


Dalam blog sebelum ini, kami melihat cara memasang dan menyediakan neo4j secara setempat dengan 2 pemalam APOC dan Perpustakaan Sains Data Graf - GDS. Dalam blog ini saya akan mengambil set data mainan(produk dalam tapak web e-dagang) dan menyimpannya dalam Neo4j.
Sebelum mula memuatkan data jika dalam kes penggunaan anda, anda mempunyai data yang besar pastikan jumlah memori yang mencukupi diperuntukkan kepada neo4j. Untuk melakukannya:



Graf mempunyai dua komponen utama nod dan perhubungan, mari kita buat nod dahulu dan kemudian wujudkan perhubungan.
Data yang saya gunakan ada di sini - data
Gunakan requirements.txt yang ada di sini untuk mencipta persekitaran maya python - requirements.txt
Mari kita tentukan pelbagai fungsi untuk menolak data.
Mengimport perpustakaan yang diperlukan
import pandas as pd from neo4j import GraphDatabase from openai import OpenAI
client = OpenAI(api_key="") product_data_df = pd.read_csv('../data/product_data.csv')
def get_embedding(text): """ Used to generate embeddings using OpenAI embeddings model :param text: str - text that needs to be converted to embeddings :return: embedding """ model = "text-embedding-3-small" text = text.replace("\n", " ") return client.embeddings.create(input=[text], model=model).data[0].embedding
def create_category(product_data_df): """ Used to generate queries for creating category nodes in neo4j :param product_data_df: pandas dataframe - data :return: query_list: list - list containing all create node queries for category """ cat_query = """CREATE (a:Category {name: '%s', embedding: %s})""" distinct_category = product_data_df['Category'].unique() query_list = [] for category in distinct_category: embedding = get_embedding(category) query_list.append(cat_query % (category, embedding)) return query_list
def create_product(product_data_df): """ Used to generate queries for creating product nodes in neo4j :param product_data_df: pandas dataframe - data :return: query_list: list - list containing all create node queries for product """ product_query = """CREATE (a:Product {name: '%s', description: '%s', price: %d, warranty_period: %d, available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})""" query_list = [] for idx, row in product_data_df.iterrows(): embedding = get_embedding(row['Product Name'] + " - " + row['Description']) query_list.append(product_query % (row['Product Name'], row['Description'], int(row['Price (INR)']), int(row['Warranty Period (Years)']), int(row['Stock']), float(row['Review Rating']), str(row['Product Release Date']), embedding)) return query_list
def execute_bulk_query(query_list): """ Executes queries is a list one by one :param query_list: list - list of cypher queries :return: None """ url = "bolt://localhost:7687" auth = ("neo4j", "neo4j@123") with GraphDatabase.driver(url, auth=auth) as driver: with driver.session() as session: for query in query_list: try: session.run(query) except Exception as error: print(f"Error in executing query - {query}, Error - {error}")
import pandas as pd from neo4j import GraphDatabase from openai import OpenAI client = OpenAI(api_key="") product_data_df = pd.read_csv('../data/product_data.csv') def preprocessing(df, columns_to_replace): """ Used to preprocess certain column in dataframe :param df: pandas dataframe - data :param columns_to_replace: list - column name list :return: df: pandas dataframe - processed data """ df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s")) df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", "")) return df def get_embedding(text): """ Used to generate embeddings using OpenAI embeddings model :param text: str - text that needs to be converted to embeddings :return: embedding """ model = "text-embedding-3-small" text = text.replace("\n", " ") return client.embeddings.create(input=[text], model=model).data[0].embedding def create_category(product_data_df): """ Used to generate queries for creating category nodes in neo4j :param product_data_df: pandas dataframe - data :return: query_list: list - list containing all create node queries for category """ cat_query = """CREATE (a:Category {name: '%s', embedding: %s})""" distinct_category = product_data_df['Category'].unique() query_list = [] for category in distinct_category: embedding = get_embedding(category) query_list.append(cat_query % (category, embedding)) return query_list def create_product(product_data_df): """ Used to generate queries for creating product nodes in neo4j :param product_data_df: pandas dataframe - data :return: query_list: list - list containing all create node queries for product """ product_query = """CREATE (a:Product {name: '%s', description: '%s', price: %d, warranty_period: %d, available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})""" query_list = [] for idx, row in product_data_df.iterrows(): embedding = get_embedding(row['Product Name'] + " - " + row['Description']) query_list.append(product_query % (row['Product Name'], row['Description'], int(row['Price (INR)']), int(row['Warranty Period (Years)']), int(row['Stock']), float(row['Review Rating']), str(row['Product Release Date']), embedding)) return query_list def execute_bulk_query(query_list): """ Executes queries is a list one by one :param query_list: list - list of cypher queries :return: None """ url = "bolt://localhost:7687" auth = ("neo4j", "neo4j@123") with GraphDatabase.driver(url, auth=auth) as driver: with driver.session() as session: for query in query_list: try: session.run(query) except Exception as error: print(f"Error in executing query - {query}, Error - {error}") # PREPROCESSING product_data_df = preprocessing(product_data_df, ['Product Name', 'Description']) # CREATE CATEGORY query_list = create_category(product_data_df) execute_bulk_query(query_list) # CREATE PRODUCT query_list = create_product(product_data_df) execute_bulk_query(query_list)
Mewujudkan Perhubungan
from neo4j import GraphDatabase import pandas as pd product_data_df = pd.read_csv('../data/product_data.csv') def preprocessing(df, columns_to_replace): """ Used to preprocess certain column in dataframe :param df: pandas dataframe - data :param columns_to_replace: list - column name list :return: df: pandas dataframe - processed data """ df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s")) df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", "")) return df def create_category_food_relationship_query(product_data_df): """ Used to create relationship between category and products :param product_data_df: dataframe - data :return: query_list: list - cypher queries """ query = """MATCH (c:Category {name: '%s'}), (p:Product {name: '%s'}) CREATE (c)-[:CATEGORY_CONTAINS_PRODUCT]->(p)""" query_list = [] for idx, row in product_data_df.iterrows(): query_list.append(query % (row['Category'], row['Product Name'])) return query_list def execute_bulk_query(query_list): """ Executes queries is a list one by one :param query_list: list - list of cypher queries :return: None """ url = "bolt://localhost:7687" auth = ("neo4j", "neo4j@123") with GraphDatabase.driver(url, auth=auth) as driver: with driver.session() as session: for query in query_list: try: session.run(query) except Exception as error: print(f"Error in executing query - {query}, Error - {error}") # PREPROCESSING product_data_df = preprocessing(product_data_df, ['Product Name', 'Description']) # CATEGORY - FOOD RELATIONSHIP query_list = create_category_food_relationship_query(product_data_df) execute_bulk_query(query_list)
Memvisualisasikan Nod Yang Dicipta
dan klik padaneo4j browseruntuk memvisualisasikan nod yang telah kami buat.
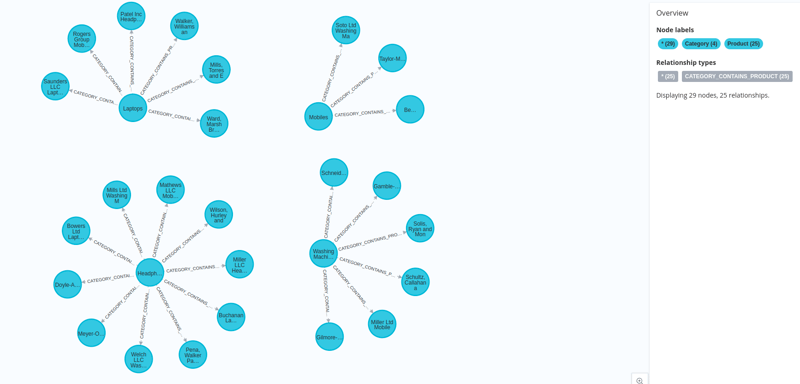 Dan data kami dimuatkan ke dalam neo4j bersama-sama dengan benamnya.
Dan data kami dimuatkan ke dalam neo4j bersama-sama dengan benamnya.
Semoga ini membantu... Jumpa anda !!!
LinkedIn - https://www.linkedin.com/in/praveenr2998/
Github - https://github.com/praveenr2998/Creating-Lightweight-RAG-Systems-With-Graphs/tree/main/push_data_to_dbAtas ialah kandungan terperinci Muatkan Data Ke dalam Neo4j. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 busyboxv1.30.1 tidak boleh boot
busyboxv1.30.1 tidak boleh boot Bagaimana untuk menyelesaikan masalah pemindahan nama domain pelayan perlahan
Bagaimana untuk menyelesaikan masalah pemindahan nama domain pelayan perlahan Kad grafik gred peminat
Kad grafik gred peminat Apakah yang dimaksudkan dengan menulis dalam python?
Apakah yang dimaksudkan dengan menulis dalam python? Mengapa Amazon tidak boleh dibuka
Mengapa Amazon tidak boleh dibuka ralat permulaan mom.exe
ralat permulaan mom.exe Apakah fungsi tetingkap?
Apakah fungsi tetingkap? Apakah maksud port pautan atas?
Apakah maksud port pautan atas?




















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



