



Sunting |. platform pracetak arXiv >Ke Arah Menilai dan Membina Model Bahasa Besar Serbaguna untuk Perubatan
》, menganalisis dan membincangkan secara menyeluruh penggunaan model bahasa besar dalam perubatan klinikal daripada pelbagai perspektif data, penilaian dan model.Semua data, kod dan model yang terlibat dalam artikel ini adalah sumber terbuka.
GitHub:  https://github.com/MAGIC-AI4Med/MedS-Ins
https://github.com/MAGIC-AI4Med/MedS-Ins
Dalam beberapa tahun kebelakangan ini, model bahasa besar (LLM) telah mencapai kemajuan yang ketara dan mencapai keputusan tertentu dalam bidang perubatan. Model ini telah menunjukkan keupayaan cekap pada penanda aras Menjawab Soalan Pelbagai Pilihan Perubatan (MCQA) dan telah mencapai atau melebihi tahap pakar dalam peperiksaan profesional seperti UMLS.
Walau bagaimanapun, LLM masih jauh daripada aplikasinya dalam senario klinikal sebenar. Masalah utama tertumpu pada ketidakcukupan model dalam memproses pengetahuan perubatan asas, seperti kesilapan dalam mentafsir kodICD
, meramalkan prosedur klinikal dan menghuraikan data rekod kesihatan elektronik (EHR).Isu ini menunjukkan titik kritikal: Penanda aras penilaian semasa memfokuskan terutamanya pada soalan aneka pilihan pada peperiksaan perubatan dan tidak menggambarkan penggunaan LLM dengan secukupnya dalam senario klinikal kehidupan sebenar.
Kajian ini mencadangkan penanda aras penilaian baharu, MedS-Bench, yang bukan sahaja merangkumi soalan aneka pilihan, tetapi juga merangkumi 11 tugas klinikal lanjutan seperti ringkasan laporan klinikal, pengesyoran rawatan, diagnosis dan pengiktirafan entiti yang dinamakan. . Pasukan penyelidik menilai berbilang model perubatan arus perdana melalui penanda aras ini dan mendapati bahawa walaupun dengan gesaan beberapa pukulan, model paling canggih, seperti GPT-4,Claude
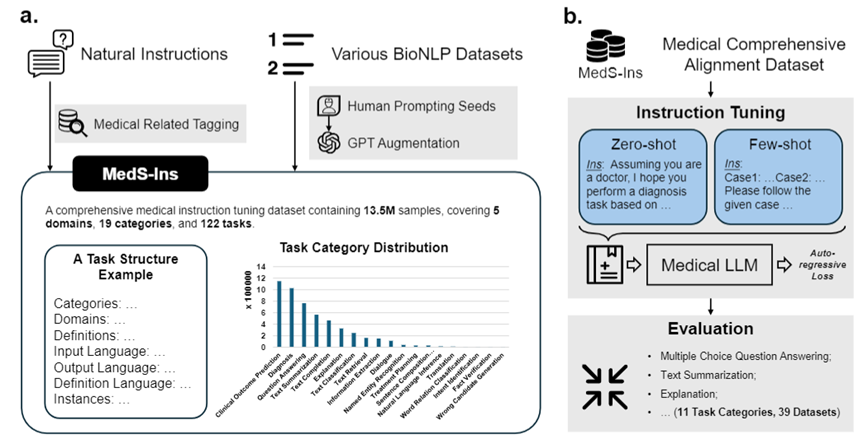
, dsb., juga menghadapi kesukaran dalam mengendalikan tugas klinikal yang kompleks ini.Untuk menyelesaikan masalah ini, diilhamkan oleh Super-NaturalInstructions, pasukan penyelidik membina set data penalaan halus arahan perubatan komprehensif pertama MedS-Ins, yang menyepadukan data daripada peperiksaan, teks klinikal, kertas akademik, 58 teks bioperubatan set data pangkalan pengetahuan perubatan dan perbualan harian, yang mengandungi lebih daripada 13.5 juta sampel, meliputi 122 tugas klinikal.
Atas dasar ini, pasukan penyelidik melaraskan arahan model bahasa perubatan sumber terbuka dan meneroka kesan model dalam persekitaran pembelajaran dalam konteks. Model bahasa besar perubatan yang dibangunkan dalam karya ini, MMedIns-Llama 3, mengatasi model sumber tertutup terkemuka sedia ada seperti GPT-4 dan Claude-3.5 dalam pelbagai tugas klinikal. Pembinaan MedS-Ins telah banyak mempromosikan keupayaan model bahasa besar perubatan dalam senario klinikal sebenar, menjadikan skop aplikasinya jauh melebihi had sembang dalam talian atau soal jawab aneka pilihan. Kami percaya bahawa kemajuan ini bukan sahaja menggalakkan pembangunan model bahasa perubatan, tetapi juga menyediakan kemungkinan baharu untuk aplikasi kecerdasan buatan dalam amalan klinikal pada masa hadapan.Set Data Penanda Aras Ujian (
MedS-Bench) Untuk menilai keupayaan pelbagai LLM dalam aplikasi klinikal, pasukan penyelidik membangunkan MedS -Bench , penanda aras perubatan komprehensif yang melangkaui soalan aneka pilihan tradisional. Seperti yang ditunjukkan dalam rajah di bawah, MedS-Bench diperoleh daripada 39 set data sedia ada, meliputi 11 kategori dan mengandungi sejumlah 52 tugasan.
Dalam MedS-Bench, data diformatkan semula menjadi struktur yang memerintahkan penalaan halus. Di samping itu, setiap tugasan disertakan dengan takrifan tugas beranotasi secara manual. 11 kategori yang terlibat ialah: Menjawab Soalan Pelbagai Pilihan (MCQA), Ringkasan Teks, Pengekstrakan Maklumat (Pengeluaran Maklumat
), Penjelasan dan Rasional, dan Pengiktirafan Entiti Dinamakan (NER) , Diagnosis, Perancangan Rawatan, Ramalan Hasil Klinikal , Klasifikasi Teks, Pengesahan Fakta dan Inferens Bahasa Semulajadi (NLI).
Selain mentakrifkan kategori tugas ini, pasukan penyelidik juga menjalankan statistik terperinci tentang panjang teks MedS-Bench dan membezakan keupayaan yang diperlukan oleh LLM untuk mengendalikan tugasan yang berbeza, seperti yang ditunjukkan dalam jadual di bawah. Keupayaan yang diperlukan untuk tugas pemprosesan LLM dibahagikan kepada dua kategori: (i) penaakulan berdasarkan pengetahuan dalaman model (ii) mendapatkan semula fakta daripada konteks yang disediakan;
Secara umum, yang pertama melibatkan tugas yang memerlukan mendapatkan pengetahuan yang dikodkan dalam pemberat model daripada pra-latihan berskala besar, manakala yang kedua melibatkan tugas yang memerlukan mengekstrak maklumat daripada konteks yang disediakan, seperti ringkasan atau ekstrak maklumat . Seperti yang ditunjukkan dalam Jadual 1, terdapat sejumlah lapan kategori tugasan yang memerlukan model mengingat kembali pengetahuan daripada model, manakala baki tiga kategori tugasan memerlukan pengambilan fakta daripada konteks tertentu.
Jadual 1: Statistik terperinci tugasan ujian yang digunakan.

Set data penalaan halus arahan (MedS-Ins)
Selain itu, pasukan penyelidik juga arahan sumber terbuka Memperhalusi set data MedS-Ins. Set data merangkumi 5 sumber teks yang berbeza dan 19 kategori tugasan untuk sejumlah 122 tugas klinikal yang berbeza. Rajah di bawah meringkaskan proses pembinaan dan maklumat statistik MedS-Ins.
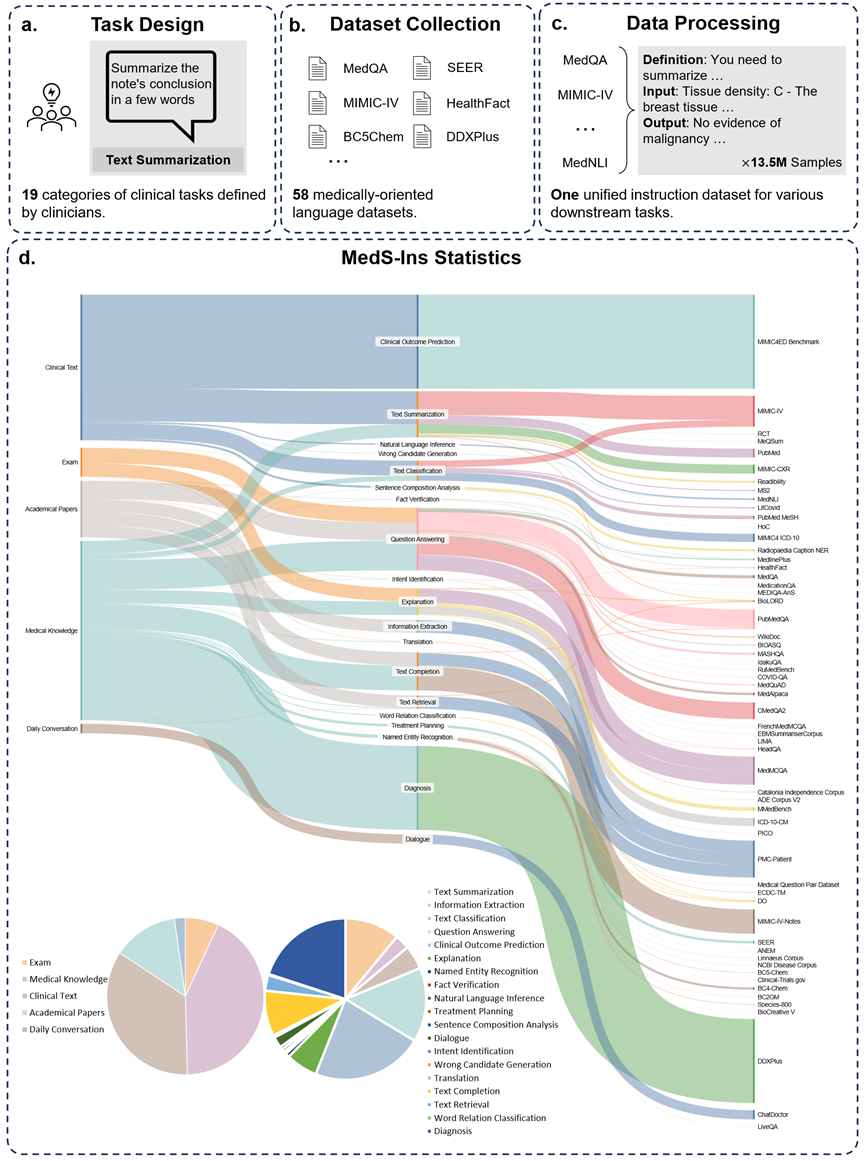
Sumber teks
Data data penalaan halus arahan yang dicadangkan dalam kertas ini terdiri daripada sampel daripada lima sumber berbeza: peperiksaan, teks klinikal, kertas akademik, pangkalan pengetahuan perubatan, dan perbualan harian.
Peperiksaan: Kategori ini mengandungi data daripada soalan peperiksaan perubatan dari negara yang berbeza. Ia merangkumi pelbagai pengetahuan perubatan daripada pengetahuan perubatan asas kepada prosedur klinikal yang kompleks. Soalan peperiksaan adalah cara penting untuk memahami dan menilai tahap pendidikan perubatan Walau bagaimanapun, perlu diperhatikan bahawa tahap penyeragaman peperiksaan yang tinggi sering mengakibatkan kes yang terlalu mudah berbanding dengan tugas klinikal dunia sebenar. 7% daripada data dalam set data berasal daripada peperiksaan.
Teks Klinikal: Kategori teks ini dihasilkan dalam amalan klinikal rutin, termasuk proses diagnostik, terapeutik dan pencegahan di hospital dan pusat klinikal. Teks sedemikian termasuk rekod kesihatan elektronik (EHR), laporan radiologi, keputusan makmal, arahan susulan, pengesyoran ubat dan banyak lagi. Teks ini adalah penting untuk diagnosis penyakit dan pengurusan pesakit, jadi analisis dan pemahaman yang tepat adalah penting untuk aplikasi klinikal LLM yang berkesan. 35% daripada data dalam set data berasal daripada teks klinikal.
Kertas akademik: Kategori data ini datang daripada kertas penyelidikan perubatan, meliputi penemuan dan perkembangan terkini dalam bidang penyelidikan perubatan. Mengekstrak data daripada kertas akademik agak mudah kerana kemudahan akses dan organisasi berstruktur. Data ini membantu model menguasai maklumat penyelidikan perubatan yang paling canggih dan membimbing model untuk lebih memahami perkembangan perubatan kontemporari. 13% daripada data dalam set data berasal daripada kertas akademik.
Pangkalan Pengetahuan Perubatan: Kategori data ini terdiri daripada pengetahuan perubatan komprehensif yang tersusun dengan baik, termasuk ensiklopedia perubatan, graf pengetahuan dan glosari istilah perubatan. Data ini membentuk teras asas pengetahuan perubatan, menyokong pendidikan perubatan dan aplikasi LLM dalam amalan klinikal. 43% daripada data dalam set data berasal daripada pengetahuan perubatan.
Perbualan harian: Kategori data ini merujuk kepada perundingan harian antara doktor dan pesakit, terutamanya daripada platform dalam talian dan senario interaktif yang lain. Data ini mencerminkan interaksi sebenar antara kakitangan perubatan dan pesakit dan memainkan peranan penting dalam memahami keperluan pesakit dan meningkatkan keseluruhan pengalaman perkhidmatan perubatan. 2% daripada data dalam set data berasal daripada perbualan harian.
Jenis tugas
Selain mengklasifikasikan bidang yang terlibat dalam teks, pasukan penyelidik membahagikan lagi kategori tugas sampel dalam MedS-Ins: 19 kategori tugas telah dikenal pasti, setiap kategori mewakili keupayaan utama yang sepatutnya ada pada model bahasa besar perubatan. . Dengan membina arahan ini untuk memperhalusi set data dan memperhalusi model dengan sewajarnya, model bahasa besar mempunyai keupayaan yang diperlukan untuk mengendalikan aplikasi perubatan, seperti yang ditunjukkan dalam Rajah 2.
19 kategori tugas dalam MedS-In termasuk tetapi tidak terhad kepada 11 kategori dalam penanda aras MedS-Bench. Kategori tugas tambahan meliputi pelbagai tugas linguistik dan analisis yang diperlukan dalam bidang perubatan, termasuk pengecaman niat, terjemahan, klasifikasi perhubungan perkataan, perolehan teks, analisis komponen ayat, penjanaan calon ralat, dialog dan pelengkapan teks, manakala MCQA melanjutkan Untuk Soal Jawab umum. Kepelbagaian kategori tugas - daripada Soal Jawab dan perbualan umum kepada pelbagai tugas klinikal hiliran, memastikan pemahaman menyeluruh tentang aplikasi perubatan.
Perbandingan kuantitatif
Pasukan penyelidik menguji secara meluas enam model arus perdana sedia ada (MEDITRON, Mistral, InternLM 2, Llama 3, GPT-4 dan Claude-3.5) Prestasi pada Setiap Jenis Tugasan,Prestasi pelbagai LLM sedia ada mula-mula dibincangkan dan kemudian dibandingkan dengan model akhir yang dicadangkan,MMedIns-Llama 3. Dalam artikel ini, semua keputusan diperoleh menggunakan Prompt 3-shot. Kecuali gesaan sifar pukulan digunakan dalam tugasan MCQA agar konsisten dengan penyelidikan terdahulu. Memandangkan model sumber tertutup seperti GPT-4 dan Claude 3.5 akan menanggung perbelanjaan dan dihadkan oleh kos, hanya 50-100 kes ujian telah diambil sampel untuk setiap tugasan dalam eksperimen Keputusan kuantifikasi ujian komprehensif ditunjukkan dalam Jadual 2-8.
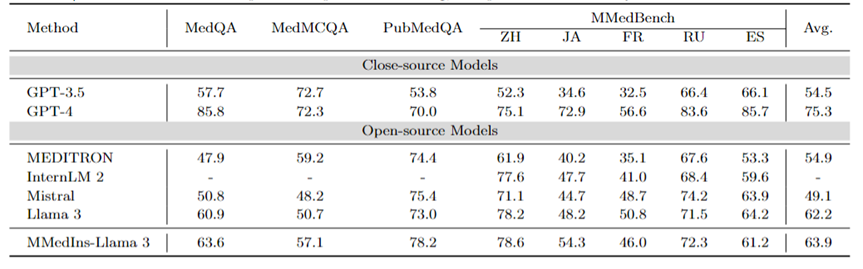
MCQA berbilang bahasa: Jadual 2 menunjukkan keputusan penilaian pada penanda aras MCQA yang digunakan secara meluas dalam "Ketepatan". Pada set data menjawab soalan aneka pilihan ini, model bahasa besar sedia ada telah menunjukkan ketepatan yang sangat tinggi Contohnya, pada MedQA, GPT-4 boleh mencapai 85.8 mata, hampir setanding dengan pakar manusia, manakala Llama 3 juga boleh lulus peperiksaan dengan. markah 60.9. Begitu juga, dalam bahasa selain bahasa Inggeris, LLM juga menunjukkan keputusan cemerlang dalam ketepatan berbilang pilihan pada MMedBench.
Hasilnya menunjukkan bahawa memandangkan soalan aneka pilihan telah dipertimbangkan secara meluas dalam penyelidikan sedia ada, LLM yang berbeza mungkin telah dioptimumkan secara khusus untuk tugasan tersebut, menghasilkan prestasi yang lebih tinggi. Oleh itu, adalah perlu untuk mewujudkan penanda aras yang lebih komprehensif untuk terus mempromosikan LLM ke arah aplikasi klinikal.
Jadual 2: Keputusan kuantitatif pada soalan aneka pilihan Setiap penunjuk diukur dengan ketepatan pemilihan ACC.
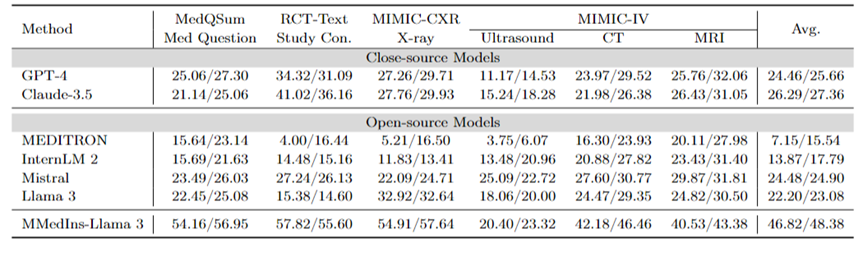
Ringkasan teks: Jadual 3 melaporkan prestasi model bahasa yang berbeza pada tugas ringkasan teks dalam bentuk skor "BLEU/ROUGE". Ujian meliputi pelbagai jenis laporan, termasuk X-ray, CT, MRI, ultrasound dan isu perubatan lain. Keputusan eksperimen menunjukkan bahawa model bahasa besar sumber tertutup seperti GPT-4 dan Claude-3.5 mengatasi semua model bahasa besar sumber terbuka.
Antara model sumber terbuka, Mistral mempunyai hasil terbaik, dengan BLEU/ROUGE masing-masing 24.48/24.90, diikuti oleh Llama 3 pada 22.20/23.08.
MMedIns-Llama 3 yang dicadangkan dalam artikel ini dilatih pada set data pengajaran perubatan khusus (MedS-Ins), dan prestasinya jauh lebih baik daripada model lain, termasuk model sumber tertutup termaju GPT-4 dan Claude- 3.5, dengan skor purata 46.82/48.38.
Jadual 3: Keputusan kuantitatif pada tugasan ringkasan teks.
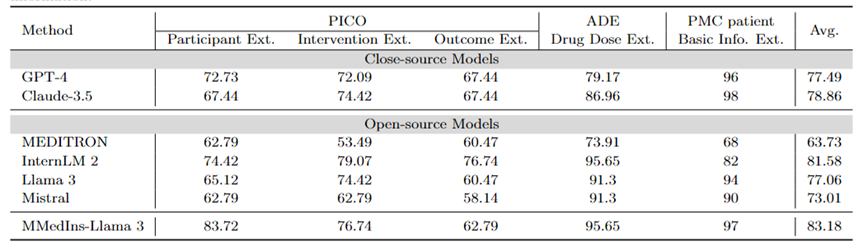
Pengeluaran maklumat: Jadual 4 menunjukkan prestasi pengekstrakan maklumat model berbeza dengan "Ketepatan". InternLM 2 berprestasi baik dalam tugasan ini dengan purata skor 81.58, dan model sumber tertutup seperti GPT-4 dan Claude-3.5 mengatasi semua model sumber terbuka lain dengan purata skor masing-masing 77.49 dan 78.86.
Analisis hasil tugasan individu menunjukkan bahawa kebanyakan model bahasa besar berprestasi lebih baik dalam mengekstrak maklumat perubatan yang kurang kompleks seperti maklumat asas pesakit berbanding dengan data perubatan khusus. Sebagai contoh, dalam mengekstrak maklumat asas daripada pesakit PMC, kebanyakan model bahasa besar mendapat markah melebihi 90 mata, dengan Claude-3.5 mencapai skor tertinggi 98.02 mata. Sebaliknya, prestasi pada tugas pengekstrakan hasil klinikal dalam PICO adalah agak lemah. Model yang dicadangkan dalam artikel ini, MMedIns-Llama 3, mempunyai prestasi keseluruhan terbaik, dengan skor purata 83.18, melebihi model InternLM 2 sebanyak 1.6 mata.
Jadual 4: Keputusan kuantitatif pada tugas pengekstrakan maklumat Setiap penunjuk diukur mengikut ketepatan (ACC). "Ext." bermaksud Pengekstrakan, dan "Maklumat."
Penjelasan konsep perubatan: Jadual 5 menunjukkan keupayaan penjelasan konsep perubatan model berbeza dalam bentuk skor "BLEU/ROUGE", GPT-4 , Llama 3 dan Mistral berprestasi baik dalam tugasan ini.
반면 Claude-3.5, InternLM 2, MEDITRON의 점수는 상대적으로 낮습니다. MEDITRON의 상대적으로 저조한 성과는 MEDITRON의 훈련 코퍼스가 학술 논문 및 가이드라인에 더 중점을 두기 때문에 의학 개념을 설명하는 능력이 부족하기 때문일 수 있습니다.
최종 모델인 MMedIns-Llama 3는 모든 개념 설명 작업에서 다른 모델보다 월등히 뛰어난 성능을 발휘했습니다.
표 5: 의학적 개념 설명에 대한 정량적 결과, 각 지표는 BLEU-1/ROUGE-1로 측정되며 "Exp."는 설명을 의미합니다.
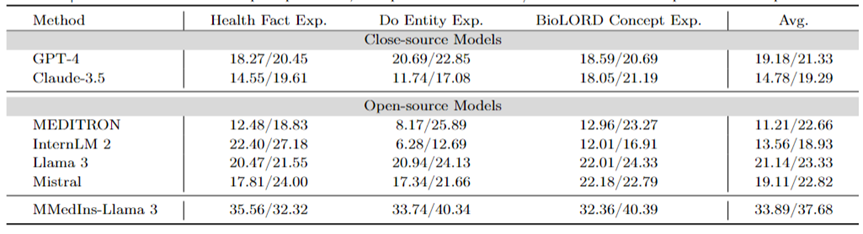
속성 분석(근거): 표 6은 "BLEU/ROUGE" 점수 형식으로 속성 분석 작업에 대한 각 모델의 성능을 평가합니다. 성능,6개 언어의 다양한 모델의 추론 능력을 MMedBench 데이터셋을 이용하여 비교하였습니다.
테스트된 모델 중 비공개 소스 모델인 Claude-3.5가 평균 점수 46.03/37.65로 가장 강력한 성능을 보여주었습니다. 이러한 뛰어난 성능은 많은 범용 LLM에서 특별히 강화된 COT 생성 작업과의 유사성 때문일 수 있습니다.
오픈소스 모델 중 Mistral과 InternLM 2는 평균 점수가 각각 37.61/31.55, 30.03/26.44로 비슷한 성능을 보였습니다. 특히 MMedBench 데이터 세트의 속성 분석 부분은 주로 GPT-4를 사용하여 빌드를 생성하므로 GPT-4가 이 평가에서 제외되었습니다. 이로 인해 테스트 편향이 발생하여 불공정한 비교가 발생할 수 있습니다.
개념 설명 과제 수행에 맞춰 최종 모델인 MMedIns-Llama 3 역시 모든 언어에서 평균 47.17/34.96점으로 종합적으로 가장 좋은 성능을 보였습니다. 이러한 탁월한 성능은 선택된 기본 언어 모델(MMed-Llama 3)이 원래 여러 언어용으로 개발되었기 때문일 수 있습니다. 따라서 명령 조정이 다국어 데이터를 명시적으로 대상으로 하지 않더라도 최종 모델은 여전히 여러 언어의 다른 모델보다 더 나은 성능을 발휘합니다.
표 6: 귀인분석에 대한 정량적 결과(근거), 각 지표는 BLEU-1/ROUGE-1로 측정됩니다. 여기에는 GPT-4 생성 결과를 바탕으로 원본 데이터가 구성되어 있고 공정성 편향이 있기 때문에 GPT-4가 없으므로 GPT-4를 비교하지 않습니다.
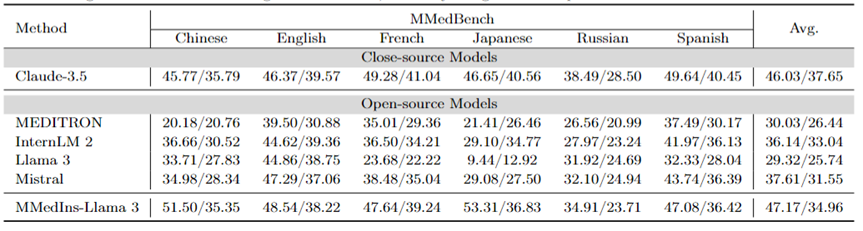
의료 개체 추출(NER): 표 7은 "F1" 점수 성능 형식으로 NER 작업에 대한 기존 6개 모델을 테스트합니다. GPT-4는 모든 명명된 개체 인식(NER) 작업에서 평균 F1 점수가 44.30으로 잘 수행되는 유일한 모델입니다.
BC5Chem 화학물질 인식 과제에서 63.77점으로 특히 좋은 성능을 보였습니다. InternLM 2는 평균 F1 점수 40.81로 바짝 뒤지고 있으며 BC5Chem 및 BC5Disease 작업 모두에서 우수한 성능을 발휘합니다. Llama 3와 Mistral은 각각 평균 F1 점수 24.70과 20.10으로 평균 성능을 나타냅니다. MEDITRON은 NER 작업에 최적화되어 있지 않으며 이 영역에서는 제대로 작동하지 않습니다. MMedIns-Llama 3는 평균 F1 점수 68.58로 다른 모든 모델보다 훨씬 뛰어난 성능을 발휘합니다.
표 7: NER 작업의 정량적 결과, 각 지표는 F1 점수로 측정됩니다. "Rec."는 "인정"을 의미합니다.
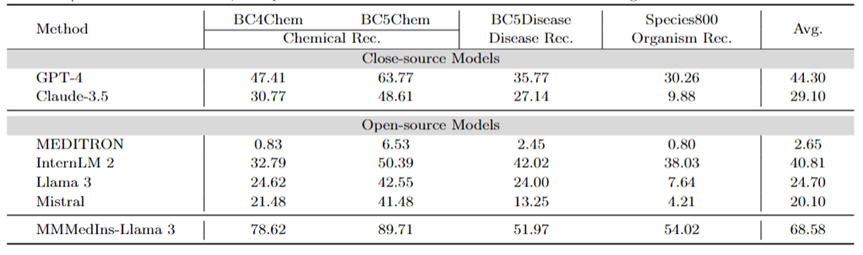
진단, 치료 권장 사항 및 임상 결과 예측: 표 8 DDXPlus 데이터 세트를 진단 벤치마크로, SEER 데이터 세트를 치료 권장 벤치마크로, MIMIC4ED 데이터를 임상 결과 예측 작업 벤치마크로 사용한 진단, 치료 권장 사항 및 임상 결과 평가 3가지 주요 작업에 대한 모델 성능을 예측하고, 결과를 정확도로 측정한 결과는 Table 8과 같다.
여기서 각 데이터세트는 원래 문제를 닫힌 집합의 선택 문제로 축소하므로 생성된 예측을 평가하는 데 정확도 측정항목을 사용할 수 있습니다. 특히 DDXPlus는 모델이 제공된 환자 배경을 기반으로 질병을 선택해야 하는 사전 정의된 질병 목록을 사용합니다. SEER에서는 치료 권장 사항이 8개의 상위 범주로 나뉘는 반면, MIMIC4ED에서는 최종 임상 결과 결정이 항상 이진법(참 또는 거짓)입니다.
전체적으로 오픈 소스 LLM은 이러한 작업에서 폐쇄 소스 LLM보다 성능이 떨어지며 어떤 경우에는 의미 있는 예측을 제공하지 못합니다. 예를 들어 Llama 3는 Critical Triage를 예측하는 데 성능이 좋지 않습니다. DDXPlus 진단 작업의 경우 InternLM 2와 Llama 3이 정확도 32로 약간 더 나은 성능을 보였습니다. 그러나 GPT-4 및 Claude-3.5와 같은 비공개 소스 모델은 훨씬 더 나은 성능을 보여줍니다. 예를 들어 Claude-3.5는 SEER에서 90의 정확도를 달성할 수 있는 반면, GPT-4는 DDXPlus에서 52점으로 더 높은 진단 정확도를 달성하여 오픈 소스와 폐쇄 소스 LLM 간의 큰 격차를 강조합니다.
이러한 결과에도 불구하고 이 점수는 아직 임상에 사용할 만큼 신뢰할 수 없습니다. 이에 비해 MMedIns-Llama 3는 SEER 98점, DDXPlus 95점 등 임상 의사결정 지원 업무에서 우수한 정확도를 보였으며, 임상 결과 예측 작업(입원, ED 재방문 평균 72시간, Critical Triage 점수)에서는 평균 정확도 86.67점을 보였습니다. ).
텍스트 분류: 표 8에는 HoC 다중 레이블 분류 작업에 대한 평가도 나와 있으며 Macro-precision, Macro-recall 및 Macro-F1 Scores가 보고됩니다. 이러한 유형의 작업에서는 모든 후보 레이블이 목록 형식으로 언어 모델에 입력되고 모델은 다중 선택이 허용되는 해당 답변을 선택하도록 요청됩니다. 그런 다음 모델의 최종 선택 결과를 기반으로 정확도 측정항목이 계산됩니다.
GPT-4와 Claude-3.5는 이 작업에서 좋은 성능을 발휘하며 GPT-4의 Macro-F1 점수는 60.38이고 Claude-3.5는 63.32를 달성하여 더욱 우수합니다. 두 모델 모두 강력한 리콜 기능을 보여주며, 특히 Macro-Recall이 80.96인 Claude-3.5를 보여줍니다. Mistral은 Macro-F1 점수 40.8로 정밀도와 재현율의 균형을 유지하며 적당히 좋은 성능을 보였습니다.
반면 Llama 3과 InternLM 2의 전반적인 성능은 Macro-F1 점수가 각각 36.18과 32.72로 좋지 않습니다. 이러한 모델(특히 InternLM 2)은 재현율은 높지만 정밀도가 낮아 Macro-F1 점수가 낮습니다.
MEDITRON은 Macro-F1 점수 26.21점으로 이 작업에서 가장 낮은 순위를 기록했습니다. MMedIns-Llama 3는 매크로 정밀도 91.29, 매크로 재현율 85.57, Macro-F1 점수 87.37로 모든 지표에서 가장 높은 점수를 달성하여 다른 모든 모델보다 훨씬 뛰어난 성능을 발휘합니다. 이러한 결과는 MMedIns-Llama 3가 텍스트를 정확하게 분류하는 능력을 강조하여 이러한 유형의 복잡한 작업에 가장 효과적인 모델임을 보여줍니다.
표 8: 치료 계획(SEER), 진단(DDXPlus), 임상 결과 예측(MIMIC4ED) 및 텍스트 분류(HoC Classification)의 네 가지 작업 범주에 대한 결과입니다. 처음 세 가지 작업의 결과는 정확도를 기반으로 하며 텍스트 분류 결과는 정밀도, 재현율 및 F1 점수를 기반으로 합니다.
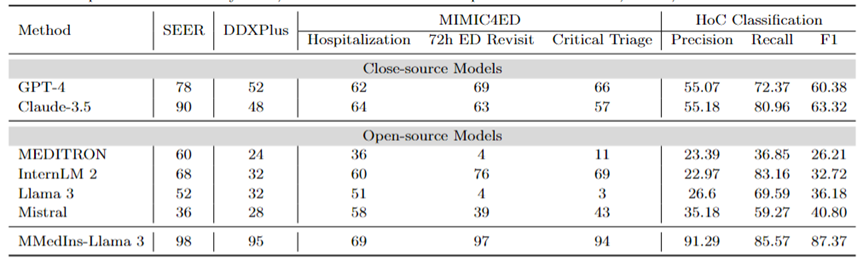
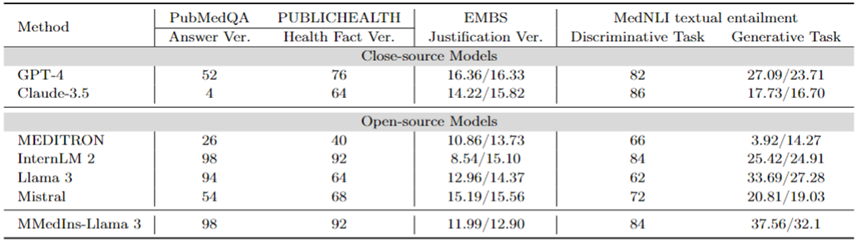
사실 수정: 표 9는 사실 검증 작업에 대한 모델 평가 결과를 보여준다. PubMedQA 답변 검증 및 HealthFact 검증의 경우 LLM은 제공된 후보 목록에서 답변을 선택해야 하므로 정확도가 평가 지표로 사용됩니다.
반대로 EBMS 타당성 검증으로 인해 작업에는 BLEU-1 및 ROUGE-1 점수를 사용하여 성능을 평가하는 자유 형식 텍스트를 생성하는 작업이 포함됩니다. InternLM 2는 PubMedQA 답변 검증과 HealthFact 검증에서 각각 98점과 92점으로 가장 높은 정확도를 달성했습니다.
EBMS 벤치마크에서는 GPT-4가 BLEU-1/ROGE-1 점수 각각 16.36/16.33으로 가장 강력한 성능을 보여줍니다. Claude-3.5는 14.22/15.82의 점수로 근소한 차이로 2위지만 PubMedQA 답변 검증에서는 성능이 좋지 않습니다.
Llama 3의 정확도는 PubMedQA와 HealthFact Verification에서 각각 94와 64이며, BLEU-1/ROUGE-1 점수는 12.96/14.37입니다. MMedIns-Llama 3는 계속해서 기존 모델을 능가하여 InternLM 2와 함께 PubMedQA 답변 검증 작업에서 가장 높은 정확도 점수를 달성했으며, EMBS에서는 MMedIns-Llama 3이 BLEU-1 및 ROUGE-1에서 11.99/12.90을 달성했습니다. GPT-4보다 약간 뒤쳐져 있습니다.
의료문자 함축(NLI): 표 9에도 NLI(Medical Text Implication), 주로 MedNLI에 대한 평가 결과가 나와 있다. 두 가지 테스트 방법이 있습니다. 하나는 정확도로 측정되는 판별 작업(후보 목록에서 정답 선택)이고, 다른 하나는 BLEU/ROUGE 측정항목으로 측정되는 생성 작업(자유 형식 텍스트 답변 생성)입니다.
InternLM 2는 84점으로 오픈소스 LLM 중 가장 높은 점수를 받았습니다. 비공개 소스 LLM의 경우 GPT-4와 Claude-3.5 모두 각각 82와 86의 정확도로 상대적으로 높은 점수를 나타냅니다. 생성 작업에서 Llama 3은 BLEU 및 ROUGE 점수가 33.69/27.28로 Ground Truth와의 일관성이 가장 높습니다. Mistral과 Llama 3의 성능은 평균 수준이었습니다. GPT-4는 27.09/23.71의 점수로 바짝 뒤쫓고 있는 반면 Claude-3.5는 생성 작업에서 좋은 성능을 발휘하지 못합니다.
MMedIns-Llama 3은 판별 작업에서 84점으로 가장 높은 정확도를 보였지만 Claude-3.5보다 약간 뒤처졌습니다. MMedIns-Llama 3는 생성 작업에서도 BLEU/ROUGE 점수가 37.56/32.17로 다른 모델보다 훨씬 우수한 성능을 보였습니다.
표 9: 사실 검증 및 텍스트 암시 작업에 대한 정량적 결과는 정확도(ACC)로 측정되었으며 표의 "Ver."는 "verification"의 약어입니다.
일반적으로 연구팀은 다양한 업무 차원에서 6가지 주류 모델을 평가했습니다. 연구 결과에 따르면 현재의 주류 LLM은 임상 업무를 처리할 때 여전히 상당히 취약한 것으로 나타났습니다. 다양하고 복잡한 임상 시나리오에서 심각한 성능 결함이 발생합니다.
동시에 LLM과 실제 임상 적용 간의 일치성을 강화하기 위해 지침 데이터 세트에 더 많은 임상 작업 텍스트를 추가하면 LLM의 성능이 크게 향상될 수 있다는 실험 결과도 나타났습니다.
데이터 수집 방법 및 학습 과정
이 섹션에서는 그림 3b와 같이 훈련 과정을 자세히 소개합니다. 구체적인 방법은 이전 작업인 MMedLM 및 PMC-LLaMA와 동일하며, 둘 다 의료 관련 말뭉치에 대한 추가 자동 회귀 훈련을 통해 해당 의학 지식을 모델에 주입할 수 있으므로 다양한 다운스트림 작업에서 더 나은 성능을 발휘할 수 있습니다.
구체적으로 연구팀은 다국어 LLM 기본 모델(MMed-Llama 3)로 시작하여 MedS-Ins의 지시 미세 조정 데이터를 사용하여 추가로 훈련했습니다.
명령 미세 조정을 위한 데이터는 주로 두 가지 측면을 포함합니다.
의학적으로 필터링된 자연 명령 데이터: 첫째, 세계에서 가장 큰 명령 데이터 세트인 Super-Natural Instructions에서 자연 분야 의료 관련 작업을 필터링합니다. Super-NaturalInstructions는 일반 분야의 다양한 자연어 처리 작업에 더 중점을 두기 때문에 의료 분야의 분류 세분성은 상대적으로 거칠습니다.
먼저 '의료' 및 '의학' 카테고리의 모든 지침을 추출한 후 작업 카테고리는 변경하지 않은 채 더 자세한 도메인 라벨을 수동으로 추가했습니다. 또한 많은 일반 도메인으로 구성된 지침 미세 조정 데이터 세트에는 LIMA 및 ShareGPT와 같은 일부 의료 관련 데이터도 포함됩니다.
이러한 데이터 중 의학적 부분을 필터링하기 위해 연구팀은 InsTag를 사용하여 각 명령의 도메인에 대한 대략적인 분류를 수행했습니다. 특히 InsTag는 다양한 명령 샘플에 태그를 지정하도록 설계된 LLM입니다. 명령어 쿼리가 주어지면 해당 명령어가 어떤 도메인과 작업에 속하는지 분석하고 이를 기반으로 의료, 의료 또는 생물 의학으로 라벨이 지정된 샘플을 필터링합니다.
마지막으로 일반 도메인에 설정된 명령어 데이터를 필터링하여 총 75373개의 샘플로 37개의 태스크가 수집되었습니다.
기존 BioNLP 데이터 세트 구성 팁: 기존 데이터 세트 중에는 임상 시나리오의 텍스트 분석에 탁월한 데이터 세트가 많이 있습니다. 그러나 대부분의 데이터 세트는 다양한 목적으로 수집되므로 대규모 언어 모델을 교육하는 데 직접 사용할 수 없습니다. 그러나 이러한 기존 의료 NLP 작업은 생성 모델을 훈련하는 데 사용할 수 있는 형식으로 변환하여 명령 적응에 통합될 수 있습니다.
구체적으로 연구팀은 MIMIC-IV-Note를 예로 들었다. MIMIC-IV-Note는 결과와 결론이 모두 포함된 고품질의 구조화된 보고서를 제공하며 결론에 대한 결과 생성은 고전적인 임상 텍스트 요약 작업으로 간주됩니다. 먼저 작업을 정의하기 위한 프롬프트를 수동으로 작성합니다(예: "초음파 영상 진단의 자세한 결과를 바탕으로 결과를 몇 단어로 요약합니다.") 교수 조정의 다양성 요구를 고려하여 연구팀은 5명에게 3가지 다른 방법을 독립적으로 사용하도록 요청했습니다. 특정 작업을 설명하라는 메시지가 표시됩니다.
이로 인해 작업당 15개의 무료 텍스트 프롬프트가 생성되어 유사한 의미를 보장하면서도 가능한 다양한 표현과 형식을 보장했습니다. 그런 다음 Self-Instruct에서 영감을 받아 이러한 수동으로 작성된 지침은 시드 지침으로 사용되며 GPT-4는 보다 다양한 지침을 얻기 위해 이에 따라 다시 작성하도록 요청됩니다.
위 과정을 통해 추가로 85개의 과제가 통일된 자유질문과 답변 형식으로 출제되었고, 필터링된 데이터와 결합하여 총 122개 과제를 포괄하는 1,350만 개의 고품질 샘플을 얻었습니다. MedS-Ins 및 지침 미세 조정을 통해 새로운 8B 크기의 의료 LLM을 교육했으며, 그 결과 이 방법이 임상 작업 성능을 크게 향상시키는 것으로 나타났습니다.
명령 미세 조정에서 연구팀은 두 가지 명령 형식에 중점을 두었습니다.
제로 샘플 프롬프트: 여기서 작업 명령에는 몇 가지 의미론적 작업 설명이 포함되어 있습니다. 프롬프트로 표시되므로 모델은 내부 모델 지식을 기반으로 질문에 직접 대답해야 합니다. 수집된 MedS-Ins에서는 각 작업의 "정의" 내용을 자연스럽게 영점 지시 입력으로 사용할 수 있습니다. 다양한 의료 업무 정의가 다루어짐에 따라 모델은 다양한 업무 설명에 대한 의미론적 이해를 학습할 것으로 예상됩니다.
몇 가지 팁: 여기 지침에는 모델이 상황에서 작업의 대략적인 요구 사항을 학습할 수 있는 소수의 예가 포함되어 있습니다. 이러한 지침은 동일한 작업에 대한 훈련 세트에서 다른 사례를 무작위로 샘플링하고 다음과 같은 간단한 템플릿을 사용하여 구성하여 얻을 수 있습니다.
Case1: 입력: {CASE1_INPUT}, 출력: {CASE1_OUTPUT} ... CaseN: 입력: {CASEN_INPUT}, 출력: {CASEN_OUTPUT} {INSTRUCTION} 어떤 콘텐츠를 출력해야 하는지 확인하세요. 입력: {INPUT}
토론
전체적으로 이 문서는 몇 가지 중요한 기여를 합니다.
종합 평가 벤치마크--MedS-Bench
의료 LLM 개발은 MCQA(객관식 질문 답변) 벤치마크 테스트에 크게 의존합니다. 그러나 이러한 좁은 평가 프레임워크는 다양하고 복잡한 임상 시나리오에서 LLM의 진정한 기능을 무시합니다.
따라서 이번 연구에서 연구팀은 모델 사전 훈련된 코퍼스에서 사실을 회상하거나 주어진 상황에서 추론하는 작업입니다.
연구 결과에 따르면 기존 LLM은 MCQA 벤치마크에서는 좋은 성과를 거두지만, 특히 치료 추천 및 설명과 같은 작업에서는 임상 실무에 부합하는 데 어려움을 겪고 있는 것으로 나타났습니다. 이 발견은 더 넓은 범위의 임상 및 의료 시나리오에 적합한 의료용 대형 언어 모델의 추가 개발 필요성을 강조합니다.
종합 지시 조정 데이터 세트--MedS-Ins
연구팀은 기존 BioNLP 데이터 세트에서 광범위하게 데이터를 획득하고 이러한 샘플을 통일된 형식으로 변환하여 동시에 새로운 의료 주문 조정 데이터 세트인 MedS-Ins를 구축하고 개발하기 위해 반자동 프롬프트 전략이 사용되었습니다. 교육 미세 조정 데이터 세트에 대한 이전 작업은 주로 일상 대화, 시험 또는 학술 논문에서 질문-답변 쌍을 구성하는 데 중점을 두었으며 종종 실제 임상 실습에서 생성된 텍스트를 무시했습니다.
반면, MedS-Ins는 5개의 주요 텍스트 영역과 19개의 작업 범주를 포함하여 더 광범위한 의료 텍스트 리소스를 통합합니다. 데이터 구성에 대한 이러한 체계적인 분석은 사용자가 LLM의 임상 적용 범위를 이해하는 데 도움이 됩니다.
의료용 대형 언어 모델--MMedIns-Llama 3
모델 측면에서 연구팀은 MedS-Ins에 대한 지시 미세 조정 훈련을 수행하여 이를 입증했습니다. , 이는 오픈 소스 의료 LLM과 임상 요구 사항의 정렬을 크게 향상시킬 수 있습니다.
최종 모델 MMedIns-Llama 3은 8B의 중간 매개변수 척도를 사용하는 "개념 증명" 모델에 가깝다는 점을 강조할 필요가 있습니다. , 추가 작업별 교육 없이도 지침 프롬프트가 전혀 없거나 적은 수를 통해 다양한 의료 시나리오에 유연하게 적응할 수 있습니다.
결과에 따르면 MMedIns-Llama 3는 특정 임상 작업 유형에서 GPT-4, Claude-3.5 등을 포함한 기존 LLM보다 성능이 뛰어난 것으로 나타났습니다.
기존 한계
여기서 연구팀은 이 기사의 한계와 향후 개선 가능성도 강조하고 싶습니다.
우선, 현재 MedS-Bench는 11개의 임상 작업만 다루고 있어 모든 임상 시나리오의 복잡성을 완전히 다루지는 않습니다. 또한 6개의 주류 LLM이 평가되었지만 최신 LLM 중 일부는 여전히 분석에서 누락되었습니다. 이러한 한계를 해결하기 위해 연구팀은 이 기사가 출판되는 것과 동시에 의학 LLM 리더보드를 출시할 계획이며, 더 많은 연구자들이 의학 LLM의 종합 평가 벤치마크를 지속적으로 확장하고 개선하도록 장려하는 것을 목표로 하고 있습니다. 평가 과정에 다양한 텍스트 소스의 더 많은 작업 범주를 포함함으로써 의학에서 LLM 사용의 개발 및 경계에 대한 더 깊은 이해를 얻을 수 있기를 바랍니다.
둘째, MedS-Ins는 현재 광범위한 의료 업무를 다루고 있지만 아직 불완전하고 실용적인 의료 시나리오가 부족합니다. 이 문제를 해결하기 위해 연구팀은 수집된 모든 데이터와 리소스를 GitHub에 오픈소스화했습니다. 일반 분야의 Super-NaturalInstructions처럼 더 많은 임상의나 연구자들이 함께 협력하여 이 지침 조정 데이터 세트를 유지하고 확장할 수 있기를 진심으로 바랍니다. 연구팀은 GitHub 페이지에 자세한 업로드 지침을 제공했으며, 논문의 반복 업데이트에서 데이터 세트 업데이트에 참여한 모든 기여자에게 서면으로 감사 인사를 전할 것입니다.
셋째, 연구팀은 더욱 강력한 다국어 의료 LLM 개발을 지원하기 위해 MedS-Bench와 MedS-Ins에 더 많은 언어를 추가할 계획입니다. 현재 이러한 리소스는 주로 영어 중심이지만 일부 다국어 작업은 MedS-Bench 및 MedS-Ins에 포함되어 있습니다. 이를 더 넓은 범위의 언어로 확장하는 것은 최근 의료 AI의 발전이 더 넓고 더 다양한 지역에 공평하게 혜택을 줄 수 있도록 하기 위한 유망한 미래 방향이 될 것입니다.
드디어 연구팀은 모든 코드, 데이터, 평가 과정을 오픈 소스로 만들었습니다. 이 작업이 의료 LLM의 개발을 이끌어 이러한 강력한 언어 모델을 실제 임상 응용 프로그램과 통합하는 방법에 더 집중할 수 있기를 바랍니다.
Atas ialah kandungan terperinci Ke arah model perubatan 'semuanya', pasukan Shanghai Jiao Tong University mengeluarkan data penalaan halus arahan berskala besar, model sumber terbuka dan ujian penanda aras yang komprehensif. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah perpustakaan pihak ketiga yang biasa digunakan dalam PHP?
Apakah perpustakaan pihak ketiga yang biasa digunakan dalam PHP?
 kekunci pintasan gantian wps
kekunci pintasan gantian wps
 laman web rasmi aplikasi platform dagangan okex
laman web rasmi aplikasi platform dagangan okex
 Apakah akhiran video?
Apakah akhiran video?
 10 pertukaran mata wang teratas
10 pertukaran mata wang teratas
 ORACLEDISTINCT
ORACLEDISTINCT
 Perbezaan antara versi rumah win10 dan versi profesional
Perbezaan antara versi rumah win10 dan versi profesional
 Bagaimana untuk mengeksport Apipost di luar talian
Bagaimana untuk mengeksport Apipost di luar talian





















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



