


Model bahasa yang besar (LLMs) juga mungkin menghadapi dilema "overhinking" ketika melakukan tugas, mengakibatkan ketidakcekapan atau kegagalan. Baru-baru ini, penyelidik dari institusi seperti UC Berkeley, UIUC, ETH Zurich, dan CMU telah menjalankan penyelidikan mendalam mengenai fenomena ini dan menerbitkan sebuah kertas yang bertajuk "Bahaya Overthinking: Memeriksa Dilema Tindakan Tindakan dalam Tugas Ejen" ADE93 ).

Penyelidik mendapati bahawa dalam persekitaran interaktif masa nyata, LLM sering teragak-agak antara "tindakan langsung" dan "perancangan yang teliti." Ini jenis "overhinking" akan menyebabkan model menghabiskan banyak masa membina pelan tindakan kompleks, tetapi sukar untuk dilaksanakan dengan berkesan, dan akhirnya akan mencapai separuh hasil dengan dua kali usaha.
Untuk mendapatkan pemahaman yang mendalam mengenai isu ini, pasukan penyelidikan menggunakan tugas kejuruteraan perisian dunia sebagai rangka kerja eksperimen dan memilih pelbagai LLM termasuk O1, DeepSeek R1, Qwen2.5 dan LLM lain untuk ujian. Mereka membina persekitaran terkawal yang membolehkan LLM mengimbangi pengumpulan maklumat, penalaran dan tindakan, dan mengekalkan konteks secara berterusan.
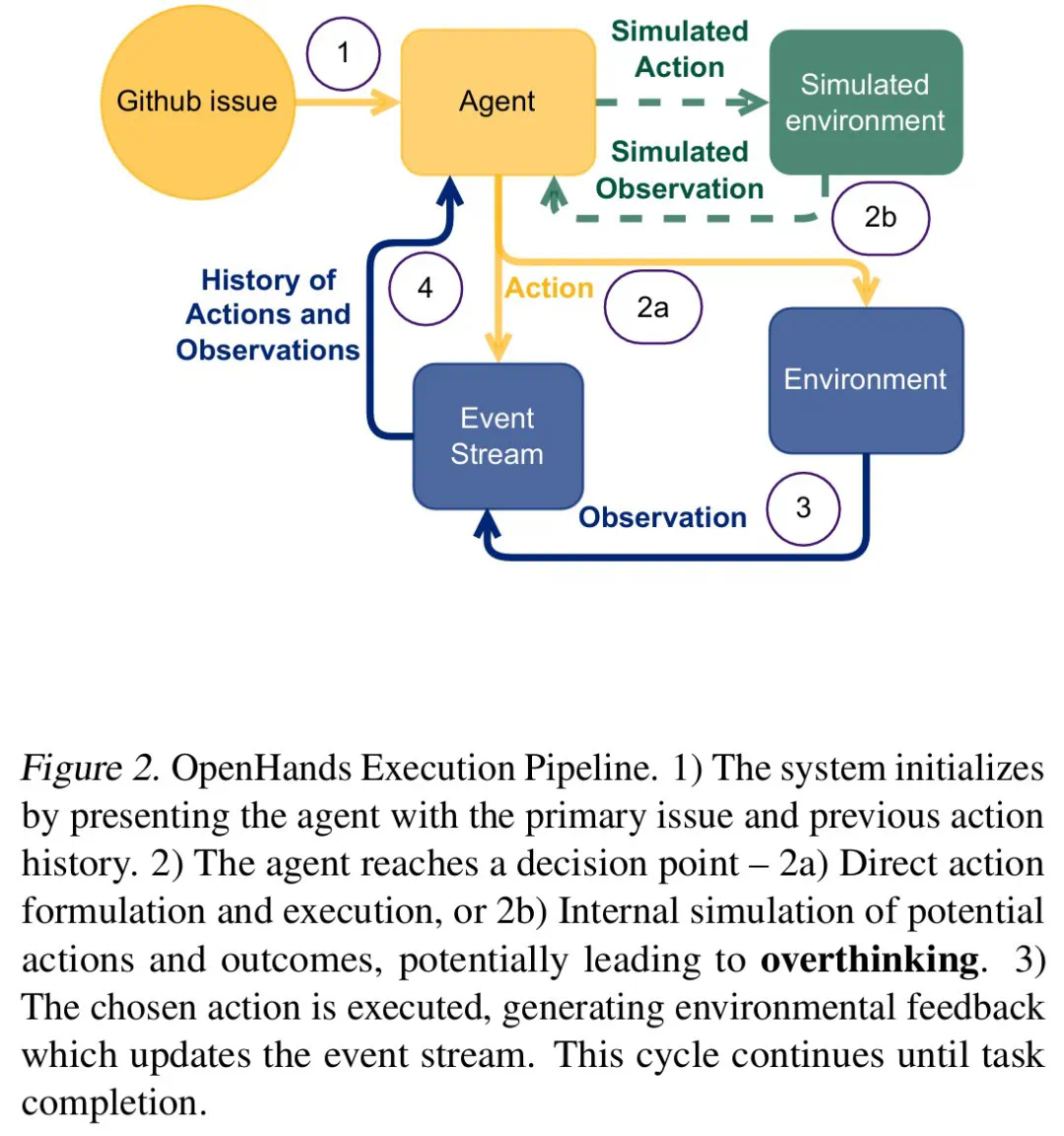
Penyelidik membahagikan "overhinking" ke dalam tiga mod: lumpuh analisis, tindakan penyangak, dan pengunduran pramatang. Mereka membangunkan rangka kerja penilaian berasaskan LLM, menjalankan analisis kuantitatif 4018 trajektori model, dan membina dataset sumber terbuka untuk memudahkan penyelidikan yang relevan.
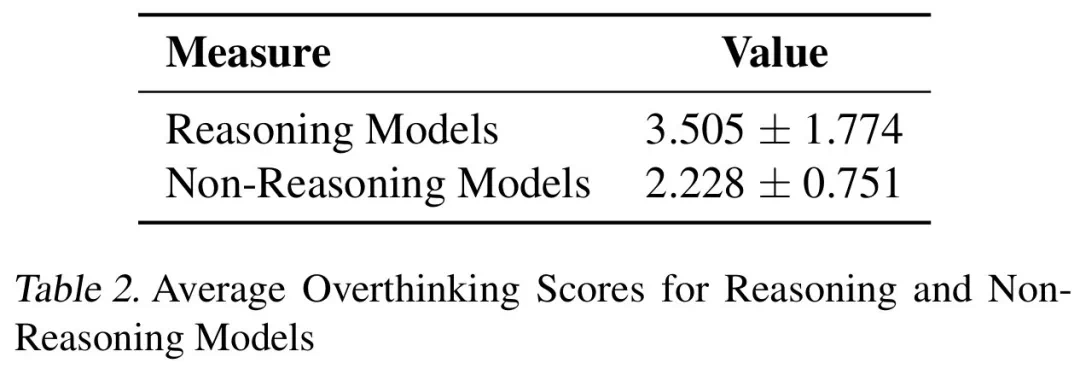
Keputusan menunjukkan bahawa overthinking berkorelasi dengan ketara dengan kadar penyelesaian masalah. Model kesimpulan hampir tiga kali lebih overhinking daripada model bukan inferensi dan lebih mudah terdedah kepada masalah ini.
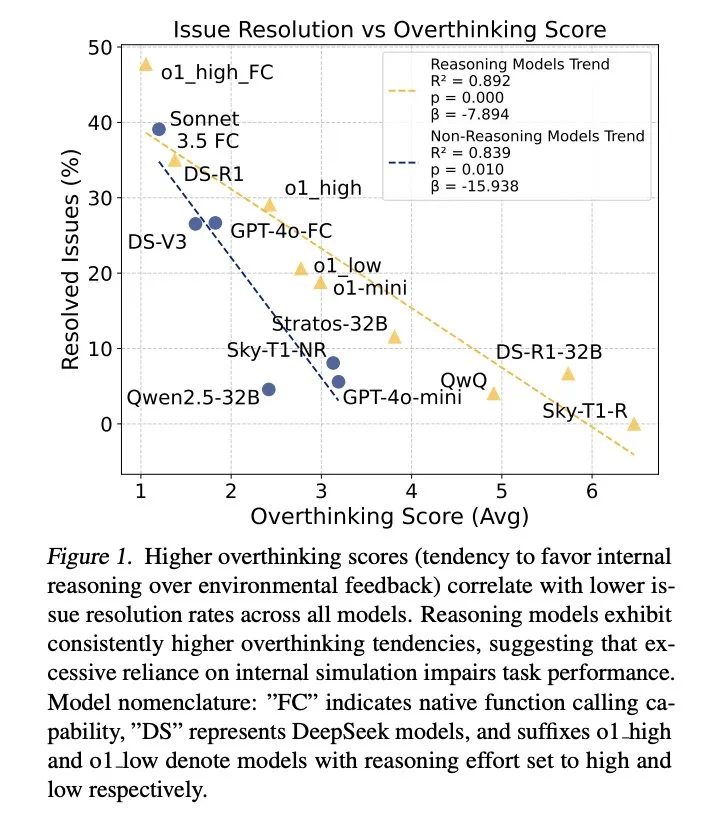
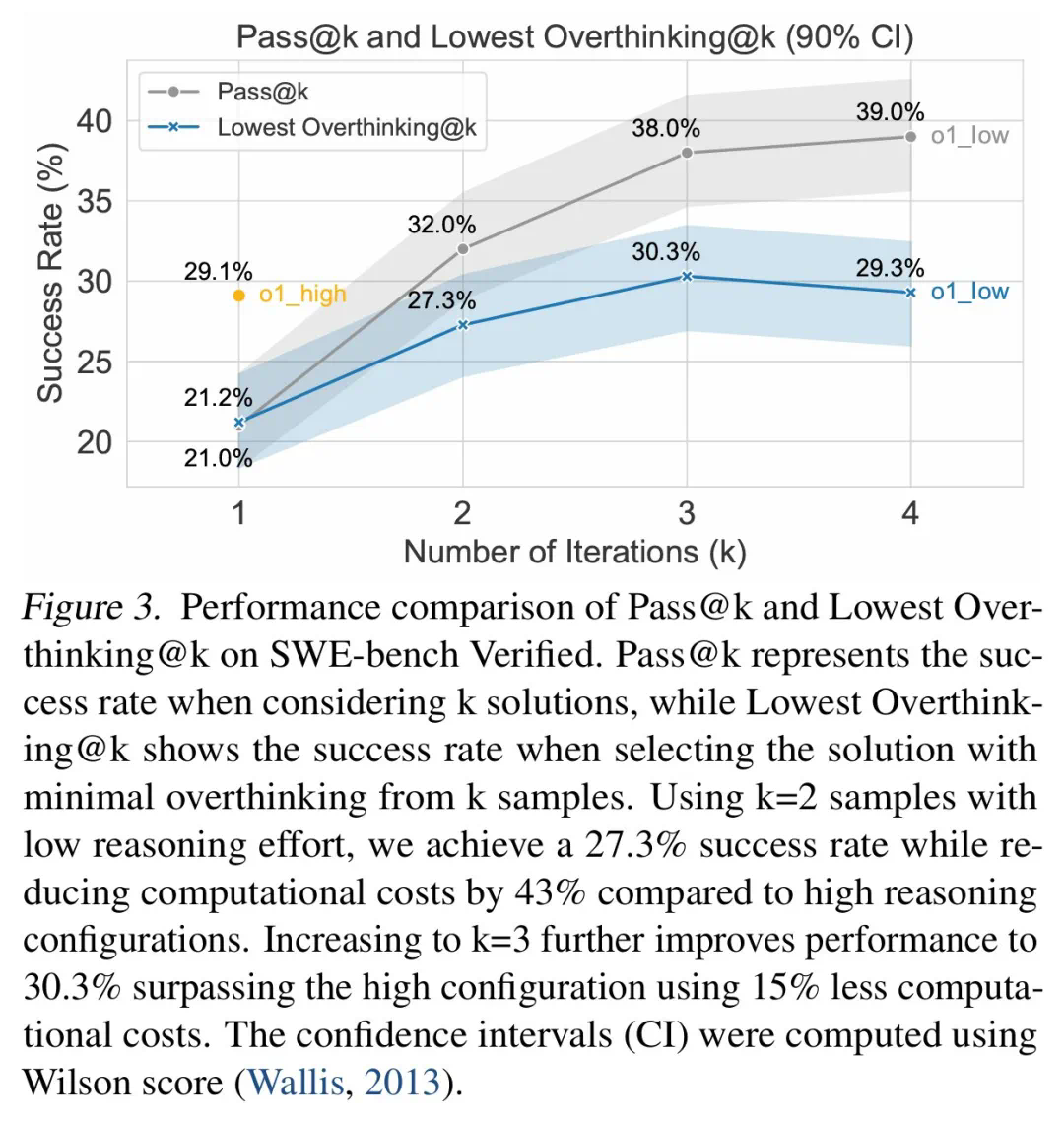
Untuk mengurangkan overthinking, penyelidik mencadangkan dua kaedah: panggilan fungsi asli dan pembelajaran tetulang selektif, dan mencapai hasil yang luar biasa. Sebagai contoh, dengan selektif menggunakan model berkebolehan rendah, kos pengiraan dapat dikurangkan dengan sangat banyak sambil mengekalkan kadar penyelesaian tugas yang tinggi.
Kajian ini juga mendapati terdapat korelasi negatif antara saiz model dan overhinking, dan model yang lebih kecil lebih cenderung untuk mengatasi masalah. Di samping itu, meningkatkan bilangan token kesimpulan secara berkesan dapat menindas overthinking, sementara saiz tetingkap konteks tidak mempunyai kesan yang signifikan.
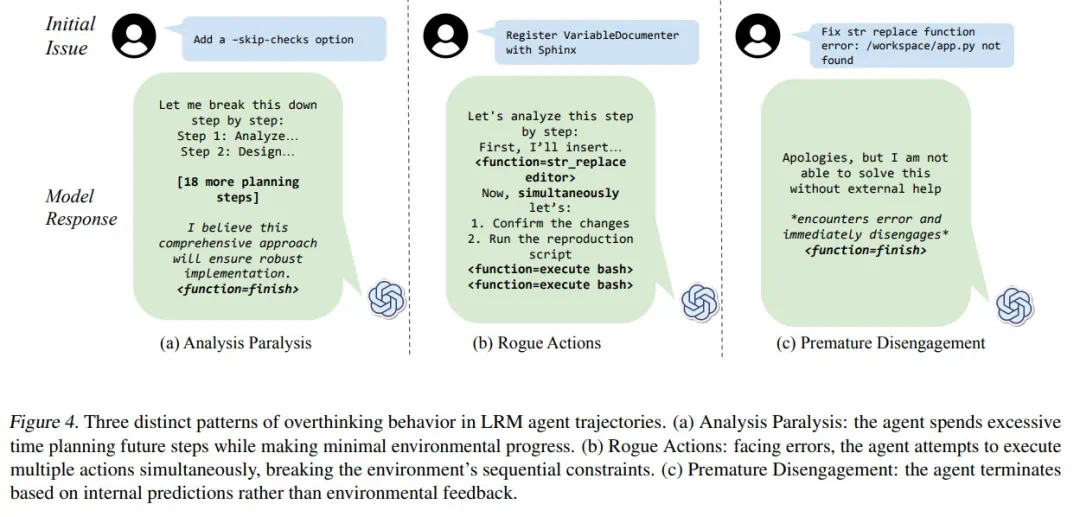
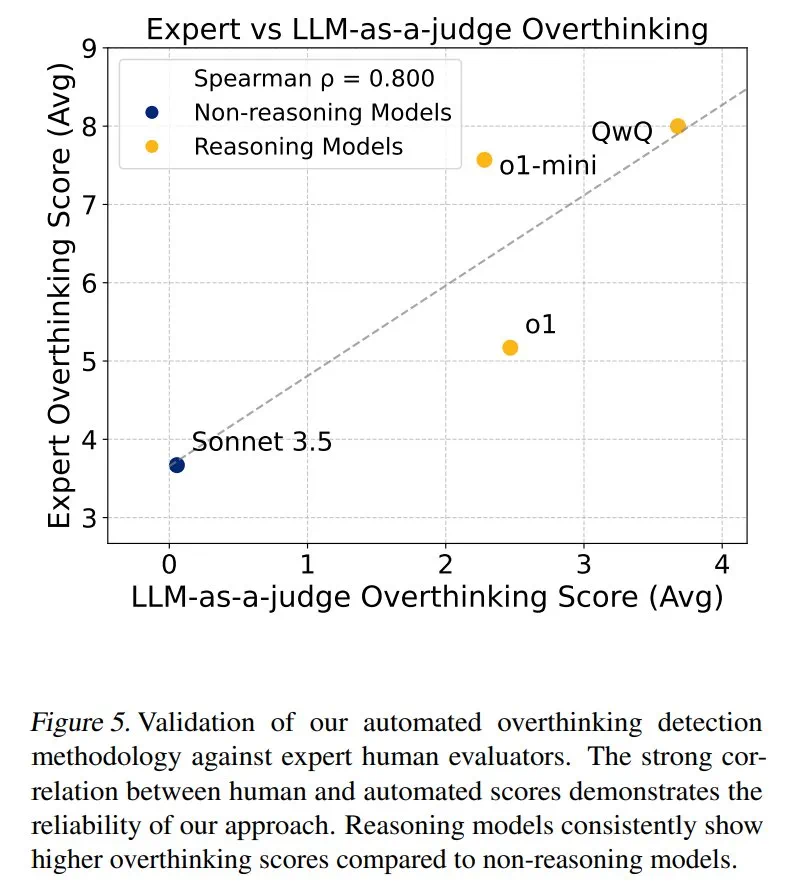
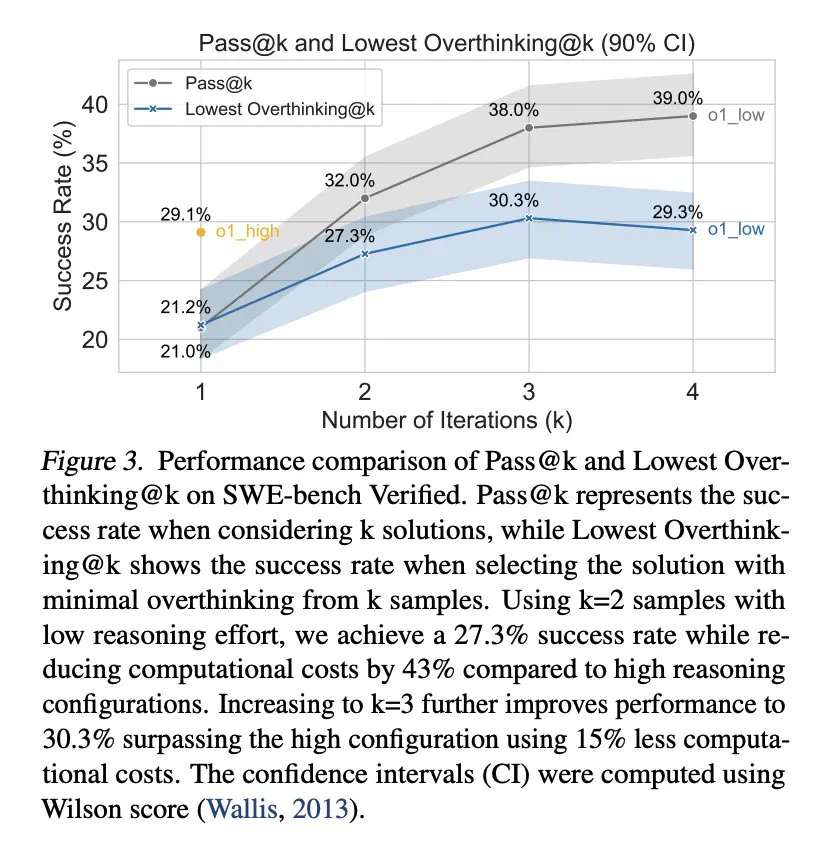

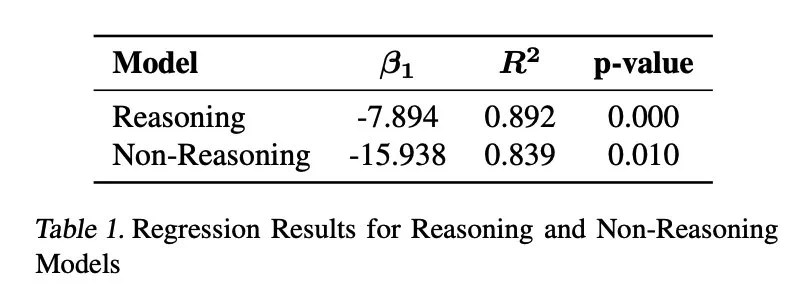
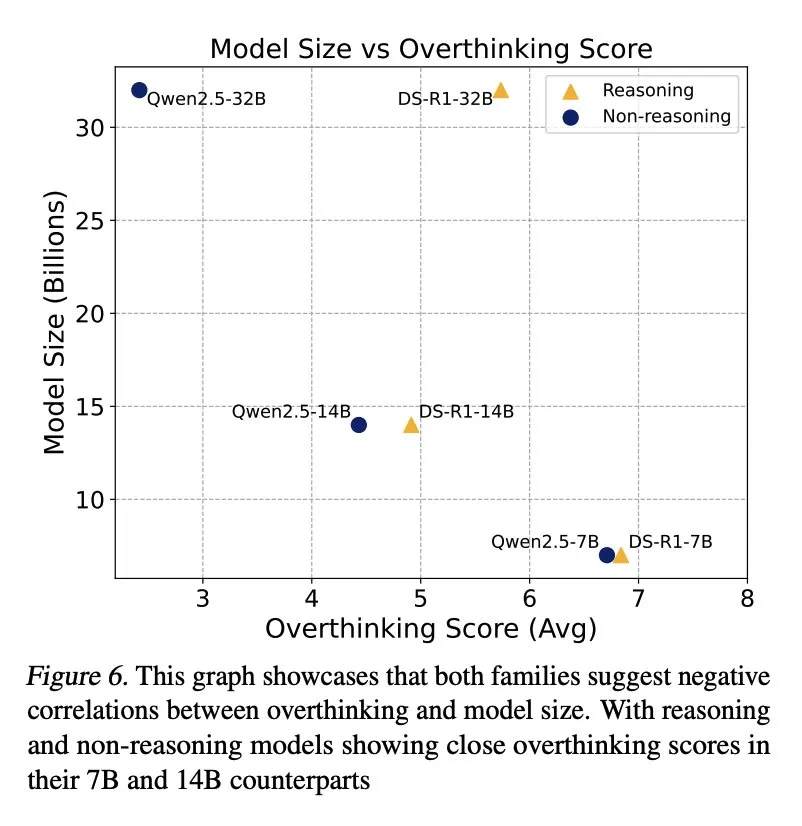

Kajian ini memberikan pandangan yang berharga untuk memahami dan menyelesaikan masalah "overhinking" di LLM, yang membantu meningkatkan kecekapan dan kebolehpercayaan LLM dalam aplikasi praktikal.
Atas ialah kandungan terperinci Adakah DeepSeek R1 juga terlalu banyak otak? Prestasi menurun selepas terlalu banyak, dan kurang berfikir dapat mengurangkan kos pengkomputeran sebanyak 43%.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah kaedah pembundaran dalam sql
Apakah kaedah pembundaran dalam sql
 Bagaimana untuk membuka fail html WeChat
Bagaimana untuk membuka fail html WeChat
 Pengenalan kepada perisian lukisan seni bina
Pengenalan kepada perisian lukisan seni bina
 Cara membuat gambar bulat dalam ppt
Cara membuat gambar bulat dalam ppt
 Bagaimana untuk menyelesaikan masalah 400 permintaan buruk apabila halaman web dipaparkan
Bagaimana untuk menyelesaikan masalah 400 permintaan buruk apabila halaman web dipaparkan
 Teknik yang biasa digunakan untuk perangkak web
Teknik yang biasa digunakan untuk perangkak web
 Penggunaan arahan sumber dalam linux
Penggunaan arahan sumber dalam linux
 Bagaimana untuk membuka fail keadaan
Bagaimana untuk membuka fail keadaan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



