


1、java中==和equals和hashCode的区别
基本数据类型的==比较的值相等.
类的==比较的内存的地址,即是否是同一个对象,在不覆盖equals的情况下,同比较内存地址,原实现也为 == ,如String等重写了equals方法.
hashCode也是Object类的一个方法。返回一个离散的int型整数。在集合类操作中使用,为了提高查询速度。(HashMap,HashSet等比较是否为同一个)
如果两个对象equals,Java运行时环境会认为他们的hashcode一定相等。
如果两个对象不equals,他们的hashcode有可能相等。
如果两个对象hashcode相等,他们不一定equals。
如果两个对象hashcode不相等,他们一定不equals。
2、int与integer的区别
int 基本类型
integer 对象 int的封装类
3、String、StringBuffer、StringBuilder区别
String:字符串常量 不适用于经常要改变值得情况,每次改变相当于生成一个新的对象
StringBuffer:字符串变量 (线程安全)
StringBuilder:字符串变量(线程不安全) 确保单线程下可用,效率略高于StringBuffer
4、什么是内部类?内部类的作用
内部类可直接访问外部类的属性
Java中内部类主要分为成员内部类、局部内部类(嵌套在方法和作用域内)、匿名内部类(没构造方法)、静态内部类(static修饰的类,不能使用任何外围类的非static成员变量和方法, 不依赖外围类)
5、进程和线程的区别
进程是cpu资源分配的最小单位,线程是cpu调度的最小单位。
进程之间不能共享资源,而线程共享所在进程的地址空间和其它资源。
一个进程内可拥有多个线程,进程可开启进程,也可开启线程。
一个线程只能属于一个进程,线程可直接使用同进程的资源,线程依赖于进程而存在。
6、final,finally,finalize的区别
final:修饰类、成员变量和成员方法,类不可被继承,成员变量不可变,成员方法不可重写
finally:与try...catch...共同使用,确保无论是否出现异常都能被调用到
finalize:类的方法,垃圾回收之前会调用此方法,子类可以重写finalize()方法实现对资源的回收
7、Serializable 和Parcelable 的区别
Serializable Java 序列化接口 在硬盘上读写 读写过程中有大量临时变量的生成,内部执行大量的i/o操作,效率很低。
Parcelable Android 序列化接口 效率高 使用麻烦 在内存中读写(AS有相关插件 一键生成所需方法) ,对象不能保存到磁盘中
8、静态属性和静态方法是否可以被继承?是否可以被重写?以及原因?
可继承 不可重写 而是被隐藏
如果子类里面定义了静态方法和属性,那么这时候父类的静态方法或属性称之为"隐藏"。如果你想要调用父类的静态方法和属性,直接通过父类名.方法或变量名完成。
9、成员内部类、静态内部类、局部内部类和匿名内部类的理解,以及项目中的应用
ava中内部类主要分为成员内部类、局部内部类(嵌套在方法和作用域内)、匿名内部类(没构造方法)、静态内部类(static修饰的类,不能使用任何外围类的非static成员变量和方法, 不依赖外围类)
使用内部类最吸引人的原因是:每个内部类都能独立地继承一个(接口的)实现,所以无论外围类是否已经继承了某个(接口的)实现,对于内部类都没有影响。
因为Java不支持多继承,支持实现多个接口。但有时候会存在一些使用接口很难解决的问题,这个时候我们可以利用内部类提供的、可以继承多个具体的或者抽象的类的能力来解决这些程序设计问题。可以这样说,接口只是解决了部分问题,而内部类使得多重继承的解决方案变得更加完整。
10、string 转换成 integer的方式及原理
String integer Intrger.parseInt(string);
Integerstring Integer.toString();
11、哪些情况下的对象会被垃圾回收机制处理掉?
1.所有实例都没有活动线程访问。
2.没有被其他任何实例访问的循环引用实例。
3.Java 中有不同的引用类型。判断实例是否符合垃圾收集的条件都依赖于它的引用类型。
要判断怎样的对象是没用的对象。这里有2种方法:
1.采用标记计数的方法:
给内存中的对象给打上标记,对象被引用一次,计数就加1,引用被释放了,计数就减一,当这个计数为0的时候,这个对象就可以被回收了。当然,这也就引发了一个问题:循环引用的对象是无法被识别出来并且被回收的。所以就有了第二种方法:
2.采用根搜索算法:
从一个根出发,搜索所有的可达对象,这样剩下的那些对象就是需要被回收的
12、静态代理和动态代理的区别,什么场景使用?
静态代理类: 由程序员创建或由特定工具自动生成源代码,再对其编译。在程序运行前,代理类的.class文件就已经存在了。动态代理类:在程序运行时,运用反射机制动态创建而成。
14、Java中实现多态的机制是什么?
答:方法的重写Overriding和重载Overloading是Java多态性的不同表现
重写Overriding是父类与子类之间多态性的一种表现
重载Overloading是一个类中多态性的一种表现.
16、说说你对Java反射的理解
JAVA反射机制是在运行状态中, 对于任意一个类, 都能够知道这个类的所有属性和方法; 对于任意一个对象, 都能够调用它的任意一个方法和属性。 从对象出发,通过反射(Class类)可以取得取得类的完整信息(类名 Class类型,所在包、具有的所有方法 Method[]类型、某个方法的完整信息(包括修饰符、返回值类型、异常、参数类型)、所有属性 Field[]、某个属性的完整信息、构造器 Constructors),调用类的属性或方法自己的总结: 在运行过程中获得类、对象、方法的所有信息。
17、说说你对Java注解的理解
元注解
元注解的作用就是负责注解其他注解。java5.0的时候,定义了4个标准的meta-annotation类型,它们用来提供对其他注解的类型作说明。
1.@Target
2.@Retention
3.@Documented
4.@Inherited
18、Java中String的了解
在源码中string是用final 进行修饰,它是不可更改,不可继承的常量。
19、String为什么要设计成不可变的?
1、字符串池的需求
字符串池是方法区(Method Area)中的一块特殊的存储区域。当一个字符串已经被创建并且该字符串在 池 中,该字符串的引用会立即返回给变量,而不是重新创建一个字符串再将引用返回给变量。如果字符串不是不可变的,那么改变一个引用(如: string2)的字符串将会导致另一个引用(如: string1)出现脏数据。
2、允许字符串缓存哈希码
在java中常常会用到字符串的哈希码,例如: HashMap 。String的不变性保证哈希码始终一,因此,他可以不用担心变化的出现。 这种方法意味着不必每次使用时都重新计算一次哈希码——这样,效率会高很多。
3、安全
String广泛的用于java 类中的参数,如:网络连接(Network connetion),打开文件(opening files )等等。如果String不是不可变的,网络连接、文件将会被改变——这将会导致一系列的安全威胁。操作的方法本以为连接上了一台机器,但实际上却不是。由于反射中的参数都是字符串,同样,也会引起一系列的安全问题。
20、Object类的equal和hashCode方法重写,为什么?
首先equals与hashcode间的关系是这样的:
1、如果两个对象相同(即用equals比较返回true),那么它们的hashCode值一定要相同;
2、如果两个对象的hashCode相同,它们并不一定相同(即用equals比较返回false)
由于为了提高程序的效率才实现了hashcode方法,先进行hashcode的比较,如果不同,那没就不必在进行equals的比较了,这样就大大减少了equals比较的次数,这对比需要比较的数量很大的效率提高是很明显的
21、List,Set,Map的区别
Set是最简单的一种集合。集合中的对象不按特定的方式排序,并且没有重复对象。 Set接口主要实现了两个实现类:HashSet: HashSet类按照哈希算法来存取集合中的对象,存取速度比较快
TreeSet :TreeSet类实现了SortedSet接口,能够对集合中的对象进行排序。
List的特征是其元素以线性方式存储,集合中可以存放重复对象。
ArrayList() : 代表长度可以改变得数组。可以对元素进行随机的访问,向ArrayList()中插入与删除元素的速度慢。
LinkedList(): 在实现中采用链表数据结构。插入和删除速度快,访问速度慢。
Map 是一种把键对象和值对象映射的集合,它的每一个元素都包含一对键对象和值对象。 Map没有继承于Collection接口 从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象。
HashMap:Map基于散列表的实现。插入和查询“键值对”的开销是固定的。可以通过构造器设置容量capacity和负载因子load factor,以调整容器的性能。
LinkedHashMap: 类似于HashMap,但是迭代遍历它时,取得“键值对”的顺序是其插入次序,或者是最近最少使用(LRU)的次序。只比HashMap慢一点。而在迭代访问时发而更快,因为它使用链表维护内部次序。
TreeMap : 基于红黑树数据结构的实现。查看“键”或“键值对”时,它们会被排序(次序由Comparabel或Comparator决定)。TreeMap的特点在 于,你得到的结果是经过排序的。TreeMap是唯一的带有subMap()方法的Map,它可以返回一个子树。
WeakHashMao :弱键(weak key)Map,Map中使用的对象也被允许释放: 这是为解决特殊问题设计的。如果没有map之外的引用指向某个“键”,则此“键”可以被垃圾收集器回收。
26、ArrayMap和HashMap的对比
1、存储方式不同
HashMap内部有一个HashMapEntry
2、添加数据时扩容时的处理不一样,进行了new操作,重新创建对象,开销很大。ArrayMap用的是copy数据,所以效率相对要高。
3、ArrayMap提供了数组收缩的功能,在clear或remove后,会重新收缩数组,是否空间
4、ArrayMap采用二分法查找;
29、HashMap和HashTable的区别
1 HashMap不是线程安全的,效率高一点、方法不是Synchronize的要提供外同步,有containsvalue和containsKey方法。
hashtable是,线程安全,不允许有null的键和值,效率稍低,方法是是Synchronize的。有contains方法方法。Hashtable 继承于Dictionary 类
30、HashMap与HashSet的区别
hashMap:HashMap实现了Map接口,HashMap储存键值对,使用put()方法将元素放入map中,HashMap中使用键对象来计算hashcode值,HashMap比较快,因为是使用唯一的键来获取对象。
HashSet实现了Set接口,HashSet仅仅存储对象,使用add()方法将元素放入set中,HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false。HashSet较HashMap来说比较慢。
31、HashSet与HashMap怎么判断集合元素重复?
HashSet不能添加重复的元素,当调用add(Object)方法时候,
首先会调用Object的hashCode方法判hashCode是否已经存在,如不存在则直接插入元素;如果已存在则调用Object对象的equals方法判断是否返回true,如果为true则说明元素已经存在,如为false则插入元素。
33、ArrayList和LinkedList的区别,以及应用场景
ArrayList是基于数组实现的,ArrayList线程不安全。
LinkedList是基于双链表实现的:
使用场景:
(1)如果应用程序对各个索引位置的元素进行大量的存取或删除操作,ArrayList对象要远优于LinkedList对象;
( 2 ) 如果应用程序主要是对列表进行循环,并且循环时候进行插入或者删除操作,LinkedList对象要远优于ArrayList对象;
34、数组和链表的区别
数组:是将元素在内存中连续存储的;它的优点:因为数据是连续存储的,内存地址连续,所以在查找数据的时候效率比较高;它的缺点:在存储之前,我们需要申请一块连续的内存空间,并且在编译的时候就必须确定好它的空间的大小。在运行的时候空间的大小是无法随着你的需要进行增加和减少而改变的,当数据两比较大的时候,有可能会出现越界的情况,数据比较小的时候,又有可能会浪费掉内存空间。在改变数据个数时,增加、插入、删除数据效率比较低。
链表:是动态申请内存空间,不需要像数组需要提前申请好内存的大小,链表只需在用的时候申请就可以,根据需要来动态申请或者删除内存空间,对于数据增加和删除以及插入比数组灵活。还有就是链表中数据在内存中可以在任意的位置,通过应用来关联数据(就是通过存在元素的指针来联系)
35、开启线程的三种方式?
ava有三种创建线程的方式,分别是继承Thread类、实现Runable接口和使用线程池
36、线程和进程的区别?
线程是进程的子集,一个进程可以有很多线程,每条线程并行执行不同的任务。不同的进程使用不同的内存空间,而所有的线程共享一片相同的内存空间。别把它和栈内存搞混,每个线程都拥有单独的栈内存用来存储本地数据。
38、run()和start()方法区别
这个问题经常被问到,但还是能从此区分出面试者对Java线程模型的理解程度。start()方法被用来启动新创建的线程,而且start()内部调用了run()方法,这和直接调用run()方法的效果不一样。当你调用run()方法的时候,只会是在原来的线程中调用,没有新的线程启动,start()方法才会启动新线程。
39、如何控制某个方法允许并发访问线程的个数?
semaphore.acquire() 请求一个信号量,这时候的信号量个数-1(一旦没有可使用的信号量,也即信号量个数变为负数时,再次请求的时候就会阻塞,直到其他线程释放了信号量)
semaphore.release() 释放一个信号量,此时信号量个数+1
40、在Java中wait和seelp方法的不同;
Java程序中wait 和 sleep都会造成某种形式的暂停,它们可以满足不同的需要。wait()方法用于线程间通信,如果等待条件为真且其它线程被唤醒时它会释放锁,而sleep()方法仅仅释放CPU资源或者让当前线程停止执行一段时间,但不会释放锁。
41、谈谈wait/notify关键字的理解
等待对象的同步锁,需要获得该对象的同步锁才可以调用这个方法,否则编译可以通过,但运行时会收到一个异常:IllegalMonitorStateException。
调用任意对象的 wait() 方法导致该线程阻塞,该线程不可继续执行,并且该对象上的锁被释放。
唤醒在等待该对象同步锁的线程(只唤醒一个,如果有多个在等待),注意的是在调用此方法的时候,并不能确切的唤醒某一个等待状态的线程,而是由JVM确定唤醒哪个线程,而且不是按优先级。
调用任意对象的notify()方法则导致因调用该对象的 wait()方法而阻塞的线程中随机选择的一个解除阻塞(但要等到获得锁后才真正可执行)。
42、什么导致线程阻塞?线程如何关闭?
阻塞式方法是指程序会一直等待该方法完成期间不做其他事情,ServerSocket的accept()方法就是一直等待客户端连接。这里的阻塞是指调用结果返回之前,当前线程会被挂起,直到得到结果之后才会返回。此外,还有异步和非阻塞式方法在任务完成前就返回。
一种是调用它里面的stop()方法
另一种就是你自己设置一个停止线程的标记 (推荐这种)
43、如何保证线程安全?
1.synchronized;
2.Object方法中的wait,notify;
3.ThreadLocal机制 来实现的。
44、如何实现线程同步?
1、synchronized关键字修改的方法。2、synchronized关键字修饰的语句块3、使用特殊域变量(volatile)实现线程同步
45、线程间操作List
List list = Collections.synchronizedList(new ArrayList());
46、谈谈对Synchronized关键字,类锁,方法锁,重入锁的理解
java的对象锁和类锁:java的对象锁和类锁在锁的概念上基本上和内置锁是一致的,但是,两个锁实际是有很大的区别的,对象锁是用于对象实例方法,或者一个对象实例上的,类锁是用于类的静态方法或者一个类的class对象上的。我们知道,类的对象实例可以有很多个,但是每个类只有一个class对象,所以不同对象实例的对象锁是互不干扰的,但是每个类只有一个类锁。但是有一点必须注意的是,其实类锁只是一个概念上的东西,并不是真实存在的,它只是用来帮助我们理解锁定实例方法和静态方法的区别的
49、synchronized 和volatile 关键字的区别
1.volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取;synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
2.volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的
3.volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性
4.volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
5.volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化
51、ReentrantLock 、synchronized和volatile比较
ava在过去很长一段时间只能通过synchronized关键字来实现互斥,它有一些缺点。比如你不能扩展锁之外的方法或者块边界,尝试获取锁时不能中途取消等。Java 5 通过Lock接口提供了更复杂的控制来解决这些问题。 ReentrantLock 类实现了 Lock,它拥有与 synchronized 相同的并发性和内存语义且它还具有可扩展性。
53、死锁的四个必要条件?
死锁产生的原因
1. 系统资源的竞争
系统资源的竞争导致系统资源不足,以及资源分配不当,导致死锁。
2. 进程运行推进顺序不合适
互斥条件:一个资源每次只能被一个进程使用,即在一段时间内某 资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。
请求与保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源 已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放。
不可剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能 由获得该资源的进程自己来释放(只能是主动释放)。
循环等待条件: 若干进程间形成首尾相接循环等待资源的关系
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
死锁的避免与预防:
死锁避免的基本思想:
系统对进程发出每一个系统能够满足的资源申请进行动态检查,并根据检查结果决定是否分配资源,如果分配后系统可能发生死锁,则不予分配,否则予以分配。这是一种保证系统不进入死锁状态的动态策略。
理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和解除死锁。所以,在系统设计、进程调度等方面注意如何让这四个必要条件不成立,如何确定资源的合理分配算法,避免进程永久占据系统资源。此外,也要防止进程在处于等待状态的情况下占用资源。因此,对资源的分配要给予合理的规划。
死锁避免和死锁预防的区别:
死锁预防是设法至少破坏产生死锁的四个必要条件之一,严格的防止死锁的出现,而死锁避免则不那么严格的限制产生死锁的必要条件的存在,因为即使死锁的必要条件存在,也不一定发生死锁。死锁避免是在系统运行过程中注意避免死锁的最终发生。
56、什么是线程池,如何使用?
创建线程要花费昂贵的资源和时间,如果任务来了才创建线程那么响应时间会变长,而且一个进程能创建的线程数有限。为了避免这些问题,在程序启动的时候就创建若干线程来响应处理,它们被称为线程池,里面的线程叫工作线程。从JDK1.5开始,Java API提供了Executor框架让你可以创建不同的线程池。比如单线程池,每次处理一个任务;数目固定的线程池或者是缓存线程池(一个适合很多生存期短的任务的程序的可扩展线程池)。
57、Java中堆和栈有什么不同?
为什么把这个问题归类在多线程和并发面试题里?因为栈是一块和线程紧密相关的内存区域。每个线程都有自己的栈内存,用于存储本地变量,方法参数和栈调用,一个线程中存储的变量对其它线程是不可见的。而堆是所有线程共享的一片公用内存区域。对象都在堆里创建,为了提升效率线程会从堆中弄一个缓存到自己的栈,如果多个线程使用该变量就可能引发问题,这时volatile 变量就可以发挥作用了,它要求线程从主存中读取变量的值。
58、有三个线程T1,T2,T3,怎么确保它们按顺序执行?
在多线程中有多种方法让线程按特定顺序执行,你可以用线程类的join()方法在一个线程中启动另一个线程,另外一个线程完成该线程继续执行。为了确保三个线程的顺序你应该先启动最后一个(T3调用T2,T2调用T1),这样T1就会先完成而T3最后完成。
线程间通信
我们知道线程是CPU调度的最小单位。在Android中主线程是不能够做耗时操作的,子线程是不能够更新UI的。而线程间通信的方式有很多,比如广播,Eventbus,接口回掉,在Android中主要是使用handler。handler通过调用sendmessage方法,将保存消息的Message发送到Messagequeue中,而looper对象不断的调用loop方法,从messageueue中取出message,交给handler处理,从而完成线程间通信。
线程池
Android中常见的线程池有四种,FixedThreadPool、CachedThreadPool、ScheduledThreadPool、SingleThreadExecutor。
FixedThreadPool线程池是通过Executors的new FixedThreadPool方法来创建。它的特点是该线程池中的线程数量是固定的。即使线程处于闲置的状态,它们也不会被回收,除非线程池被关闭。当所有的线程都处于活跃状态的时候,新任务就处于队列中等待线程来处理。注意,FixedThreadPool只有核心线程,没有非核心线程。
CachedThreadPool线程池是通过Executors的newCachedThreadPool进行创建的。它是一种线程数目不固定的线程池,它没有核心线程,只有非核心线程,当线程池中的线程都处于活跃状态,就会创建新的线程来处理新的任务。否则就会利用闲置的线程来处理新的任务。线程池中的线程都有超时机制,这个超时机制时长是60s,超过这个时间,闲置的线程就会被回收。这种线程池适合处理大量并且耗时较少的任务。这里得说一下,CachedThreadPool的任务队列,基本都是空的。
ScheduledThreadPool线程池是通过Executors的newScheduledThreadPool进行创建的,它的核心线程是固定的,但是非核心线程数是不固定的,并且当非核心线程一处于空闲状态,就立即被回收。这种线程适合执行定时任务和具有固定周期的重复任务。
SingleThreadExecutor线程池是通过Executors的newSingleThreadExecutor方法来创建的,这类线程池中只有一个核心线程,也没有非核心线程,这就确保了所有任务能够在同一个线程并且按照顺序来执行,这样就不需要考虑线程同步的问题。
AsyncTask的工作原理
AsyncTask是Android本身提供的一种轻量级的异步任务类。它可以在线程池中执行后台任务,然后把执行的进度和最终的结果传递给主线程更新UI。实际上,AsyncTask内部是封装了Thread和Handler。虽然AsyncTask很方便的执行后台任务,以及在主线程上更新UI,但是,AsyncTask并不合适进行特别耗时的后台操作,对于特别耗时的任务,个人还是建议使用线程池。
AsyncTask提供有4个核心方法:
1、onPreExecute():该方法在主线程中执行,在执行异步任务之前会被调用,一般用于一些准备工作。
2、doInBackground(String... params):这个方法是在线程池中执行,此方法用于执行异步任务。在这个方法中可以通过publishProgress方法来更新任务的进度,publishProgress方法会调用onProgressUpdate方法,另外,任务的结果返回给onPostExecute方法。
3、onProgressUpdate(Object... values):该方法在主线程中执行,主要用于任务进度更新的时候,该方法会被调用。
4、onPostExecute(Long aLong):在主线程中执行,在异步任务执行完毕之后,该方法会被调用,该方法的参数及为后台的返回结果。
除了这几个方法之外还有一些不太常用的方法,如onCancelled(),在异步任务取消的情况下,该方法会被调用。
源码可以知道从上面的execute方法内部调用的是executeOnExecutor()方法,即executeOnExecutor(sDefaultExecutor, params);而sDefaultExecutor实际上是一个串行的线程池。而onPreExecute()方法在这里就会被调用了。接着看这个线程池。AsyncTask的执行是排队执行的,因为有关键字synchronized,而AsyncTask的Params参数就封装成为FutureTask类,FutureTask这个类是一个并发类,在这里它充当了Runnable的作用。接着FutureTask会交给SerialExecutor的execute方法去处理,而SerialExecutor的executor方法首先就会将FutureTask添加到mTasks队列中,如果这个时候没有任务,就会调用scheduleNext()方法,执行下一个任务。如果有任务的话,则执行完毕后最后在调用 scheduleNext();执行下一个任务。直到所有任务被执行完毕。而AsyncTask的构造方法中有一个call()方法,而这个方法由于会被FutureTask的run方法执行。所以最终这个call方法会在线程池中执行。而doInBackground这个方法就是在这里被调用的。我们好好研究一下这个call()方法。mTaskInvoked.set(true);表示当前任务已经执行过了。接着执行doInBackground方法,最后将结果通过postResult(result);方法进行传递。postResult()方法中通过sHandler来发送消息,sHandler的中通过消息的类型来判断一个MESSAGE_POST_RESULT,这种情况就是调用onPostExecute(result)方法或者是onCancelled(result)。另一种消息类型是MESSAGE_POST_PROGRESS则调用更新进度onProgressUpdate。
Binder的工作机制
直观来说,Binder是Android中的一个类,它实现了IBinder接口,从IPC的角度来说,Binder是Android中的一种跨进程通信的一种方式,同时还可以理解为是一种虚拟的物理设备,它的设备驱动是/dev/binder/。从Framework角度来说,Binder是ServiceManager的桥梁。从应用层来说,Binder是客户端和服务端进行通信的媒介。
我们先来了解一下这个类中每个方法的含义:
DESCRIPTOR:Binder的唯一标识,一般用于当前Binder的类名表示。
asInterface(android.os.IBinder obj):用于将服务端的Binder对象转换成客户端所需的AIDL接口类型的对象,这种转化过程是区分进程的,如果客户端和服务端位于同一个进程,那么这个方法返回的是服务端的stub对象本身,否则返回的是系统封装后的Stub.proxy对象。
asBinder():用于返回当前Binder对象。
onTransact:该方法运行在服务端的Binder线程池中,当客户端发起跨进程通信请求的时候,远程请求通过系统底层封装后交给该方法处理。注意这个方法public boolean onTransact(int code, android.os.Parcel data, android.os.Parcel reply, int flags),服务端通过code可以确定客户端所请求的目标方法是什么,接着从data中取出目标方法所需的参数,然后执行目标方法。当目标方法执行完毕后,就像reply中写入返回值。这个方法的执行过程就是这样的。如果这个方法返回false,客户端是会请求失败的,所以我们可以在这个方法中做一些安全验证。
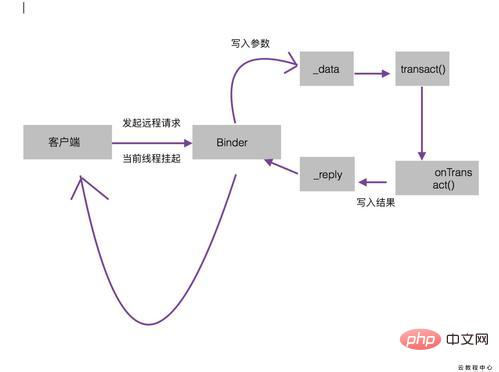
Binder的工作机制但是要注意一些问题:1、当客户端发起请求时,由于当前线程会被挂起,直到服务端返回数据,如果这个远程方法很耗时的话,那么是不能够在UI线程,也就是主线程中发起这个远程请求的。
2、由于Service的Binder方法运行在线程池中,所以Binder方法不管是耗时还是不耗时都应该采用同步的方式,因为它已经运行在一个线程中了。
view的事件分发和view的工作原理
Android自定义view,我们都知道实现有三部曲,onMeasure(),onLayout(),onDraw()。View的绘制流程是从viewRoot的perfromTraversal方法开始的。它经过measure,layout,draw方法才能够将view绘制出来。其中measure是测量宽高的,layout是确定view在父容器上的摆布位置的,draw是将view绘制到屏幕上的。
Measure:
view的测量是需要MeasureSpc(测量规格),它代表一个32位int值,高2位代表SpecMode(测量模式),低(30)位的代表SpecSize(某种测量模式下的规格大小)。而一组SpecMode和SpeSize可以打包为一个MeasureSpec,反之,MeasureSpec可以解包得到SpecMode和SpeSize的值。SpecMode有三类:
unSpecified:父容器不对view有任何限制,要多大有多大。一般系统用这个多。
Exactly:父容器已经检测出view所需要的精确大小,这个时候,view的大小就是SpecSize所指定的值,它对应者layout布局中的math_parent或者是具体的数值
At_most:父容器指定了一个可用大小的SpecSize,view的大小不能够大于这个值,它对应这布局中的wrao_content.
对于普通的view,它的MeasureSpec是由父容器的MeasureSpec和自身的layoutParam共同决定的,一旦MeasureSpec确定后,onMeasure就可以确定view的宽高了。
View的measure过程:
onMeasure方法中有个setMeasureDimenSion方法来设置view的宽高测量值,而setMeasureDimenSion有个getDefaultSize()方法作为参数。一般情况下,我们只需要关注at_most和exactly两种情况,getDefaultSize的返回值就是measureSpec中的SpecSize,而这个值基本就是view测量后的大小。而UnSpecified这种情况,一般是系统内部的测量过程,它是需要考虑view的背景这些因素的。
前面说的是view的测量过程,而viewGroup的measure过程:
对于viewGroup来说,除了完成自己的measure过程以外,还要遍历去调用子类的measure方法,各个子元素在递归执行这个过程,viewGroup是一个抽象的类,没有提供有onMeasure方法,但是提供了一个measureChildren的方法。measureChild方法的思想就是取出子元素的layoutParams,然后通过getChildMeasureSpec来常见子元素的MeasureSpec,然后子元素在电泳measure方法进行测量。由于viewGroup子类有不同的布局方式,导致他们的测量细节不一样,所以viewGroup不能象view一样调用onMeasure方法进行测量。
注意:在activity的生命周期中是没有办法正确的获取view的宽高的,原因就是view没有测量完。
onLayout
普通的view的话,可以通过setFrame方法来的到view四个顶点的位置,也就确定了view在父容器的位置,接着就调用onLayout方法,该方法是父容器确定子元素的位置。
onDraw
该方法就是将view绘制到屏幕上。分以下几步
Android中性能优化
由于手机硬件的限制,内存和CPU都无法像pc一样具有超大的内存,Android手机上,过多的使用内存,会容易导致oom,过多的使用CPU资源,会导致手机卡顿,甚至导致anr。我主要是从一下几部分进行优化:
布局优化,绘制优化,内存泄漏优化,响应速度优化,listview优化,bitmap优化,线程优化
布局优化:工具 hierarchyviewer,解决方式:
1、删除无用的空间和层级。
2、选择性能较低的viewgroup,如Relativelayout,如果可以选择Relativelayout也可以使用LinearLayout,就优先使用LinearLayout,因为相对来说Relativelayout功能较为复杂,会占用更多的CPU资源。
3、使用标签
绘制优化
绘制优化指view在ondraw方法中避免大量的耗时操作,由于ondraw方法可能会被频繁的调用。
1、ondraw方法中不要创建新的局部变量,ondraw方法被频繁的调用,很容易引起GC。
2、ondraw方法不要做耗时操作。
内存优化:参考内存泄漏。
响应优化:主线程不能做耗时操作,触摸事件5s,广播10s,service20s。
listview优化:
1、getview方法中避免耗时操作。
2、view的复用和viewholder的使用。
3、滑动不适合开启异步加载。
4、分页处理数据。
5、图片使用三级缓存。
Bitmap优化:
1、等比例压缩图片。
2、不用的图片,及时recycler掉
线程优化
线程优化的思想是使用线程池来管理和复用线程,避免程序中有大量的Thread,同时可以控制线程的并发数,避免相互抢占资源而导致线程阻塞。
其他优化
1、少用枚举,枚举占用空间大。
2、使用Android特有的数据结构,如SparseArray来代替hashMap。
3、适当的使用软引用和弱引用。
加密算法(base64、MD5、对称加密和非对称加密)和使用场景。
什么是Rsa加密?
RSA算法是最流行的公钥密码算法,使用长度可以变化的密钥。RSA是第一个既能用于数据加密也能用于数字签名的算法。
RSA算法原理如下:
1.随机选择两个大质数p和q,p不等于q,计算N=pq;
2.选择一个大于1小于N的自然数e,e必须与(p-1)(q-1)互素。
3.用公式计算出d:d×e = 1 (mod (p-1)(q-1)) 。
4.销毁p和q。
最终得到的N和e就是“公钥”,d就是“私钥”,发送方使用N去加密数据,接收方只有使用d才能解开数据内容。
RSA的安全性依赖于大数分解,小于1024位的N已经被证明是不安全的,而且由于RSA算法进行的都是大数计算,使得RSA最快的情况也比DES慢上倍,这是RSA最大的缺陷,因此通常只能用于加密少量数据或者加密密钥,但RSA仍然不失为一种高强度的算法。
使用场景:项目中除了登陆,支付等接口采用rsa非对称加密,之外的采用aes对称加密,今天我们来认识一下aes加密。
什么是MD5加密?
MD5英文全称“Message-Digest Algorithm 5”,翻译过来是“消息摘要算法5”,由MD2、MD3、MD4演变过来的,是一种单向加密算法,是不可逆的一种的加密方式。
MD5加密有哪些特点?
压缩性:任意长度的数据,算出的MD5值长度都是固定的。
容易计算:从原数据计算出MD5值很容易。
抗修改性:对原数据进行任何改动,哪怕只修改1个字节,所得到的MD5值都有很大区别。
强抗碰撞:已知原数据和其MD5值,想找到一个具有相同MD5值的数据(即伪造数据)是非常困难的。
MD5应用场景:
一致性验证
数字签名
安全访问认证
什么是aes加密?
高级加密标准(英语:Advanced Encryption Standard,缩写:AES),在密码学中又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准。这个标准用来替代原先的DES,已经被多方分析且广为全世界所使用。
HashMap的实现原理:
HashMap是基于哈希表的map接口的非同步实现,它允许使用null值作为key和value。在Java编程语言中最基本的结构就是两种,一种是数组,另一种是模拟指针(引用)。所有的数据结构都可以用这两个基本的结构来构造,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构。即数组和链表的结合体。
HashMap底层就是一个数据结构,数组中的每一项又是一个链表。
冲突:
HashMap中调用Hashcode()方法计算Hashclde值,由于Java中两个不同的对象可能有一样的Hashcode。就导致了冲突的产生。
解决:
HashMap在put时候,底层源码可以看出,当程序试图将一个key-value对象放入到HashMap中,首先根据该key的hashCode()返回值决定该Entry的存储位置,如果两个Entry的key的hashCode()方法返回值相同,那他们的存储位置相同,如果这两个Entry的key通过equals比较返回true,新添加的Entry的value将会覆盖原来的Entry的value,但是key不会被覆盖,反之,如果返回false,新添加的Entry将与集合中原有的Entry形成Entry链,新添加的位于头部,旧的位于尾部
HashMap的实现原理:
===========================
1、Activity生命周期?
onCreate() -> onStart() -> onResume() -> onPause() -> onStop() -> onDetroy()
2、Service生命周期?
service 启动方式有两种,一种是通过startService()方式进行启动,另一种是通过bindService()方式进行启动。不同的启动方式他们的生命周期是不一样.
通过startService()这种方式启动的service,生命周期是这样:调用startService() --> onCreate()--> onStartConmon()--> onDestroy()。这种方式启动的话,需要注意一下几个问题,第一:当我们通过startService被调用以后,多次在调用startService(),onCreate()方法也只会被调用一次,而onStartConmon()会被多次调用当我们调用stopService()的时候,onDestroy()就会被调用,从而销毁服务。第二:当我们通过startService启动时候,通过intent传值,在onStartConmon()方法中获取值的时候,一定要先判断intent是否为null。
通过bindService()方式进行绑定,这种方式绑定service,生命周期走法:bindService-->onCreate()-->onBind()-->unBind()-->onDestroy() bingservice 这种方式进行启动service好处是更加便利activity中操作service,比如加入service中有几个方法,a,b ,如果要在activity中调用,在需要在activity获取ServiceConnection对象,通过ServiceConnection来获取service中内部类的类对象,然后通过这个类对象就可以调用类中的方法,当然这个类需要继承Binder对象
3、Activity的启动过程(不要回答生命周期)
app启动的过程有两种情况,第一种是从桌面launcher上点击相应的应用图标,第二种是在activity中通过调用startActivity来启动一个新的activity。
我们创建一个新的项目,默认的根activity都是MainActivity,而所有的activity都是保存在堆栈中的,我们启动一个新的activity就会放在上一个activity上面,而我们从桌面点击应用图标的时候,由于launcher本身也是一个应用,当我们点击图标的时候,系统就会调用startActivitySately(),一般情况下,我们所启动的activity的相关信息都会保存在intent中,比如action,category等等。我们在安装这个应用的时候,系统也会启动一个PackaManagerService的管理服务,这个管理服务会对AndroidManifest.xml文件进行解析,从而得到应用程序中的相关信息,比如service,activity,Broadcast等等,然后获得相关组件的信息。当我们点击应用图标的时候,就会调用startActivitySately()方法,而这个方法内部则是调用startActivty(),而startActivity()方法最终还是会调用startActivityForResult()这个方法。而在startActivityForResult()这个方法。因为startActivityForResult()方法是有返回结果的,所以系统就直接给一个-1,就表示不需要结果返回了。而startActivityForResult()这个方法实际是通过Instrumentation类中的execStartActivity()方法来启动activity,Instrumentation这个类主要作用就是监控程序和系统之间的交互。而在这个execStartActivity()方法中会获取ActivityManagerService的代理对象,通过这个代理对象进行启动activity。启动会就会调用一个checkStartActivityResult()方法,如果说没有在配置清单中配置有这个组件,就会在这个方法中抛出异常了。当然最后是调用的是Application.scheduleLaunchActivity()进行启动activity,而这个方法中通过获取得到一个ActivityClientRecord对象,而这个ActivityClientRecord通过handler来进行消息的发送,系统内部会将每一个activity组件使用ActivityClientRecord对象来进行描述,而ActivityClientRecord对象中保存有一个LoaderApk对象,通过这个对象调用handleLaunchActivity来启动activity组件,而页面的生命周期方法也就是在这个方法中进行调用。
4、Broadcast注册方式与区别
此处延伸:什么情况下用动态注册
Broadcast广播,注册方式主要有两种.
第一种是静态注册,也可成为常驻型广播,这种广播需要在Androidmanifest.xml中进行注册,这中方式注册的广播,不受页面生命周期的影响,即使退出了页面,也可以收到广播这种广播一般用于想开机自启动啊等等,由于这种注册的方式的广播是常驻型广播,所以会占用CPU的资源。
第二种是动态注册,而动态注册的话,是在代码中注册的,这种注册方式也叫非常驻型广播,收到生命周期的影响,退出页面后,就不会收到广播,我们通常运用在更新UI方面。这种注册方式优先级较高。最后需要解绑,否会会内存泄露
广播是分为有序广播和无序广播。
5、HttpClient与HttpUrlConnection的区别
此处延伸:Volley里用的哪种请求方式(2.3前HttpClient,2.3后HttpUrlConnection)
首先HttpClient和HttpUrlConnection 这两种方式都支持Https协议,都是以流的形式进行上传或者下载数据,也可以说是以流的形式进行数据的传输,还有ipv6,以及连接池等功能。HttpClient这个拥有非常多的API,所以如果想要进行扩展的话,并且不破坏它的兼容性的话,很难进行扩展,也就是这个原因,Google在Android6.0的时候,直接就弃用了这个HttpClient.
而HttpUrlConnection相对来说就是比较轻量级了,API比较少,容易扩展,并且能够满足Android大部分的数据传输。比较经典的一个框架volley,在2.3版本以前都是使用HttpClient,在2.3以后就使用了HttpUrlConnection。
6、java虚拟机和Dalvik虚拟机的区别
Java虚拟机:
1、java虚拟机基于栈。 基于栈的机器必须使用指令来载入和操作栈上数据,所需指令更多更多。
2、java虚拟机运行的是java字节码。(java类会被编译成一个或多个字节码.class文件)
Dalvik虚拟机:
1、dalvik虚拟机是基于寄存器的
2、Dalvik运行的是自定义的.dex字节码格式。(java类被编译成.class文件后,会通过一个dx工具将所有的.class文件转换成一个.dex文件,然后dalvik虚拟机会从其中读取指令和数据
3、常量池已被修改为只使用32位的索引,以 简化解释器。
4、一个应用,一个虚拟机实例,一个进程(所有android应用的线程都是对应一个linux线程,都运行在自己的沙盒中,不同的应用在不同的进程中运行。每个android dalvik应用程序都被赋予了一个独立的linux PID(app_*))
7、进程保活(不死进程)
此处延伸:进程的优先级是什么
当前业界的Android进程保活手段主要分为** 黑、白、灰 **三种,其大致的实现思路如下:
黑色保活:不同的app进程,用广播相互唤醒(包括利用系统提供的广播进行唤醒)
白色保活:启动前台Service
灰色保活:利用系统的漏洞启动前台Service
黑色保活
所谓黑色保活,就是利用不同的app进程使用广播来进行相互唤醒。举个3个比较常见的场景:
场景1:开机,网络切换、拍照、拍视频时候,利用系统产生的广播唤醒app
场景2:接入第三方SDK也会唤醒相应的app进程,如微信sdk会唤醒微信,支付宝sdk会唤醒支付宝。由此发散开去,就会直接触发了下面的 场景3
场景3:假如你手机里装了支付宝、淘宝、天猫、UC等阿里系的app,那么你打开任意一个阿里系的app后,有可能就顺便把其他阿里系的app给唤醒了。(只是拿阿里打个比方,其实BAT系都差不多)
白色保活
白色保活手段非常简单,就是调用系统api启动一个前台的Service进程,这样会在系统的通知栏生成一个Notification,用来让用户知道有这样一个app在运行着,哪怕当前的app退到了后台。如下方的LBE和QQ音乐这样:
灰色保活
灰色保活,这种保活手段是应用范围最广泛。它是利用系统的漏洞来启动一个前台的Service进程,与普通的启动方式区别在于,它不会在系统通知栏处出现一个Notification,看起来就如同运行着一个后台Service进程一样。这样做带来的好处就是,用户无法察觉到你运行着一个前台进程(因为看不到Notification),但你的进程优先级又是高于普通后台进程的。那么如何利用系统的漏洞呢,大致的实现思路和代码如下:
思路一:API < 18,启动前台Service时直接传入new Notification();
思路二:API >= 18,同时启动两个id相同的前台Service,然后再将后启动的Service做stop处理
熟悉Android系统的童鞋都知道,系统出于体验和性能上的考虑,app在退到后台时系统并不会真正的kill掉这个进程,而是将其缓存起来。打开的应用越多,后台缓存的进程也越多。在系统内存不足的情况下,系统开始依据自身的一套进程回收机制来判断要kill掉哪些进程,以腾出内存来供给需要的app。这套杀进程回收内存的机制就叫 Low Memory Killer ,它是基于Linux内核的 OOM Killer(Out-Of-Memory killer)机制诞生。
进程的重要性,划分5级:
前台进程 (Foreground process)
可见进程 (Visible process)
服务进程 (Service process)
后台进程 (Background process)
空进程 (Empty process)
了解完 Low Memory Killer,再科普一下oom_adj。什么是oom_adj?它是linux内核分配给每个系统进程的一个值,代表进程的优先级,进程回收机制就是根据这个优先级来决定是否进行回收。对于oom_adj的作用,你只需要记住以下几点即可:
进程的oom_adj越大,表示此进程优先级越低,越容易被杀回收;越小,表示进程优先级越高,越不容易被杀回收
普通app进程的oom_adj>=0,系统进程的oom_adj才可能<0
有些手机厂商把这些知名的app放入了自己的白名单中,保证了进程不死来提高用户体验(如微信、QQ、陌陌都在小米的白名单中)。如果从白名单中移除,他们终究还是和普通app一样躲避不了被杀的命运,为了尽量避免被杀,还是老老实实去做好优化工作吧。
所以,进程保活的根本方案终究还是回到了性能优化上,进程永生不死终究是个彻头彻尾的伪命题!
8、讲解一下Context
Context是一个抽象基类。在翻译为上下文,也可以理解为环境,是提供一些程序的运行环境基础信息。Context下有两个子类,ContextWrapper是上下文功能的封装类,而ContextImpl则是上下文功能的实现类。而ContextWrapper又有三个直接的子类, ContextThemeWrapper、Service和Application。其中,ContextThemeWrapper是一个带主题的封装类,而它有一个直接子类就是Activity,所以Activity和Service以及Application的Context是不一样的,只有Activity需要主题,Service不需要主题。Context一共有三种类型,分别是Application、Activity和Service。这三个类虽然分别各种承担着不同的作用,但它们都属于Context的一种,而它们具体Context的功能则是由ContextImpl类去实现的,因此在绝大多数场景下,Activity、Service和Application这三种类型的Context都是可以通用的。不过有几种场景比较特殊,比如启动Activity,还有弹出Dialog。出于安全原因的考虑,Android是不允许Activity或Dialog凭空出现的,一个Activity的启动必须要建立在另一个Activity的基础之上,也就是以此形成的返回栈。而Dialog则必须在一个Activity上面弹出(除非是System Alert类型的Dialog),因此在这种场景下,我们只能使用Activity类型的Context,否则将会出错。
getApplicationContext()和getApplication()方法得到的对象都是同一个application对象,只是对象的类型不一样。
Context数量 = Activity数量 + Service数量 + 1 (1为Application)
9、理解Activity,View,Window三者关系
这个问题真的很不好回答。所以这里先来个算是比较恰当的比喻来形容下它们的关系吧。Activity像一个工匠(控制单元),Window像窗户(承载模型),View像窗花(显示视图)LayoutInflater像剪刀,Xml配置像窗花图纸。
1:Activity构造的时候会初始化一个Window,准确的说是PhoneWindow。
2:这个PhoneWindow有一个“ViewRoot”,这个“ViewRoot”是一个View或者说ViewGroup,是最初始的根视图。
3:“ViewRoot”通过addView方法来一个个的添加View。比如TextView,Button等
4:这些View的事件监听,是由WindowManagerService来接受消息,并且回调Activity函数。比如onClickListener,onKeyDown等。
10、四种LaunchMode及其使用场景
此处延伸:栈(First In Last Out)与队列(First In First Out)的区别
栈与队列的区别:
1. 队列先进先出,栈先进后出
2. 对插入和删除操作的"限定"。 栈是限定只能在表的一端进行插入和删除操作的线性表。 队列是限定只能在表的一端进行插入和在另一端进行删除操作的线性表。
3. 遍历数据速度不同
standard 模式
这是默认模式,每次激活Activity时都会创建Activity实例,并放入任务栈中。使用场景:大多数Activity。
singleTop 模式
如果在任务的栈顶正好存在该Activity的实例,就重用该实例( 会调用实例的 onNewIntent() ),否则就会创建新的实例并放入栈顶,即使栈中已经存在该Activity的实例,只要不在栈顶,都会创建新的实例。使用场景如新闻类或者阅读类App的内容页面。
singleTask 模式
如果在栈中已经有该Activity的实例,就重用该实例(会调用实例的 onNewIntent() )。重用时,会让该实例回到栈顶,因此在它上面的实例将会被移出栈。如果栈中不存在该实例,将会创建新的实例放入栈中。使用场景如浏览器的主界面。不管从多少个应用启动浏览器,只会启动主界面一次,其余情况都会走onNewIntent,并且会清空主界面上面的其他页面。
singleInstance 模式
在一个新栈中创建该Activity的实例,并让多个应用共享该栈中的该Activity实例。一旦该模式的Activity实例已经存在于某个栈中,任何应用再激活该Activity时都会重用该栈中的实例( 会调用实例的 onNewIntent() )。其效果相当于多个应用共享一个应用,不管谁激活该 Activity 都会进入同一个应用中。使用场景如闹铃提醒,将闹铃提醒与闹铃设置分离。singleInstance不要用于中间页面,如果用于中间页面,跳转会有问题,比如:A -> B (singleInstance) -> C,完全退出后,在此启动,首先打开的是B。
11、View的绘制流程
自定义控件:
1、组合控件。这种自定义控件不需要我们自己绘制,而是使用原生控件组合成的新控件。如标题栏。
2、继承原有的控件。这种自定义控件在原生控件提供的方法外,可以自己添加一些方法。如制作圆角,圆形图片。
3、完全自定义控件:这个View上所展现的内容全部都是我们自己绘制出来的。比如说制作水波纹进度条。
View的绘制流程:OnMeasure()——>OnLayout()——>OnDraw()
第一步:OnMeasure():测量视图大小。从顶层父View到子View递归调用measure方法,measure方法又回调OnMeasure。
第二步:OnLayout():确定View位置,进行页面布局。从顶层父View向子View的递归调用view.layout方法的过程,即父View根据上一步measure子View所得到的布局大小和布局参数,将子View放在合适的位置上。
第三步:OnDraw():绘制视图。ViewRoot创建一个Canvas对象,然后调用OnDraw()。六个步骤:①、绘制视图的背景;②、保存画布的图层(Layer);③、绘制View的内容;④、绘制View子视图,如果没有就不用;
⑤、还原图层(Layer);⑥、绘制滚动条。
12、View,ViewGroup事件分
1. Touch事件分发中只有两个主角:ViewGroup和View。ViewGroup包含onInterceptTouchEvent、dispatchTouchEvent、onTouchEvent三个相关事件。View包含dispatchTouchEvent、onTouchEvent两个相关事件。其中ViewGroup又继承于View。
2.ViewGroup和View组成了一个树状结构,根节点为Activity内部包含的一个ViwGroup。
3.触摸事件由Action_Down、Action_Move、Aciton_UP组成,其中一次完整的触摸事件中,Down和Up都只有一个,Move有若干个,可以为0个。
4.当Acitivty接收到Touch事件时,将遍历子View进行Down事件的分发。ViewGroup的遍历可以看成是递归的。分发的目的是为了找到真正要处理本次完整触摸事件的View,这个View会在onTouchuEvent结果返回true。
5.当某个子View返回true时,会中止Down事件的分发,同时在ViewGroup中记录该子View。接下去的Move和Up事件将由该子View直接进行处理。由于子View是保存在ViewGroup中的,多层ViewGroup的节点结构时,上级ViewGroup保存的会是真实处理事件的View所在的ViewGroup对象:如ViewGroup0-ViewGroup1-TextView的结构中,TextView返回了true,它将被保存在ViewGroup1中,而ViewGroup1也会返回true,被保存在ViewGroup0中。当Move和UP事件来时,会先从ViewGroup0传递至ViewGroup1,再由ViewGroup1传递至TextView。
6.当ViewGroup中所有子View都不捕获Down事件时,将触发ViewGroup自身的onTouch事件。触发的方式是调用super.dispatchTouchEvent函数,即父类View的dispatchTouchEvent方法。在所有子View都不处理的情况下,触发Acitivity的onTouchEvent方法。
7.onInterceptTouchEvent有两个作用:1.拦截Down事件的分发。2.中止Up和Move事件向目标View传递,使得目标View所在的ViewGroup捕获Up和Move事件。
13、保存Activity状态
onSaveInstanceState(Bundle)会在activity转入后台状态之前被调用,也就是onStop()方法之前,onPause方法之后被调用;
14、Android中的几种动画
帧动画:指通过指定每一帧的图片和播放时间,有序的进行播放而形成动画效果,比如想听的律动条。
补间动画:指通过指定View的初始状态、变化时间、方式,通过一系列的算法去进行图形变换,从而形成动画效果,主要有Alpha、Scale、Translate、Rotate四种效果。注意:只是在视图层实现了动画效果,并没有真正改变View的属性,比如滑动列表,改变标题栏的透明度。
属性动画:在Android3.0的时候才支持,通过不断的改变View的属性,不断的重绘而形成动画效果。相比于视图动画,View的属性是真正改变了。比如view的旋转,放大,缩小。
15、Android中跨进程通讯的几种方式
Android 跨进程通信,像intent,contentProvider,广播,service都可以跨进程通信。
intent:这种跨进程方式并不是访问内存的形式,它需要传递一个uri,比如说打电话。
contentProvider:这种形式,是使用数据共享的形式进行数据共享。
service:远程服务,aidl
广播
16、AIDL理解
此处延伸:简述Binder
AIDL: 每一个进程都有自己的Dalvik VM实例,都有自己的一块独立的内存,都在自己的内存上存储自己的数据,执行着自己的操作,都在自己的那片狭小的空间里过完自己的一生。而aidl就类似与两个进程之间的桥梁,使得两个进程之间可以进行数据的传输,跨进程通信有多种选择,比如 BroadcastReceiver , Messenger 等,但是 BroadcastReceiver 占用的系统资源比较多,如果是频繁的跨进程通信的话显然是不可取的;Messenger 进行跨进程通信时请求队列是同步进行的,无法并发执行。
Binde机制简单理解:
在Android系统的Binder机制中,是有Client,Service,ServiceManager,Binder驱动程序组成的,其中Client,service,Service Manager运行在用户空间,Binder驱动程序是运行在内核空间的。而Binder就是把这4种组件粘合在一块的粘合剂,其中核心的组件就是Binder驱动程序,Service Manager提供辅助管理的功能,而Client和Service正是在Binder驱动程序和Service Manager提供的基础设施上实现C/S 之间的通信。其中Binder驱动程序提供设备文件/dev/binder与用户控件进行交互,
Client、Service,Service Manager通过open和ioctl文件操作相应的方法与Binder驱动程序进行通信。而Client和Service之间的进程间通信是通过Binder驱动程序间接实现的。而Binder Manager是一个守护进程,用来管理Service,并向Client提供查询Service接口的能力。
17、Handler的原理
Android中主线程是不能进行耗时操作的,子线程是不能进行更新UI的。所以就有了handler,它的作用就是实现线程之间的通信。
handler整个流程中,主要有四个对象,handler,Message,MessageQueue,Looper。当应用创建的时候,就会在主线程中创建handler对象,
我们通过要传送的消息保存到Message中,handler通过调用sendMessage方法将Message发送到MessageQueue中,Looper对象就会不断的调用loop()方法
不断的从MessageQueue中取出Message交给handler进行处理。从而实现线程之间的通信。
18、Binder机制原理
在Android系统的Binder机制中,是有Client,Service,ServiceManager,Binder驱动程序组成的,其中Client,service,Service Manager运行在用户空间,Binder驱动程序是运行在内核空间的。而Binder就是把这4种组件粘合在一块的粘合剂,其中核心的组件就是Binder驱动程序,Service Manager提供辅助管理的功能,而Client和Service正是在Binder驱动程序和Service Manager提供的基础设施上实现C/S 之间的通信。其中Binder驱动程序提供设备文件/dev/binder与用户控件进行交互,Client、Service,Service Manager通过open和ioctl文件操作相应的方法与Binder驱动程序进行通信。而Client和Service之间的进程间通信是通过Binder驱动程序间接实现的。而Binder Manager是一个守护进程,用来管理Service,并向Client提供查询Service接口的能力。
19、热修复的原理
我们知道Java虚拟机 —— JVM 是加载类的class文件的,而Android虚拟机——Dalvik/ART VM 是加载类的dex文件,
而他们加载类的时候都需要ClassLoader,ClassLoader有一个子类BaseDexClassLoader,而BaseDexClassLoader下有一个
数组——DexPathList,是用来存放dex文件,当BaseDexClassLoader通过调用findClass方法时,实际上就是遍历数组,
找到相应的dex文件,找到,则直接将它return。而热修复的解决方法就是将新的dex添加到该集合中,并且是在旧的dex的前面,
所以就会优先被取出来并且return返回。
20、Android内存泄露及管理
(1)内存溢出(OOM)和内存泄露(对象无法被回收)的区别。
(2)引起内存泄露的原因
(3) 内存泄露检测工具 ------>LeakCanary
内存溢出 out of memory:是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memory;比如申请了一个integer,但给它存了long才能存下的数,那就是内存溢出。内存溢出通俗的讲就是内存不够用。
内存泄露 memory leak:是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光
内存泄露原因:
一、Handler 引起的内存泄漏。
解决:将Handler声明为静态内部类,就不会持有外部类SecondActivity的引用,其生命周期就和外部类无关,
如果Handler里面需要context的话,可以通过弱引用方式引用外部类
二、单例模式引起的内存泄漏。
解决:Context是ApplicationContext,由于ApplicationContext的生命周期是和app一致的,不会导致内存泄漏
三、非静态内部类创建静态实例引起的内存泄漏。
解决:把内部类修改为静态的就可以避免内存泄漏了
四、非静态匿名内部类引起的内存泄漏。
解决:将匿名内部类设置为静态的。
五、注册/反注册未成对使用引起的内存泄漏。
注册广播接受器、EventBus等,记得解绑。
六、资源对象没有关闭引起的内存泄漏。
在这些资源不使用的时候,记得调用相应的类似close()、destroy()、recycler()、release()等方法释放。
七、集合对象没有及时清理引起的内存泄漏。
通常会把一些对象装入到集合中,当不使用的时候一定要记得及时清理集合,让相关对象不再被引用。
21、Fragment与Fragment、Activity通信的方式
1.直接在一个Fragment中调用另外一个Fragment中的方法
2.使用接口回调
3.使用广播
4.Fragment直接调用Activity中的public方法
22、Android UI适配
字体使用sp,使用dp,多使用match_parent,wrap_content,weight
图片资源,不同图片的的分辨率,放在相应的文件夹下可使用百分比代替。
23、app优化
app优化:(工具:Hierarchy Viewer 分析布局 工具:TraceView 测试分析耗时的)
App启动优化
布局优化
响应优化
内存优化
电池使用优化
网络优化
App启动优化(针对冷启动)
App启动的方式有三种:
冷启动:App没有启动过或App进程被killed, 系统中不存在该App进程, 此时启动App即为冷启动。
热启动:热启动意味着你的App进程只是处于后台, 系统只是将其从后台带到前台, 展示给用户。
介于冷启动和热启动之间, 一般来说在以下两种情况下发生:
(1)用户back退出了App, 然后又启动. App进程可能还在运行, 但是activity需要重建。
(2)用户退出App后, 系统可能由于内存原因将App杀死, 进程和activity都需要重启, 但是可以在onCreate中将被动杀死锁保存的状态(saved instance state)恢复。
优化:
Application的onCreate(特别是第三方SDK初始化),首屏Activity的渲染都不要进行耗时操作,如果有,就可以放到子线程或者IntentService中
布局优化
尽量不要过于复杂的嵌套。可以使用
响应优化
Android系统每隔16ms会发出VSYNC信号重绘我们的界面(Activity)。
页面卡顿的原因:
(1)过于复杂的布局.
(2)UI线程的复杂运算
(3)频繁的GC,导致频繁GC有两个原因:1、内存抖动, 即大量的对象被创建又在短时间内马上被释放.2、瞬间产生大量的对象会严重占用内存区域。
内存优化:参考内存泄露和内存溢出部分
电池使用优化(使用工具:Batterystats & bugreport)
(1)优化网络请求
(2)定位中使用GPS, 请记得及时关闭
网络优化(网络连接对用户的影响:流量,电量,用户等待)可在Android studio下方logcat旁边那个工具Network Monitor检测
API设计:App与Server之间的API设计要考虑网络请求的频次, 资源的状态等. 以便App可以以较少的请求来完成业务需求和界面的展示.
Gzip压缩:使用Gzip来压缩request和response, 减少传输数据量, 从而减少流量消耗.
图片的Size:可以在获取图片时告知服务器需要的图片的宽高, 以便服务器给出合适的图片, 避免浪费.
网络缓存:适当的缓存, 既可以让我们的应用看起来更快, 也能避免一些不必要的流量消耗.
24、图片优化
(1)对图片本身进行操作。尽量不要使用setImageBitmap、setImageResource、BitmapFactory.decodeResource来设置一张大图,因为这些方法在完成decode后,
最终都是通过java层的createBitmap来完成的,需要消耗更多内存.
(2)图片进行缩放的比例,SDK中建议其值是2的指数值,值越大会导致图片不清晰。
(3)不用的图片记得调用图片的recycle()方法
25、HybridApp WebView和JS交互
Android与JS通过WebView互相调用方法,实际上是:
Android去调用JS的代码
1. 通过WebView的loadUrl(),使用该方法比较简洁,方便。但是效率比较低,获取返回值比较困难。
2. 通过WebView的evaluateJavascript(),该方法效率高,但是4.4以上的版本才支持,4.4以下版本不支持。所以建议两者混合使用。
JS去调用Android的代码
1. 通过WebView的addJavascriptInterface()进行对象映射 ,该方法使用简单,仅将Android对象和JS对象映射即可,但是存在比较大的漏洞。
漏洞产生原因是:当JS拿到Android这个对象后,就可以调用这个Android对象中所有的方法,包括系统类(java.lang.Runtime 类),从而进行任意代码执行。
解决方式:
(1)Google 在Android 4.2 版本中规定对被调用的函数以 @JavascriptInterface进行注解从而避免漏洞攻击。
(2)在Android 4.2版本之前采用拦截prompt()进行漏洞修复。
2. 通过 WebViewClient 的shouldOverrideUrlLoading ()方法回调拦截 url 。这种方式的优点:不存在方式1的漏洞;缺点:JS获取Android方法的返回值复杂。(ios主要用的是这个方式)
(1)Android通过 WebViewClient 的回调方法shouldOverrideUrlLoading ()拦截 url
(2)解析该 url 的协议
(3)如果检测到是预先约定好的协议,就调用相应方法
3. 通过 WebChromeClient 的onJsAlert()、onJsConfirm()、onJsPrompt()方法回调拦截JS对话框alert()、confirm()、prompt() 消息
这种方式的优点:不存在方式1的漏洞;缺点:JS获取Android方法的返回值复杂。
26、JAVA GC原理
垃圾收集算法的核心思想是:对虚拟机可用内存空间,即堆空间中的对象进行识别,如果对象正在被引用,那么称其为存活对象
,反之,如果对象不再被引用,则为垃圾对象,可以回收其占据的空间,用于再分配。垃圾收集算法的选择和垃圾收集系统参数的合理调节直接影响着系统性能。
27、ANR
ANR全名Application Not Responding, 也就是"应用无响应". 当操作在一段时间内系统无法处理时, 系统层面会弹出上图那样的ANR对话框.
产生原因:
(1)5s内无法响应用户输入事件(例如键盘输入, 触摸屏幕等).
(2)BroadcastReceiver在10s内无法结束
(3)Service 20s内无法结束(低概率)
解决方式:
(1)不要在主线程中做耗时的操作,而应放在子线程中来实现。如onCreate()和onResume()里尽可能少的去做创建操作。
(2)应用程序应该避免在BroadcastReceiver里做耗时的操作或计算。
(3)避免在Intent Receiver里启动一个Activity,因为它会创建一个新的画面,并从当前用户正在运行的程序上抢夺焦点。
(4)service是运行在主线程的,所以在service中做耗时操作,必须要放在子线程中。
28、设计模式
此处延伸:Double Check的写法被要求写出来。
单例模式:分为恶汉式和懒汉式
恶汉式:
1 2 3 4 5 6 7 8 9 |
|
懒汉式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
29、RxJava
30、MVP,MVC,MVVM
此处延伸:手写mvp例子,与mvc之间的区别,mvp的优势
MVP模式,对应着Model--业务逻辑和实体模型,view--对应着activity,负责View的绘制以及与用户交互,Presenter--负责View和Model之间的交互,MVP模式是在MVC模式的基础上,将Model与View彻底分离使得项目的耦合性更低,在Mvc中项目中的activity对应着mvc中的C--Controllor,而项目中的逻辑处理都是在这个C中处理,同时View与Model之间的交互,也是也就是说,mvc中所有的逻辑交互和用户交互,都是放在Controllor中,也就是activity中。View和model是可以直接通信的。而MVP模式则是分离的更加彻底,分工更加明确Model--业务逻辑和实体模型,view--负责与用户交互,Presenter 负责完成View于Model间的交互,MVP和MVC最大的区别是MVC中是允许Model和View进行交互的,而MVP中很明显,Model与View之间的交互由Presenter完成。还有一点就是Presenter与View之间的交互是通过接口的
31、手写算法(选择冒泡必须要会)
32、JNI
(1)安装和下载Cygwin,下载 Android NDK
(2)在ndk项目中JNI接口的设计
(3)使用C/C++实现本地方法
(4)JNI生成动态链接库.so文件
(5)将动态链接库复制到java工程,在java工程中调用,运行java工程即可
33、RecyclerView和ListView的区别
RecyclerView可以完成ListView,GridView的效果,还可以完成瀑布流的效果。同时还可以设置列表的滚动方向(垂直或者水平);
RecyclerView中view的复用不需要开发者自己写代码,系统已经帮封装完成了。
RecyclerView可以进行局部刷新。
RecyclerView提供了API来实现item的动画效果。
在性能上:
如果需要频繁的刷新数据,需要添加动画,则RecyclerView有较大的优势。
如果只是作为列表展示,则两者区别并不是很大。
34、Universal-ImageLoader,Picasso,Fresco,Glide对比
Fresco 是 Facebook 推出的开源图片缓存工具,主要特点包括:两个内存缓存加上 Native 缓存构成了三级缓存,
优点:
1. 图片存储在安卓系统的匿名共享内存, 而不是虚拟机的堆内存中, 图片的中间缓冲数据也存放在本地堆内存, 所以, 应用程序有更多的内存使用, 不会因为图片加载而导致oom, 同时也减少垃圾回收器频繁调用回收 Bitmap 导致的界面卡顿, 性能更高。
2. 渐进式加载 JPEG 图片, 支持图片从模糊到清晰加载。
3. 图片可以以任意的中心点显示在 ImageView, 而不仅仅是图片的中心。
4. JPEG 图片改变大小也是在 native 进行的, 不是在虚拟机的堆内存, 同样减少 OOM。
5. 很好的支持 GIF 图片的显示。
缺点:
1. 框架较大, 影响 Apk 体积
2. 使用较繁琐
Universal-ImageLoader:(估计由于HttpClient被Google放弃,作者就放弃维护这个框架)
优点:
1.支持下载进度监听
2.可以在 View 滚动中暂停图片加载,通过 PauseOnScrollListener 接口可以在 View 滚动中暂停图片加载。
3.默认实现多种内存缓存算法 这几个图片缓存都可以配置缓存算法,不过 ImageLoader 默认实现了较多缓存算法,如 Size 最大先删除、使用最少先删除、最近最少使用、先进先删除、时间最长先删除等。
4.支持本地缓存文件名规则定义
Picasso 优点
1. 自带统计监控功能。支持图片缓存使用的监控,包括缓存命中率、已使用内存大小、节省的流量等。
2.支持优先级处理。每次任务调度前会选择优先级高的任务,比如 App 页面中 Banner 的优先级高于 Icon 时就很适用。
3.支持延迟到图片尺寸计算完成加载
4.支持飞行模式、并发线程数根据网络类型而变。 手机切换到飞行模式或网络类型变换时会自动调整线程池最大并发数,比如 wifi 最大并发为 4,4g 为 3,3g 为 2。 这里 Picasso 根据网络类型来决定最大并发数,而不是 CPU 核数。
5.“无”本地缓存。无”本地缓存,不是说没有本地缓存,而是 Picasso 自己没有实现,交给了 Square 的另外一个网络库 okhttp 去实现,这样的好处是可以通过请求 Response Header 中的 Cache-Control 及 Expired 控制图片的过期时间。
Glide 优点
1. 不仅仅可以进行图片缓存还可以缓存媒体文件。Glide 不仅是一个图片缓存,它支持 Gif、WebP、缩略图。甚至是 Video,所以更该当做一个媒体缓存。
2. 支持优先级处理。
3. 与 Activity/Fragment 生命周期一致,支持 trimMemory。Glide 对每个 context 都保持一个 RequestManager,通过 FragmentTransaction 保持与 Activity/Fragment 生命周期一致,并且有对应的 trimMemory 接口实现可供调用。
4. 支持 okhttp、Volley。Glide 默认通过 UrlConnection 获取数据,可以配合 okhttp 或是 Volley 使用。实际 ImageLoader、Picasso 也都支持 okhttp、Volley。
5. 内存友好。Glide 的内存缓存有个 active 的设计,从内存缓存中取数据时,不像一般的实现用 get,而是用 remove,再将这个缓存数据放到一个 value 为软引用的 activeResources map 中,并计数引用数,在图片加载完成后进行判断,如果引用计数为空则回收掉。内存缓存更小图片,Glide 以 url、view_width、view_height、屏幕的分辨率等做为联合 key,将处理后的图片缓存在内存缓存中,而不是原始图片以节省大小与 Activity/Fragment 生命周期一致,支持 trimMemory。图片默认使用默认 RGB_565 而不是 ARGB_888,虽然清晰度差些,但图片更小,也可配置到 ARGB_888。
6.Glide 可以通过 signature 或不使用本地缓存支持 url 过期
42、Xutils, OKhttp, Volley, Retrofit对比
Xutils这个框架非常全面,可以进行网络请求,可以进行图片加载处理,可以数据储存,还可以对view进行注解,使用这个框架非常方便,但是缺点也是非常明显的,使用这个项目,会导致项目对这个框架依赖非常的严重,一旦这个框架出现问题,那么对项目来说影响非常大的。、
OKhttp:Android开发中是可以直接使用现成的api进行网络请求的。就是使用HttpClient,HttpUrlConnection进行操作。okhttp针对Java和Android程序,封装的一个高性能的http请求库,支持同步,异步,而且okhttp又封装了线程池,封装了数据转换,封装了参数的使用,错误处理等。API使用起来更加的方便。但是我们在项目中使用的时候仍然需要自己在做一层封装,这样才能使用的更加的顺手。
Volley:Volley是Google官方出的一套小而巧的异步请求库,该框架封装的扩展性很强,支持HttpClient、HttpUrlConnection, 甚至支持OkHttp,而且Volley里面也封装了ImageLoader,所以如果你愿意你甚至不需要使用图片加载框架,不过这块功能没有一些专门的图片加载框架强大,对于简单的需求可以使用,稍复杂点的需求还是需要用到专门的图片加载框架。Volley也有缺陷,比如不支持post大数据,所以不适合上传文件。不过Volley设计的初衷本身也就是为频繁的、数据量小的网络请求而生。
Retrofit:Retrofit是Square公司出品的默认基于OkHttp封装的一套RESTful网络请求框架,RESTful是目前流行的一套api设计的风格, 并不是标准。Retrofit的封装可以说是很强大,里面涉及到一堆的设计模式,可以通过注解直接配置请求,可以使用不同的http客户端,虽然默认是用http ,可以使用不同Json Converter 来序列化数据,同时提供对RxJava的支持,使用Retrofit + OkHttp + RxJava + Dagger2 可以说是目前比较潮的一套框架,但是需要有比较高的门槛。
Volley VS OkHttp
Volley的优势在于封装的更好,而使用OkHttp你需要有足够的能力再进行一次封装。而OkHttp的优势在于性能更高,因为 OkHttp基于NIO和Okio ,所以性能上要比 Volley更快。IO 和 NIO这两个都是Java中的概念,如果我从硬盘读取数据,第一种方式就是程序一直等,数据读完后才能继续操作这种是最简单的也叫阻塞式IO,还有一种是你读你的,程序接着往下执行,等数据处理完你再来通知我,然后再处理回调。而第二种就是 NIO 的方式,非阻塞式, 所以NIO当然要比IO的性能要好了,而 Okio是 Square 公司基于IO和NIO基础上做的一个更简单、高效处理数据流的一个库。理论上如果Volley和OkHttp对比的话,更倾向于使用 Volley,因为Volley内部同样支持使用OkHttp,这点OkHttp的性能优势就没了, 而且 Volley 本身封装的也更易用,扩展性更好些。
OkHttp VS Retrofit
毫无疑问,Retrofit 默认是基于 OkHttp 而做的封装,这点来说没有可比性,肯定首选 Retrofit。
Volley VS Retrofit
这两个库都做了不错的封装,但Retrofit解耦的更彻底,尤其Retrofit2.0出来,Jake对之前1.0设计不合理的地方做了大量重构, 职责更细分,而且Retrofit默认使用OkHttp,性能上也要比Volley占优势,再有如果你的项目如果采用了RxJava ,那更该使用 Retrofit 。所以这两个库相比,Retrofit更有优势,在能掌握两个框架的前提下该优先使用 Retrofit。但是Retrofit门槛要比Volley稍高些,要理解他的原理,各种用法,想彻底搞明白还是需要花些功夫的,如果你对它一知半解,那还是建议在商业项目使用Volley吧。
Java
1、线程中sleep和wait的区别
(1)这两个方法来自不同的类,sleep是来自Thread,wait是来自Object;
(2)sleep方法没有释放锁,而wait方法释放了锁。
(3)wait,notify,notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用。
2、Thread中的start()和run()方法有什么区别
start()方法是用来启动新创建的线程,而start()内部调用了run()方法,这和直接调用run()方法是不一样的,如果直接调用run()方法,
则和普通的方法没有什么区别。
3、关键字final和static是怎么使用的。
final:
1、final变量即为常量,只能赋值一次。
2、final方法不能被子类重写。
3、final类不能被继承。
static:
1、static变量:对于静态变量在内存中只有一个拷贝(节省内存),JVM只为静态分配一次内存,
在加载类的过程中完成静态变量的内存分配,可用类名直接访问(方便),当然也可以通过对象来访问(但是这是不推荐的)。
2、static代码块
static代码块是类加载时,初始化自动执行的。
3、static方法
static方法可以直接通过类名调用,任何的实例也都可以调用,因此static方法中不能用this和super关键字,
不能直接访问所属类的实例变量和实例方法(就是不带static的成员变量和成员成员方法),只能访问所属类的静态成员变量和成员方法。
4、String,StringBuffer,StringBuilder区别
1、三者在执行速度上:StringBuilder > StringBuffer > String (由于String是常量,不可改变,拼接时会重新创建新的对象)。
2、StringBuffer是线程安全的,StringBuilder是线程不安全的。(由于StringBuffer有缓冲区)
5、Java中重载和重写的区别:
1、重载:一个类中可以有多个相同方法名的,但是参数类型和个数都不一样。这是重载。
2、重写:子类继承父类,则子类可以通过实现父类中的方法,从而新的方法把父类旧的方法覆盖。
6、Http https区别
此处延伸:https的实现原理
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
https实现原理:
(1)客户使用https的URL访问Web服务器,要求与Web服务器建立SSL连接。
(2)Web服务器收到客户端请求后,会将网站的证书信息(证书中包含公钥)传送一份给客户端。
(3)客户端的浏览器与Web服务器开始协商SSL连接的安全等级,也就是信息加密的等级。
(4)客户端的浏览器根据双方同意的安全等级,建立会话密钥,然后利用网站的公钥将会话密钥加密,并传送给网站。
(5)Web服务器利用自己的私钥解密出会话密钥。
(6)Web服务器利用会话密钥加密与客户端之间的通信。
7、Http位于TCP/IP模型中的第几层?为什么说Http是可靠的数据传输协议?
tcp/ip的五层模型:
从下到上:物理层->数据链路层->网络层->传输层->应用层
其中tcp/ip位于模型中的网络层,处于同一层的还有ICMP(网络控制信息协议)。http位于模型中的应用层
由于tcp/ip是面向连接的可靠协议,而http是在传输层基于tcp/ip协议的,所以说http是可靠的数据传输协议。
8、HTTP链接的特点
HTTP连接最显著的特点是客户端发送的每次请求都需要服务器回送响应,在请求结束后,会主动释放连接。
从建立连接到关闭连接的过程称为“一次连接”。
9、TCP和UDP的区别
tcp是面向连接的,由于tcp连接需要三次握手,所以能够最低限度的降低风险,保证连接的可靠性。
udp 不是面向连接的,udp建立连接前不需要与对象建立连接,无论是发送还是接收,都没有发送确认信号。所以说udp是不可靠的。
由于udp不需要进行确认连接,使得UDP的开销更小,传输速率更高,所以实时行更好。
10、Socket建立网络连接的步骤
建立Socket连接至少需要一对套接字,其中一个运行与客户端--ClientSocket,一个运行于服务端--ServiceSocket
1、服务器监听:服务器端套接字并不定位具体的客户端套接字,而是处于等待连接的状态,实时监控网络状态,等待客户端的连接请求。
2、客户端请求:指客户端的套接字提出连接请求,要连接的目标是服务器端的套接字。注意:客户端的套接字必须描述他要连接的服务器的套接字,
指出服务器套接字的地址和端口号,然后就像服务器端套接字提出连接请求。
3、连接确认:当服务器端套接字监听到客户端套接字的连接请求时,就响应客户端套接字的请求,建立一个新的线程,把服务器端套接字的描述
发给客户端,一旦客户端确认了此描述,双方就正式建立连接。而服务端套接字则继续处于监听状态,继续接收其他客户端套接字的连接请求。
11、Tcp/IP三次握手,四次挥手
Atas ialah kandungan terperinci 中高级的Android面试题(含答案). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Tiga rangka kerja utama untuk pembangunan android
Tiga rangka kerja utama untuk pembangunan android
 Apakah sistem android
Apakah sistem android
 Bagaimana untuk membuka kunci sekatan kebenaran android
Bagaimana untuk membuka kunci sekatan kebenaran android
 Apakah kaedah untuk memulakan semula aplikasi dalam Android?
Apakah kaedah untuk memulakan semula aplikasi dalam Android?
 Kaedah pelaksanaan fungsi main balik suara Android
Kaedah pelaksanaan fungsi main balik suara Android
 Apakah maksud aktiviti status pengaktifan win11?
Apakah maksud aktiviti status pengaktifan win11?
 laman web dalam talian java
laman web dalam talian java
 Bagaimana untuk mengulas kod dalam html
Bagaimana untuk mengulas kod dalam html
 apakah julat python
apakah julat python









![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



