


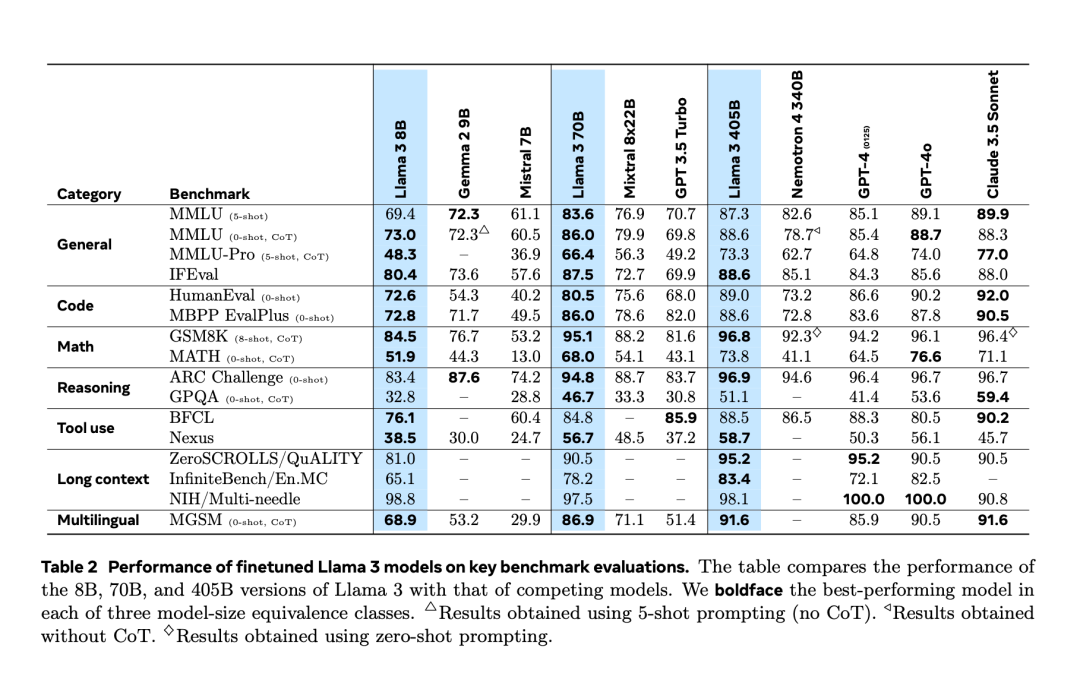
Selepas mengalami "kebocoran tidak sengaja" dua hari lebih awal, akhirnya Llama 3.1 dikeluarkan secara rasmi malam tadi. Llama 3.1 memanjangkan panjang konteks kepada 128K dan tersedia dalam versi 8B, 70B dan 405B, sekali lagi secara bersendirian meningkatkan bar untuk persaingan pada trek model besar. Bagi komuniti AI, kepentingan paling penting Llama 3.1 405B ialah ia menyegarkan had atas keupayaan model asas sumber terbuka, pegawai Meta berkata dalam satu siri tugasan, prestasinya adalah setanding dengan yang terbaik tertutup model sumber. Jadual di bawah menunjukkan prestasi model Siri Llama 3 semasa pada penanda aras utama. Ia boleh dilihat bahawa prestasi model 405B sangat hampir dengan GPT-4o.

Meta meningkatkan prapemprosesan model Llama dan saluran paip Curation bagi data pra-latihan, serta jaminan kualiti dan kaedah penapisan data selepas latihan.
Meta percaya bahawa terdapat tiga tuil utama untuk pembangunan model asas berkualiti tinggi: pengurusan data, skala dan kerumitan.
Atas ialah kandungan terperinci Bagaimana untuk mencipta model sumber terbuka yang boleh mengalahkan GPT-4o? Mengenai Llama 3.1 405B, Meta ditulis dalam kertas ini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Penyelesaian virus exe folder
Penyelesaian virus exe folder
 java mengkonfigurasi pembolehubah persekitaran jdk
java mengkonfigurasi pembolehubah persekitaran jdk
 pengecualian nullpointerexception
pengecualian nullpointerexception
 Pertanyaan masa Internet
Pertanyaan masa Internet
 Bagaimana untuk memulihkan pelayar IE untuk melompat ke EDGE secara automatik
Bagaimana untuk memulihkan pelayar IE untuk melompat ke EDGE secara automatik
 kaedah pemadaman fail hiberfil
kaedah pemadaman fail hiberfil
 Beberapa cara untuk menangkap data
Beberapa cara untuk menangkap data
 Apakah perisian yang terbuka?
Apakah perisian yang terbuka?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



