Beli Saya Kopi☕
*Memo:
-
Siaran saya menerangkan Descent Batch, Mini-Batch dan Stochastic Gradient Descent dengan DataLoader() dalam PyTorch.
-
Siaran saya menerangkan Descent Gradient Batch tanpa DataLoader() dalam PyTorch.
-
Siaran saya menerangkan pengoptimum dalam PyTorch.
Terdapat Keturunan Kecerunan Batch(BGD), Keturunan Kecerunan Mini-Batch(MBGD) dan Keturunan Kecerunan Stokastik(SGD) yang merupakan cara cara mengambil data daripada dataset untuk melakukan keturunan kecerunan dengan pengoptimum seperti Adam(), SGD(), RMSprop(), Adadelta(), Adagrad(), dll dalam PyTorch.
*Memo:
-
SGD() dalam PyTorch hanyalah keturunan kecerunan asas tanpa ciri khas(Keturunan Kecerunan Klasik(CGD)) tetapi bukan Keturunan Kecerunan Stokastik(SGD).
- Sebagai contoh, menggunakan cara di bawah ini, anda boleh melakukan BGD, MBGD atau SGD Adam secara fleksibel dengan Adam(), CGD dengan SGD(), RMSprop dengan RMSprop(), Adadelta dengan Adadelta(), Adagrad dengan Adagrad(), dll dalam PyTorch.
- Pada asasnya, BGD, MBGD atau SGD dilakukan dengan set data yang dikocok dengan DataLoader():
*Memo:
- Mengocok set data mengurangkan Terlebih pemasangan. *Pada asasnya, hanya data kereta api dikocok jadi data ujian tidak dikocok.
-
Siaran saya menerangkan Overfitting dan Underfitting.
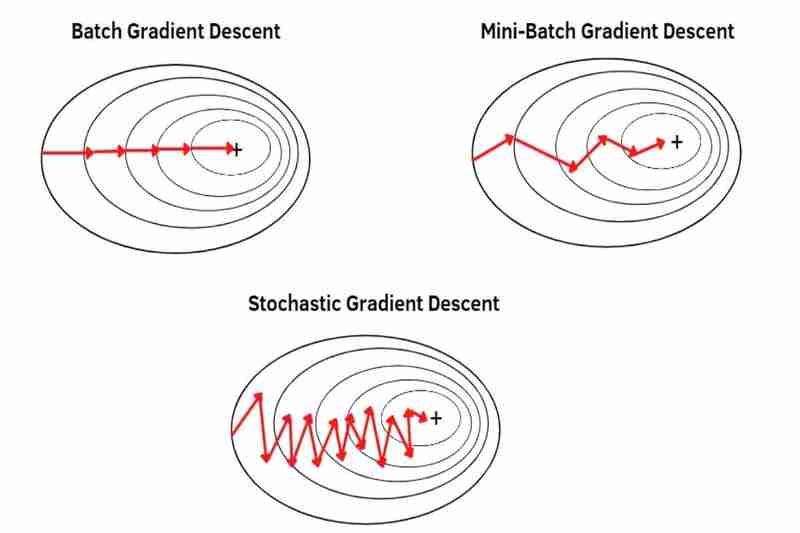
(1) Keturunan Kecerunan Kelompok(BGD):
- boleh melakukan penurunan kecerunan dengan keseluruhan set data, mengambil hanya satu langkah dalam satu zaman. Sebagai contoh, keseluruhan set data mempunyai 100 sampel(1x100), kemudian keturunan kecerunan berlaku sekali sahaja dalam satu zaman yang bermaksud parameter model dikemas kini sekali sahaja dalam satu zaman.
- menggunakan purata keseluruhan set data, jadi setiap sampel kurang menyerlah (kurang ditekankan) berbanding MBGD dan SGD. Akibatnya, penumpuan adalah lebih stabil (kurang turun naik) daripada MBGD dan SGD dan juga lebih kuat dalam hingar (data bising) daripada MBGD dan SGD, menyebabkan kurang overshooting daripada MBGD dan SGD dan mencipta model yang lebih tepat daripada MBGD dan SGD jika tidak terperangkap dalam minima tempatan tetapi BGD kurang mudah melepaskan minima atau mata pelana tempatan berbanding MBGD dan SGD kerana penumpuan adalah lebih stabil (kurang turun naik) daripada MBGD dan SGD seperti yang saya katakan sebelum ini dan BGD lebih mudah menyebabkan overfitting daripada MBGD dan SGD kerana setiap sampel kurang menonjol (kurang ditekankan) daripada MBGD dan SGD seperti yang saya katakan sebelum ini.
*Memo:
-
Penumpuan bermaksud pemberat awal bergerak ke arah minimum global bagi sesuatu fungsi melalui keturunan kecerunan.
-
Bunyi(data bising) bermaksud outlier, anomali atau kadangkala data pendua.
-
Pencapaian berlebihan bermaksud melompati fungsi minimum global.
- kebaikan:
- Tumpuan adalah lebih stabil(kurang turun naik) daripada MBGD dan SGD.
- Ia kuat dalam bunyi(data bising) berbanding MBGD dan SGD.
- Ia kurang menyebabkan overshooting berbanding MBGD dan SGD.
- Ia mencipta model yang lebih tepat daripada MBGD dan SGD jika tidak terperangkap dalam minima tempatan.
Kekurangan - :
- Ia tidak bagus pada set data yang besar seperti pembelajaran dalam talian kerana ia memerlukan banyak memori, memperlahankan penumpuan. *Pembelajaran dalam talian ialah cara model belajar secara berperingkat daripada aliran set data dalam masa nyata.
- Ia memerlukan penyediaan semula keseluruhan set data jika anda ingin mengemas kini model.
- Ia kurang mudah melepaskan minima atau mata pelana tempatan berbanding MBGD dan SGD.
- Ia lebih mudah menyebabkan overfitting berbanding MBGD dan SGD.
(2) Keturunan Kecerunan Kelompok Mini(MBGD):
- boleh melakukan penurunan kecerunan dengan set data terbahagi (kelompok kecil seluruh set data) satu kelompok kecil dengan satu kelompok kecil, mengambil bilangan langkah yang sama seperti kumpulan kecil seluruh set data dalam satu zaman. Sebagai contoh, keseluruhan set data yang mempunyai 100 sampel(1x100) dibahagikan kepada 5 kelompok kecil(5x20), kemudian keturunan kecerunan berlaku 5 kali dalam satu zaman yang bermaksud parameter model dikemas kini 5 kali dalam satu zaman.
menggunakan purata setiap kelompok kecil dipisahkan daripada keseluruhan set data supaya setiap sampel lebih menonjol (lebih ditekankan) daripada BDG. *Memisahkan keseluruhan set data kepada kelompok yang lebih kecil boleh menjadikan setiap sampel lebih menonjol (lebih dan lebih ditekankan). Akibatnya, penumpuan kurang stabil (lebih turun naik) daripada BGD dan juga kurang kuat dalam hingar (data bising) daripada BGD, lebih menyebabkan overshoot daripada BGD dan mencipta model yang kurang tepat daripada BGD walaupun tidak tersekat dalam minima tempatan tetapi MBGD lebih mudah melepaskan minima atau titik pelana tempatan daripada BGD kerana penumpuan kurang stabil (lebih turun naik) daripada BGD kerana saya dikatakan sebelum ini dan MBGD kurang mudah menyebabkan overfitting daripada BGD kerana setiap sampel lebih menonjol (lebih ditekankan) daripada BGD seperti yang saya katakan sebelum ini.
-
kebaikan:
- Ia lebih baik pada set data yang besar seperti pembelajaran dalam talian daripada BGD kerana ia memerlukan memori yang lebih kecil daripada BGD, kurang memperlahankan penumpuan daripada BGD.
- Ia tidak memerlukan penyediaan semula keseluruhan set data jika anda ingin mengemas kini model.
- Ia lebih mudah melepaskan minima atau mata pelana tempatan berbanding BGD.
- Ia kurang mudah menyebabkan overfitting berbanding BGD.
-
keburukan:
- Tumpuan kurang stabil (lebih turun naik) daripada BGD.
- Ia kurang kuat dalam hingar(data bising) berbanding BGD.
- Ia lebih banyak menyebabkan overshooting berbanding BGD.
- Ia mencipta model yang kurang tepat berbanding BGD walaupun tidak tersekat dalam minima tempatan.
(3) Penurunan Kecerunan Stokastik(SGD):
- boleh melakukan penurunan kecerunan dengan setiap sampel keseluruhan set data satu sampel demi satu sampel, mengambil bilangan langkah yang sama seperti sampel keseluruhan set data dalam satu zaman. Sebagai contoh, keseluruhan set data mempunyai 100 sampel(1x100), kemudian keturunan kecerunan berlaku 100 kali dalam satu zaman yang bermaksud parameter model dikemas kini 100 kali dalam satu zaman.
menggunakan setiap sampel bagi keseluruhan set data satu sampel demi satu sampel tetapi bukan purata supaya setiap sampel lebih menonjol (lebih ditekankan) daripada MBGD. Akibatnya, penumpuan adalah kurang stabil (lebih turun naik) daripada MBGD dan juga kurang kuat dalam hingar (data bising) daripada MBGD, lebih menyebabkan overshooting daripada MBGD dan mencipta model yang kurang tepat daripada MBGD walaupun tidak tersekat dalam minima tempatan tetapi SGD lebih mudah melepaskan minima atau titik pelana tempatan daripada MBGD kerana penumpuan kurang stabil (lebih turun naik) daripada MBGD kerana saya dikatakan sebelum ini dan SGD kurang mudah menyebabkan overfitting daripada MBGD kerana setiap sampel lebih menonjol (lebih ditekankan) daripada MBGD seperti yang saya katakan sebelum ini.
-
kebaikan:
- Ia lebih baik pada set data yang besar seperti pembelajaran dalam talian daripada MBGD kerana ia memerlukan memori yang lebih kecil daripada MBGD, kurang memperlahankan penumpuan daripada MBGD.
- Ia tidak memerlukan penyediaan semula keseluruhan set data jika anda ingin mengemas kini model.
- Ia lebih mudah melarikan diri dari minima atau mata pelana tempatan berbanding MBGD.
- Ia kurang mudah menyebabkan overfitting berbanding MBGD.
-
keburukan:
- Tumpuan kurang stabil (lebih turun naik) daripada MBGD.
- Ia kurang kuat dalam hingar(data bising) berbanding MBGD.
- Ia lebih menyebabkan overshooting berbanding MBGD.
- Ia mencipta model yang kurang tepat berbanding MBGD jika tidak tersekat dalam minima tempatan.
Atas ialah kandungan terperinci Batch, Mini-Batch & Stochastic Gradient Descent. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



