



Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Penjanaan imej interaksi watak merujuk kepada penjanaan imej yang memenuhi keperluan perihalan teks, dan kandungannya ialah interaksi antara orang dan objek, dan imej itu diperlukan untuk menjadi realistik dan semantik yang mungkin. Dalam tahun-tahun kebelakangan ini, model imej yang dijana teks telah mencapai kemajuan yang ketara dalam menjana imej kehidupan sebenar, tetapi model ini masih menghadapi cabaran dalam menghasilkan imej kesetiaan tinggi dengan interaksi manusia sebagai kandungan utama. Kesukaran terutamanya berpunca daripada dua aspek: pertama, kerumitan dan kepelbagaian postur manusia membawa cabaran kepada penjanaan watak yang munasabah kedua, penjanaan kawasan sempadan interaktif yang tidak boleh dipercayai (kawasan yang kaya dengan semantik interaktif) boleh menyebabkan kegagalan ekspresi semantik interaktif watak; tidak mencukupi.
Sebagai tindak balas kepada masalah di atas, pasukan penyelidik dari Universiti Peking mencadangkan rangka kerja penjanaan imej interaksi manusia yang sedar postur dan interaksi (SA-HOI), yang menggunakan kualiti penjanaan postur manusia dan maklumat kawasan sempadan interaksi sebagai panduan untuk proses denoising imej interaksi watak yang lebih munasabah dan realistik dihasilkan. Untuk menilai secara menyeluruh kualiti imej yang dihasilkan, mereka juga mencadangkan penanda aras penjanaan imej interaksi manusia yang komprehensif.

Pautan kertas: https://proceedings.mlr.press/v235/xu24e.html
Laman utama projek: https://sites.google.com/view/sa-hoi/
Pengenalan Kaedah
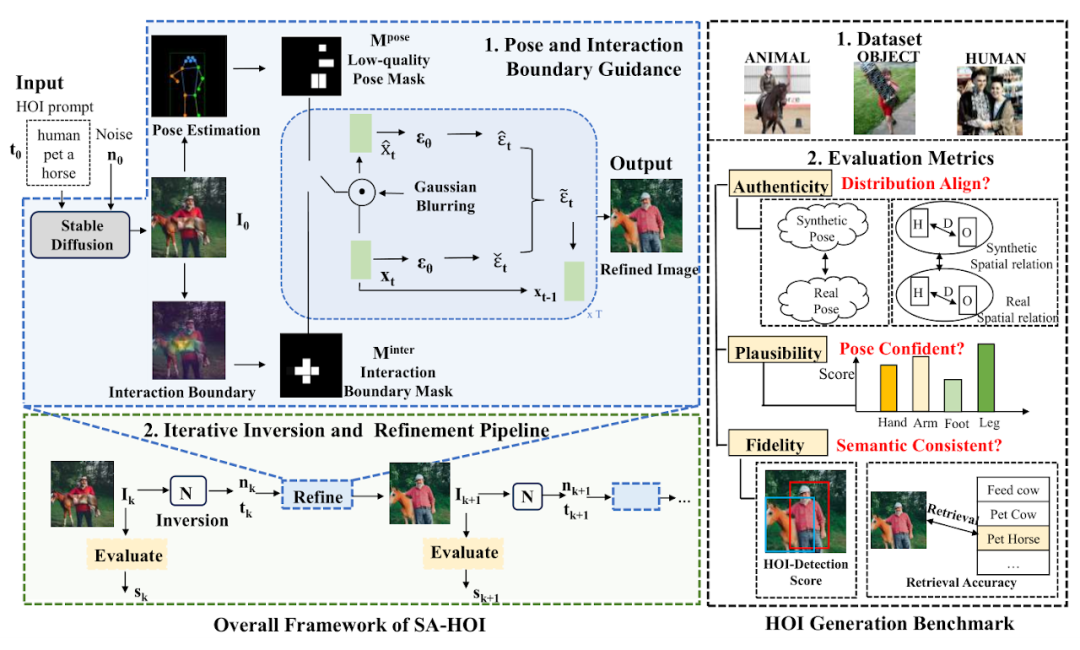
Pengenalan kaedahPanduan postur dan interaktif(Panduan Pose dan Interaksi, PIG) danInversion Inversion and Refinement Pipeline
(Iterative Inversion and Refinement Pipeline, IIR).Dalam PIG, untuk penerangan teks interaksi watak tertentu dan hingar
dan hingar , model resapan stabil (Resapan Stabil [2]) mula-mula digunakan untuk menjana
, model resapan stabil (Resapan Stabil [2]) mula-mula digunakan untuk menjana sebagai imej awal dan pengesan pose [3] digunakan untuk mendapatkan kedudukan sendi badan manusia
sebagai imej awal dan pengesan pose [3] digunakan untuk mendapatkan kedudukan sendi badan manusia dan skor keyakinan yang sepadan
dan skor keyakinan yang sepadan , membina topeng pose
, membina topeng pose yang menyerlahkan kawasan pose berkualiti rendah.
yang menyerlahkan kawasan pose berkualiti rendah.
Untuk panduan interaktif, model segmentasi digunakan untuk mengesan kawasan sempadan interaksi, mendapatkan mata utama dan skor keyakinan yang sepadan
dan skor keyakinan yang sepadan , dan menyerlahkan kawasan interaksi dalam topeng interaksi
, dan menyerlahkan kawasan interaksi dalam topeng interaksi untuk meningkatkan ekspresi semantik sempadan interaksi. Untuk setiap langkah denoising,
untuk meningkatkan ekspresi semantik sempadan interaksi. Untuk setiap langkah denoising, dan
dan digunakan sebagai kekangan untuk membetulkan kawasan yang diserlahkan ini, dengan itu mengurangkan masalah penjanaan yang wujud di kawasan ini. Di samping itu, IIR digabungkan dengan model penyongsangan imej N untuk mengekstrak bunyi n dan pembenaman t penerangan teks daripada imej yang memerlukan pembetulan lanjut, dan kemudian menggunakan PIG untuk melakukan pembetulan seterusnya pada imej, dan menggunakan kualiti penilai Q untuk menilai kualiti imej yang diperbetulkan Menilai dan menggunakan operasi untuk meningkatkan kualiti imej secara beransur-ansur.
digunakan sebagai kekangan untuk membetulkan kawasan yang diserlahkan ini, dengan itu mengurangkan masalah penjanaan yang wujud di kawasan ini. Di samping itu, IIR digabungkan dengan model penyongsangan imej N untuk mengekstrak bunyi n dan pembenaman t penerangan teks daripada imej yang memerlukan pembetulan lanjut, dan kemudian menggunakan PIG untuk melakukan pembetulan seterusnya pada imej, dan menggunakan kualiti penilai Q untuk menilai kualiti imej yang diperbetulkan Menilai dan menggunakan operasi untuk meningkatkan kualiti imej secara beransur-ansur.
Pseudokod persampelan berpandukan pose dan interaksi ditunjukkan dalam Rajah 2. Dalam setiap langkah denoising, kami mula-mula mendapatkan ramalan hingar ϵt dan pembinaan semula perantaraan ϵt seperti yang direka dalam model resapan stabil (Resapan Stabil). Kami kemudian menggunakan Gaussian blur G pada untuk mendapatkan ciri terpendam terdegradasi dan , dan seterusnya memperkenalkan maklumat dalam ciri terpendam yang sepadan ke dalam proses penyahnosan.
 dan
dan digunakan untuk menjana
digunakan untuk menjana dan
dan , dan menyerlahkan kawasan kualiti pose rendah dalam
, dan menyerlahkan kawasan kualiti pose rendah dalam dan
dan untuk membimbing model mengurangkan penjanaan herotan di kawasan ini. Untuk membimbing model untuk menambah baik kawasan berkualiti rendah, kawasan skor pose rendah akan diserlahkan melalui formula berikut:
untuk membimbing model mengurangkan penjanaan herotan di kawasan ini. Untuk membimbing model untuk menambah baik kawasan berkualiti rendah, kawasan skor pose rendah akan diserlahkan melalui formula berikut:

Di mana , x, y ialah koordinat piksel demi piksel bagi imej, H, W ialah saiz imej dan σ ialah varians bagi taburan Gaussian.
, x, y ialah koordinat piksel demi piksel bagi imej, H, W ialah saiz imej dan σ ialah varians bagi taburan Gaussian. mewakili perhatian yang tertumpu pada sendi ke-i Dengan menggabungkan perhatian semua sendi, kita boleh membentuk peta perhatian akhir
mewakili perhatian yang tertumpu pada sendi ke-i Dengan menggabungkan perhatian semua sendi, kita boleh membentuk peta perhatian akhir dan menggunakan ambang untuk menukarmenjadi topeng.
dan menggunakan ambang untuk menukarmenjadi topeng.
di mana ϕt ialah ambang yang menjana topeng pada langkah masa t. Begitu juga, untuk panduan interaktif, pengarang kertas kerja menggunakan model segmentasi untuk mendapatkan titik kontur luar objek O dan titik sendi badan manusia C, mengira matriks jarak D antara orang dan objek, dan sampel titik utama sempadan interaksi daripadanya, dan penggunaan serta panduan postur Kaedah yang sama menjana perhatian interaktif
daripadanya, dan penggunaan serta panduan postur Kaedah yang sama menjana perhatian interaktif dan topengdan digunakan untuk mengira hingar ramalan akhir.
dan topengdan digunakan untuk mengira hingar ramalan akhir.
Penyongsangan berulang dan proses pembetulan imej
Untuk mendapatkan penilaian kualiti imej yang dijana dalam masa nyata, pengarang kertas kerja memperkenalkan penilai kualiti Q sebagai panduan untuk operasi berulang. Untuk imej pusingan ke-k , penilai Q digunakan untuk mendapatkan skor kualitinya
, penilai Q digunakan untuk mendapatkan skor kualitinya , dan kemudian
, dan kemudian dijana berdasarkan
dijana berdasarkan . Untuk mengekalkan kandungan utamaselepas pengoptimuman, hingar yang sepadan diperlukan sebagai nilai awal untuk denoising.
. Untuk mengekalkan kandungan utamaselepas pengoptimuman, hingar yang sepadan diperlukan sebagai nilai awal untuk denoising.
Walau bagaimanapun, hingar sedemikian tidak tersedia, jadi kaedah penyongsangan imej diperkenalkan untuk mendapatkan ciri potensi hingar
diperkenalkan untuk mendapatkan ciri potensi hingar dan pembenaman teks
dan pembenaman teks , sebagai input PIG, untuk menjana hasil yang dioptimumkan
, sebagai input PIG, untuk menjana hasil yang dioptimumkan .
.
반복 라운드 전후의 품질 점수를 비교하여 최적화를 계속할지 여부를 판단할 수 있습니다. 와
와 사이에 큰 차이가 없는 경우, 즉 임계값 θ 미만인 경우 프로세스가 이미지를 충분히 개선하여 최적화를 종료하고 가장 높은 품질 점수의 이미지를 출력합니다.
사이에 큰 차이가 없는 경우, 즉 임계값 θ 미만인 경우 프로세스가 이미지를 충분히 개선하여 최적화를 종료하고 가장 높은 품질 점수의 이미지를 출력합니다.
캐릭터 상호작용 이미지 생성 벤치마크
 >
>
실험 결과
기존 방법과의 비교 실험 결과는 캐릭터 상호작용 이미지 생성 지표와 기존 이미지 생성 지표의 성능을 각각 비교한 Table 1과 Table 2와 같다. 표 2: 기존 이미지 생성 지표에서 기존 방법과의 비교 실험 결과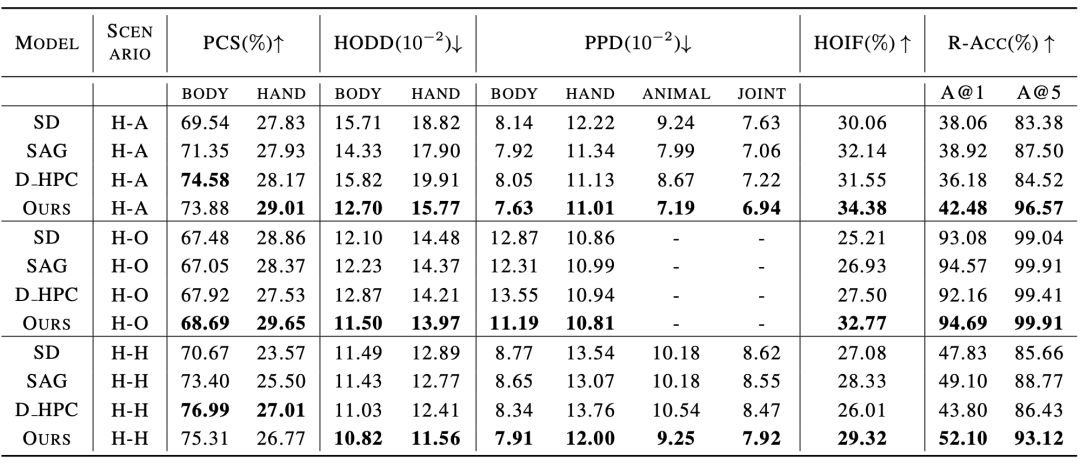 실험 결과는 본 논문의 방법이 인간과 같은 다차원에서 기존 모델보다 우수하다는 것을 보여줍니다. 신체 생성 품질, 상호 작용 의미 표현, 인간 상호 작용 거리, 인간 자세 분포 및 전반적인 이미지 품질.
실험 결과는 본 논문의 방법이 인간과 같은 다차원에서 기존 모델보다 우수하다는 것을 보여줍니다. 신체 생성 품질, 상호 작용 의미 표현, 인간 상호 작용 거리, 인간 자세 분포 및 전반적인 이미지 품질.
또한 논문의 저자는 주관적인 평가를 실시하여 많은 사용자를 대상으로 인체 품질, 사물 외관, 대화형 의미 및 전반적인 품질 등 다양한 관점에서 평가하도록 했습니다. 실험 결과는 SA-HOI 방법이 우수함을 입증합니다. 모든 각도에서 인간의 미학과 더 일치합니다.
표 3: 기존 방법을 사용한 주관적 평가 결과
정성적 실험에서 아래 그림은 동일한 캐릭터 상호작용 카테고리 설명에 대해 다양한 방법으로 생성된 결과를 비교한 것입니다. 위의 사진 그룹에서 새로운 방법을 사용한 모델은 "키스"의 의미를 정확하게 표현하고 생성된 인체 자세도 더욱 합리적입니다. 아래 사진 그룹에서 논문의 방법은 다른 방법에 존재하는 인체의 왜곡과 뒤틀림을 성공적으로 완화하고 손이 닿는 부분에 여행 가방의 레버를 생성하여 "여행 가방 가져가기"의 상호 작용을 향상시킵니다. 의미론적 표현을 통해 인체 자세와 상호작용 의미론 모두에서 다른 방법보다 우수한 결과를 얻습니다. ㅋㅋㅋ ~ .
 참고 자료:
참고 자료:
[1] Rombach, R., Blattmann, A., Lorenz, D., Esser, P. 및 Ommer, B. Proceedings에서 잠재 확산 모델을 사용한 고해상도 이미지 합성. IEEE/CVF
컴퓨터 비전 및 패턴 인식(CVPR) 컨퍼런스, 페이지 10684–10695, 2022년 6월
[2] HuggingFace, 2022. URL https://huggingface . co/CompVis/stable-diffusion-v1-4.
[3] Chen, K., Wang, J., Pang, J., Cao, Y., Xiong, Y., Li, X . , Sun, S., Feng, W., Liu, Z., Xu, J., Zhang, Z., Cheng, D., Zhu, C
., Cheng, T., Zhao, Q., Li, B., Lu, X., Zhu, R., Wu, Y., Dai, J., Wang, J., Shi, J., Ouyang, W., Loy, C. C. 및 Lin, D. MM감지: 공개 mmlab 감지 도구 상자 및 벤치마크 arXiv:1906.07155, 2019.[4] Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch 및 Daniel Cohen-Or Null-
텍스트 arXiv preprint
arXiv:2211.09794, 2022.
[5] Yu-Wei Chao, Zhan Wang, Yugeng He, Jiaxuan Wang 및 Jia Deng HICO: 이미지에서 인간과 사물의 상호 작용을 인식하기 위한 벤치마크, 컴퓨터 비전에 관한 IEEE 국제 컨퍼런스 진행, 2015.
Atas ialah kandungan terperinci ICML 2024 |. Imej interaksi watak, kini saya memahami kata-kata segera anda dengan lebih baik, Universiti Peking melancarkan rangka kerja penjanaan imej interaksi watak berdasarkan persepsi semantik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!





























![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



