


Tinjauan terobosan ini, "Dataset untuk Model Bahasa Besar: Satu Kajian Komprehensif," yang dikeluarkan pada bulan Februari 2024, memperkenalkan harta karun lebih dari 400 dataset yang dikategorikan dengan teliti untuk pembangunan model bahasa (LLM) yang besar. Disusun oleh Yang Liu, Jiahuan Cao, Chongyu Liu, Kai Ding, dan Lianwen Jin, sumber ini adalah tambang emas untuk penyelidik dan pemaju. Ia bukan sekadar koleksi statik; Ia sentiasa dikemas kini, memastikan kaitannya yang berterusan.
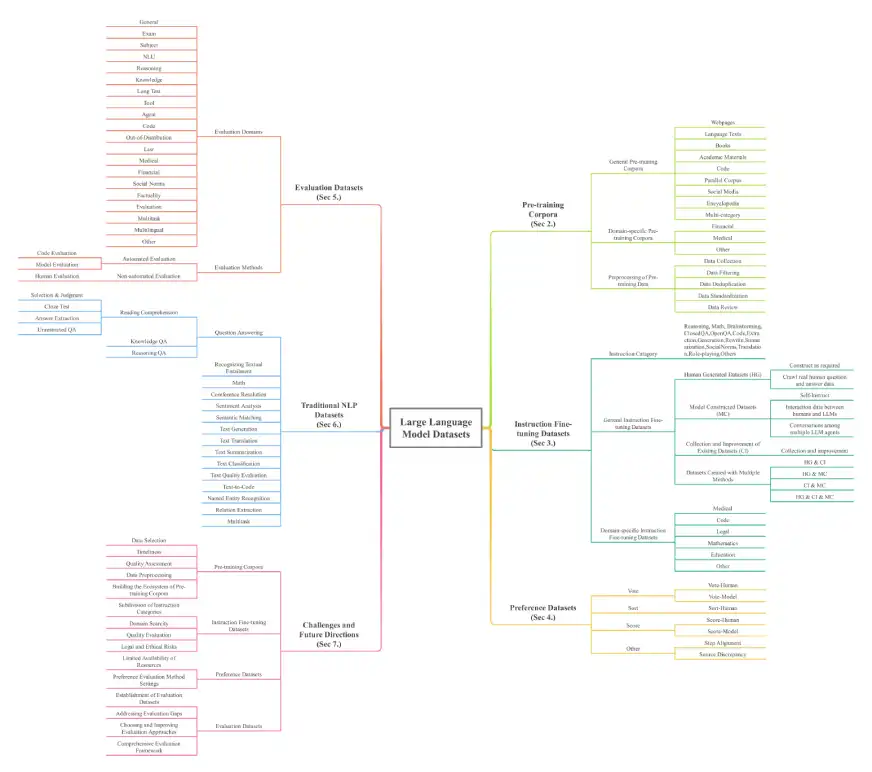
Makalah ini memberikan gambaran menyeluruh mengenai dataset LLM, penting untuk memahami asas model -model yang berkuasa ini. Dataset dikategorikan di tujuh dimensi utama: corpora pra-latihan, kumpulan data penalaan halus, dataset keutamaan, dataset penilaian, dataset NLP tradisional, dataset model bahasa besar (MLLMS), dan kumpulan data generasi penambahan (RAG). Skala semata-mata mengagumkan, dengan lebih daripada 774.5 TB data untuk pra-latihan sahaja dan 700 juta contoh di seluruh kategori lain, merangkumi 32 domain dan 8 bahasa.

Kategori dan contoh dataset utama:
Tinjauan ini memperincikan pelbagai jenis dataset, termasuk:
Pra-latihan Corpora: Koleksi teks besar-besaran untuk latihan LLM awal. Contohnya termasuk Madlad-400 (token 2.8t), Fineweb (token 15TB), dan BookCorpusOpen (17,868 buku). Ini terus dipecah menjadi korpora umum (halaman web, buku, teks bahasa) dan corpora khusus domain (kewangan, perubatan, matematik).
Arahan Data Penalaan Baik: Pasangan arahan dan jawapan yang sepadan untuk memperbaiki tingkah laku model. Contohnya termasuk databricks-dolly-15k dan alpaca_data. Ini juga dikategorikan kepada dataset umum dan khusus (perubatan, kod).
Dataset Keutamaan: Digunakan untuk menilai dan meningkatkan output model dengan membandingkan pelbagai respons. Contohnya termasuk chatbot_arena_conversations dan hh-rlhf.
Dataset Penilaian: Direka khusus untuk penanda aras prestasi LLM pada pelbagai tugas. Contohnya termasuk Alpacaeval dan Bayling-80.
Dataset NLP tradisional: dataset yang digunakan untuk tugas pra-LLM NLP. Contohnya termasuk Boolq, Cosmosqa, dan PubMedqa.
Dataset Model Bahasa Besar Multi-Modal (MLLMS): dataset menggabungkan teks dan modaliti lain (imej, video). Contohnya termasuk Moscar dan MMRS-1M.
Dataset Generasi Tambahan (RAG) Pengambilan semula: Dataset yang meningkatkan LLM dengan keupayaan pengambilan data luaran. Contohnya termasuk crud-rag dan wikieval.

Sumber: Dataset untuk Model Bahasa Besar: Tinjauan Komprehensif
Senibina tinjauan digambarkan di bawah:
Kesimpulan dan penerokaan lanjut:
Tinjauan ini berfungsi sebagai sumber penting, membimbing penyelidik dan pemaju dalam bidang LLM. Repositori yang disediakan (Awesome-LLMS-Datasets) menawarkan pelan tindakan lengkap untuk mengakses dan menggunakan dataset yang tidak ternilai ini. Pengkategorian terperinci dan statistik komprehensif menjadikannya alat penting bagi sesiapa yang bekerja dengan atau meneliti LLM. Makalah ini juga menangani cabaran utama dan mencadangkan arahan penyelidikan masa depan.
Atas ialah kandungan terperinci Panduan kepada 400 Dataset Model Bahasa Besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 aritmetik binari
aritmetik binari
 Cara menggunakan shuffle
Cara menggunakan shuffle
 Bagaimana untuk membeli syiling Ripple sebenar
Bagaimana untuk membeli syiling Ripple sebenar
 Bagaimana untuk memulakan semula perkhidmatan dalam rangka kerja swoole
Bagaimana untuk memulakan semula perkhidmatan dalam rangka kerja swoole
 arahan telnet
arahan telnet
 penggunaan fungsi informix
penggunaan fungsi informix
 Bagaimana untuk menetapkan sempadan bertitik css
Bagaimana untuk menetapkan sempadan bertitik css
 Kedudukan terkini pertukaran mata wang digital
Kedudukan terkini pertukaran mata wang digital
 Apakah tujuh prinsip spesifikasi kod PHP?
Apakah tujuh prinsip spesifikasi kod PHP?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



