


Masa Depan LLM: 3 Penciptaan Membentuk Model AI Seterusnya

Mekanisme perhatian meletakkan asas bagi seni bina pengubah dalam bidang pemprosesan bahasa semulajadi (NLP). Sejak pengenalannya, kami telah menyaksikan evolusi pesat di NLP. Malah, kejayaan ini telah menandakan permulaan era baru untuk generatif AI dan NLP secara keseluruhan. Hari ini, syarikat -syarikat di seluruh dunia melepaskan LLM yang semakin maju. Dan setiap tuntutan ini menetapkan penanda aras baru dalam prestasi, akhirnya membentuk masa depan LLM dan AI secara umum.
Untuk benar -benar memahami di mana masa depan LLMS ini diketuai, adalah penting untuk memahami beberapa inovasi terkini yang mempengaruhi perkembangan mereka. Dalam artikel ini, kami akan meneroka tiga kemajuan utama yang membuka laluan untuk generasi LLM yang akan datang. Ini adalah:
- Fungsi pengaktifan swish
- Tali (Posisi berputar)
- Perhatian infini
Mari kita menyelam setiap topik ini dan meneroka bagaimana mereka menyumbang kepada landskap yang berkembang dalam model bahasa yang besar.
Jadual Kandungan
- Fungsi pengaktifan swish
- Carian seni bina saraf
- Pelaksanaan kod fungsi swish
- Di mana Silu kebanyakannya digunakan?
- Embedding tali
- Embeddings kedudukan mutlak
- Embeddings posisional relatif
- Tali
- Matriks tali
- Komponen tali
- Perhatian infini
- Memori mampatan
- Aliran kerja lengkap
- Mekanisme gating
- Kemas kini memori
- Kesimpulan
Fungsi pengaktifan swish
Sebagai saintis data, kami telah menemui pelbagai fungsi pengaktifan. Ini terdiri daripada asas -asas seperti fungsi linear dan langkah, kepada fungsi yang lebih maju yang diperkenalkan dengan kebangkitan rangkaian saraf, seperti Tanh dan relu yang digunakan secara meluas. Walaupun Relu membawa penambahbaikan yang ketara, batasannya membawa kepada pembangunan alternatif yang dipertingkatkan seperti Leaky Relu, ELU, dan lain -lain.
Menariknya, kebanyakan fungsi pengaktifan ini direka oleh manusia. Walau bagaimanapun, fungsi pengaktifan swish menonjol, seperti yang ditemui oleh mesin. Menarik, bukan? Apa yang lebih menarik ialah pengaktifan swish memainkan peranan penting dalam membentuk masa depan LLM. Jika anda biasa dengan penglihatan komputer, anda mungkin telah menemui model Yolo-NAS. Inilah maksudnya.
Carian seni bina saraf
NAS di Yolo-Nas bermaksud carian seni bina saraf. Ia adalah teknik yang dibangunkan oleh Google untuk mengautomasikan reka bentuk seni bina rangkaian saraf. NAS bertujuan untuk mengenal pasti konfigurasi model terbaik untuk tugas tertentu. Ini termasuk keputusan seperti bilangan lapisan dan neuron.
Di NAS, kami menentukan kedua -dua ruang carian (kemungkinan seni bina) dan strategi carian (bagaimana kita meneroka ruang itu). Ia sering memberi tumpuan kepada metrik seperti ketepatan atau saiz model. Kekangan ditetapkan dengan sewajarnya, dan banyak eksperimen dijalankan untuk menemui seni bina yang optimum.
Terutama, EfficialNet adalah salah satu seni bina yang berjaya yang dibuat menggunakan NAS, yang memanfaatkan pembelajaran tetulang untuk membimbing proses cariannya.

Carian automatik untuk rangkaian saraf yang cekap juga dimanfaatkan untuk menemui fungsi pengaktifan baru. Akibatnya, beberapa calon fungsi pengaktifan yang menjanjikan telah dikenalpasti. Sebahagian daripada ini termasuk:

Fungsi pengaktifan ini dinilai pada dataset penanda aras seperti CIFAR-10 dan CIFAR-100. Prestasi mereka dibandingkan dengan model standard seperti ResNet, Wide Resnet, dan Densenet. Ia terutamanya memberi tumpuan kepada metrik ketepatan berbanding dengan Relu.

Fungsi pengaktifan seperti Relu, Leaky Relu, Elu, dan Tanh semuanya monotonik; Mereka sama ada terus meningkat atau berkurangan dari negatif ke sisi positif paksi-x. Walaupun pengaktifan swish bukan monotonik. Pengaktifan swish berkurangan sedikit pada mulanya sebelum meningkat, mewujudkan lengkung yang merangkumi kedua -dua cerun ke bawah dan ke atas.
Ini bukan monotonik meningkatkan kuasa ekspresif rangkaian dan meningkatkan aliran kecerunan semasa pas ke hadapan dan ke belakang. Akibatnya, model yang menggunakan pengaktifan swish menunjukkan kekukuhan terhadap variasi dalam permulaan berat badan dan kadar pembelajaran, yang membawa kepada kestabilan dan prestasi latihan yang lebih baik.

Fungsi pengaktifan swish kelihatan seperti ini f (x) = x * sigmoid (βx)
Di mana β di sini adalah parameter yang tetap atau dilatih.
Sekiranya β
Sekiranya β> 1, ia berfungsi lebih seperti fungsi relu

Pelaksanaan kod fungsi swish
import numpy sebagai np
def swish (x):
kembali x * (1 / (1 np.exp (-x)))
Di manakah Silu paling banyak digunakan?
Silu digunakan dalam blok ke hadapan setiap lapisan pengubah, khususnya selepas transformasi linear pertama, sebelum memproyeksikan kembali ke dimensi model.
Ini bertambah baik:
- Kestabilan latihan
- Aliran kecerunan
- Prestasi model akhir (terutamanya dalam tetapan berskala besar)
Fungsi pengaktifan Swish menyediakan banyak ciri yang diingini, akhirnya membentuk masa depan LLM. Ini adalah:
- Ketidakhadiran membantu menghilangkan masalah kecerunan yang hilang di sini.
- Monotonicity sangat berkesan kerana ia mengandungi kedua -dua penurunan dan cerun yang semakin meningkat.
- Ia menyediakan lengkung yang lancar, jadi kecerunan wujud pada setiap titik.
Mari kita lihat bagaimana Silu dilaksanakan dalam blok pengubah. Coretan kod ini memberikan gambaran keseluruhan bagaimana Silu digunakan dalam penyebaran ke hadapan.
Kelas Transformerblock (NN.Module):
def __init __ (diri, d_model, d_ff):
super () .__ init __ ()
self.attn = multiheadattention (...)
self.ffn = nn.sequential (
nn.linear (d_model, d_ff),
nn.silu (), # silu diterapkan di sini
nn.linear (d_ff, d_model)
)
self.norm1 = nn.layernorm (d_model)
self.norm2 = nn.layernorm (d_model)
def forward (diri, x):
x = x self.attn (self.norm1 (x)) # Perhatian sisa
x = x self.ffn (self.norm2 (x)) # Feedforward sisa
kembali x
Rangkaian Feed-forward (FFN) bertanggungjawab untuk pembelajaran kompleks, transformasi bukan linear dari embeddings token. Fungsi pengaktifan dalam FFN ini (History Relu, kemudian Gelu, dan sekarang Silu) memainkan peranan penting dalam menambah peralihan bukan linear dan lancar, meningkatkan keupayaan pembelajaran.
Dalam llama meta (sumber terbuka), anda akan sering menemui corak ini:
self.act_fn = nn.silu ()
self.ffn = nn.sequential (
nn.linear (red, hidden_dim),
self.act_fn,
NN.LINEAR (HIDDEN_DIM, DIM)
)
Sebagai contoh, model Llama dan Llama2 dari penyelidikan Facebook Meta menggunakan Swish Activation/Swiglu untuk fungsi pengaktifan mereka. Butiran tepat seni bina GPT-4 adalah sulit. Walaupun ia dikhabarkan menggunakan fungsi pengaktifan sigmoid (iaitu, silu) dalam fungsi kerugiannya. Tambahan pula, fungsi pengaktifan silu juga digunakan dalam model Yolo (contohnya YOLOV7) ultralitik untuk tugas pengesanan objek.
Sekarang, kita telah memahami apa fungsi pengaktifan Swish dan di mana ia digunakan secara berkesan dalam Transformers, memberikan kita pandangan penting tentang masa depan LLM. Baru-baru ini, kami melihat model OpenAI GPT-OSS menggunakan varian fungsi pengaktifan Swish dengan nama Swiglu. Swiglu menggunakan fungsi pengaktifan Swish, yang ditakrifkan sebagai swish (x) = x ⋅ (x) di mana σ (x) adalah fungsi sigmoid, di samping mekanisme gating yang serupa dengan yang dalam Glu.
Embedding tali
Perhatian adalah semua yang anda perlukan kertas, yang diterbitkan pada tahun 2017, memperkenalkan seni bina Transformer, yang merevolusikan bidang pemprosesan bahasa semulajadi. Sejak itu, banyak seni bina baru telah dicadangkan, walaupun tidak semua telah terbukti sama berkesan. Satu ciri umum di kalangan transformer awal ini adalah pergantungan mereka terhadap embeddings posting sinusoidal untuk menyandikan kedudukan token dalam urutan.
Pada tahun 2022, pendekatan yang lebih berkesan untuk pengekodan posisi diperkenalkan: embeddings positional rotary (tali). Teknik ini telah diterima pakai oleh beberapa model bahasa besar, termasuk Palm, Llama 1, Llama 2, dan lain -lain. Ini kerana keupayaannya untuk mengendalikan panjang konteks yang lebih lama dan mengekalkan maklumat kedudukan relatif.
Anda boleh membaca artikel kami yang mendalam mengenai evolusi embeddings di sini.
Embeddings kedudukan mutlak
Cara -cara sebelumnya untuk menghasilkan embeddings kedudukan kebanyakannya bergantung kepada embeddings post mutlak. Dalam embeddings mutlak, kami mewakili satu perkataan dengan maklumat kedudukannya. Pada dasarnya kita mewakili setiap perkataan dengan kedudukan tertentu dalam urutan. Dan di sini token akhir dibuat dengan menjumlahkan perkataan embeddings dengan embedding posisional.
Terdapat 2 cara untuk menghasilkan embeddings kedudukan:
- Dipelajari dari data: Vektor embedding dimulakan secara rawak dan kemudian dilatih semasa proses latihan. Kaedah ini digunakan dalam Transformers asal dan dalam model popular seperti Bert, GPT, dan Roberta.
Tetapi katakan ada vektor posisional antara 1 hingga 512. Ini menimbulkan masalah besar sejak panjang maksimum dibatasi, menjadikannya sukar untuk memanfaatkan logik ini untuk konteks yang panjang kerana ia tidak dapat menyamarinya dengan baik. - Fungsi Sinusoidal: Ia memberikan embedding posisional yang unik untuk setiap kedudukan yang mungkin dalam urutan. Ini memberikan fleksibiliti yang hebat dalam mengendalikan pelbagai saiz input.
Ia juga sukar untuk memahami corak dalam cara ia beralih kerana kedua -dua magnitud dan sudut berubah dengan ketara.

Dari eksperimen yang berbeza, kedua -dua embeddings posisional yang dipelajari dan sinusoidal melakukan sama. Tetapi satu isu ialah setiap kedudukan dirawat secara berasingan. Sebagai contoh, model melihat perbezaan antara kedudukan 1 dan 2 sama seperti antara kedudukan 2 dan 500, walaupun kedudukan berdekatan biasanya lebih berkaitan dengan makna.

Satu lagi perkara yang perlu diperhatikan ialah setiap token di sini mendapat embedding posisional yang unik. Oleh itu, jika perkataan dipindahkan ke kedudukan yang berbeza dalam ayat, walaupun maknanya tidak banyak berubah, ia masih mendapat nilai kedudukan yang sama sekali baru. Ini boleh menjadikan model lebih sukar untuk memahami dan umum.
Embeddings posisional relatif
Dalam embeddings posisional relatif, kita tidak mewakili kedudukan mutlak setiap token. Sebaliknya, kita belajar sejauh mana setiap pasangan token berada dalam ayat. Oleh kerana kedudukan bergantung kepada pasangan, kita tidak boleh menambah penanaman kedudukan ke token embedding seperti yang kita lakukan dalam embeddings mutlak. Sebaliknya, kita perlu mengubahsuai mekanisme perhatian itu sendiri untuk memasukkan maklumat kedudukan relatif ini.

Dalam imej ini, kita dapat melihat matriks bias, yang menandakan hubungan antara kata -kata dengan jarak tertentu. Kemudian kami jumlah matriks yang dicipta dengan matriks Skor Perhatian di sini.
Pembasmian kedudukan relatif memastikan bahawa token yang, katakan, 3 perkataan selain selalu diperlakukan dengan cara yang sama, tidak kira di mana mereka muncul dalam ayat itu. Ini menjadikan mereka berguna untuk mengendalikan urutan panjang. Walau bagaimanapun, mereka lebih perlahan kerana mereka memerlukan langkah tambahan untuk menambah matriks bias kepada skor perhatian.
Juga, kerana embeddings bergantung pada kedudukan antara setiap pasangan token, kita tidak dapat dengan mudah menggunakan semula pasangan nilai utama sebelumnya, menjadikannya sukar untuk menggunakan caching nilai kunci dengan cekap. Itulah sebabnya kebanyakan orang tidak menggunakannya secara meluas dalam amalan.

Seperti yang kita lihat di sini, embeddings posisional relatif membantu kita memahami urutan urutan tanpa bimbang tentang kedudukan yang tepat dan mempunyai peranan penting untuk bermain di masa depan LLM.
Tali
Pembasmian posisi berputar menggabungkan bahagian -bahagian terbaik embeddings mutlak dan relatif. Di sini dalam tali, bukannya menambahkan vektor kedudukan untuk menyandikan kedudukan perkataan dalam urutan, mereka mencadangkan untuk memohon putaran kepada vektor.

Jumlah yang kita putar hanyalah satu integer pelbagai kedudukan perkataan dalam ayat, jadi untuk mewakili kedudukan m dalam ayat. Kami berputar vektor perkataan asal dengan sudut m kali θ (theta). Ini mempunyai beberapa kelebihan embeddings mutlak mutlak, seperti jika kita menambah lebih banyak token hingga akhir ayat tetap sama, yang menjadikan mereka lebih mudah untuk ditangkap.
Jumlah putaran bergantung hanya pada kedudukan token dalam ayat, jadi mana -mana bilangan token selepas perkataan tertentu tidak mempengaruhi embedding seperti dalam embeddings kedudukan mutlak.
Untuk contohnya:
Kucing mengejar anjing
Beberapa hari yang lalu, kucing itu mengejar anjing itu dari sini.


Matriks tali
Tali memutar vektor untuk "anjing" dan "anjing" dengan jumlah yang sama, memelihara sudut di antara mereka sehingga tetap sama di mana -mana. Ini bermakna produk titik antara 2 vektor akan tetap sama walaupun kita menambah kata -kata pada awal atau akhir vektor tersebut, dengan andaian bahawa jarak antara vektor tetap sama.
Idea utama tali adalah untuk memutar pertanyaan dan vektor utama berdasarkan kedudukan mereka dalam urutan.


- Matriks putaran, yang membantu memutar vektor dengan sudut "mx θ".
- Kami mula -mula memohon transformasi linear untuk mendapatkan pertanyaan dan vektor utama, kemudian gunakan matriks putaran untuk mengekalkan harta invarians putaran.
Invariance putaran merujuk kepada harta sistem atau fungsi yang masih tidak berubah di bawah putaran.
Nota: Kami hanya menggunakan putaran untuk pertanyaan dan vektor utama, bukan vektor nilai - Ini adalah vektor yang kita putar.
Tetapi pada hakikatnya, matriks pastinya tidak dalam 2D dan boleh memanjang hingga dimensi seperti ini:

Di sini, vektor dibahagikan kepada ketulan 2 dan diputar oleh m kali tertentu θ.
Tetapi logik semacam ini benar -benar buruk kerana memori dan kerumitan pengiraan yang tidak perlu. Jadi, bukannya ini, kami akan melaksanakan menggunakan operasi elemen seperti ini:

Biasanya, diandaikan bahawa dimensi vektor adalah, yang biasanya berlaku, oleh itu andaian membuat potongan 2 di sini.
Lembaran ini digunakan untuk melatih beberapa model bahasa seperti Bert, Roformer, dan lain -lain, yang mempamerkan bahawa model -model ini dilatih lebih cepat dengan embeddings tali atas embeddings sinusoidal.
Komponen tali
Tali mempunyai 2 jenis komponen - komponen frekuensi tinggi dan frekuensi rendah. Komponen frekuensi tinggi sangat sensitif terhadap perubahan kedudukan. Komponen frekuensi rendah, sebaliknya, kurang sensitif terhadap kedudukan relatif, yang membolehkan transformer mengekalkan perhatian semantik ke arah jarak yang lebih jauh.
Oleh itu, asas N meningkat dari 10000 hingga 500000, yang seterusnya melambatkan komponen frekuensi rendah, yang membolehkan transformer menghadiri token relatif dengan jarak relatif yang besar untuk menangkap ketergantungan jarak jauh.
Tetapi kita perlu memahami bagaimana kita dapat memastikan tali dapat digunakan untuk urutan panjang konteks yang lebih lama. Latihan model secara langsung pada konteks log masuk sangat mencabar kerana kelajuan latihan, jejak memori, dan kekurangan data berskala besar. Sumber -sumber jenis ini sangat terhad kerana hanya syarikat teratas yang mempunyai keupayaan ini. Kami juga akan membincangkan panjang konteks yang lebih lama di bahagian seterusnya, yang dipanggil perhatian infini, dan kesannya terhadap masa depan LLM.
Pendek kata: Satu kaedah yang berkesan adalah untuk memulihkan kedudukan ke dalam panjang konteks latihan; Ini dipanggil interpolasi kedudukan. Ini pada dasarnya pada dasarnya skala kedudukan lebih jauh, melambatkan komponen frekuensi rendah, oleh itu membolehkan maklumat urutan panjang konteks panjang untuk disimpan.
Perhatian infini
Model Transformer biasanya mempunyai tingkap konteks bersaiz terhad. Perhatian Infini menggabungkan memori mampatan ke dalam mekanisme perhatian vanila dan membina kedua -dua perhatian tempatan bertopeng dan mekanisme perhatian linear yang panjang dalam satu blok pengubah. Mekanisme perhatian datang dengan lebih banyak kelemahan, seperti:
- Ia mempunyai kerumitan kuadratik dalam kedua -dua memori dan masa pengiraan.
- Keterbatasan dalam skala pengubah ke urutan yang lebih panjang (pada dasarnya, mempelajari perwakilan yang baik dari urutan yang lebih lama menjadi mahal).
Terdapat beberapa eksperimen sebelum pelepasan "Tinggalkan Konteks Tidak Di belakang: Infinite Cekap dengan Perhatian Infini". Sesetengah teknik seperti melakukan barisan pengiraan mengikut baris, yang mana kita berdagang pengiraan terhadap ingatan, tetapi masih, kita mempunyai kerumitan kuadratik dalam pengiraan, tidak kira bagaimana kita mengedarkannya. Terdapat juga percubaan untuk melakukan perhitungan perhatian linear, yang juga dipanggil perhatian linear atau berat cepat. Beberapa pendekatan dibuat untuk mengatasi kesesakan kerumitan kuadrat ini, tetapi perhatian infini datang ke hadapan.

Memori mampatan
Perhatian Infini mempunyai unit memori mampatan selain mekanisme perhatian vanila.
Sistem memori mampatan dalam perhatian infini direka untuk mengendalikan urutan yang panjang dengan meringkaskan maklumat masa lalu dalam bentuk padat. Daripada menyimpan semua data yang lalu, mereka mengekalkan set parameter tetap yang bertindak sebagai ringkasan sejarah urutan. Ringkasan ini boleh dikemas kini dari masa ke masa dan masih mengekalkan maklumat berguna. Idea utama ialah apabila maklumat baru tiba, memori dikemas kini dan parameternya diubah suai sedemikian rupa sehingga aspek yang paling relevan dari maklumat baru itu ditangkap. Ini membolehkan model untuk mengingati butiran penting kemudian, tanpa perlu menyimpan atau memproses keseluruhan urutan secara eksplisit.
Akibatnya, kedua -dua keperluan penyimpanan dan pengiraan kekal dalam had tertentu, menjadikannya lebih berskala untuk memproses input yang panjang, dan oleh itu pemain utama dalam membentuk masa depan LLM.
Urutan yang sangat panjang dipecah menjadi segmen "S". Setiap segmen ini diproses oleh mekanisme perhatian kausal, dan perwakilan tempatan diekstrak dari segmen semasa ini. Di atas ini, perwakilan lain yang mempunyai maklumat mengenai sejarah urutan diambil dari memori termampat. Kemudian, perwakilan segmen semasa dilampirkan atau dikemas kini ke dalam memori termampat. Akhirnya, pada akhirnya, perwakilan tempatan dari segmen semasa dan perwakilan maklumat yang diambil digabungkan untuk membentuk perwakilan jarak jauh global.
Pada asasnya, terdapat 4 langkah utama - perwakilan tempatan, pengambilan semula, kemas kini memori mampatan, dan agregasi perwakilan.

Aliran kerja lengkap
Dalam konteks yang lebih besar untuk memahami masa depan LLM, mari kita mula -mula pergi ke aliran kerja lengkap dari awal, adakah kita?
Dalam perhatian infini, kita membahagikan urutan input ke dalam pelbagai bahagian atau segmen. Sebagai contoh, jika saiz segmen adalah 100 token, kami memproses token 100 pertama sebagai satu segmen menggunakan mekanisme perhatian standard. Selepas mengira pasangan nilai utama (output perhatian) untuk segmen ini, kami menyimpan perwakilan ini dalam apa yang dipanggil memori mampatan.
Memori ini bertindak sebagai jambatan antara segmen. Untuk setiap lapisan dan setiap kepala perhatian, model mengambil apa yang telah dipelajari dari segmen semasa dan menambahkannya ke ingatan ini. Kemudian, apabila segmen seterusnya diproses, ia dapat mengakses memori ini, membantu ia mengekalkan maklumat dari segmen terdahulu.
Ringkasnya, perwakilan tempatan masih dikira menggunakan perhatian standard, tetapi perhatian infini meningkatkan ini dengan meluluskan maklumat yang dipelajari ke hadapan melalui struktur memori bersama.
Cara menyimpan pengiraan nilai utama seperti pertanyaan ke dalam jenis pengiraan utama ke memori untuk langkah -langkah masa lalu, dan entah bagaimana dapat menggunakannya untuk langkah -langkah masa depan.


Sekarang, kita akan melihat bagaimana memori termampat ini digunakan semula oleh blok pengubah segmen yang akan datang. Jadi di sini kita akan menggunakan mekanisme gating, yang kelihatan sangat mirip dengan logik yang digunakan dalam mekanisme gating LSTM.

Mekanisme gating
Di sini, kami tidak mengambil q, k, v untuk segmen semasa dan pada dasarnya menambah embeddings posisional (tali) dan kemudian mengira perhatian diri seperti yang dilakukan di atas tetapi juga menggunakan maklumat yang kami ada dari segmen sebelumnya dalam bentuk memori yang dimampatkan dengan mengambil maklumat dengan menggunakan Q (pertanyaan) yang digunakan untuk mendapatkan maklumat dari segmen semasa.
β di sini dipanggil skalar gating. Ia membantu dalam penggabungan perhatian dari segmen semasa dan sebelumnya. Ia adalah parameter yang dipelajari.
Sekarang, kita akan memahami bagaimana memori ini diperolehi.

Maklumat yang kami hituskan disimpan dalam matriks ini, di mana dalam pengangka kami menggunakan matriks memori segmen sebelumnya. Kami mengambil segmen semasa dan menggunakan fungsi pengaktifan, yang menggunakan ELU.
Z Berikut adalah jumlah semua kunci. Tidak banyak perkara; Ia kebanyakannya digunakan dalam formula ini untuk tujuan normalisasi.
Sekarang, mari kita faham bagaimana memori dikemas kini ke memori yang dimampatkan

Kemas kini memori
Untuk kemas kini ingatan, terdapat 2 kaedah:
- Kemas kini linear adalah mudah, yang merangkumi memori segmen sebelumnya dengan pengiraan segmen semasa.
- Dalam pengemaskinian delta linear, pengiraan z adalah serupa dengan kaedah di atas, tetapi di sini pengemaskinian memori sedikit berbeza. Di sini, kita tolak sumbangan beberapa bahagian memori. Pada asasnya, beberapa pengiraan perhatian telah dilakukan dari segmen sebelumnya, jadi kami hanya mengemas kini pengetahuan baru, dan maklumat sebelumnya adalah seperti itu. Ini membantu dalam mengeluarkan pendua dan menjadikan memori kurang berantakan.
Bagi bahagian pengambilan semula, kami akan menggunakan segmen semasa Q (pertanyaan) untuk mendapatkan serpihan memori yang diperlukan dari memori yang dimampatkan dan yang diluluskan ke dalam mekanisme gating seperti yang dijelaskan di atas.
Ini adalah bagaimana aliran keseluruhan perhatian infini berfungsi secara dalaman.
Mari kita lihat beberapa metrik tentang bagaimana perhatian infini yang berkesan dibandingkan dengan kajian lain seperti Transformer XL, Transformer Berasaskan Reformer, dan lain-lain ...

Di sini, semakin rendah skor, lebih baik prestasi model menunjukkan.
Satu lagi ujian yang berkesan telah dilakukan mengenai tugas pengambilan semula dengan bereksperimen dengan tugas pengambilan laluan berasaskan sifar di mana laluan masuk berasaskan angka disembunyikan dengan konteks maklumat teks yang besar, dan model pengubah ditugaskan untuk mengekstrak dan mengambil semula laluan ini


Di sini, kita dapat melihat bahawa Transformer Infini, yang disusun sehingga 400 langkah, sangat berkesan pada tugas pengambilan semula, terutamanya apabila kita menggunakan logik pengemaskinian memori delta linear seperti yang dijelaskan di atas.

Transformer Infini melakukan lebih baik daripada beberapa model seperti Bart dan Primera ketika datang ke summarisasi, seperti yang dipamerkan dengan nilai Rouge yang disediakan dalam jadual di atas. Ini memberi kita gambaran utama tentang masa depan LLM.
Kesimpulan
Dalam artikel ini, kami meneroka tiga inovasi utama - fungsi pengaktifan swish, embeddings tali, dan perhatian infini yang secara aktif membentuk generasi akan datang model bahasa besar atau masa depan LLM secara umum. Setiap kemajuan ini menangani batasan kritikal dalam seni bina terdahulu, sama ada ia meningkatkan aliran kecerunan, meningkatkan pemahaman kedudukan, atau memanjangkan panjang konteks dengan cekap.
Memandangkan penyelidikan dalam bidang ini terus mempercepatkan, sumbangan dari seluruh dunia, yang didorong oleh komuniti sumber terbuka yang berkembang maju, membolehkan kita mendapatkan pandangan yang lebih mendalam ke dalam kerja-kerja dalaman LLM yang canggih, mengembangkannya ke ketinggian baru pada masa akan datang. Terobosan ini bukan sahaja meningkatkan prestasi model tetapi juga mentakrifkan semula apa yang mungkin dalam pemahaman bahasa dan generasi semula jadi.
Masa depan LLMS sedang dibina di atas inovasi asas seperti itu, dan tetap dikemas kini pada mereka adalah kunci untuk memahami di mana AI menuju seterusnya. Anda boleh membaca tentang bagaimana LLM moden memahami imej visual di sini.
Atas ialah kandungan terperinci Masa Depan LLM: 3 Penciptaan Membentuk Model AI Seterusnya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undress AI Tool
Gambar buka pakaian secara percuma

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.


Stock Market GPT
Penyelidikan pelaburan dikuasakan AI untuk keputusan yang lebih bijak

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)



 Kawalan ibu bapa yang baru dan rsquo; s dan perlindungan kesihatan mental untuk ChatGPT bertujuan untuk menjadikan AI lebih selamat untuk remaja.
Sep 15, 2025 am 12:06 AM
Kawalan ibu bapa yang baru dan rsquo; s dan perlindungan kesihatan mental untuk ChatGPT bertujuan untuk menjadikan AI lebih selamat untuk remaja.
Sep 15, 2025 am 12:06 AM
Openai menggulung kawalan ibu bapa untuk chatgptarents kini boleh berhubung dengan akaun remaja mereka, had ciri, dan mendapatkan makluman jika tekanan emosi dikesan perbualan berisiko akan dikendalikan oleh model khas yang dilatih untuk menyokong penggunaan
 Hos Podcast AI Google Notebooklm kini boleh menjadi hujah mengenai nota anda
Sep 16, 2025 am 07:12 AM
Hos Podcast AI Google Notebooklm kini boleh menjadi hujah mengenai nota anda
Sep 16, 2025 am 07:12 AM
NotebookLM oleh Google Now mempunyai format gambaran audio baru: penambahan ringkas, kritikan, dan debatethese membawa interaksi yang lebih baik dan perbincangan berstruktur untuk memuat naik kandungan yang ditingkatkan mendorong alat lebih dekat ke interaktif, gaya podcast AI
 Microsoft memberi amaran tentang lalu lintas azure yang perlahan
Sep 17, 2025 am 05:33 AM
Microsoft memberi amaran tentang lalu lintas azure yang perlahan
Sep 17, 2025 am 05:33 AM
Microsoft telah mengeluarkan amaran mengenai latensi rangkaian yang lebih tinggi yang mempengaruhi perkhidmatan Azure kerana gangguan di bawah kabel bawah laut yang terletak di Laut Merah, memaksa syarikat itu mengalihkan trafik melalui laluan alternatif. "Walaupun sambungan rangkaian
 GPT 5 vs GPT 4O: Mana yang lebih baik?
Sep 18, 2025 am 03:21 AM
GPT 5 vs GPT 4O: Mana yang lebih baik?
Sep 18, 2025 am 03:21 AM
Pembebasan terbaru GPT-5 telah mengambil dunia dengan ribut. Model perdana terbaru Openai telah menerima ulasan bercampur - sementara beberapa memuji keupayaannya, yang lain menyerlahkan kekurangannya. Ini membuat saya tertanya-tanya: Adakah GPT-
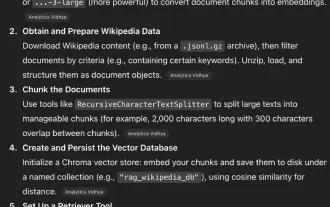
 Codex Cli vs Gemini Cli vs Claude Code: Mana yang terbaik?
Sep 18, 2025 am 04:06 AM
Codex Cli vs Gemini Cli vs Claude Code: Mana yang terbaik?
Sep 18, 2025 am 04:06 AM
Pada tahun 2025, beberapa pembantu pengaturcaraan AI yang boleh diakses terus dari terminal akan dikeluarkan satu demi satu. Codex CLI, Gemini CLI, dan Kod Claude adalah beberapa alat popular yang membenamkan model bahasa besar ke dalam alur kerja baris arahan. Alat pengaturcaraan ini mampu menghasilkan dan membaiki kod melalui arahan bahasa semulajadi, dan sangat kuat. Kami mengkaji prestasi ketiga -tiga alat ini dalam tugas yang berbeza untuk menentukan yang mana lebih praktikal. Setiap pembantu didasarkan pada model AI canggih seperti O4-Mini, Gemini 2.5 Pro atau Claude Sonnet 4, yang direka untuk meningkatkan kecekapan pembangunan. Kami meletakkan tiga dalam persekitaran yang sama dan menggunakan metrik tertentu
 FBI memberi amaran 'Kempen Hacking Taufan Salt' yang tidak disengajakan telah melanda organisasi di lebih daripada 80 negara
Sep 14, 2025 am 12:42 AM
FBI memberi amaran 'Kempen Hacking Taufan Salt' yang tidak disengajakan telah melanda organisasi di lebih daripada 80 negara
Sep 14, 2025 am 12:42 AM
FBI telah mengeluarkan amaran keselamatan kritikal, memberi amaran bahawa kolektif penggodaman terkenal yang dikenali sebagai Taufan Salt semakin menggiatkan operasi sibernya di seluruh dunia. Menurut agensi, kumpulan yang disokong oleh negara ini telah menjalankan secara meluas
 AI bermaksud pelanggaran data sekarang lebih murah - tetapi mereka masih menjadi ancaman besar kepada perniagaan
Sep 21, 2025 am 12:24 AM
AI bermaksud pelanggaran data sekarang lebih murah - tetapi mereka masih menjadi ancaman besar kepada perniagaan
Sep 21, 2025 am 12:24 AM
AI memotong masa yang diperlukan untuk mengesan dan bertindak balas terhadap laporan data yang dibebaskan oleh pemohon AI menjimatkan sehingga £ 600,000 setiap pelanggaran berbanding dengan bukan pengguna 33% organisasi UK telah melaksanakan AI dalam strategi keselamatan mereka dari IBM dalam
 Paradoks AI Trust: Bagaimana Industri Terkawal Boleh Dipercayai Di Dunia yang Dipandang AI
Sep 21, 2025 am 12:36 AM
Paradoks AI Trust: Bagaimana Industri Terkawal Boleh Dipercayai Di Dunia yang Dipandang AI
Sep 21, 2025 am 12:36 AM
Sekiranya anda memberitahu bilik yang penuh dengan eksekutif insurans yang tidak berisiko lima tahun yang lalu bahawa hampir separuh daripada pengguna UK akan segera mengalu-alukan nasihat kesihatan dari AI, anda akan bertemu dengan keraguan yang serius, jika tidak ketawa.
