


Dalam beberapa tahun kebelakangan ini, seni bina Transformer telah mencapai kejayaan besar, dan ia juga telah melahirkan sejumlah besar varian, seperti Vision Transformer (ViT), yang pandai memproses tugas visual. Body Transformer (BoT) yang diperkenalkan dalam artikel ini adalah varian Transformer yang sangat sesuai untuk pembelajaran strategi robot.
Kita tahu bahawa apabila agen fizikal melakukan pembetulan dan penstabilan tindakan, ia sering memberikan tindak balas spatial berdasarkan lokasi rangsangan luar yang dirasai. Sebagai contoh, litar tindak balas manusia terhadap rangsangan ini terletak pada tahap litar saraf tunjang, dan mereka bertanggungjawab secara khusus untuk tindak balas penggerak tunggal. Pelaksanaan tempatan pembetulan adalah faktor utama dalam pergerakan yang cekap, yang juga penting terutamanya untuk robot.
Tetapi seni bina pembelajaran terdahulu biasanya tidak mewujudkan korelasi spatial antara penderia dan penggerak. Memandangkan strategi robotik menggunakan seni bina yang sebahagian besarnya dibangunkan untuk bahasa semula jadi dan penglihatan komputer, mereka sering gagal mengeksploitasi struktur badan robot dengan berkesan.
Walau bagaimanapun, Transformer masih mempunyai potensi besar dalam hal ini Kajian telah menunjukkan bahawa Transformer boleh mengendalikan kebergantungan jujukan yang panjang dan boleh menyerap sejumlah besar data dengan berkesan. Seni bina Transformer pada asalnya dibangunkan untuk tugas pemprosesan bahasa semula jadi (NLP) tidak berstruktur. Dalam tugasan ini (seperti terjemahan bahasa), jujukan input biasanya dipetakan kepada jujukan output.
Berdasarkan pemerhatian ini, pasukan yang diketuai oleh Profesor Pieter Abbeel dari University of California, Berkeley mencadangkan Body Transformer (BoT), yang menambah perhatian kepada lokasi spatial penderia dan penggerak pada badan robot. . .cc/bot_site

Body Transformer
Dalam amalan, mereka menetapkan kuantiti global kepada elemen akar badan robot dan kuantiti tempatan kepada nod yang mewakili anggota badan yang sepadan. Peruntukan ini serupa dengan kaedah GNN sebelumnya.
Kemudian, gunakan lapisan linear untuk menayangkan vektor keadaan setempat ke dalam vektor benam. Keadaan setiap nod dimasukkan ke dalam unjuran linear boleh dipelajari khusus nodnya, menghasilkan jujukan n benam, dengan n mewakili bilangan nod (atau panjang jujukan). Ini berbeza daripada karya sebelumnya, yang biasanya hanya menggunakan satu unjuran linear boleh dipelajari yang dikongsi untuk mengendalikan bilangan nod yang berbeza dalam pembelajaran pengukuhan berbilang tugas.BoT Encoder
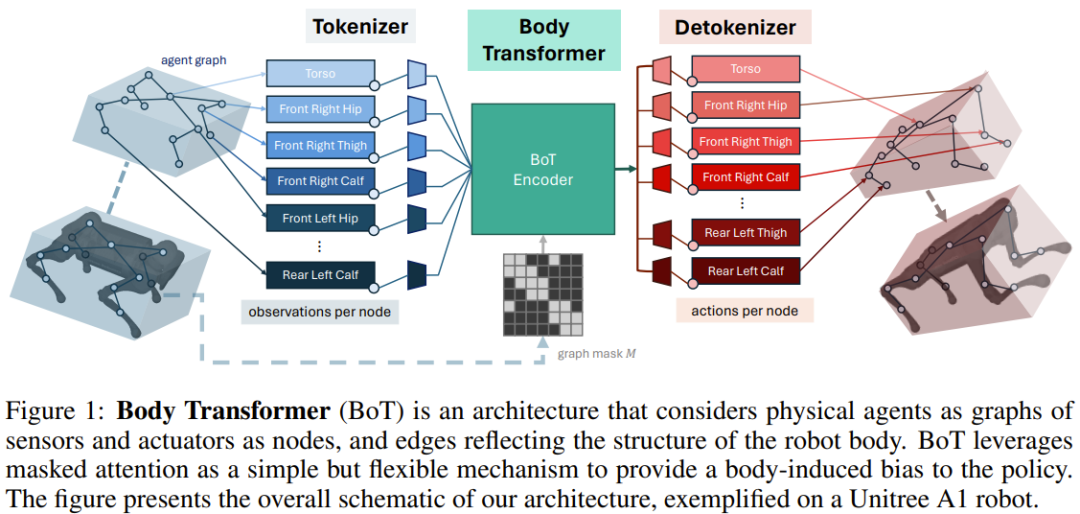 Rangkaian tulang belakang yang digunakan oleh pasukan ialah pengekod Transformer berbilang lapisan standard, dan terdapat dua varian seni bina ini:
Rangkaian tulang belakang yang digunakan oleh pasukan ialah pengekod Transformer berbilang lapisan standard, dan terdapat dua varian seni bina ini:
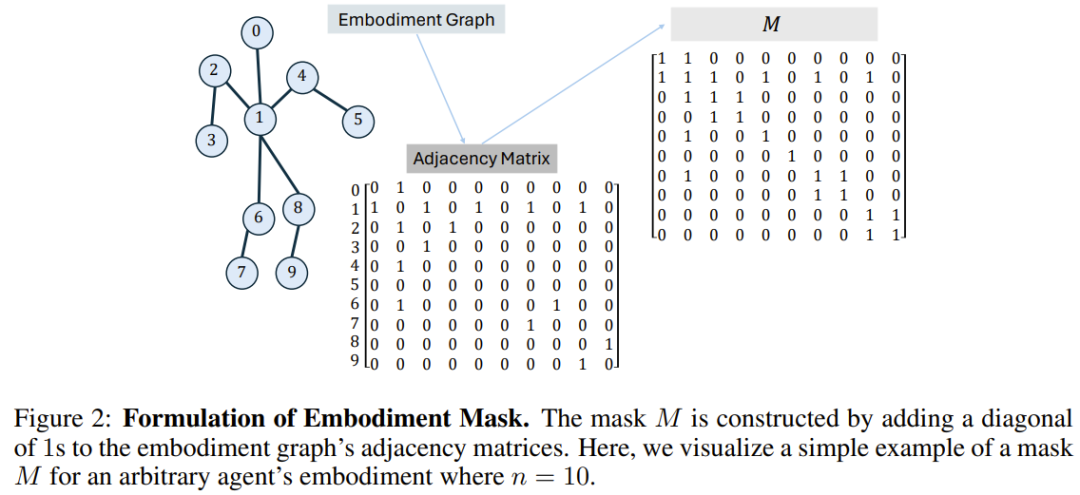
BoT-Hard: Topeng setiap lapisan menggunakan topeng binari yang mencerminkan struktur graf. Secara khusus, cara mereka membina topeng ialah M = I_n + A, di mana I_n ialah matriks identiti dimensi-n dan A ialah matriks bersebelahan yang sepadan dengan graf. Rajah 2 menunjukkan contoh. Ini membolehkan setiap nod hanya melihat dirinya dan jiran terdekatnya, dan boleh memperkenalkan masalah yang jarang berlaku - yang sangat menarik dari perspektif kos pengiraan.
BoT-Mix: menjalin lapisan dengan perhatian bertopeng (seperti BoT-Hard) dengan lapisan dengan perhatian yang tidak bertopeng.
detokenizer
Transformer Ciri-ciri keluaran oleh pengekod disalurkan ke lapisan linear dan kemudian diunjurkan ke dalam tindakan yang dikaitkan dengan anggota nod, tindakan ini ditetapkan berdasarkan kedekatan penggerak yang sepadan dengan anggota . Sekali lagi, lapisan unjuran linear yang boleh dipelajari ini adalah berasingan untuk setiap nod. Jika BoT digunakan sebagai seni bina kritikal dalam tetapan pembelajaran pengukuhan, penyahtoknis mengeluarkan bukan tindakan tetapi nilai, yang kemudiannya dipuratakan ke atas bahagian badan.
Eksperimen
Pasukan menilai prestasi BoT dalam pembelajaran tiruan dan tetapan pembelajaran pengukuhan. Mereka mengekalkan struktur yang sama seperti Rajah 1, hanya menggantikan pengekod BoT dengan pelbagai seni bina garis dasar untuk menentukan keberkesanan pengekod.
Matlamat eksperimen ini adalah untuk menjawab soalan berikut:
Bolehkah perhatian bertopeng meningkatkan prestasi dan keupayaan generalisasi pembelajaran tiruan?
Berbanding dengan seni bina Transformer asal, bolehkah BoT menunjukkan trend penskalaan yang positif?
Adakah BoT serasi dengan rangka kerja pembelajaran pengukuhan, dan apakah beberapa pilihan reka bentuk yang munasabah untuk memaksimumkan prestasi?
Bolehkah strategi BoT digunakan untuk tugas robotik dunia sebenar?
Apakah kelebihan pengiraan perhatian bertopeng?
Eksperimen Pembelajaran Tiruan
Pasukan menilai prestasi pembelajaran tiruan seni bina BoT pada tugas pengesanan badan, yang ditakrifkan melalui set data MoCapAct.
Hasilnya ditunjukkan dalam Rajah 3a, dan dapat dilihat bahawa BoT sentiasa berprestasi lebih baik daripada garis dasar MLP dan Transformer. Perlu diingat bahawa kelebihan BoT berbanding seni bina ini akan terus meningkat pada klip video pengesahan yang tidak kelihatan, yang membuktikan bahawa berat sebelah induktif sedar badan boleh membawa kepada keupayaan generalisasi yang lebih baik.
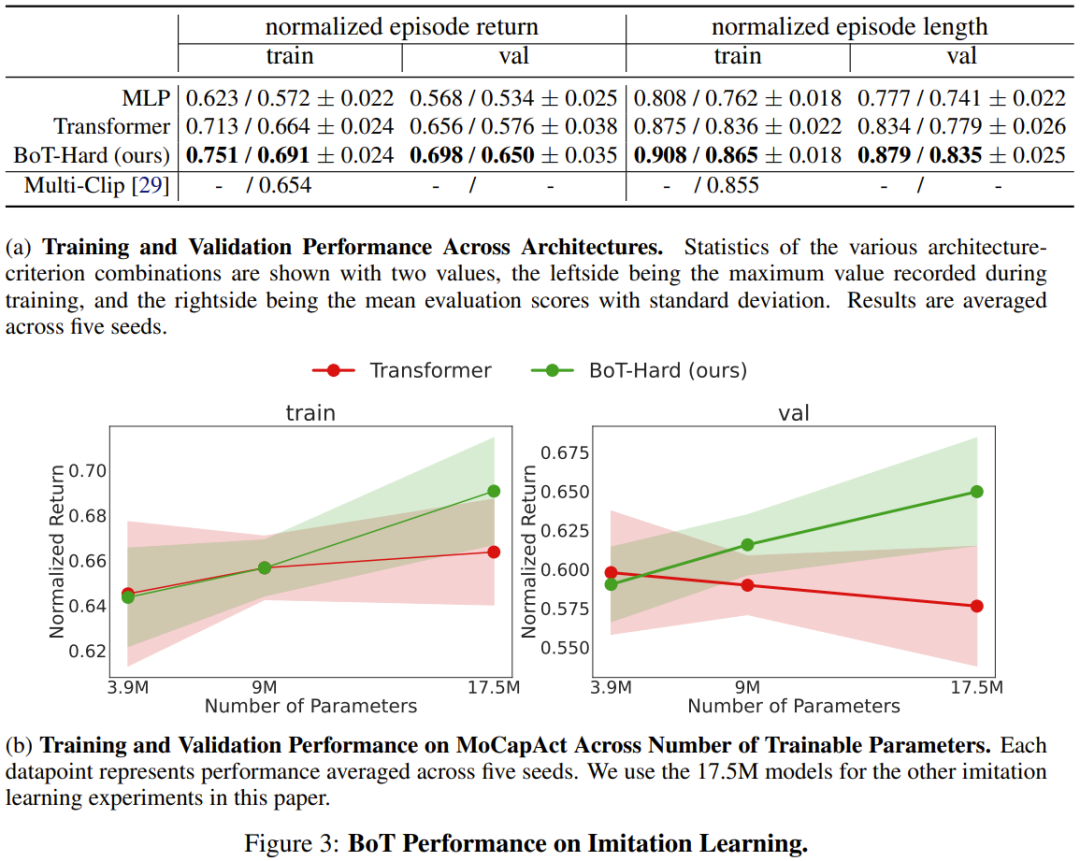
Dan Rajah 3b menunjukkan bahawa BoT-Hard mempunyai kebolehskalaan yang baik Berbanding dengan garis dasar Transformer, prestasinya pada klip video latihan dan pengesahan akan meningkat apabila bilangan parameter boleh dilatih meningkat, yang seterusnya menunjukkan bahawa BoT-Hard cenderung untuk. overfit data latihan, dan overfitting ini disebabkan oleh bias penjelmaan. Lebih banyak contoh eksperimen ditunjukkan di bawah, lihat kertas asal untuk butiran.


Eksperimen Pembelajaran Pengukuhan
Pasukan menilai prestasi pembelajaran pengukuhan BoT pada 4 tugas kawalan robot di Gim Isaac berbanding garis dasar menggunakan PPO. 4 tugasan tersebut ialah: Humanoid-Mod, Humanoid-Board, Humanoid-Hill dan A1-Walk.
Rajah 5 menunjukkan pulangan plot purata pelancaran penilaian semasa latihan untuk MLP, Transformer dan BoT (Hard and Mix). di mana garis pepejal sepadan dengan min dan kawasan berlorek sepadan dengan ralat piawai lima biji.
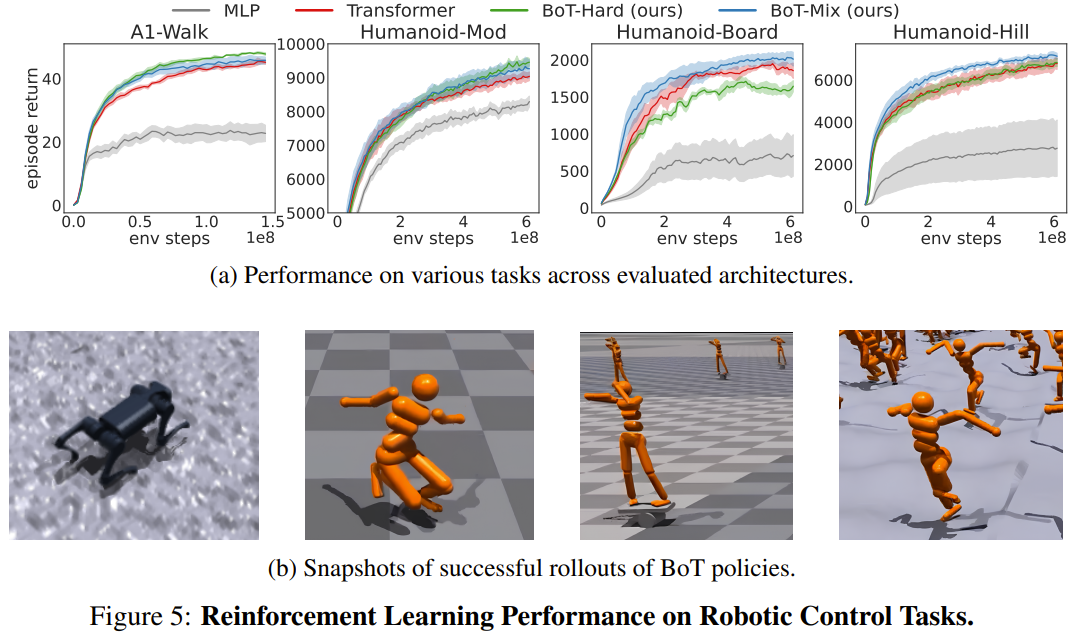

Hasilnya menunjukkan bahawa BoT-Mix secara konsisten mengatasi prestasi MLP dan garis dasar Transformer asal dari segi kecekapan sampel dan prestasi asimptotik. Ini menggambarkan kegunaan menyepadukan berat sebelah daripada badan robot ke dalam seni bina rangkaian dasar.
Sementara itu, BoT-Hard berprestasi lebih baik daripada Transformer asal pada tugas yang lebih mudah (A1-Walk dan Humanoid-Mod), tetapi melakukan lebih teruk pada tugas penerokaan yang lebih sukar (Humanoid-Board dan Humanoid-Hill) . Memandangkan perhatian bertopeng menghalang penyebaran maklumat dari bahagian badan yang jauh, batasan kuat BoT-Hard dalam komunikasi maklumat mungkin menghalang kecekapan penerokaan pembelajaran pengukuhan.
Eksperimen Dunia Sebenar
Simulierte Sportumgebungen von Isaac Gym werden häufig verwendet, um verstärkende Lernstrategien von virtuellen auf reale Umgebungen zu übertragen, ohne dass Anpassungen in der realen Welt erforderlich sind. Um zu überprüfen, ob die neu vorgeschlagene Architektur für reale Anwendungen geeignet ist, implementierte das Team eine oben trainierte BoT-Richtlinie auf einem Unitree A1-Roboter. Wie Sie dem Video unten entnehmen können, kann die neue Architektur zuverlässig in realen Einsätzen eingesetzt werden.

Computeranalyse
Das Team analysierte auch den Rechenaufwand der neuen Architektur, wie in Abbildung 6 dargestellt. Hier werden die Skalierungsergebnisse der neu vorgeschlagenen maskierten Aufmerksamkeit und der konventionellen Aufmerksamkeit für unterschiedliche Sequenzlängen (Anzahl der Knoten) angegeben.
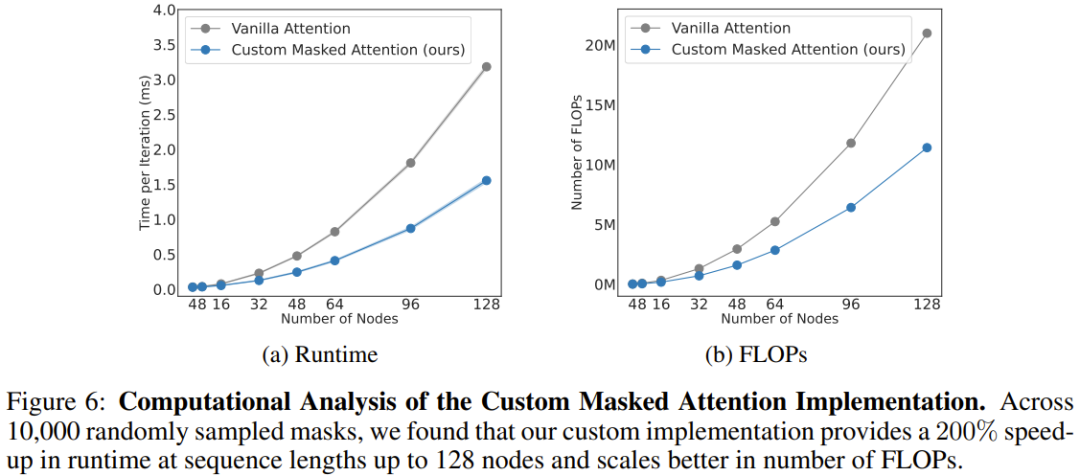
Es ist ersichtlich, dass bei 128 Knoten (entspricht einem humanoiden Roboter mit geschickten Armen) die neue Aufmerksamkeit die Geschwindigkeit um 206 % erhöhen kann.
Insgesamt zeigt dies, dass körperbasierte Bias in BoT-Architekturen nicht nur die Gesamtleistung physikalischer Agenten verbessern, sondern auch von der natürlich spärlichen Maskierung der Architektur profitieren. Diese Methode kann durch ausreichende Parallelisierung die Trainingszeit von Lernalgorithmen deutlich reduzieren.
Atas ialah kandungan terperinci Game Changer untuk pembelajaran strategi robot? Berkeley mencadangkan Body Transformer. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!





























![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



