


Saya menulis skrip Python yang menterjemah logik perniagaan pengekstrakan data PDF ke dalam kod yang berfungsi.
Skrip telah diuji pada 71 halaman PDF Penyata Kustodian meliputi tempoh 10 bulan (Jan hingga Okt 2024). Memproses PDF mengambil masa kira-kira 4 saat untuk disiapkan - jauh lebih cepat daripada melakukannya secara manual.
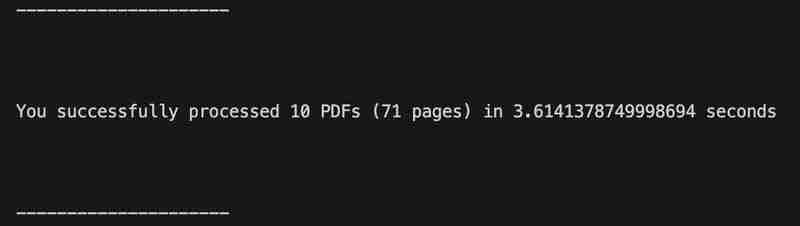
Daripada apa yang saya lihat, output kelihatan betul dan kod itu tidak mengalami sebarang ralat.
Tangkapan gambar bagi tiga output CSV ditunjukkan di bawah. Harap maklum bahawa data sensitif telah dikelabukan.
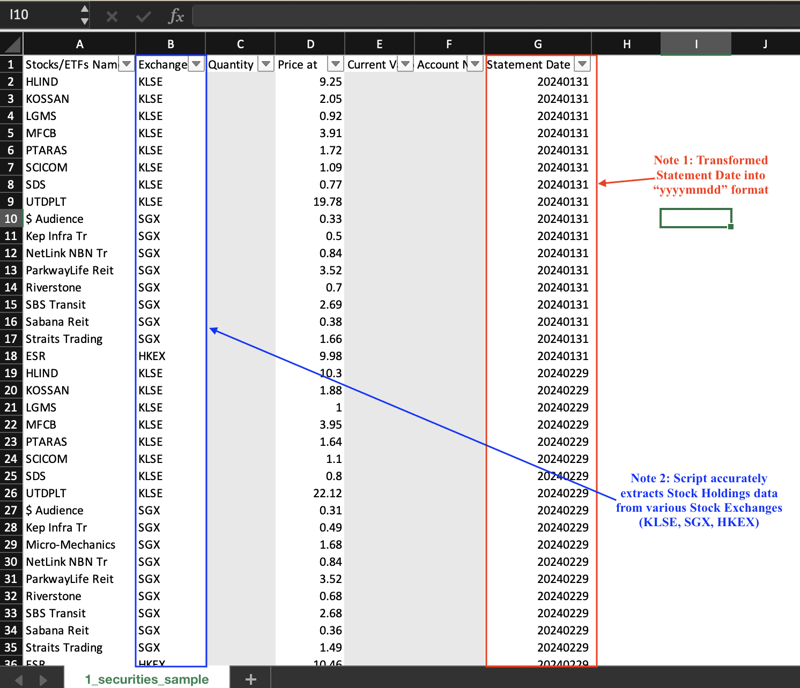
Snapshot 1: Pegangan Saham
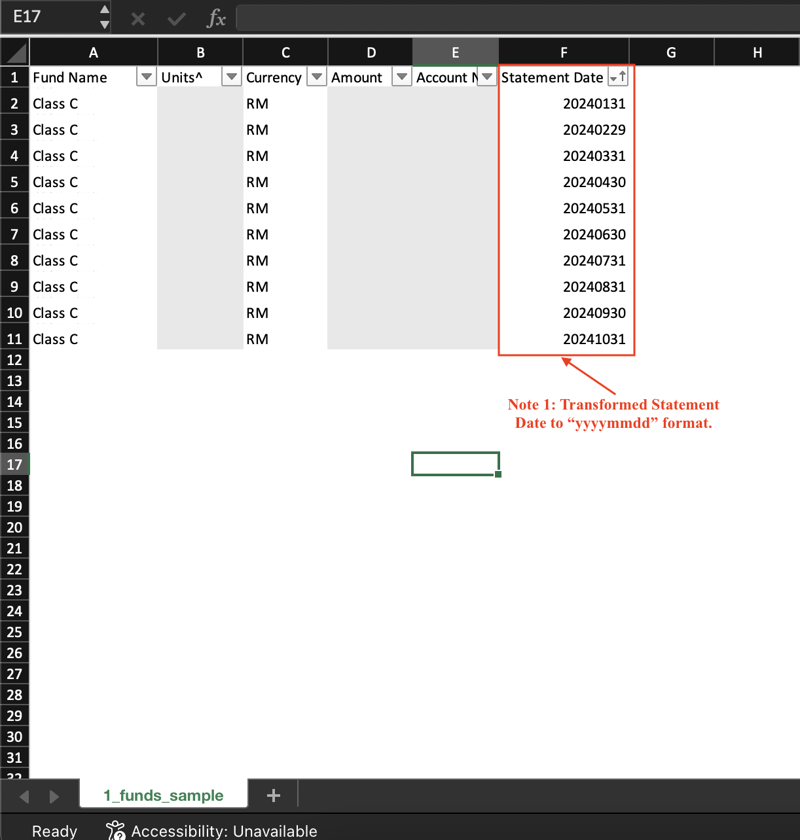
Gambar 2: Pegangan Dana
Gambar 3: Pegangan Tunai

Aliran kerja ini menunjukkan langkah luas yang saya ambil untuk menjana fail CSV.

Sekarang, saya akan menghuraikan dengan lebih terperinci cara saya menterjemah logik perniagaan kepada kod dalam Python.
Saya menggunakan fungsi open() pdfplumber.
# Open the PDF file with pdfplumber.open(file_path) as pdf:
file_path ialah pembolehubah yang diisytiharkan yang memberitahu pdfplumber fail yang hendak dibuka.
Fungsi extract_tables() melakukan kerja keras mengekstrak semua jadual daripada setiap halaman.
Walaupun saya tidak begitu mahir dengan logik asas, saya rasa fungsi itu melakukan kerja yang cukup baik. Sebagai contoh, dua syot kilat di bawah menunjukkan jadual yang diekstrak berbanding yang asal (daripada PDF)
Snapshot A: Output daripada Terminal Kod VS

Snapshot B: Jadual dalam PDF

Saya kemudiannya perlu melabel secara unik setiap jadual, supaya saya boleh "memilih dan memilih" data daripada jadual tertentu kemudian hari.
Pilihan yang ideal ialah menggunakan tajuk setiap jadual. Walau bagaimanapun, menentukan koordinat tajuk adalah di luar kemampuan saya.
Sebagai penyelesaian, saya mengenal pasti setiap jadual dengan menggabungkan pengepala tiga lajur pertama. Contohnya, jadual Pegangan Saham dalam Snapshot B dilabelkan Saham/ETFsnNameExchangeQuantity.
⚠️Pendekatan ini mempunyai kelemahan yang serius - tiga nama pengepala pertama tidak menjadikan semua jadual cukup unik. Nasib baik, ini hanya memberi kesan kepada jadual yang tidak berkaitan.
Nilai khusus yang saya perlukan - Nombor Akaun dan Tarikh Penyata - adalah sub-rentetan dalam Halaman 1 setiap PDF.
Sebagai contoh, "Nombor Akaun M1234567" mengandungi nombor akaun "M1234567".

Saya menggunakan pustaka semula Python dan mendapat ChatGPT untuk mencadangkan ungkapan biasa yang sesuai ("regex"). Regex membahagikan setiap rentetan kepada dua kumpulan, dengan data yang dikehendaki dalam kumpulan kedua.
Regex untuk rentetan Tarikh Penyata dan Nombor Akaun
# Open the PDF file with pdfplumber.open(file_path) as pdf:
Saya seterusnya menukar Tarikh Penyata kepada format "yyyymmdd". Ini memudahkan anda membuat pertanyaan dan mengisih data.
regex_date=r'Statement for \b([A-Za-z]{3}-\d{4})\b'
regex_acc_no=r'Account Number ([A-Za-z]\d{7})'
match_date ialah pembolehubah yang diisytiharkan apabila rentetan yang sepadan dengan regex ditemui.
Ela keras - mengekstrak titik data yang berkaitan - cukup banyak dilakukan pada ketika ini.
Seterusnya, saya menggunakan fungsi DataFrame() panda untuk mencipta data jadual berdasarkan output dalam Langkah 2 dan Langkah 3. Saya juga menggunakan fungsi ini untuk menggugurkan lajur dan baris yang tidak diperlukan.
Hasil akhir kemudiannya boleh ditulis dengan mudah ke CSV atau disimpan dalam pangkalan data.
Saya menggunakan fungsi write_to_csv() Python untuk menulis setiap bingkai data ke fail CSV.
if match_date:
# Convert string to a mmm-yyyy date
date_obj=datetime.strptime(match_date.group(1),"%b-%Y")
# Get last day of the month
last_day=calendar.monthrange(date_obj.year,date_obj.month[1]
# Replace day with last day of month
last_day_of_month=date_obj.replace(day=last_day)
statement_date=last_day_of_month.strftime("%Y%m%d")
df_cash_selected ialah rangka data Cash Holdings manakala file_cash_holdings ialah nama fail Cash Holdings CSV.
➡️ Saya akan menulis data ke pangkalan data yang betul setelah saya memperoleh beberapa pengetahuan pangkalan data.
Skrip berfungsi kini tersedia untuk mengekstrak data jadual dan teks daripada Penyata Penjaga PDF.
Sebelum saya meneruskan lebih jauh, saya akan menjalankan beberapa ujian untuk melihat sama ada skrip berfungsi seperti yang diharapkan.
--Tamat
Atas ialah kandungan terperinci # | Automatikkan pengekstrakan data PDF: Bina. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



