


负载均衡的基本思路很简单:在一个服务器集群中尽可能地的平均负载量。基于这个思路,我们通常的做法是在服务器前端设置一个负载均衡器。负载均衡器的作用是将请求的连接路由到最空闲的可用服务器上。
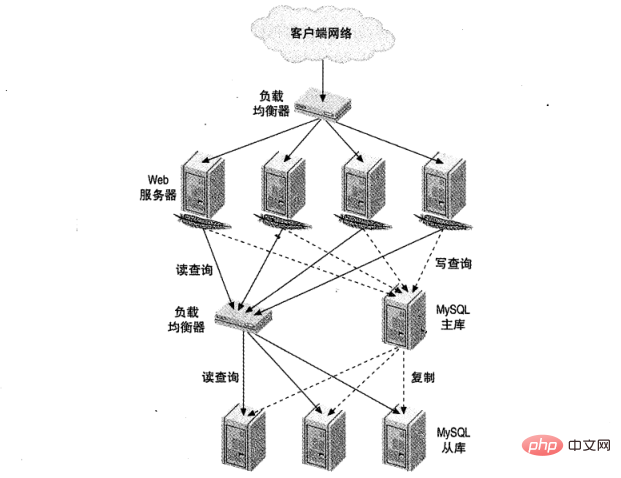
如图 1,显示了一个大型网站负载均衡设置。其中一个负责 HTTP 流量,另一个用于 MySQL 访问。
负载均衡有五个常见目的:
而对于负载均衡的实现,一般有两种方式:直接连接和引入中间件。
相关教程:mysql视频教程
有些人认为负载均衡就是配置在应用和 MySQL 服务器直接东西,但实际上这并不是唯一的负载均衡方法。接下来我们就讨论一下常见的应用直连的方法,及其相关注意事项。
此种方式下,容易出现一个最大的问题:脏数据。一个典型的例子是,当用户评论了一篇博文,然后重新加载页面,却没有看到新增的评论。
当然,我们也不能因为脏数据的问题,就将读写分离弃之不用。实际上,对于很多应用,可能对脏数据的容忍度比较高,此时就可以大胆的引入此种方式。
那么对于脏数据的容忍度比较低的应用,如何进行读写分离呢?接下来,我们对读写分离再进一步区分,相信你总能找到适合自己的一款策略。
1) 基于查询分离
如果应用只有少数数据不能容忍脏数据,我们可以将所有不能容忍脏数据的读和写都分配到 master 上。其它的读查询分配的 slave 上。该策略很容易实现,但如果容忍脏数据的查询比较少,很可能会出现不能有效使用备库的情况。
2) 基于脏数据分离
这是对基于查询分离策略的小改进。需要做一些额外的工作,比如让应用检查复制延迟,以确定备库数据是否最新。许多报表类应用都可以使用这个策略:只需要晚上加载的数据复制到备库接口,并不关心是不是完全跟上了主库。
3) 基于会话分离
这个策略比脏数据分离策略更深入 一些。它是判断用户是否修改了数据,用户不需要看到其他用户的最新数据,只需要看到自己的更新。
具体可以在会话层设置一个标记位,表明用户是否做了更新,用户一旦做了更新,就将该用户的查询在一段时间内指向主库。
这种策略在简单和有效性之间做了很好的妥协,是一种较为推荐的策略。
当然,如果你的想法够多,可以把基于会话的分离策略和复制延迟监控策略结合起来。如果用户在 10 秒前更新了数据,而所有备库延迟在 5 秒内,就可以大胆的从备库中读取数据。要注意的是,记得为整个会话选择同个备库,否则一旦多个备库的延迟不一致,就会给用户造成困扰。
4) 基于全局版本 / 会话分离
通过记录主库日志坐标和备库已复制的坐标对比,确认备库是否更新数据。当应用指向写操作时,在提交事务后,执行一次 SHOW MASTER STATUS 操作,然后将主库日志坐标存储在缓存中,作为被修改对象或者会话的版本号。当应用连接到备库时,执行 SHOW SLAVE STATUS,并将备库上的坐标和缓存中的版本号对比。如果备库比主库记录点更新,就表明备库已更新对应数据,可放心的使用。
实际上,很多读写分离策略都需要监控复制延迟来决定读查询的分配。不过要注意的是,SHOW SLAVE STATUS 得到的 Seconds_behind_master 列的值并不能精确的表示延迟。我们可以使用 Percona Toolkit 中的 pt-heartbeat 工具更好的监控延迟。
对于一些比较简单的应用,可以为不同目的创建 DNS。最简单的方法是只读服务器拥有一个 DNS 名(read.mysql-db.com),给负责写操作的服务器起另外一个 DNS 名(write.mysql-db.com)。如果备库能够跟得上主库,就把只读 DNS 名指向到备库,否则,就指向到主库。
这种策略非常容易实现,但有个很大的问题是:无法完全控制 DNS。
这种策略较为危险,即使可以通过修改 /etc/hosts 文件来避免 DNS 无法完全控制的问题,但仍不失理想策略。
通过在服务器间转移虚拟地址,来实现负载均衡。是不是感觉和修改 DNS 很像?但实际上完全是两码事。转移 IP 地址允许 DNS 名保持不变,我们可以通过 ARP 命令(不了解 ARP,看这里)强制使 IP 地址的更改快速而且原子性的通知到局域网络上。
一个比较方便的技术是为每个物理服务器分配一个固定的 IP 地址。该 IP 地址固定在服务器上,不再改变。然后可以为每个逻辑上的 “服务”(可以理解为容器)使用一个虚拟 IP 地址。
这样,IP 就能够很方便的在服务器间转移,无需重新配置应用,实现也更加容易。
上面的策略都是假定应用是和 MySQL 服务器之间连接的,但是许多负载均衡都会引入一个中间件,作为网络通信的代理。它一边接受所有的通信,另一边将这些请求分发的指定服务器上,并将执行结果发送回请求机器。图 2 展示了此种架构。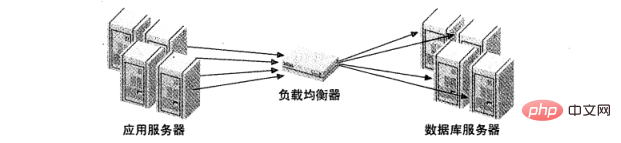
现在有许多负载均衡硬件和软件,但很少有专门为 MySQL 服务器设计的。Web 服务器通常更需要负载均衡,因此许多多用途的负载均衡设备都会支持 HTTP,而对其他用途则只有一些很少的基本特性。
MySQL 连接只是正常的 TCP/IP 连接,所以可以在 MySQL 上使用多用途负载均衡器。但由于缺少 MySQL 专有的特性,因此会多一些限制:
有很多算法用来决定哪个服务器接受下一个连接。每个厂商都有各自不同的算法,有以下常用方法:
上述各种方法没有最好,只有最适合的,这取决于具体的工作负载。
另外,我们只描述了即时处理的算法。但有时候使用排队算法可能会更有效。例如,一个算法可能只维护给定的数据库服务器并发数量,同一时刻只允许不超过 N 个活跃事务。如果有太多的活跃事务,就将新的请求放到一个队列里,然后让可用服务器列表来处理。
最常见的复制结构就是一个主库加多个备库。这种架构的扩展性较差,但我们可以通过一些方法结合负载均衡来获得更好的效果。
我们不能也不应该在应用的开始就就想着把架构做成阿里那样的架构。最好的方式是实现应用当前所明确需要的,并为可能的快速增长做好预先规划。
另外,为可扩展性制定一个数字目标是很有意义的,就像我们为性能制定了一个精确目标,满足 10K 或 100K 并发一样。这样可以通过相关理论避免诸如序列化或交互操作的开销问题带入到我们的应用中。
在 MySQL 扩展策略方面,典型的的应用在增长到非常庞大时,通常先从单个服务器转移到向外扩展的拥有备库的架构,再到数据分片或按功能分区。这里要注意的是,我们不提倡诸如 “尽早分片,尽量分片” 的建议。实际上,分片很复杂,而且成本很高,最主要的是很多应用可能根本不需要。与其花大成本去分片,还不如先去看看新的硬件和新版本的 MySQL 有哪些变化,也许这些新变化会给你带来惊喜。
为扩展性量化指标。
最后,希望本文对你有所帮助。
Atas ialah kandungan terperinci MySQL深入浅出负载均衡. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



