默认存储在两个文件中 ib_logfile0 ib_logfile1,这两个文件都是固定大小的。为什么需要固定大小?
这是因为redo log的 顺序读取 的特性造成的,必须是连续的存储空间
看一张图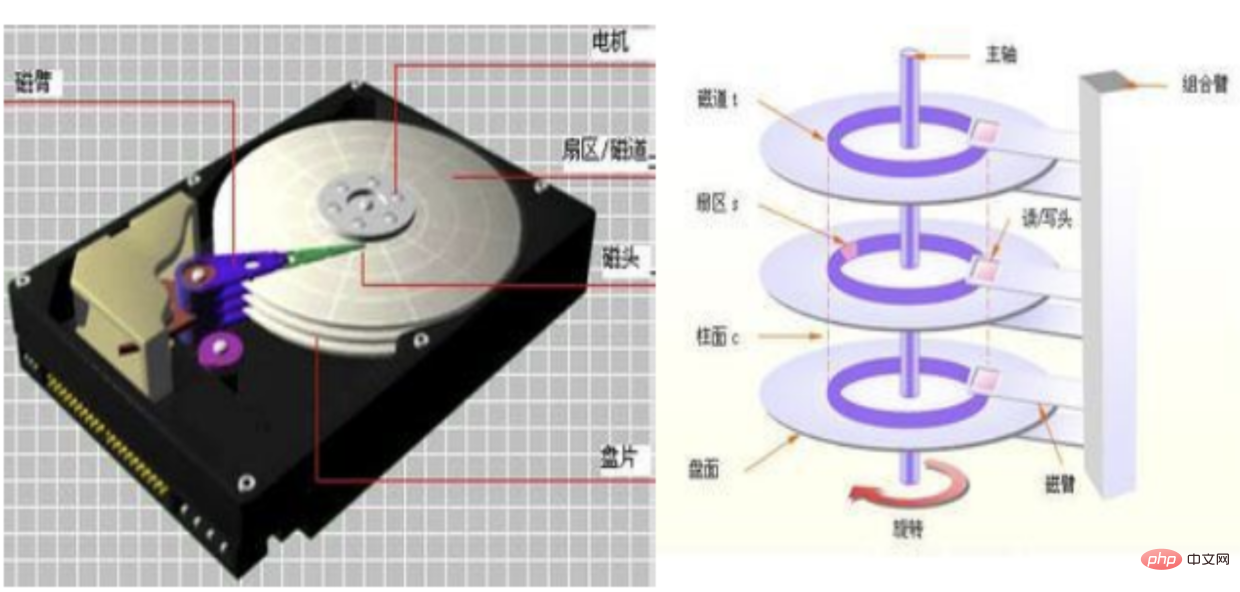
一般我们的数据都是分散在磁盘上的:
机械硬盘的读写顺序是:
固态读写:
其实不管机械还是固态,我们去存储时,都是通过文件系统与磁盘打交道的,而他们打交道的方式就有两个。随机读写和顺序读写
块(默认 1block=8扇区=4K)一串连续的块中,这样读取速度就大大提升了
看到buffer pool中的Log Buffer,其就是用来写 redo log 之前存在的缓冲区
在这里,redo log具体的执行策略有三种:
Log Buffer,只需要每秒写redo log 磁盘数据一次,性能高,但会造成数据 1s 内的一致性问题。适用于强实时性,弱一致性,比如评论区评论
Log Buffer,同时写入磁盘,性能最差,一致性最高。 适用于弱实时性,强一致性,比如支付场景
Log Buffer,同时写到os buffer(其会每秒调用 fsync 将数据刷入磁盘),性能好,安全性也高。这个是实时性适中 一致性适中的,比如订单类。我们通过innodb_flush_log_at_trx_commit就可以设置执行策略。默认为 1

自适应Hash索引主要用于加快查询 页。在查询时,Innodb通过监视索引搜索的机制来判断当前查询是否能走Hash索引。比如LIKE运算符和% 通配符就不能走。存储在一个叫ibdata1的文件中,其中包含:
Buffer Pool写入数据页时,不是直接写入到文件,而是先写入到这个区域。这样做的好处的是,一但操作系统,文件系统或者mysql挂掉,可以直接从这个Buffer中获取数据。每一张表都有一张 .ibd 的文件,存储数据和索引。
每表文件表空间可以使得 ALTER TABLE与 TRUNCATE TABLE 性能得到很好的提升。比如 ALTER TABLE,相较于对驻留在共享表空间中的表,在修改表时,会进行表复制操作,这可能会增加表空间占用的磁盘空间量。此类操作可能需要与表中的数据以及索引一样多的额外空间。该空间不会像每表文件表空间那样释放回操作系统。当然有优点就有缺陷:
Drop table的时候会影响性能(除非你自己管理了碎片)fsync一次性刷入数据到文件中文件句柄, 以提供维持对文件的持续访问共享表空间,他可以存储多个表的数据每表表空间 小
存储在一个叫 ibtmp1 的文件中。正常情况下Mysql启动的时候会创建临时表空间,停止的时候会删除临时表空间。并且它能够自动扩容。
原子性,即当修改到一半,出现异常,可以通过Undo 日志回滚。系统表空间``撤销表空间``临时表空间中,如架构图所示。前面已经介绍过
origin,返给执行器modification
modification刷入内存,Buffer Pool的 Change Buffer
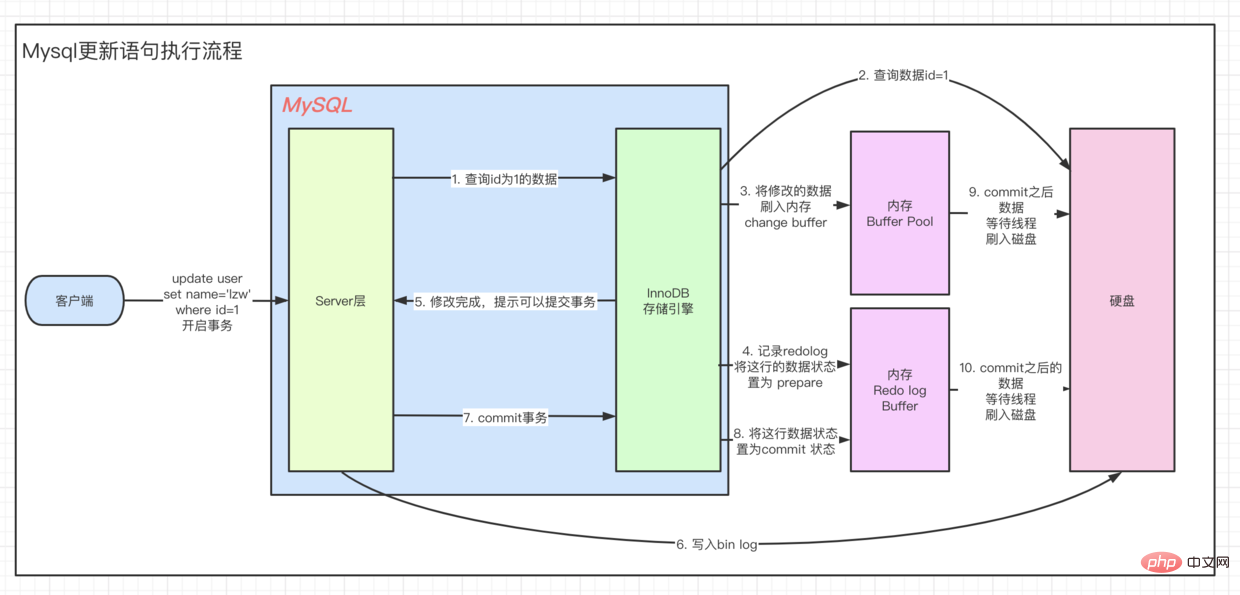
说了 Undo、Redo也顺便说一下Bin log.
innodb引擎没有多大关系,我们前面说的那两种日志,都在是innodb引擎层的。而Bin log是处于服务层的。所以他能被各个引擎所通用Bin log 是以事件的形式,记录了各个 DDL DML 语句,它是一种逻辑意义上的日志。主从复制, 从服务器拿到主服务器的bin log日志,然后执行。数据恢复,拿到某个时间段的日志,重新执行一遍。索引试试华丽的分割线
要想彻底弄明白InnoDB中的索引是个什么东西,就必须要了解它的文件存储级别
Pages, Extents, Segments, and Tablespaces
它们的关系是:
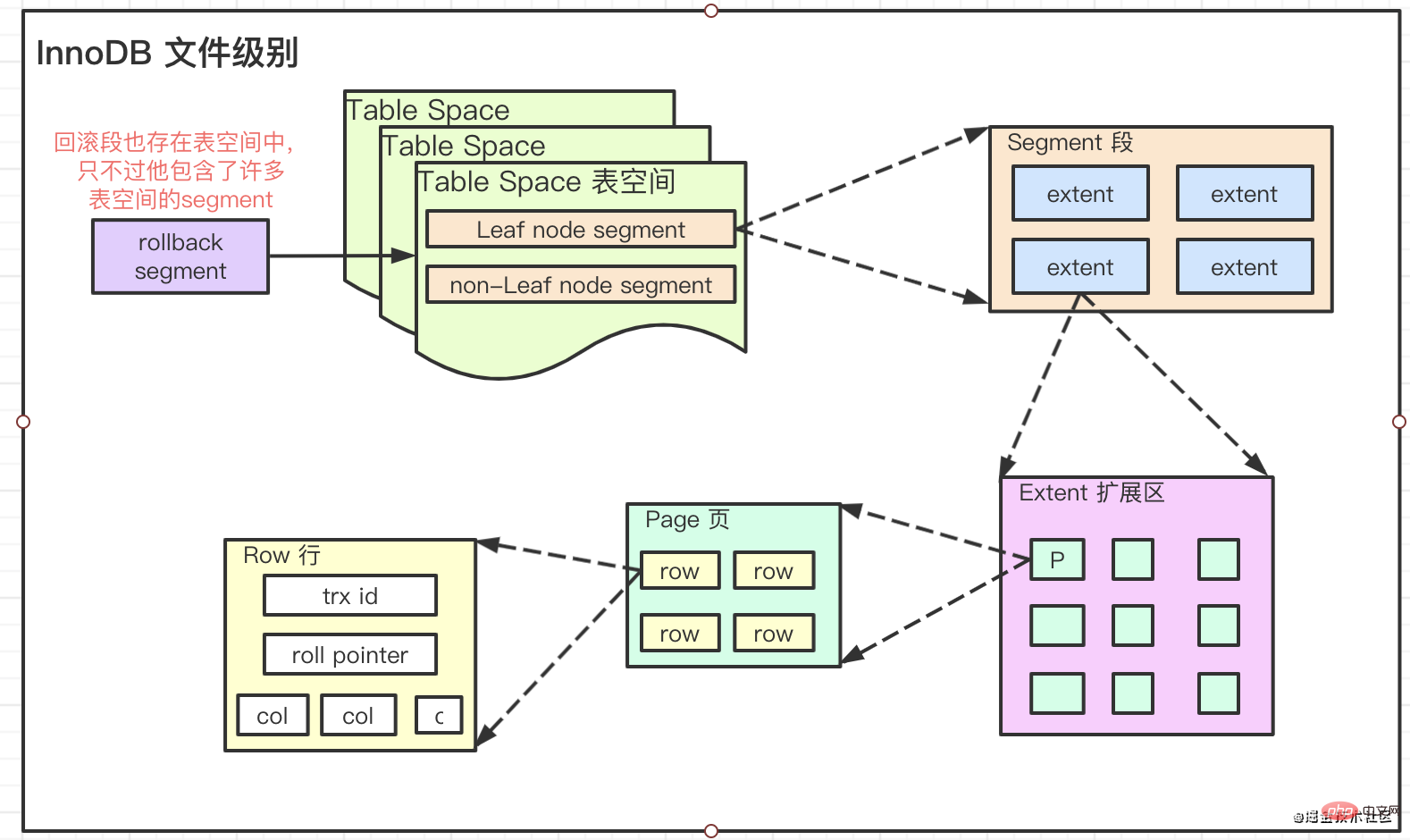
extent 大小为 1M 即 64个 16KB的Page。平常我们文件系统所说的页大小是 4KB,包含 8 个 512Byte的扇区。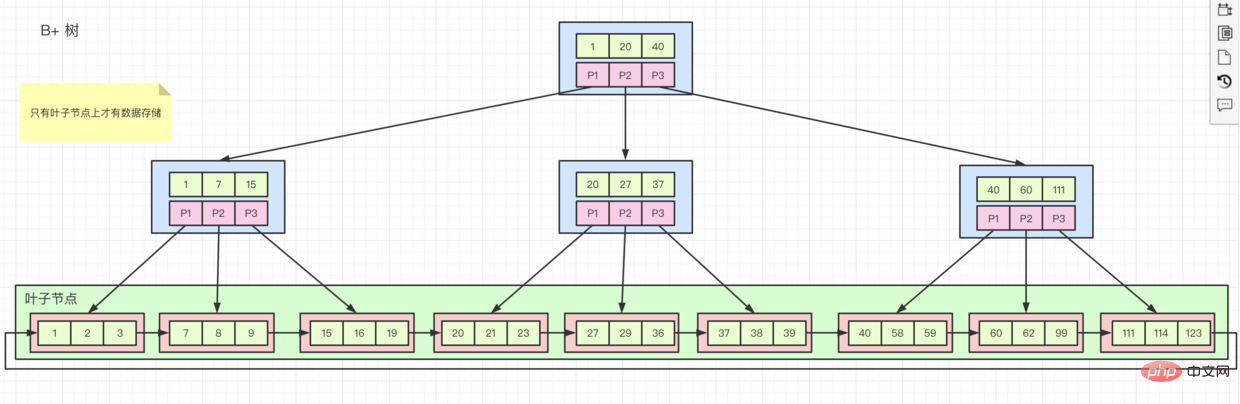
所以有时候,我们被要求主键为什么要是有序的原因就是,如果我们在一个有序的字段上,建立索引,然后插入数据。
在存储的时候,innodb就会按着顺序一个个存储到 页 上,存满一个页再去申请新的页,然后接着存。
但如果我们的字段是无序的,存储的位置就会在不同的页上。当我们的数据存储到一个已经被 存满的页上时,就会造成页分裂,从而形成碎片。
B+树图所示,子节点上存储行数据,并且索引的排列的顺序和索引键值顺序一致的话就是 聚簇索引。主键索引就是聚簇索引,除了主键索引,其他所以都是辅助索引
辅助索引,它的叶子节点上只存储自己的值和主键索引的值。这就意味着,如果我们通过辅助索引查询所有数据,就会先去查找辅助索引中的主键键值,然后再去主键索引里面,查到相关数据。这个过程称为回表
rowid 如果没有主键索引怎么办呢?聚簇索引。rowid 的东西,根据这个id来创建 聚簇索引
搞清楚什么是索引,结构是什么之后。 我们来看看,什么时候我们要用到索引,理解了这些能更好的帮助我们创建正确高效的索引
离散度低不建索引,也就是数据之间相差不大的就没必要建立索引。(因为建立索引,在查询的时候,innodb大多数据都是相同的,我走索引 和全表没什么差别就会直接全表查询)。比如 性别字段。这样反而浪费了大量的存储空间。
联合字段索引,比如 idx(name, class_name)
select * from stu where class_name = xx and name = lzw 查询时,也能走 idx 这个索引的,因为优化器将SQL优化为了 name = lzw and class_name = xx
select ··· where name = lzw 的时候,不需要创建一个单独的 name索引,会直接走 idx这个索引覆盖索引。如果我们此次查询的所有数据全都包含在索引里面了,就不需要再 回表去查询了。比如:select class_name from stu where name =lzw
索引条件下推(index_condition_pushdown)
select * from stu where name = lzw and class_name like '%xx'
索引条件下推,因为后面是 like '%xx'的查询条件,所以这里首先根据 name 走 idx联合索引 查询到几条数据后,再回表查询到全量row数据,然后在server层进行 like 过滤找到数据引擎层对like也进行过滤了,相当于把server层这个过滤操作下推到引擎层了。如图所示: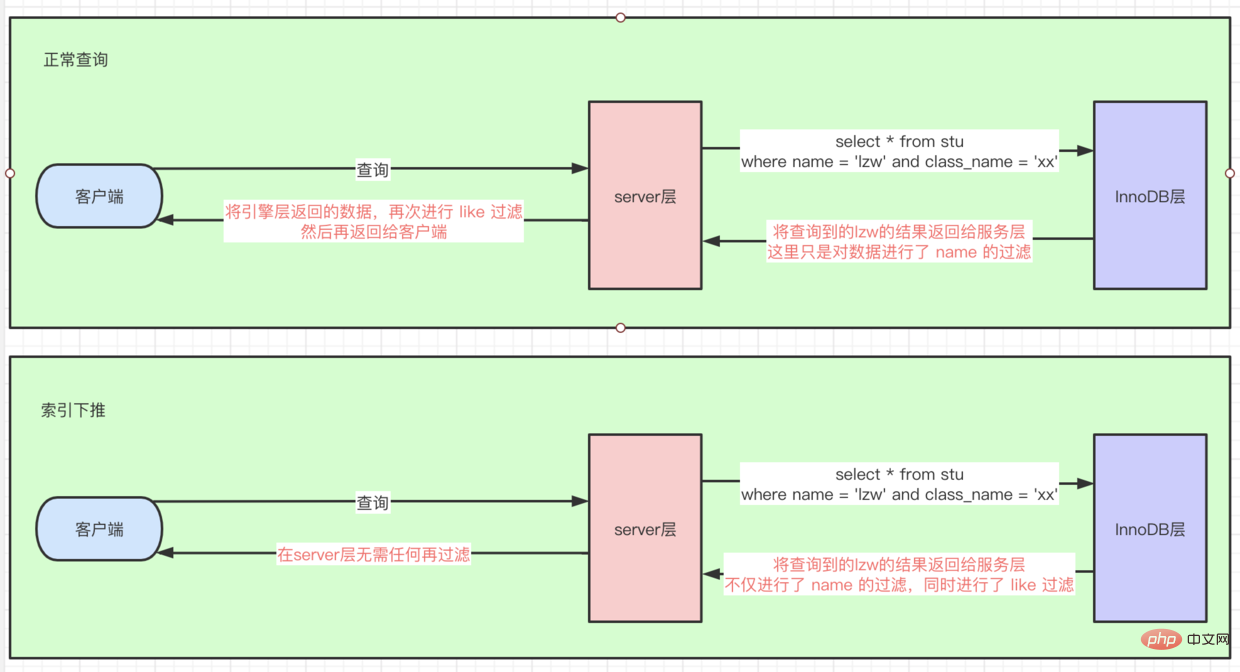
页分裂,索引按顺序存储,如果存储页满了,再去插入就会造成页分裂)函数的时候不会使用索引,所以没必要额外建select count(distinct left(name, 10))/count(*) 来看离散度,决定到底提取前几位)优化器决定的。比如你使用了 Cost Base Optimizer 基于开销的优化器,那种开销小就用哪种优化。又一个华丽的分割线
先回顾一下我们耳熟能详的几个基本概念:
前提,在一个事务中:
SQL92 标准规定: (并发度从左到右,依次降低)

这两种方案在Innodb中结合使用。这里简要说明一下 RR 的 MVCC实现,图中 回滚id 初始值不应该为0而是NULL,这里为了方便写成0

RC的MVCC实现是对 同一个事务的多个读 创建一个版本 而 RR 是 同一个事务任何一条都创建一个版本
通过MVCC与LBCC的结合,InnoDB能解决对于不加锁条件下的 幻读的情况。而不必像 Serializable 一样,必须让事务串行进行,无任何并发。
下面我们来深入研究一下InnoDB锁是如何实现 RR 事务隔离级别的
表级别的 共享和排它锁 => (IS、IX)上面这四把锁是最基本锁的类型
这三把锁,理解成对于上面四把锁实现的三种算法方式,我们这里暂且把它们称为:高阶锁
上面三把是额外扩展的锁
lock in share mode 。排它锁默认 Insert、Update、Delete会使用。显示使用在语句后加for update。打一个标记,记录这个表是否被锁住了) => 如果没有这个锁,别的事务想锁住这张表的时候,就要去全表扫描是否有锁,效率太低。所以才会有意向锁的存在。锁的是索引,那么这个时候可能有人要问了:那如果我不创建索引呢?
索引的存在,我们上面讲过了,这里再回顾一下,有下面几种情况
完整的数据)聚簇索引
rowid 的东西,根据这个id来创建 聚簇索引
所以一个表里面,必然会存在一个索引,所以锁当然总有索引拿来锁住了。
当要给一张你没有显示创建索引的表,进行加锁查询时,数据库其实是不知道到底要查哪些数据的,整张表可能都会用到。所以索性就锁整张表。
辅助索引加写锁,比如select * from where name = ’xxx‘ for update 最后要回表查主键上的信息,所以这个时候除了锁辅助索引还要锁主键索引
首先上三个概念,有这么一组数据:主键是 1,3,6,9 在存储时候有如下:x 1 x 3 x x 6 x x x 9 x···
记录锁,锁的是每个记录,也就是 1,3,6,9
间隙锁,锁的是记录间隙,每个 x,(-∞,1), (1,3), (3,6), (6,9), (9,+∞)
临锁,锁的是 (-∞,1], (1,3], (3,6], (6,9], (9,+∞] 左开右闭的区间
首先这三种锁都是 排它锁, 并且 临键锁 = 记录锁 + 间隙锁
select * from xxx where id = 3 for update 时,产生记录锁select * from xxx where id = 5 for update 时,产生间隙锁 => 锁住了(3,6),这里要格外注意一点:间隙锁之间是不冲突的。select * from xxx where id = 5 for update 时,产生临键锁 => 锁住了(3,6], mysql默认使用临键锁,如果不满足 1 ,2 情况 则他的行锁的都是临键锁Record Lock 行锁防止别的事务修改或删除,Gap Lock 间隙锁防止别的事务新增,Gap Lock 和 Record Lock结合形成的Next-Key锁共同解决RR级别在写数据时的幻读问题。show status like 'innodb_row_lock_%'select * from information_schema.INNODB_TRX 能查看到当前正在运行和被锁住的事务show full processlist = select * from information_schema.processlist 能查询出是 哪个用户 在哪台机器host的哪个端口上 连接哪个数据库 执行什么指令 的 状态与时间
编码层 -- 实现 AbstracRoutingDataSource => 框架层 -- 实现 Mybatis Plugin => 驱动层 -- Sharding-JDBC(配置多个数据源,根据自定义实现的策略对数据进行分库分表存储)核心流程,SQL解析=>执行优化=>SQL数据库路由=>SQL改变(比如分表,改表名)=>SQL执行=>结果归并) => 代理层 -- Mycat(将所有与数据库的连接独立出来。全部由Mycat连接,其他服务访问Mycat获取数据) => 服务层 -- 特殊的SQL版本
说到底我们学习这么多知识都是为了能更好使用MYSQL,那就让我们来实操一下,建立一个完整的优化体系
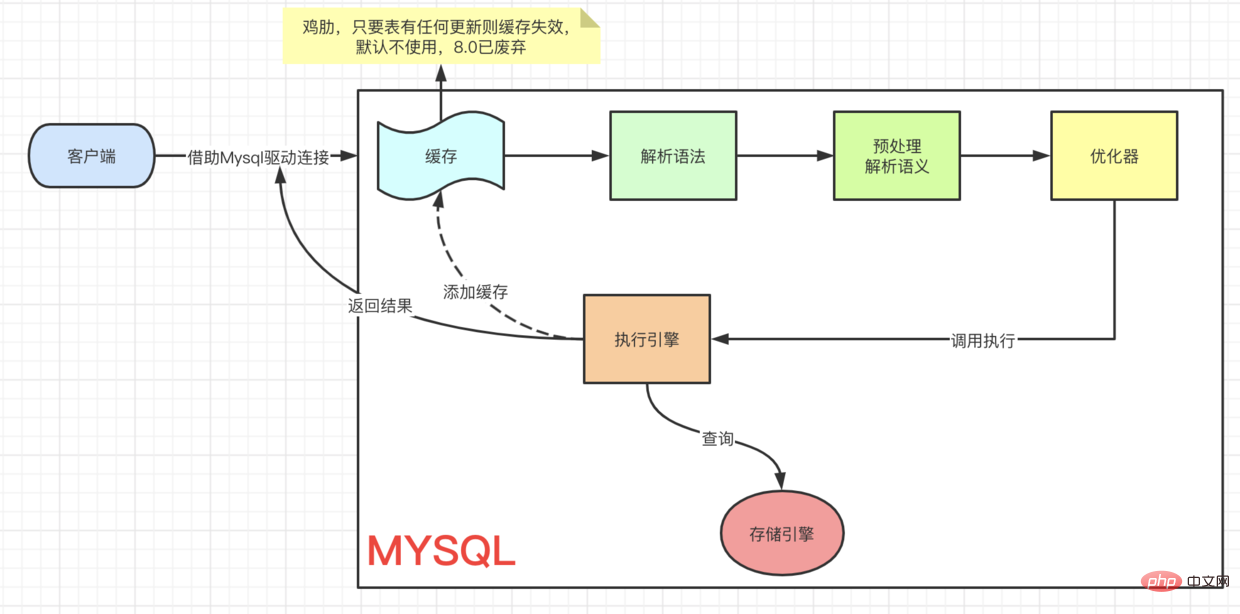
要想获得更好的查询性能,可以从这张查询执行过程入手
添加连接池,避免每次都新建、销毁连接那我们的连接池是不是越多越好呢?
有兴趣的盆友可以看看这篇文章:About Pool Sizing
我大概总结一下:
CPU才能真正去执行线程。而操作系统因为用时间分片的技术,让我们以为一个CPU内核执行了多个线程。CPU在某个时间段只能执行一个线程,所以无论我们怎么增加并发,CPU还是只能在这个时间段里处理这么多数据。CPU处理不了这么多数据,又怎么会变慢?因为时间分片,当多个线程看起来在"同时执行",其实他们之间的上下文切换十分耗时I/O操作,这个时候,CPU就可以把时间,分片给其他线程,以提升处理效率和速度I/O等待时间非常短,所以我们就不能添加过多连接数线程数 = ((核心数 * 2) + 有效磁盘数)。比如一台 i7 4core 1hard disk的机器,就是 4 * 2 + 1 = 9很多CPU计算和I/O的场景 比如:设置最大线程数等如果并发非常大,就不能让他们全打到数据库上,在客户端连接数据库查询时,添加如Redis这种三方缓存
既然我们一个数据库承受不了巨大的并发,那为什么不多添加几台机器呢? 主从复制原理图
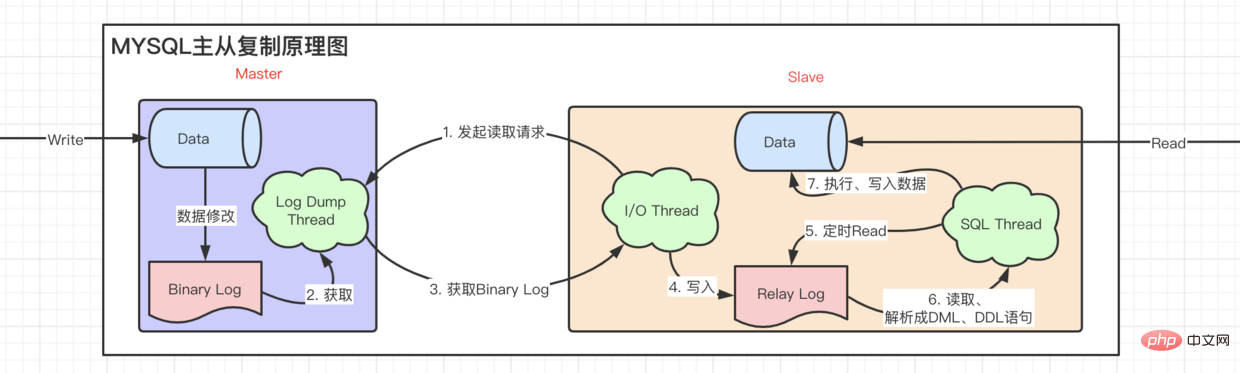
从图中我们不难看出、Mysql主从复制 读写分离 异步复制的特性。
Binary Log写入relay log之后,slave都会把最新读取到的Binary Log Position记录到master info上,下一次就直接从这个位置去取。上面这种异步的主从复制,很明显的一个问题就是,更新不及时的问题。当写入一个数据后,马上有用户读取,读取的还是之前的数据,也就是存在着延时。
要解决延时的问题,就需要引入 事务
failover动作,即主节点挂掉,选举从节点后,能快速自动避免数据丢失。对数据进行分类划分,分成不同表,减少对单一表造成过多锁操作影响性能
开启show_query_log,执行时间超过变量long_query_time的SQL会被记录下来。
可以使用mysqldumpslow /var/lib/mysql/mysql-slow.log,还有很多插件可以提供比这个更优雅的分析,这里就不详细讲了。
任何SQL在写完之后都应该explain一下
left/right join导致性能低下left/right join会直接指定驱动表,在MYSQL中,默认使用Nest loop join进行表关联(即通过驱动表的结果集作为循环基础数据,然后通过此集合中的每一条数据筛选下一个关联表的数据,最后合并结果,得出我们常说的临时表)。驱动表的数据是 百万千万级别的,可想而知这联表查询得有多慢。但是反过来,如果以小表作为驱动表,借助千万级表的索引查询就能变得很快。驱动表,那么请交给优化器来决定,比如:select xxx from table1, table2, table3 where ···,优化器会将查询记录行数少的表作为驱动表。驱动表,那么请拿好Explain武器,在Explain的结果中,第一个就是基础驱动表
表排序也是有很大的性能差异,我们尽量对驱动表进行排序,而不要对临时表,也就是合并后的结果集进行排序。即执行计划中出现了 using temporary,就需要进行优化。普通查询和复杂查询(联合查询、子查询等)SIMPLE,查询不包含子查询或者UNIONPRIMARY,如果查询包含复杂查询的子结构,那么就需要用到主键查询SUBQUERY,在select或者where中包含 子查询
DERIVED,在from中包含子查询UNION RESULT,从union表查询子查询越来越快const或者system 常量级别的扫描,查询表最快的一种,system是const的一种特殊情况(表中只有一条数据)eq_ref 唯一性索引扫描ref 非唯一性索引扫描range 索引的范围扫描,比如 between、<、>等范围查询index (index full)扫描全部索引树ALL 扫描全表NULL,不需要访问表或者索引不一定使用
哪一个索引被真正使用到了。如果没有则为NULL索引(key)一起被使用only index 信息只需要从索引中查出,可能用到了覆盖索引,查询非常快using where 如果查询没有使用索引,这里会在server层过滤再使用 where来过滤结果集impossible where 啥也没查出来using filesort ,只要没有通过索引来排序,而是使用了其他排序的方式就是 filesortusing temporary(需要通过临时表来对结果集进行暂时存储,然后再进行计算。)一般来说这种情况都是进行了DISTINCT、排序、分组
using index condition 索引下推,上文讲过,就是把server层这个过滤操作下推到引擎层
插入与查询比较多的时候,可以使用MyISAM存储引擎memory
插入、更新、查询等并发数很多时,可以使用InnoDB
从五个层次回答MYSQL优化,由上至下
除此之外,查数据慢,要不仅仅拘留于一味的 "优化" 数据库,而是要从业务应用层面去分析。比如对数据进行缓存,对请求进行限流等。
我们下篇文章见
相关免费学习推荐:mysql视频教程
Atas ialah kandungan terperinci 一篇文章让你搞懂MYSQL底层原理. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



