


随着互联网的发展,各方面的数据越来越多,从最近两年大数据越来越强的呼声中就可见一斑。
我们所做的项目虽算不上什么大项目,但是由于业务量的问题,数据也是相当的多。
数据一多,就很容易出现性能问题,而为了解决这个问题我们通常很容易想到集群、分片等。
但是在某些时候却不一定必须要用集群、分片,也可以适当的使用数据分区。
什么是分区?
MySQL在未启用分区功能时,数据库的单个表内容是以单个文件的形式存放在文件系统上的。当启用分区功能后,MySQL将按用户指定的规则将单个表内容分割成几个文件存放在文件系统上。分区分为水平分区和垂直分区,水平分区是将表的数据按行分割成不同的数据文件,而垂直分区则是将表的数据按列分割成不同的数据文件。分片要遵循完备性原则、可重构性原则与不相交原则。完备性代表所有数据必须映射到某个片段上。可重构性表示所有分片数据必须可以重新构成全局数据。不相交性表示不同分片上的数据没有重复(除非你是特意做的冗余)。
大概是介于各方面的考虑,我们用的的表中就用到了range分区,数据库是其他人在管理,但是因为用到了这个表,因此我便抽时间进行了简单的学习。
据我的了解,要使用分区的话,必须要在创建表结构的时候就使用创建分区的语句,不能再后期更改。
例如我创建一个简单的emp表,有id、name、age三个字段,然后根据id分区。正确的建表语句基本如下:
CREATE TABLE emp( id INT NOT NULL, NAME VARCHAR(20), age INT) PARTITION BY RANGE(ID)( PARTITION p0 VALUES LESS THAN (6), PARTITION p1 VALUES LESS THAN (11), PARTITION pmax VALUES LESS THAN maxvalue );
这里我是设置把整个表的数据分为三个区,id小于6的是一个区,区名称p0;id介于6到11的属于一个区,区名称p1;然后所有id大于11的一个区,区名称pmax。
整理一个语法,基本如下:
create table tablename( 字段名 数据类型...) partition by range(分区依赖的字段名)( partition 分取名 values less than (分区条件的值),...)
这里需要注意的是例子中的最后一行partition pmax values less than maxvalue,这一句中只有代表分区名的pmax是可以自己任意取得,剩下的单词不能变,maxvalue代表上边分区条件的最大值。
这样的话能保证所有数据都能正常入库,否则,假如没有这一句的话,那么id大于等于11的数据便无法存入库中,将会报错。
表结构创建好以后,为了测试分区是否成功,我向表中插入了一些数据,语句如下:
INSERT INTO emp VALUES(1,'test1',22);INSERT INTO emp VALUES(2,'test2',25);INSERT INTO emp VALUES(3,'test3',27); INSERT INTO emp VALUES(4,'test4',20);INSERT INTO emp VALUES(5,'test5',22);INSERT INTO emp VALUES(6,'test6',25); INSERT INTO emp VALUES(7,'test7',27);INSERT INTO emp VALUES(8,'test8',20);INSERT INTO emp VALUES(9,'test9',22); INSERT INTO emp VALUES(10,'test10',25);INSERT INTO emp VALUES(11,'test11',27);INSERT INTO emp VALUES(12,'test12',20); INSERT INTO emp VALUES(13,'test13',22);INSERT INTO emp VALUES(14,'test14',25);INSERT INTO emp VALUES(15,'test15',27); INSERT INTO emp VALUES(16,'test16',20);INSERT INTO emp VALUES(17,'test17',30);INSERT INTO emp VALUES(18,'test18',40); INSERT INTO emp VALUES(19,'test19',20);
数据插入完成后,要验证是否对应id的数据保存在了对应的分区,可以使用查询分区的命令,如下:
SELECT partition_name,partition_expression,partition_description,table_rows FROM information_schema.PARTITIONS WHERE table_schema = SCHEMA() AND table_name='emp'
查询出的结果如图: 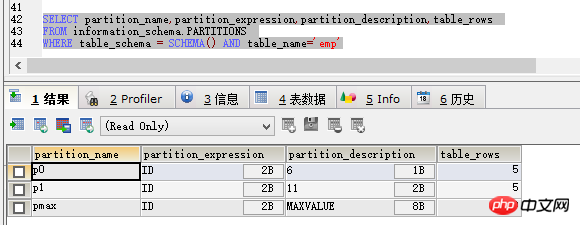
可以看出partition_name是分区名,partition_expression是分区依赖的字段,partition_description可以理解成该分区的条件,table_rows表示该分区中现在有的数据量。
从上边的数据中可以看出分区是成功的,但是如上分区虽然可以避免无法插入的问题,却又出现了一个新的问题。
那就是最后一个pmax区的数据有可能非常的大,这样一来,数据并不平均,不成比例,有可能使得查询最后一个区的数据时依旧出现性能问题。所以,解决办法大致有这样三个:
一是在能控制分区字段数据的情况下,比如说这里的id,假如能明确的知道什么时候会是多大的值,那么就可以一开始的时候不要这个pmax,而是定期的增加分区。例如这里存在了p0、p1,那么可以在id即将到达11的时候增加p2、p3甚至更多。增加分区的语句示例如下:
ALTER TABLE emp ADD PARTITION(PARTITION p2 VALUES LESS THAN (16))
语法整理就是:
alter table tablename add partition(partition 分区名 values lessthan (分区条件))
上边这个办法可以解决数据不成比例的这个问题,只不过也同时存在隐患,那就是假如什么时候忘了增加后边的分区,亦或者说是分区依赖的字段值超出了预料,那么就又可能导致数据无法入库的问题。这样一来又有两种方法可以解决:
一是可以使用mysql的事务机制和存储过程等,做一个mysql的定时任务,然后使数据库系统自己在特定的时间增加分区。这样一来基本上不会出现第一个方法所说的问题,只不过这种方法需要对mysql的事务和存储过程也有一定的理解,操作起来有一定的难度。
我知道这个方法,暂时还没有着手去实现,等后边进一步了解事务和存储过程后再给出相关的例子。
那么除开上边这种定时任务的方法外,还有一个就是拆分分区的办法,也就是还是使用之前有pmax分区的这个表结构,然后用拆分分区的语句来拆分pmax。示例如下:
ALTER TABLE emp REORGANIZE PARTITION pmax INTO( PARTITION p2 VALUES LESS THAN (16), PARTITION pmax VALUES LESS THAN maxvalue )
然后我们再用查询分区情况的语句查询,便可以看到结果变成这样: 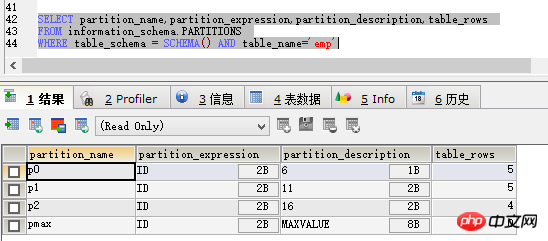
很显然,多出来了一个p2分区,拆分成功的同事不影响其他的功能。
那么这里分区拆分的语法整理如下:
alter table tablename reorganize partition 要拆分的分区名 into( partition 拆分后的分区名1 values less than (条件), partition 拆分后的分区名2 values lessthan (条件),...)
好了,到这里基本上算是完成了,但是我们知道数据库一般的操作都是增删改查,我们这里已经有了增改查,却自然也不能少了删。
按理说正常的生产环境的数据库应该是不能随意删除数据的,但是并不代表就不能删,反而有的时候还必须要删。
就比如我们项目中那个库,由于数据量太大,即便是分区了也依旧会在大量数据的情况下变慢。而与此同时,我们是按时间分区的,实际使用过程中只需要用到几天的数据,那么实际上很早以前的数据是可以删除不要的,或者说备份以后删除这个表的,这样就需要用到删除语句。
当然了,删除可以用delete,但是这样的话分区信息还在库中,实际上也是没必要要的,完全可以直接删除分区,因为删除分区的时候也同时会删除这个区内的所有数据。
示例之前我们先查一下之前插入的所有数据,如图: 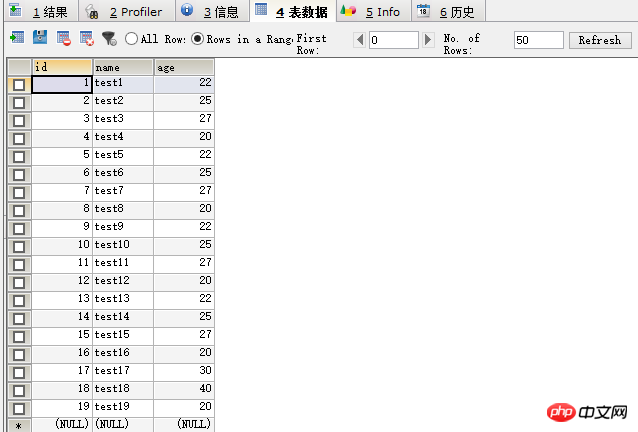
这里示例删除p0分区代码如下:
ALTER TABLE emp DROP PARTITION p0
然后先用查询分区的代码看一下,如图 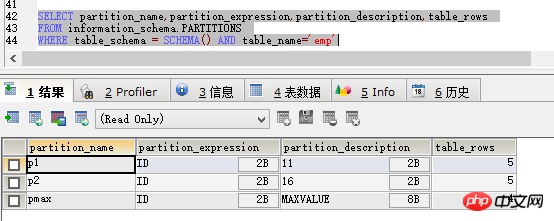
可以看到p0区不见了,在select * 一下,如图: 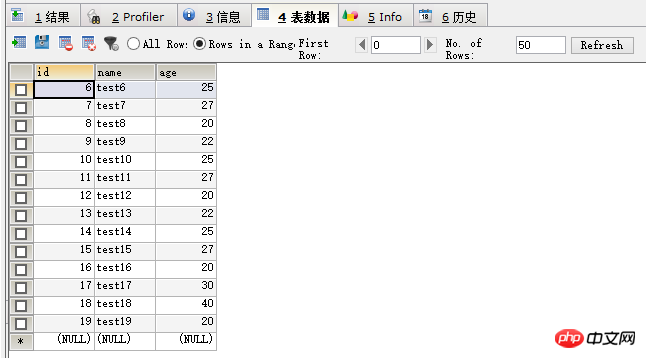
可以看到id小于6的数据已经没有了,数据删除成功。
以上就是mysql分区之range分区的详细介绍的内容,更多相关内容请关注PHP中文网(m.sbmmt.com)!
 mysql mengubah suai nama jadual data
mysql mengubah suai nama jadual data
 MySQL mencipta prosedur tersimpan
MySQL mencipta prosedur tersimpan
 Perisian partition cakera keras mudah alih
Perisian partition cakera keras mudah alih
 Perbezaan antara mongodb dan mysql
Perbezaan antara mongodb dan mysql
 Bagaimana untuk menyemak sama ada kata laluan mysql terlupa
Bagaimana untuk menyemak sama ada kata laluan mysql terlupa
 mysql mencipta pangkalan data
mysql mencipta pangkalan data
 tahap pengasingan transaksi lalai mysql
tahap pengasingan transaksi lalai mysql
 Perbezaan antara sqlserver dan mysql
Perbezaan antara sqlserver dan mysql








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



