


查询其实就是一系列的子任务组成,优化查询实际上就是:要么消除一些子任务,要么减少子任务执行的次数。
1)查询了不需要的数据:
比如我们通过select 查询出了大量的结果,获取前面的N行之后就关闭结果集,实际上MySQL会查询出所有的结果集,客户端接收部分数据后丢弃剩余的数据,这里就存在查询冗余。所以我们只需要查询前面的n条记录就好,利用 limit 关键字限制。
2)多表关联时返回全部的列
我们在进行多表查询时,经常会碰到
mysql>select * from …….
这样的查询其实是非常非常影响性能的,应该用具体的字段名来代替通配符 *
3)总是取出全部的列
禁止写出 select * 这样的语句。
在确定了查询只返回了需要的数据之后(也就是定制查询的具体字段不要使用通配符 * )
接下来关注的应该是返回结果是否扫描了过多的数据。对于MySQL最简单的三个指标如下:
(1)响应时间
(2)扫描的行数
(3)返回的行数。
响应时间
响应时间:包括服务时间(真正的查询时间)和排队时间(阻塞等待的时间)。
扫描行数和返回的行数
分析查询时,查看该查询扫描的行数是非常有帮助的,一定程度上说明该查询的效率高不高。
扫描的行数和访问类型
MySQL有好几种访问方式可以查找并返回一行结果:全表扫描、索引扫描、范围扫描、唯一索引查询、常数引用等。
这里加索引的作用就出来了,索引可以让MySQL以最高效、扫描行数最少的方式找到记录。
目的就是:找到一个更加优的方法获得实际需要的结果。
(1)一个复杂查询还是多个简单查询
我们在写SQL的时候经常需要考虑的一个问题就是:是否需要将一个复杂的查询分成多个简单的查询?
对于MySQL来说,连接和断开都是非常轻量级的,在返回一个小的查询结果方面很高效。虽然说尽可能少的查询当然好,但是在衡量了工作量是否明显减少之后,将大的查询分解成小的查询有时还是很有必要的。
(2)切分查询
分而治之的思想。有时候我们需要将一个大的查询切分成片,分部分执行,而且分步之间做一个延时,这样避免了长时间的锁住很多的数据。
比如我们在删除数据时 delete, 如果一次删除所有需要删除的数据,可能长时间占用事务,但是我们可以分片,将一个大的delete,通过条件限制,分成多个delete执行,这样就能提高效率。
(3)分解关联查询
很多高性能的应用都会对关联查询拆分,比如:
mysql>select * from tag left join tag_post on tag_post.tag_id=tag.id left join post on tag_post.post_id = post.idwhere tag.tag='mysql';
可以分解成
mysql>select * from tag where tag='mysql';mysql>select * from tag_post where tag_id=1234; mysql>select * from post where post.id in (123,345,456,8933);
这么分解的原因是什么呢?
(1)让缓存的效率更高;(比如上面查询的tag已经被缓存了,那么应用就可以跳过第一个查询了。)
(2)将查询分解后,执行单个查询可以减少锁的竞争。
(3)某些情况下效率也会更高,比如上面的分解后用 in 关键字查询,效率更高。
首先来看看查询执行的路径的示意图: 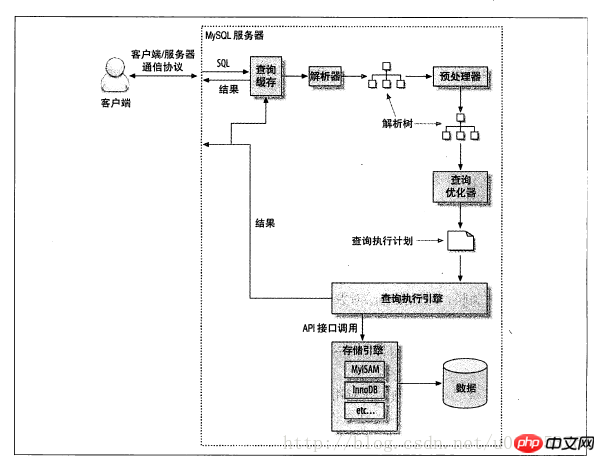
步骤如下:
(1)客户端发送一条查询给服务器;
(2)服务器先检查查询缓存,如果命中了缓存,则立刻返回存在缓存中的结果,否则进入下一步。
(3)服务器对SQL进行解析、预处理、再由优化器生成对应的执行计划。
(4)MySQL会根据优化器生成的执行计划、调用存储引擎的API来执行查询。
(5)将结果返回给客户端。
我们不需要了解通信协议内部是如何实现的,只需理解通信协议是如何工作的。
MySQL的客户端和服务器通信协议是半双工的,意味着同一时刻,只能有一方向另一方发送数据。
在解析一个SQL语句之前,如果缓存是打开的,MySQL会优先检查这个查询是否命中查询缓存中的数据。如果命中了缓存就会直接从缓存中拿到结果集并返回给客户端。如果没有命中缓存就会进入下一阶段。
在这一部分最重要的就是查询优化器了,一条查询语句可以有很多种执行方式,最后都将返回相同的结果,优化器的作用就是找到最高效的执行计划。
下面给出MySQL查询优化器能够自动处理的优化类型:
(1)重新定义关联表的顺序:数据表的关联顺序并不总是按照在查询中指定的顺序进行,这个与优化器有关。(2)将外连接转换成内连接:
(3)使用等价变换规则:可以减少一些比较或则移除一些恒等的判断。比如(5=5 and a>5)将被改写成(a > 5)。
(4)优化 COUNT()、 MIN() 和 MAX() 函数:索引和列是否允许为空可以帮助优化这类表达式:比如求最小值,利用B-Tree结构特点,只需要查询B-Tree的最左端记录就OK了。同理对于求max()函数也是一样。但是对于COUNT(*)这个函数,MyISAM存储类型维护了一个变量来专门存储表中记录行的总数。
(5)覆盖索引扫描:当索引中的列包含所有查询中需要使用的列时候,MySQL可以直接使用索引返回需要的数据,无需再查询对应的数据行。
(6)子查询优化
(8)提前终止查询:在发现已经满足查询需求的时候,MySQL总是能够立即终止查询。比如 limit 关键字。
(9)列表 IN 的比较代替OR:MySQL会先将IN语句中的数据排序,再通过二分查找来确定列表中的数据是否满足需求,这是一个O(logn)的复杂度的操作。 如果等价转换成 OR 就会变成O(n)的时间复杂度。
不管怎么说,排序都是一个成本很高的操作,一定要避免对大数据排序。所以我们一定要利用索引列来进行排序,当不能利用索引生成排序结果时候,肯定就会存在回表查询记录的情况,这时候数据量巨大,会使用文件排序。
Atas ialah kandungan terperinci MySQL查询性能优化详情介绍. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



