

本文目录:
9.1 进程的简单说明
9.11 进程和程序的区别
9.12 多任务和cpu时间片
9.13 父子进程及创建进程的方式
9.14 进程的状态
9.15 举例分析进程状态转换过程
9.16 进程结构和子shell
9.2 job任务
9.3 终端和进程的关系
9.4 信号
9.41 需知道的信号
9.42 SIGHUP
9.43 僵尸进程和SIGCHLD
9.44 手动发送信号(kill命令)
9.45 pkill和killall
9.5 fuser和lsof
进程是一个非常复杂的概念,涉及的内容也非常非常多。在这一小节所列出内容,已经是我极度简化后的内容了,应该尽可能都理解下来,我觉得这些理论比如何使用命令来查看状态更重要,而且不明白这些理论,后面查看状态信息时基本上不知道状态对应的是什么意思。
但对于非编程人员来说,更多的进程细节也没有必要去深究,当然,多多益善是肯定的。
程序是二进制文件,是静态存放在磁盘上的,不会占用系统运行资源(cpu/内存)。
进程是用户执行程序或者触发程序的结果,可以认为进程是程序的一个运行实例。进程是动态的,会申请和使用系统资源,并与操作系统内核进行交互。在后文中,不少状态统计工具的结果中显示的是system类的状态,其实system状态的同义词就是内核状态。
现在所有的操作系统都能"同时"运行多个进程,也就是多任务或者说是并行执行。但实际上这是人类的错觉,一颗物理cpu在同一时刻只能运行一个进程,只有多颗物理cpu才能真正意义上实现多任务。
人类会产生错觉,以为操作系统能并行做几件事情,这是通过在极短时间内进行进程间切换实现的,因为时间极短,前一刻执行的是进程A,下一刻切换到进程B,不断的在多个进程间进行切换,使得人类以为在同时处理多件事情。
不过,cpu如何选择下一个要执行的进程,这是一件非常复杂的事情。在Linux上,决定下一个要运行的进程是通过"调度类"(调度程序)来实现的。程序何时运行,由进程的优先级决定,但要注意,优先级值越低,优先级就越高,就越快被调度类选中。在Linux中,改变进程的nice值,可以影响某类进程的优先级值。
有些进程比较重要,要让其尽快完成,有些进程则比较次要,早点或晚点完成不会有太大影响,所以操作系统要能够知道哪些进程比较重要,哪些进程比较次要。比较重要的进程,应该多给它分配一些cpu的执行时间,让其尽快完成。下图是cpu时间片的概念。

由此可以知道,所有的进程都有机会运行,但重要的进程总是会获得更多的cpu时间,这种方式是"抢占式多任务处理":内核可以强制在时间片耗尽的情况下收回cpu使用权,并将cpu交给调度类选中的进程,此外,在某些情况下也可以直接抢占当前运行的进程。随着时间的流逝,分配给进程的时间也会被逐渐消耗,当分配时间消耗完毕时,内核收回此进程的控制权,并让下一个进程运行。但因为前面的进程还没有完成,在未来某个时候调度类还是会选中它,所以内核应该将每个进程临时停止时的运行时环境(寄存器中的内容和页表)保存下来(保存位置为内核占用的内存),这称为保护现场,在下次进程恢复运行时,将原来的运行时环境加载到cpu上,这称为恢复现场,这样cpu可以在当初的运行时环境下继续执行。
看书上说,Linux的调度器不是通过cpu的时间片流逝来选择下一个要运行的进程的,而是考虑进程的等待时间,即在就绪队列等待了多久,那些对时间需求最严格的进程应该尽早安排其执行。另外,重要的进程分配的cpu运行时间自然会较多。
调度类选中了下一个要执行的进程后,要进行底层的任务切换,也就是上下文切换,这一过程需要和cpu进程紧密的交互。进程切换不应太频繁,也不应太慢。切换太频繁将导致cpu闲置在保护和恢复现场的时间过长,保护和恢复现场对人类或者进程来说是没有产生生产力的(因为它没有在执行程序)。切换太慢将导致进程调度切换慢,很可能下一个进程要等待很久才能轮到它执行,直白的说,如果你发出一个ls命令,你可能要等半天,这显然是不允许的。
至此,也就知道了cpu的衡量单位是时间,就像内存的衡量单位是空间大小一样。进程占用的cpu时间长,说明cpu运行在它身上的时间就长。注意,cpu的百分比值不是其工作强度或频率高低,而是"进程占用cpu时间/cpu总时间",这个衡量概念一定不要搞错。
根据执行程序的用户UID以及其他标准,会为每一个进程分配一个唯一的PID。
父子进程的概念,简单来说,在某进程(父进程)的环境下执行或调用程序,这个程序触发的进程就是子进程,而进程的PPID表示的是该进程的父进程的PID。由此也知道了,子进程总是由父进程创建。
在Linux,父子进程以树型结构的方式存在,父进程创建出来的多个子进程之间称为兄弟进程。CentOS 6上,init进程是所有进程的父进程,CentOS 7上则为systemd。
Linux上创建子进程的方式有三种(极其重要的概念):一种是fork出来的进程,一种是exec出来的进程,一种是clone出来的进程。
(1).fork是复制进程,它会复制当前进程的副本(不考虑写时复制的模式),以适当的方式将这些资源交给子进程。所以子进程掌握的资源和父进程是一样的,包括内存中的内容,所以也包括环境变量和变量。但父子进程是完全独立的,它们是一个程序的两个实例。
(2).exec是加载另一个应用程序,替代当前运行的进程,也就是说在不创建新进程的情况下加载一个新程序。exec还有一个动作,在进程执行完毕后,退出exec所在的shell。所以为了保证进程安全,若要形成新的且独立的子进程,都会先fork一份当前进程,然后在fork出来的子进程上调用exec来加载新程序替代该子进程。例如在bash下执行cp命令,会先fork出一个bash,然后再exec加载cp程序覆盖子bash进程变成cp进程。
(3).clone用于实现线程。clone的工作原理和fork相同,但clone出来的新进程不独立于父进程,它只会和父进程共享某些资源,在clone进程的时候,可以指定要共享的是哪些资源。
一般情况下,兄弟进程之间是相互独立、互不可见的,但有时候通过特殊手段,它们会实现进程间通信。例如管道协调了两边的进程,两边的进程属于同一个进程组,它们的PPID是一样的,管道使得它们可以以"管道"的方式传递数据。
进程是有所有者的,也就是它的发起者,某个用户如果它非进程发起者、非父进程发起者、非root用户,那么它无法杀死进程。且杀死父进程(非终端进程),会导致子进程变成孤儿进程,孤儿进程的父进程总是init/systemd。
进程并非总是处于运行中,至少cpu没运行在它身上时它就是非运行的。进程有几种状态,不同的状态之间可以实现状态切换。下图是非常经典的进程状态描述图,个人感觉右图更加易于理解。
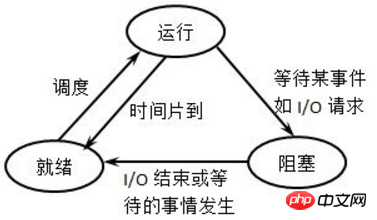
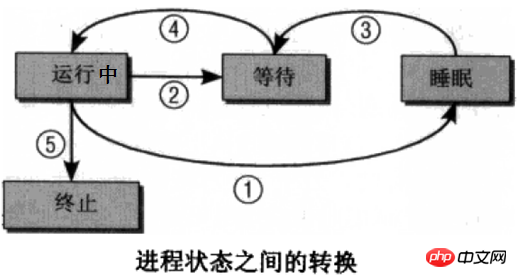
运行态:进程正在运行,也即是cpu正在它身上。
就绪(等待)态:进程可以运行,已经处于等待队列中,也就是说调度类下次可能会选中它
睡眠(阻塞)态:进程睡眠了,不可运行。
各状态之间的转换方式为:(也许可能不太好理解,可以结合稍后的例子)
(1)新状态->就绪态:当等待队列允许接纳新进程时,内核便把新进程移入等待队列。
(2)就绪态->运行态:调度类选中等待队列中的某个进程,该进程进入运行态。
(3)运行态->睡眠态:正在运行的进程因需要等待某事件(如IO等待、信号等待等)的出现而无法执行,进入睡眠态。
(4)睡眠态->就绪态:进程所等待的事件发生了,进程就从睡眠态排入等待队列,等待下次被选中执行。
(5)运行态->就绪态:正在执行的进程因时间片用完而被暂停执行;或者在抢占式调度方式中,高优先级进程强制抢占了正在执行的低优先级进程。
(6)运行态->终止态:一个进程已完成或发生某种特殊事件,进程将变为终止状态。对于命令来说,一般都会返回退出状态码。
注意上面的图中,没有"就绪-->睡眠"和"睡眠-->运行"的状态切换。这很容易理解。对于"就绪-->睡眠",等待中的进程本就已经进入了等待队列,表示可运行,而进入睡眠态表示暂时不可运行,这本身就是冲突的;对于"睡眠-->运行"这也是行不通的,因为调度类只会从等待队列中挑出下一次要运行的进程。
再说说运行态-->睡眠态。从运行态到睡眠态一般是等待某事件的出现,例如等待信号通知,等待IO完成。信号通知很容易理解,而对于IO等待,程序要运行起来,cpu就要执行该程序的指令,同时还需要输入数据,可能是变量数据、键盘输入数据或磁盘文件中的数据,后两种数据相对cpu来说,都是极慢极慢的。但不管怎样,如果cpu在需要数据的那一刻却得不到数据,cpu就只能闲置下来,这肯定是不应该的,因为cpu是极其珍贵的资源,所以内核应该让正在运行且需要数据的进程暂时进入睡眠,等它的数据都准备好了再回到等待队列等待被调度类选中。这就是IO等待。
其实上面的图中少了一种进程的特殊状态——僵尸态。僵尸态进程表示的是进程已经转为终止态,它已经完成了它的使命并消逝了,但是内核还没有来得及将它在进程列表中的项删除,也就是说内核没给它料理后事,这就造成了一个进程是死的也是活着的假象,说它死了是因为它不再消耗资源,调度类也不可能选中它并让它运行,说它活着是因为在进程列表中还存在对应的表项,可以被捕捉到。僵尸态进程并不占用多少资源,它仅在进程列表中占用一点点的内存。大多数僵尸进程的出现都是因为进程正常终止(包括kill -9),但父进程没有确认该进程已经终止,所以没有通告给内核,内核也就不知道该进程已经终止了。僵尸进程更具体说明见后文。
另外,睡眠态是一个非常宽泛的概念,分为可中断睡眠和不可中断睡眠。可中断睡眠是允许接收外界信号和内核信号而被唤醒的睡眠,绝大多数睡眠都是可中断睡眠,能ps或top捕捉到的睡眠也几乎总是可中断睡眠;不可中断睡眠只能由内核发起信号来唤醒,外界无法通过信号来唤醒,主要表现在和硬件交互的时候。例如cat一个文件时,从硬盘上加载数据到内存中,在和硬件交互的那一小段时间一定是不可中断的,否则在加载数据的时候突然被人为发送的信号手动唤醒,而被唤醒时和硬件交互的过程又还没完成,所以即使唤醒了也没法将cpu交给它运行,所以cat一个文件的时候不可能只显示一部分内容。而且,不可中断睡眠若能被人为唤醒,更严重的后果是硬件崩溃。由此可知,不可中断睡眠是为了保护某些重要进程,也是为了让cpu不被浪费。一般不可中断睡眠的存在时间极短,也极难通过非编程方式捕捉到。
其实只要发现进程存在,且非僵尸态进程,还不占用cpu资源,那么它就是睡眠的。包括后文中出现的暂停态、追踪态,它们也都是睡眠态。
进程间状态的转换情况可能很复杂,这里举一个例子,尽可能详细地描述它们。
以在bash下执行cp命令为例。在当前bash环境下,处于可运行状态(即就绪态)时,当执行cp命令时,首先fork出一个bash子进程,然后在子bash上exec加载cp程序,cp子进程进入等待队列,由于在命令行下敲的命令,所以优先级较高,调度类很快选中它。在cp这个子进程执行过程中,父进程bash会进入睡眠状态(不仅是因为cpu只有一颗的情况下一次只能执行一个进程,还因为进程等待),并等待被唤醒,此刻bash无法和人类交互。当cp命令执行完毕,它将自己的退出状态码告知父进程,此次复制是成功还是失败,然后cp进程自己消逝掉,父进程bash被唤醒再次进入等待队列,并且此时bash已经获得了cp退出状态码。根据状态码这个"信号",父进程bash知道了子进程已经终止,所以通告给内核,内核收到通知后将进程列表中的cp进程项删除。至此,整个cp进程正常完成。
假如cp这个子进程复制的是一个大文件,一个cpu时间片无法完成复制,那么在一个cpu时间片消耗尽的时候它将进入等待队列。
假如cp这个子进程复制文件时,目标位置已经有了同名文件,那么默认会询问是否覆盖,发出询问时它等待yes或no的信号,所以它进入了睡眠状态(可中断睡眠),当在键盘上敲入yes或no信号给cp的时候,cp收到信号,从睡眠态转入就绪态,等待调度类选中它完成cp进程。
在cp复制时,它需要和磁盘交互,在和硬件交互的短暂过程中,cp将处于不可中断睡眠。
假如cp进程结束了,但是结束的过程出现了某种意外,使得bash这个父进程不知道它已经结束了(此例中是不可能出现这种情况的),那么bash就不会通知内核回收进程列表中的cp表项,cp此时就成了僵尸进程。
前台进程:一般命令(如cp命令)在执行时都会fork子进程来执行,在子进程执行过程中,父进程会进入睡眠,这类是前台进程。前台进程执行时,其父进程睡眠,因为cpu只有一颗,即使是多颗cpu,也会因为执行流(进程等待)的原因而只能执行一个进程,要想实现真正的多任务,应该使用进程内多线程实现多个执行流。
后台进程:若在执行命令时,在命令的结尾加上符号"&",它会进入后台。将命令放入后台,会立即返回父进程,并返回该后台进程的的jobid和pid,所以后台进程的父进程不会进入睡眠。当后台进程出错,或者执行完成,总之后台进程终止时,父进程会收到信号。所以,通过在命令后加上"&",再在"&"后给定另一个要执行的命令,可以实现"伪并行"执行的方式,例如"cp /etc/fstab /tmp & cat /etc/fstab"。
bash内置命令:bash内置命令是非常特殊的,父进程不会创建子进程来执行这些命令,而是直接在当前bash进程中执行。但如果将内置命令放在管道后,则此内置命令将和管道左边的进程同属于一个进程组,所以仍然会创建子进程。
说到这了,应该解释下子shell,这个特殊的子进程。
一般fork出来的子进程,内容和父进程是一样的,包括变量,例如执行cp命令时也能获取到父进程的变量。但是cp命令是在哪里执行的呢?在子shell中。执行cp命令敲入回车后,当前的bash进程fork出一个子bash,然后子bash通过exec加载cp程序替代子bash。请不要在此纠结子bash和子shell,如果搞不清它们的关系,就当它是同一种东西好了。
那是否可以这样理解,所有命令其运行环境都是在子shell中呢?显然,上面所说的bash内置命令不是在子shell中运行的。其他的所有方式,都是在子shell中完成,只不过方式不尽相同。完整的子shell参见man bash,在其中非常多的地方都提到了子shell。以下列出几种常见的方式。
(1).直接执行bash命令。这是一个很巧合的命令。bash命令本身是bash内置命令,在当前shell环境下执行内置命令本不会创建子shell,也就是说不会有独立的bash进程出现,而实际结果则表现为新的bash是一个子进程。其中一个原因是执行bash命令会加载各种环境配置项,为了父bash的环境得到保护而不被覆盖,所以应该让其以子shell的方式存在。虽然fork出来的bash子进程内容完全继承父shell,但因重新加载了环境配置项,所以子shell没有继承普通变量,更准确的说是覆盖了从父shell中继承的变量。不妨试试在/etc/bashrc文件中定义一个变量,再在父shell中导出名称相同值却不同的环境变量,然后到子shell中看看该变量的值为何?
(2).执行shell脚本。因为脚本中第一行总是"#!/bin/bash"或者直接"bash xyz.sh",所以这和上面的执行bash进入子shell其实是一回事,都是使用bash命令进入子shell。只不过执行脚本多了一个动作:命令执行完毕后自动退出子shell。也因此执行脚本时,脚本中不会继承父shell的环境变量。
(3).非内置命令的命令替换。当命令中包含了命令替换部分时,将先执行这部分内容,如果这部分内容不是内置命令,将在子shell中完成,再将执行结果返回给当前命令。因为这次的子shell不是通过bash命令进入的子shell,所以它会继承父shell的所有变量内容。这也就解释了"$(echo $$)"中"$$"的结果是当前bash的pid号,而不是子shell的pid号,因为它不是使用bash命令进入的子shell。
还有两种特殊的脚本调用方式:exec和source。
exec:exec是加载程序替换当前进程,所以它不开启子shell,而是直接在当前shell中执行命令或脚本,执行完exec后直接退出exec所在的shell。这就解释了为何bash下执行cp命令时,cp执行完毕后会自动退出cp所在的子shell。
source:source一般用来加载环境配置类脚本,无法直接加载命令。它也不会开启子shell,直接在当前shell中执行调用脚本且执行脚本后不退出当前shell,所以脚本会继承当前已有的变量,且脚本执行完毕后加载的环境变量会粘滞给当前shell,在当前shell生效。
大部分进程都能将其放入后台,这时它就是一个后台任务,所以常称为job,每个开启的shell会维护一个job table,后台中的每个job都在job table中对应一个Job项。
手动将命令或脚本放入后台运行的方式是在命令行后加上"&"符号。例如:
[root@server2 ~]# cp /etc/fstab /tmp/ &[1] 8701
将进程放入后台后,会立即返回其父进程,一般对于手动放入后台的进程都是在bash下进行的,所以立即返回bash环境。在返回父进程的同时,还会返回给父进程其jobid和pid。未来要引用jobid,都应该在jobid前加上百分号"%",其中"%%"表示当前job,例如"kill -9 %1"表示杀掉jobid为1的后台进程,如果不加百分号,完了,把Init进程给杀了。
通过jobs命令可以查看后台job信息。
jobs [--l:jobs默认不会列出后台工作的PID,加上---s:显示后台工作处于stopped状态的jobs
通过"&"放入后台的任务,在后台中仍会处于运行中。当然,对于那种交互式如vim类的命令,将转入暂停运行状态。
[root@server2 ~]# sleep 10 &[1] 8710[root@server2 ~]# jobs [1]+ Running sleep 10 &
一定要注意,此处看到的是running和ps或top显示的R状态,它们并不总是表示正在运行,处于等待队列的进程也属于running。它们都属于task_running标识。
另一种手动加入后台的方式是按下CTRL+Z键,这可以将正在运行中的进程加入到后台,但这样加入后台的进程会在后台暂停运行。
[root@server2 ~]# sleep 10^Z [1]+ Stopped sleep 10[root@server2 ~]# jobs [1]+ Stopped sleep 10
从jobs信息也看到了在每个jobid的后面有个"+"号,还有"-",或者不带符号。
[root@server2 ~]# sleep 30&vim /etc/my.cnf&sleep 50&[1] 8915[2] 8916[3] 8917
[root@server2 ~]# jobs [1] Running sleep 30 &[2]+ Stopped vim /etc/my.cnf [3]- Running sleep 50 &
发现vim的进程后是加号,"+"表示执行中的任务,也就是说cpu正在它身上,"-"表示被调度类选中的下个要执行的任务,从第三个任务开始不会再对其标注。从jobs的状态可以分析出来,后台任务表中running但没有"+"的表示处于等待队列,running且带有"+"的表示正在执行,stopped状态的表示处于睡眠状态。但不能认为job列表中任务一直是这样的状态,因为每个任务分配到的时间片实际上都很短,在很短的时间内执行完这一次时间片长度的任务,立刻切换到下一个任务并执行。只不过实际过程中,因为切换速度和每个任务的时间片都极短,所以任务列表较小时,显示出来的顺序可能不怎么会出现变动。
就上面的例子而言,下一个要执行的任务是vim,但它是stop的,难道因为这个第一顺位的进程stop,其他进程就不执行吗?显然不是这样的。事实上,过不了多久,会发现另外两个sleep任务已经完成了,但vim仍处于stop状态。
[root@server2 ~]# jobs [1] Done sleep 30[2]+ Stopped vim /etc/my.cnf [3]- Done sleep 50
通过这个job例子,是不是更深入的理解了一点内核调度进程的方式呢?
回归正题。既然能手动将进程放入后台,那肯定能调回到前台,调到前台查看了下执行进度,又想调入后台,这肯定也得有方法,总不能使用CTRL+Z以暂停方式加到后台吧。
fg和bg命令分别是foreground和background的缩写,也就是放入前台和放入后台,严格的说,是以运行状态放入前台和后台,即使原来任务是stopped状态的。
操作方式也很简单,直接在命令后加上jobid即可(即[fg|bg] [%jobid]),不给定jobid时操作的将是当前任务,即带有"+"的任务项。
[root@server2 ~]# sleep 20^Z # 按下CTRL+Z进入暂停并放入后台 [3]+ Stopped sleep 20
[root@server2 ~]# jobs [2]- Stopped vim /etc/my.cnf [3]+ Stopped sleep 20 # 此时为stopped状态
[root@server2 ~]# bg %3 # 使用bg或fg可以让暂停状态的进程变会运行态 [3]+ sleep 20 &
[root@server2 ~]# jobs [2]+ Stopped vim /etc/my.cnf [3]- Running sleep 20 & # 已经变成运行态
使用disown命令可以从job table中直接移除一个job,仅仅只是移出job table,并非是结束任务。而且移除job table后,任务将挂在init/systemd进程下,使其不依赖于终端。
disown [-ar] [-h] [%jobid ...] 选项说明:-h:给定该选项,将不从job table中移除job,而是将其设置为不接受shell发送的sighup信号。具体说明见"信号"小节。-a:如果没有给定jobid,该选项表示针对Job table中的所有job进行操作。-r:如果没有给定jobid,该选项严格限定为只对running状态的job进行操作
如果不给定任何选项,该shell中所有的job都会被移除,移除是disown的默认操作,如果也没给定jobid,而且也没给定-a或-r,则表示只针对当前任务即带有"+"号的任务项。
使用pstree命令查看下当前的进程,不难发现在某个终端执行的进程其父进程或上几个级别的父进程总是会是终端的连接程序。
例如下面筛选出了两个终端下的父子进程关系,第一个行是tty终端(即直接在虚拟机中)中执行的进程情况,第二行和第三行是ssh连接到Linux上执行的进程。
[root@server2 ~]# pstree -c | grep bash|-login---bash---bash---vim|-sshd-+-sshd---bash| `-sshd---bash-+-grep
正常情况下杀死父进程会导致子进程变为孤儿进程,即其PPID改变,但是杀掉终端这种特殊的进程,会导致该终端上的所有进程都被杀掉。这在很多执行长时间任务的时候是很不方便的。比如要下班了,但是你连接的终端上还在执行数据库备份脚本,这可能会花掉很长时间,如果直接退出终端,备份就终止了。所以应该保证一种安全的退出方法。
一般的方法也是最简单的方法是使用nohup命令带上要执行的命令或脚本放入后台,这样任务就脱离了终端的关联。当终端退出时,该任务将自动挂到init(或systemd)进程下执行。如:
shell> nohup tar rf a.tar.gz /tmp/*.txt
另一种方法是使用screen这个工具,该工具可以模拟多个物理终端,虽然模拟后screen进程仍然挂在其所在的终端上的,但同nohup一样,当其所在终端退出后将自动挂到init/systemd进程下继续存在,只要screen进程仍存在,其所模拟的物理终端就会一直存在,这样就保证了模拟终端中的进程继续执行。它的实现方式其实和nohup差不多,只不过它花样更多,管理方式也更多。一般对于简单的后台持续运行进程,使用nohup足以。
另外,可能你已经发现了,很多进程是和终端无关的,也就是不依赖于终端,这类进程一般是内核类进程/线程以及daemon类进程,若它们也依赖于终端,则终端一被终止,这类进程也立即被终止,这是绝对不允许的。
信号在操作系统中控制着进程的绝大多数动作,信号可以让进程知道某个事件发生了,也指示着进程下一步要做出什么动作。信号的来源可以是硬件信号(如按下键盘或其他硬件故障),也可以是软件信号(如kill信号,还有内核发送的信号)。不过,很多可以感受到的信号都是从进程所在的控制终端发送出去的。
Linux中支持非常多种信号,它们都以SIG字符串开头,SIG字符串后的才是真正的信号名称,信号还有对应的数值,其实数值才是操作系统真正认识的信号。但由于不少信号在不同架构的计算机上数值不同(例如CTRL+Z发送的SIGSTP信号就有三种值18,20,24),所以在不确定信号数值是否唯一的时候,最好指定其字符名称。
以下是需要了解的信号。
中断进程,可被捕捉和忽略,几乎等同于sigterm,所以也会尽可能的释放执行clean-up,释放资源,保存状态等(CTRL+ 强制杀死进程,该信号不可被捕捉和忽略,进程收到该信号后不会执行任何clean- 杀死(终止)进程,可被捕捉和忽略,几乎等同于sigint信号,会尽可能的释放执行clean-- 该信号是可被忽略的进程停止信号(CTRL+ 发送此信号使得stopped进程进入running,该信号主要用于jobs,例如bg & 用户自定义信号2
只有SIGKILL和SIGSTOP这两个信号是不可被捕捉且不可被忽略的信号,其他所有信号都可以通过trap或其他编程手段捕捉到或忽略掉。
更多更详细的信号理解或说明,可以参考wiki的两篇文章:
jobs控制机制:(Unix)
信号说明:
(1).当控制终端退出时,会向该终端中的进程发送sighup信号,因此该终端上行的shell进程、其他普通进程以及任务都会收到sighup而导致进程终止。
两种方式可以改变因终端中断发送sighup而导致子进程也被结束的行为:一是使用nohup命令启动进程,它会忽略所有的sighup信号,使得该进程不会随着终端退出而结束;二是使用disown,将任务列表中的任务移除出job table或者直接使用disown -h的功能设置其不接收终端发送的sighup信号。但不管是何种实现方式,终端退出后未被终止的进程将只能挂靠在init/systemd下。
(2).对于daemon类的程序(即服务性进程),这类程序不依赖于终端(它们的父进程都是Init或systemd),它们收到sighup信号时会重读配置文件并重新打开日志文件,使得服务程序可以不用重启就可以加载配置文件。
一个编程完善的程序,在子进程终止、退出的时候,会发送SIGCHLD信号给父进程,父进程收到信号就会通知内核清理该子进程相关信息。
在子进程死亡的那一刹那,子进程的状态就是僵尸进程,但因为发出了SIGCHLD信号给父进程,父进程只要收到该信号,子进程就会被清理也就不再是僵尸进程。所以正常情况下,所有终止的进程都会有一小段时间处于僵尸态(发送SIGCHLD信号到父进程收到该信号之间),只不过这种僵尸进程存在时间极短(倒霉的僵尸),几乎是不可被ps或top这类的程序捕捉到的。
如果在特殊情况下,子进程终止了,但父进程没收到SIGCHLD信号,没收到这信号的原因可能是多种的,不管如何,此时子进程已经成了永存的僵尸,能轻易的被ps或top捕捉到。僵尸不倒霉,人类就要倒霉,但是僵尸爸爸并不知道它儿子已经变成了僵尸,因为有僵尸爸爸的掩护,僵尸道长即内核见不到小僵尸,所以也没法收尸。悲催的是,人类能力不足,直接发送信号(如kill)给僵尸进程是无效的,因为僵尸进程本就是终结了的进程,不占用任何运行资源,也收不到信号,只有内核从进程列表中将僵尸进程表项移除才能收尸。
要解决掉永存的僵尸有几种方法:
(1).杀死僵尸进程的父进程。没有了僵尸爸爸的掩护,小僵尸就暴露给了僵尸道长的直系弟子init/systemd,init/systemd会定期清理它下面的各种僵尸进程。所以这种方法有点不讲道理,僵尸爸爸是正常的啊,不过如果僵尸爸爸下面有很多僵尸儿子,这僵尸爸爸肯定是有问题的,比如编程不完善,杀掉是应该的。
(2).手动发送SIGCHLD信号给僵尸进程的父进程。僵尸道长找不到僵尸,但被僵尸祸害的人类能发现僵尸,所以人类主动通知僵尸爸爸,让僵尸爸爸知道自己的儿子死而不僵,然后通知内核来收尸。
当然,第二种手动发送SIGCHLD信号的方法要求父进程能收到信号,而SIGCHLD信号默认是被忽略的,所以应该显式地在程序中加上获取信号的代码。也就是人类主动通知僵尸爸爸的时候,默认僵尸爸爸是不搭理人类的,所以要强制让僵尸爸爸收到通知。不过一般daemon类的程序在编程上都是很完善的,发送SIGCHLD总是会收到,不用担心。
使用kill命令可以手动发送信号给指定的进程。
kill [-s signal] pid...kill [-signal] pid...kill -l
使用kill -l可以列出Linux中支持的信号,有64种之多,但绝大多数非编程人员都用不上。
使用-s或-signal都可以发送信号,不给定发送的信号时,默认为TREM信号,即kill -15。
shell> kill -9 pid1 pid2... shell> kill -TREM pid1 pid2... shell> kill -s TREM pid1 pid2...
这两个命令都可以直接指定进程名来发送信号,不指定信号时,默认信号都是TERM。
(1).pkill
pkill和pgrep命令是同族命令,都是先通过给定的匹配模式搜索到指定的进程,然后发送信号(pkill)或列出匹配的进程(pgrep),pgrep就不介绍了。
pkill能够指定模式匹配,所以可以使用进程名来删除,想要删除指定pid的进程,反而还要使用"-s"选项来指定。默认发送的信号是SIGTERM即数值为15的信号。
pkill [-signal] [-v] [-P ppid,...] [-s pid,...][-U uid,...] [-t term,...] [pattern] 选项说明:-P ppid,... :匹配PPID为指定值的进程-s pid,... :匹配PID为指定值的进程-U uid,... :匹配UID为指定值的进程,可以使用数值UID,也可以使用用户名称-t term,... :匹配给定终端,终端名称不能带上"/dev/"前缀,其实"w"命令获得终端名就满足此处条件了,所以pkill可以直接杀掉整个终端-v :反向匹配-signal :指定发送的信号,可以是数值也可以是字符代表的信号
在CentOS 7上,还有两个好用的新功能选项。
-F, --pidfile file:匹配进程时,读取进程的pid文件从中获取进程的pid值。这样就不用去写获取进程pid命令的匹配模式-L, --logpidfile :如果"-F"选项读取的pid文件未加锁,则pkill或pgrep将匹配失败。
例如踢出终端:
shell> pkill -t pts/0
(2).killall
killall主要用于杀死一批进程,例如杀死整个进程组。其强大之处还体现在可以通过指定文件来搜索哪个进程打开了该文件,然后对该进程发送信号,在这一点上,fuser和lsof命令也一样能实现。
killall [-r,--regexp] [-s,--signal signal] [-u,--user user] [-v,--verbose] [-w,--wait] [-I,--ignore-case] [--] name ... 选项说明:-I :匹配时不区分大小写-r :使用扩展正则表达式进行模式匹配-s, --signal :发送信号的方式可以是-HUP或-SIGHUP,或数值的"-1",或使用"-s"选项指定信号-u, --user :匹配该用户的进程-v, :给出详细信息-w, --wait :等待直到该杀的进程完全死透了才返回。默认killall每秒检查一次该杀的进程是否还存在,只有不存在了才会给出退出状态码。 如果一个进程忽略了发送的信号、信号未产生效果、或者是僵尸进程将永久等待下去
fuser可以查看文件或目录所属进程的pid,即由此知道该文件或目录被哪个进程使用。例如,umount的时候提示the device busy可以判断出来哪个进程在使用。而lsof则反过来,它是通过进程来查看进程打开了哪些文件,但要注意的是,一切皆文件,包括普通文件、目录、链接文件、块设备、字符设备、套接字文件、管道文件,所以lsof出来的结果可能会非常多。
fuser [-ki] [-signal] file/dir-k:找出文件或目录的pid,并试图kill掉该pid。发送的信号是SIGKILL-i:一般和-k一起使用,指的是在kill掉pid之前询问。-signal:发送信号,如-1 -15,如果不写,默认-9,即kill -9不加选项:直接显示出文件或目录的pid
在不加选项时,显示结果中文件或目录的pid后会带上一个修饰符:
c:在当前目录下
e:可被执行的
f:是一个被开启的文件或目录
F:被打开且正在写入的文件或目录
r:代表root directory
例如:
[root@xuexi ~]# fuser /usr/sbin/crond/usr/sbin/crond: 1425e
表示/usr/sbin/crond被1425这个进程打开了,后面的修饰符e表示该文件是一个可执行文件。
[root@xuexi ~]# ps aux | grep 142[5] root 1425 0.0 0.1 117332 1276 ? Ss Jun10 0:00 crond
例如:
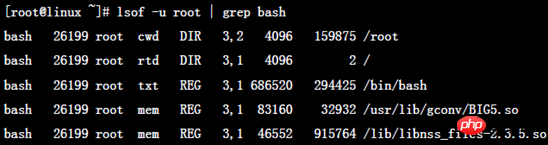
输出信息中各列意义:
COMMAND:进程的名称
PID:进程标识符
USER:进程所有者
FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等
TYPE:文件类型,如DIR、REG等
DEVICE:指定磁盘的名称
SIZE/OFF:文件的大小或文件的偏移量(单位kb)(size and offset)
NODE:索引节点(文件在磁盘上的标识)
NAME:打开文件的确切名称
lsof的各种用法:
lsof /path/to/somefile:显示打开指定文件的所有进程之列表;建议配合grep使用 lsof -c string:显示其COMMAND列中包含指定字符(string)的进程所有打开的文件;可多次使用该选项lsof -p PID:查看该进程打开了哪些文件lsof -U:列出套接字类型的文件。一般和其他条件一起使用。如lsof -u root -a -Ulsof -u uid/name:显示指定用户的进程打开的文件;可使用脱字符"^"取反,如"lsof -u ^root"将显示非root用户打开的所有文件lsof +d /DIR/:显示指定目录下被进程打开的文件 lsof +D /DIR/:基本功能同上,但lsof会对指定目录进行递归查找,注意这个参数要比grep版本慢 lsof -a:按"与"组合多个条件,如lsof -a -c apache -u apache lsof -N:列出所有NFS(网络文件系统)文件 lsof -n:不反解IP至HOSTNAME lsof -i:用以显示符合条件的进程情况lsof -i[46] [protocol][@host][:service|port]46:IPv4或IPv6 protocol:TCP or UDP host:host name或ip地址,表示搜索哪台主机上的进程信息 service:服务名称(可以不只一个) port:端口号 (可以不只一个)
大概"-i"是使用最多的了,而"-i"中使用最多的又是服务名或端口了。
[root@www ~]# lsof -i :22COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME sshd 1390 root 3u IPv4 13050 0t0 TCP *:ssh (LISTEN) sshd 1390 root 4u IPv6 13056 0t0 TCP *:ssh (LISTEN) sshd 36454 root 3r IPv4 94352 0t0 TCP xuexi:ssh->172.16.0.1:50018 (ESTABLISHED)
回到系列文章大纲:
Atas ialah kandungan terperinci linux进程和信号. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Perbezaan antara benang dan proses
Perbezaan antara benang dan proses
 Bagaimana untuk melihat proses dalam linux
Bagaimana untuk melihat proses dalam linux
 proses paparan linux
proses paparan linux
 teknologi pengkomputeran awan
teknologi pengkomputeran awan
 Ringkasan kekunci pintasan komputer yang biasa digunakan
Ringkasan kekunci pintasan komputer yang biasa digunakan
 Mengapa halaman web ruang QQ tidak boleh dibuka?
Mengapa halaman web ruang QQ tidak boleh dibuka?
 mata wang digital maya
mata wang digital maya
 Bagaimana untuk menetapkan lebar set medan
Bagaimana untuk menetapkan lebar set medan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



