


Siaran ini adalah sebahagian daripada siri tentang pengendalian concurrency dalam Go:
WaitGroup pada asasnya ialah satu cara untuk menunggu beberapa gorout menyelesaikan kerja mereka.
Setiap primitif penyegerakan mempunyai set masalahnya sendiri, dan ini tidak berbeza. Kami akan menumpukan pada isu penjajaran dengan WaitGroup, itulah sebabnya struktur dalamannya telah berubah merentas versi yang berbeza.
Artikel ini adalah berdasarkan Go 1.23. Jika apa-apa berubah, sila beritahu saya melalui X(@func25).
Jika anda sudah biasa dengan penyegerakan.WaitGroup, sila langkau ke hadapan.
Mari kita mendalami masalahnya dahulu, bayangkan anda mempunyai tugas yang besar di tangan anda, jadi anda memutuskan untuk memecahkannya kepada tugas-tugas yang lebih kecil yang boleh dijalankan serentak, tanpa bergantung antara satu sama lain.
Untuk menangani perkara ini, kami menggunakan goroutine kerana ia membenarkan tugasan yang lebih kecil ini dijalankan serentak:
func main() {
for i := 0; i < 10; i++ {
go func(i int) {
fmt.Println("Task", i)
}(i)
}
fmt.Println("Done")
}
// Output:
// Done
Tetapi inilah perkaranya, terdapat peluang baik bahawa goroutine utama selesai dan keluar sebelum goroutine lain selesai dengan kerja mereka.
Apabila kami memutarkan banyak goroutine untuk melakukan perkara mereka, kami ingin menjejaki mereka supaya goroutine utama tidak hanya selesai dan keluar sebelum orang lain selesai. Di situlah WaitGroup masuk. Setiap kali salah satu goroutine kami menyelesaikan tugasnya, ia memberitahu WaitGroup.
Setelah semua goroutine telah mendaftar masuk sebagai 'selesai,' goroutine utama mengetahui bahawa ia selamat untuk disiapkan dan semuanya terbungkus dengan kemas.
func main() {
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func(i int) {
defer wg.Done()
fmt.Println("Task", i)
}(i)
}
wg.Wait()
fmt.Println("Done")
}
// Output:
// Task 0
// Task 1
// Task 2
// Task 3
// Task 4
// Task 5
// Task 6
// Task 7
// Task 8
// Task 9
// Done
Jadi, beginilah kebiasaannya:
Biasanya, anda akan melihat WaitGroup.Add(1) digunakan semasa melancarkan goroutine:
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
...
}()
}
Kedua-dua cara secara teknikalnya baik, tetapi menggunakan wg.Add(1) mempunyai prestasi yang kecil. Namun, ia kurang terdedah kepada ralat berbanding menggunakan wg.Add(n).
"Mengapa wg.Add(n) dianggap terdedah kepada ralat?"
Maksudnya ialah ini, jika logik gelung berubah di bawah jalan, seperti jika seseorang menambah pernyataan teruskan yang melangkau lelaran tertentu, keadaan boleh menjadi kucar-kacir:
wg.Add(10)
for i := 0; i < 10; i++ {
if someCondition(i) {
continue
}
go func() {
defer wg.Done()
...
}()
}
Dalam contoh ini, kami menggunakan wg.Add(n) sebelum gelung, dengan mengandaikan gelung akan sentiasa bermula tepat n goroutines.
Tetapi jika andaian itu tidak berlaku, seperti jika sesetengah lelaran dilangkau, program anda mungkin tersekat menunggu gorout yang tidak pernah dimulakan. Dan jujurlah, itulah jenis pepijat yang boleh menyusahkan untuk dijejaki.
Dalam kes ini, wg.Add(1) adalah lebih sesuai. Ia mungkin datang dengan sedikit overhed prestasi, tetapi ia jauh lebih baik daripada menangani overhed ralat manusia.
Terdapat juga kesilapan yang biasa dilakukan orang apabila menggunakan penyegerakan.WaitGroup:
for i := 0; i < 10; i++ {
go func() {
wg.Add(1)
defer wg.Done()
...
}()
}
Inilah yang menjadi puncanya, wg.Add(1) dipanggil di dalam goroutine. Ini boleh menjadi isu kerana goroutine mungkin mula berjalan selepas goroutine utama telah memanggil wg.Wait().
Itu boleh menyebabkan pelbagai masalah masa. Juga, jika anda perasan, semua contoh di atas menggunakan defer dengan wg.Done(). Ia sememangnya harus digunakan dengan penangguhan untuk mengelakkan isu dengan berbilang laluan kembali atau pemulihan panik, memastikan ia sentiasa dipanggil dan tidak menyekat pemanggil selama-lamanya.
Itu sepatutnya merangkumi semua asas.
Mari kita mulakan dengan menyemak kod sumber penyegerakan.WaitGroup. Anda akan melihat corak yang serupa dalam penyegerakan.Mutex.
Sekali lagi, jika anda tidak biasa dengan cara mutex berfungsi, saya amat mengesyorkan anda menyemak artikel ini dahulu: Go Sync Mutex: Normal & Starvation Mode.
type WaitGroup struct {
noCopy noCopy
state atomic.Uint64
sema uint32
}
type noCopy struct{}
func (*noCopy) Lock() {}
func (*noCopy) Unlock() {}
Dalam Go, mudah untuk menyalin struct dengan hanya memberikannya kepada pembolehubah lain. Tetapi sesetengah struct, seperti WaitGroup, benar-benar tidak boleh disalin.
Copying a WaitGroup can mess things up because the internal state that tracks the goroutines and their synchronization can get out of sync between the copies. If you've read the mutex post, you'll get the idea, imagine what could go wrong if we copied the internal state of a mutex.
The same kind of issues can happen with WaitGroup.
The noCopy struct is included in WaitGroup as a way to help prevent copying mistakes, not by throwing errors, but by serving as a warning. It was contributed by Aliaksandr Valialkin, CTO of VictoriaMetrics, and was introduced in change #22015.
The noCopy struct doesn't actually affect how your program runs. Instead, it acts as a marker that tools like go vet can pick up on to detect when a struct has been copied in a way that it shouldn't be.
type noCopy struct{}
func (*noCopy) Lock() {}
func (*noCopy) Unlock() {}
Its structure is super simple:
When you run go vet on your code, it checks to see if any structs with a noCopy field, like WaitGroup, have been copied in a way that could cause issues.
It will throw an error to let you know there might be a problem. This gives you a heads-up to fix it before it turns into a bug:
func main() {
var a sync.WaitGroup
b := a
fmt.Println(a, b)
}
// go vet:
// assignment copies lock value to b: sync.WaitGroup contains sync.noCopy
// call of fmt.Println copies lock value: sync.WaitGroup contains sync.noCopy
// call of fmt.Println copies lock value: sync.WaitGroup contains sync.noCopy
In this case, go vet will warn you about 3 different spots where the copying happens. You can try it yourself at: Go Playground.
Note that it's purely a safeguard for when we're writing and testing our code, we can still run it like normal.
The state of a WaitGroup is stored in an atomic.Uint64 variable. You might have guessed this if you've read the mutex post, there are several things packed into this single value.

Here's how it breaks down:
Then there's the final field, sema uint32, which is an internal semaphore managed by the Go runtime.
when a goroutine calls wg.Wait() and the counter isn't zero, it increases the waiter count and then blocks by calling runtime_Semacquire(&wg.sema). This function call puts the goroutine to sleep until it gets woken up by a corresponding runtime_Semrelease(&wg.sema) call.
We'll dive deeper into this in another article, but for now, I want to focus on the alignment issues.
I know, talking about history might seem dull, especially when you just want to get to the point. But trust me, knowing the past is the best way to understand where we are now.
Let's take a quick look at how WaitGroup has evolved over several Go versions:
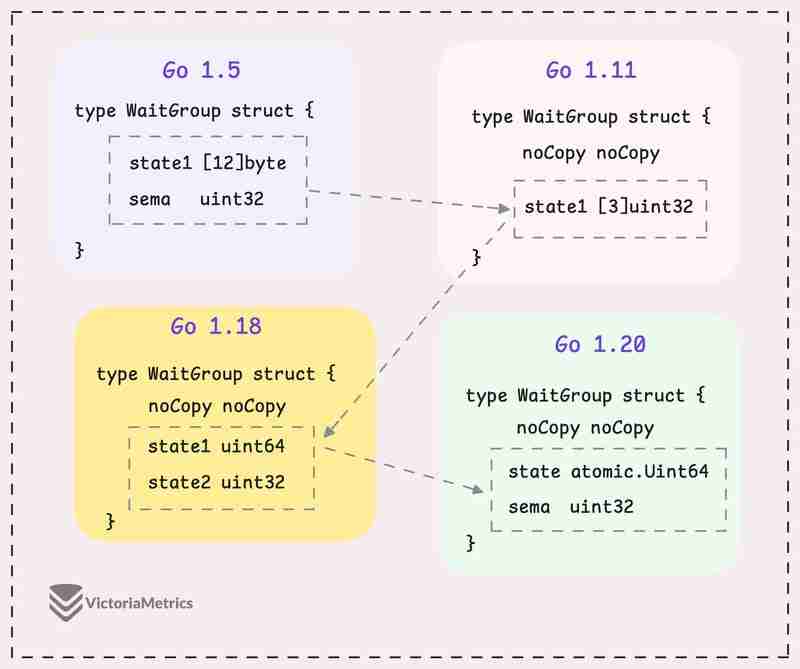
I can tell you, the core of WaitGroup (the counter, waiter, and semaphore) hasn't really changed across different Go versions. However, the way these elements are structured has been modified many times.
When we talk about alignment, we're referring to the need for data types to be stored at specific memory addresses to allow for efficient access.
For example, on a 64-bit system, a 64-bit value like uint64 should ideally be stored at a memory address that's a multiple of 8 bytes. The reason is, the CPU can grab aligned data in one go, but if the data isn't aligned, it might take multiple operations to access it.
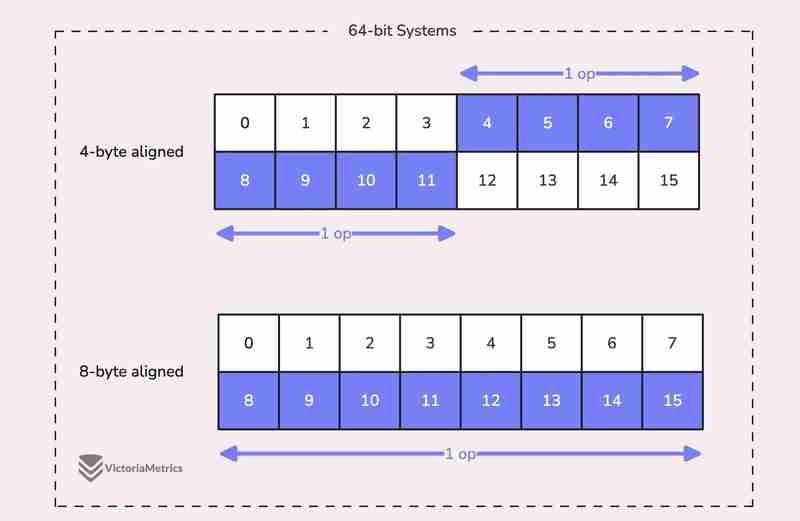
Now, here's where things get tricky:
On 32-bit architectures, the compiler doesn't guarantee that 64-bit values will be aligned on an 8-byte boundary. Instead, they might only be aligned on a 4-byte boundary.
This becomes a problem when we use the atomic package to perform operations on the state variable. The atomic package specifically notes:
"On ARM, 386, and 32-bit MIPS, it is the caller's responsibility to arrange for 64-bit alignment of 64-bit words accessed atomically via the primitive atomic functions." - atomic package note
What this means is that if we don't align the state uint64 variable to an 8-byte boundary on these 32-bit architectures, it could cause the program to crash.
So, what's the fix? Let's take a look at how this has been handled across different versions.
Go 1.5: state1 [12]byte
I'd recommend taking a moment to guess the underlying logic of this solution as you read the code below, then we'll walk through it together.
type WaitGroup struct {
state1 [12]byte
sema uint32
}
func (wg *WaitGroup) state() *uint64 {
if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
return (*uint64)(unsafe.Pointer(&wg.state1))
} else {
return (*uint64)(unsafe.Pointer(&wg.state1[4]))
}
}
Instead of directly using a uint64 for state, WaitGroup sets aside 12 bytes in an array (state1 [12]byte). This might seem like more than you'd need, but there's a reason behind it.
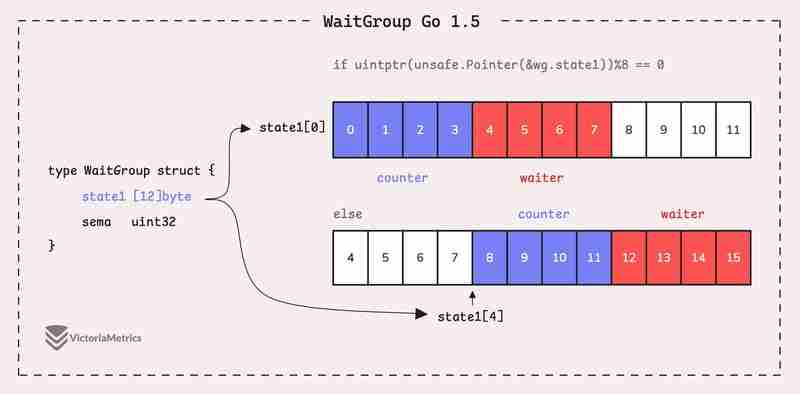
The purpose of using 12 bytes is to ensure there's enough room to find an 8-byte segment that's properly aligned.
The full post is available here: https://victoriametrics.com/blog/go-sync-waitgroup/
Atas ialah kandungan terperinci Pergi sync.WaitGroup dan Masalah Penjajaran. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk membeli syiling Ripple sebenar
Bagaimana untuk membeli syiling Ripple sebenar
 Mengapa wifi mempunyai tanda seru?
Mengapa wifi mempunyai tanda seru?
 beratus-ratus
beratus-ratus
 Apakah yang perlu saya lakukan jika msconfig tidak boleh dibuka?
Apakah yang perlu saya lakukan jika msconfig tidak boleh dibuka?
 Jenis kelemahan sistem
Jenis kelemahan sistem
 Pengenalan kepada sebab mengapa desktop jauh tidak dapat disambungkan
Pengenalan kepada sebab mengapa desktop jauh tidak dapat disambungkan
 cap waktu python
cap waktu python
 Perbezaan antara pengecasan pantas PD dan pengecasan pantas am
Perbezaan antara pengecasan pantas PD dan pengecasan pantas am








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



