


Penyelidik dari Universiti Shanghai Jiaoto, Shanghai AI Lab dan Universiti Cina Hong Kong telah melancarkan projek sumber terbuka Visual-RFT (Visual Fine Fine Tuning), yang hanya memerlukan sedikit data untuk meningkatkan prestasi mockups bahasa visual (LVLM). Visual-RFT bijak menggabungkan pendekatan pembelajaran tetulang berasaskan peraturan DeepSeek-R1 dengan paradigma penalaan Fine-Penalaan Terbuka (RFT) OpenAI, berjaya memperluaskan pendekatan ini dari medan teks ke medan visual.

Dengan merancang ganjaran peraturan yang sepadan untuk tugas-tugas seperti subkategori visual dan pengesanan objek, Visual-RFT mengatasi batasan kaedah DeepSeek-R1 yang terhad kepada teks, penalaran matematik dan bidang lain, menyediakan cara baru untuk latihan LVLM.

Kelebihan Visual-RFT:
Berbanding dengan kaedah pengajaran visual tradisional (SFT), Visual-RFT mempunyai kelebihan penting berikut:
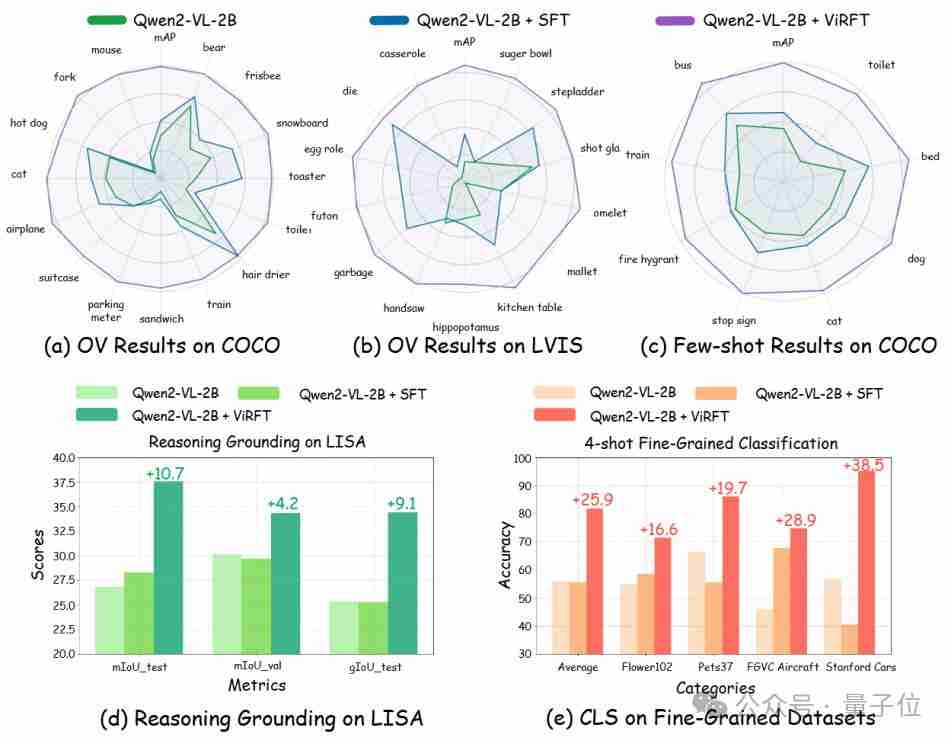
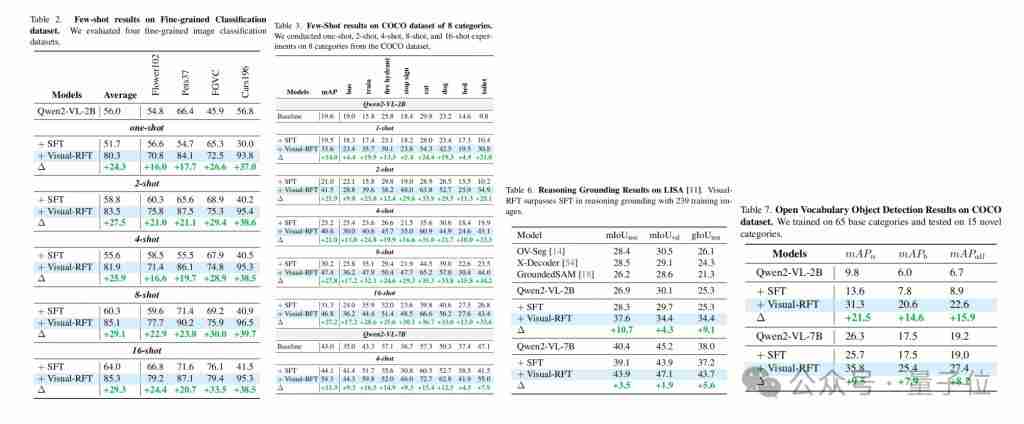
Para penyelidik mengesahkan Visual-RFT pada pelbagai tugas persepsi visual (pengesanan, klasifikasi, lokasi, dan lain-lain), dan hasilnya menunjukkan bahawa visual-RFT mencapai peningkatan prestasi yang signifikan dan pemindahan keupayaan yang mudah dicapai walaupun di bawah tetapan perbendaharaan kata terbuka dan pembelajaran sampel kecil.
Para penyelidik yang direka dengan ganjaran yang dapat disahkan untuk tugas-tugas yang berbeza: ganjaran berasaskan IOU digunakan untuk mengesan dan menempatkan tugas, dan ganjaran berasaskan klasifikasi yang dibenarkan digunakan untuk tugas klasifikasi.
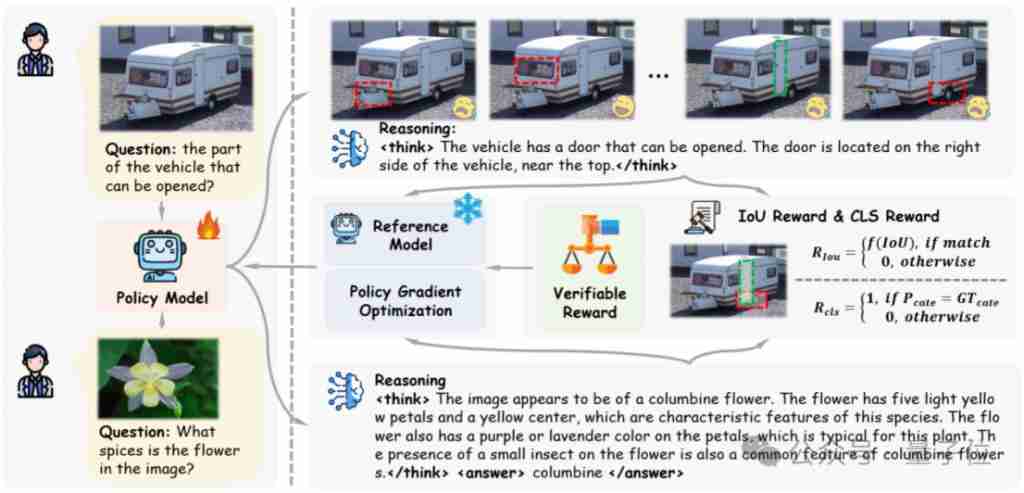
Dalam tugas kedudukan kesimpulan, Visual-RFT menunjukkan keupayaan penalaran visual yang kuat, seperti dengan tepat mengenal pasti gelas kalis air yang perlu dipakai oleh atlet dalam gambar.


Hasil eksperimen:
Eksperimen berdasarkan model QWEN2-VL 2B/7B menunjukkan bahawa Visual-RFT lebih tinggi daripada SFT dalam pengesanan objek terbuka, pengesanan sampel kecil, klasifikasi halus dan tugas kedudukan kesimpulan. Walaupun anda mengesan watak anime tertentu (seperti lendir), Visual-RFT boleh dicapai dengan hanya sedikit data.
Maklumat Sumber Terbuka:
Projek Visual-RFT adalah sumber terbuka dan mengandungi latihan, kod penilaian dan data.
Alamat Projek: //m.sbmmt.com/link/ec56522bc9c2e15be17d11962eeec453

Atas ialah kandungan terperinci Melampaui SFT, rahsia di belakang O1/DeepSeek-R1 juga boleh digunakan dalam model besar multimodal. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bina pelayan git anda sendiri
Bina pelayan git anda sendiri
 Perbezaan antara git dan svn
Perbezaan antara git dan svn
 git undo menyerahkan komit
git undo menyerahkan komit
 Bagaimana untuk membatalkan ralat komit git
Bagaimana untuk membatalkan ralat komit git
 Bagaimana untuk membandingkan kandungan fail dua versi dalam git
Bagaimana untuk membandingkan kandungan fail dua versi dalam git
 Bagaimana untuk menyelesaikan aksara bercelaru dalam PHP
Bagaimana untuk menyelesaikan aksara bercelaru dalam PHP
 Cara menggunakan DataReader
Cara menggunakan DataReader
 Kekunci yang manakah harus saya tekan untuk memulihkan apabila saya tidak boleh menaip pada papan kekunci komputer saya?
Kekunci yang manakah harus saya tekan untuk memulihkan apabila saya tidak boleh menaip pada papan kekunci komputer saya?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



