


XML文件是一种常用的文件格式,本篇文章主要介绍了C#读取XML的三种实现方式,主要是XmlDocument、XmlTextReader、Linq to Xml,有兴趣的可以了解一下。
前言
XML文件是一种常用的文件格式,例如WinForm里面的app.config以及Web程序中的web.config文件,还有许多重要的场所都有它的身影。(类似还有Json)微软也提供了一系列类库来倒帮助我们在应用程序中存储XML文件
在程序中访问进而操作XML文件一般有两种模型:
DOM(文档对象模型):使用DOM的好处在于它允许编辑和更新XML文档,可以随机访问文档中的数据,可以使用XPath查询,但是,DOM的缺点在于它需要一次性的加载整个文档到内存中,对于大型的文档,这会造成资源问题。
流模型:流模型很好的解决了这个问题,因为它对XML文件的访问采用的是流的概念,也就是说,任何时候在内存中只有当前节点,但它也有它的不足,它是只读的,仅向前的,不能在文档中执行向后导航操作。
C#中三种读取XML文件方法如下:
1.使用 XmlDocument(DOM模式)
2.使用 XmlTextReader(流模式)
3.使用 Linq to Xml(Linq模式)
使用XmlDocument方式读取
使用XmlDocument是一种基于文档结构模型的方式来读取XML文件.在XML文件中,我们可以把XML看作是由文档声明(Declare),元素(Element),属性(Attribute),文本(Text)等构成的一个树.最开始的一个结点叫作根结点,每个结点都可以有自己的子结点.得到一个结点后,可以通过一系列属性或方法得到这个结点的值或其它的一些属性.例如:
xn 代表一个结点 xn.Name;//这个结点的名称 xn.Value;//这个结点的值 xn.ChildNodes;//这个结点的所有子结点 xn.ParentNode;//这个结点的父结点
读取所有数据
使用的时候,首先声明一个XmlDocument对象,然后调用Load方法,从指定的路径加载XML文件.
BookModel是图书模型
#region XmlDocument读取
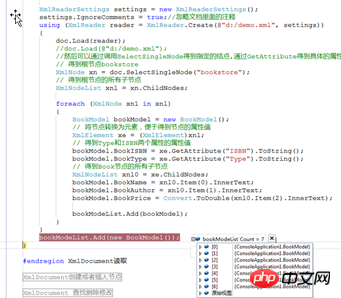
public static void XmlDocumentReadDemo()
{
//list
List<BookModel> bookModeList = new List<BookModel>();
//使用的时候,首先声明一个XmlDocument对象,然后调用Load方法,从指定的路径加载XML文件.
XmlDocument doc = new XmlDocument();
XmlReaderSettings settings = new XmlReaderSettings();
settings.IgnoreComments = true;//忽略文档里面的注释
using (XmlReader reader = XmlReader.Create(@"d:/demo.xml", settings))
{
doc.Load(reader);
//doc.Load(@"d:/demo.xml");
//然后可以通过调用SelectSingleNode得到指定的结点,通过GetAttribute得到具体的属性值.参看下面的代码
// 得到根节点bookstore
XmlNode xn = doc.SelectSingleNode("bookstore");
// 得到根节点的所有子节点
XmlNodeList xnl = xn.ChildNodes;
foreach (XmlNode xn1 in xnl)
{
BookModel bookModel = new BookModel();
// 将节点转换为元素,便于得到节点的属性值
XmlElement xe = (XmlElement)xn1;
// 得到Type和ISBN两个属性的属性值
bookModel.BookISBN = xe.GetAttribute("ISBN").ToString();
bookModel.BookType = xe.GetAttribute("Type").ToString();
// 得到Book节点的所有子节点
XmlNodeList xnl0 = xe.ChildNodes;
bookModel.BookName = xnl0.Item(0).InnerText;
bookModel.BookAuthor = xnl0.Item(1).InnerText;
bookModel.BookPrice = Convert.ToDouble(xnl0.Item(2).InnerText);
bookModeList.Add(bookModel);
}
}
bookModeList.Add(new BookModel());
}
#endregion XmlDocument读取运行结果如下:
使用XmlTextReader方式读取
使用XmlTextReader读取数据的时候,首先创建一个流,然后用read()方法来不断的向下读,根据读取的结点的类型来进行相应的操作.如下:
#region XmlTextReaderDemo
public static void XmlTextReaderDemo()
{
XmlTextReader reader = new XmlTextReader(@"d:/demo.xml");
List<BookModel> modelList = new List<BookModel>();
BookModel model = new BookModel();
while (reader.Read())
{
if (reader.NodeType == XmlNodeType.Element)
{
if (reader.Name == "book")
{
model.BookType = reader.GetAttribute("Type");
model.BookISBN = reader.GetAttribute("ISBN");
}
if (reader.Name == "title")
{
model.BookName = reader.ReadElementContentAsString();
}
if (reader.Name == "author")
{
model.BookAuthor = reader.ReadElementString().Trim();
}
if (reader.Name == "price")
{
model.BookPrice = Convert.ToDouble(reader.ReadElementString().Trim());
}
//for(int i=0;i<reader.AttributeCount;i++)
//{
// reader.MoveToAttribute(i);
//}
}
if (reader.NodeType == XmlNodeType.EndElement)
{
modelList.Add(model);
model = new BookModel();
}
}
reader.Close();
modelList.Add(new BookModel());
}
#endregion XmlTextReaderDemo使用 Linq to Xml读取
Linq是C#3.0中出现的一个新特性,使用它可以方便的操作许多数据源,也包括XML文件.使用Linq操作XML文件非常的方便,而且也比较简单。
必须引用using System.Linq;using System.Xml.Linq;
#region 读取所有的数据
XElement xe = XElement.Load(@"d:/demoLinq.xml");
//xe.Descendants
var elements = from ele in xe.Elements()
select ele;
List<BookModel> modelList = new List<BookModel>();
foreach (var ele in elements)
{
BookModel model = new BookModel();
model.BookAuthor = ele.Element("author").Value;
model.BookName = ele.Element("title").Value;
model.BookPrice = Convert.ToDouble(ele.Element("price").Value);
model.BookISBN = ele.Attribute("ISBN").Value;
model.BookType = ele.Attribute("Type").Value;
modelList.Add(model);
}
modelList.Add(new BookModel());
#endregion 读取所有的数据总结
1.XmlDocument方法优点是便于查找
2.XmlTextReader方法是流读取内存暂用少
3.Linq to Xml 最新方法也是推荐方法,代码少易于理解
以上就是C#读取XML的三种实现方式的代码详解的内容,更多相关内容请关注PHP中文网(m.sbmmt.com)!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



