| HuggingFace semua tema ranking satu 
For more resource information, you can view:
- Code address: https://github.com/KwaiVGI/LivePortrait
- Paper link: https://arxiv.org/abs /2407.03168
- Project homepage: https://liveportrait.github.io/
- HuggingFace Space one-click online experience: https://huggingface.co/spaces/KwaiVGI/LivePortrait
What kind of technology does LivePortrait use to quickly become popular on the entire Internet? Different from the current mainstream diffusion model-based methods, LivePortrait explores and expands the potential of the implicit keypoint-based framework, thereby balancing model calculation efficiency and controllability . LivePortrait focuses on better generalization, controllability and practical efficiency. In order to improve generation capabilities and controllability, LivePortrait uses 69M high-quality training frames, a video-picture hybrid training strategy, upgraded the network structure, and designed better action modeling and optimization methods. In addition, LivePortrait regards implicit key points as an effective implicit representation of facial blend deformation (Blendshape), and carefully proposes stitching and retargeting modules based on this. These two modules are lightweight MLP networks, so while improving controllability, the computational cost can be ignored. Even compared with some existing diffusion model-based methods, LivePortrait is still very effective. At the same time, on the RTX4090 GPU, LivePortrait's single frame generation speed can reach 12.8ms. If further optimized, such as TensorRT, it is expected to reach less than 10ms! LivePortrait’s model training is divided into two stages. The first stage is basic model training, and the second stage is fitting and redirection module training. The first stage of basic model training
),為第一個階段,如同在組合中ace Vid2vid[1],做了一系列改進,包括: :LivePortrait採用了公開視訊資料集Voxceleb[2],MEAD[3],RAVDESS [4]和風格化圖片資料集AAHQ[5]。此外,還使用了大規模4K分辨率的人像視頻,包含不同的表情和姿態,200餘小時的說話人像視頻,一個私有的數據集LightStage[6],以及一些風格化的視頻和圖片。 LivePortrait將長影片分割成少於30秒的片段,並確保每個片段只包含一個人。為了確保訓練資料的質量,LivePortrait使用快手自研的KVQ[7](快手自研的視訊品質評估方法,能夠綜合感知視訊的品質、內容、場景、美學、編碼、音訊等特徵,執行多維度評價)來過濾低品質的影片片段。總訓練資料有69M視頻,包含18.9K身份和60K靜態風格化人像。 :僅使用真人人像影片訓練的模型對於真人人像表現良好,但對風格化人像(例如動漫)的泛化能力不足。風格化的人像影片是較為稀有的,LivePortrait從不到100個身分中收集了僅約1.3K影片片段。相較之下,高品質的風格化人像圖片更為豐富,LivePortrait收集了大約60K身份互異的圖片,提供多元身分資訊。為了利用這兩種資料類型,LivePortrait將每張圖片視為一幀影片片段,並同時在影片和圖片上訓練模型。這種混合訓練提升了模型的泛化能力。 :LivePortrait將規範隱式關鍵點估計網絡(L),頭部姿態估計網絡(H) 和表情變形估計網絡(Δ) 統一為了一個單一模型(M),並採用ConvNeXt-V2-Tiny[8]為其結構,從而直接估計輸入圖片的規範隱式關鍵點,頭部姿態和表情變形。此外,受到face vid2vid相關工作啟發,LivePortrait採用效果更優的SPADE[9]的解碼器作為生成器 (G)。隱式特徵 (fs) 在變形後被細緻地輸入SPADE解碼器,其中隱式特徵的每個通道作為語義圖來產生驅動後的圖片。為了提升效率,LivePortrait也插入PixelShuffle[10]層作為 (G) 的最後一層,從而將解析度由256提升為512。 :原始隱式關鍵點的計算建模方式忽略了縮放係數,導致此縮放容易被學到表情係數裡,使得訓練難度變大。為了解決這個問題,LivePortrait在建模中引入了縮放因子。 LivePortrait發現縮放正規投影會導致過於靈活的可學習表情係數,造成跨身分驅動時的紋理黏連。因此LivePortrait所採用的變換是一種靈活性和驅動性之間的折衷。 :原始的隱式點框架似乎缺少生動驅動面部表情的能力,例如眨眼和眼球運動。具體來說,驅動結果中人像的眼球方向和頭部朝嚮往往保持平行。 LivePortrait將這些限制歸因於無監督學習細微臉部表情的困難。為了解決這個問題,LivePortrait引入了2D關鍵點來捕捉微表情,用關鍵點引導的損失 (Lguide)作為隱式關鍵點優化的引導。 :LivePortrait採用了face vid2vid的隱式關鍵點不變損失(LE),關鍵點先驗損失(LL),頭部姿態損失(LH) 和變形先驗損失(LΔ)。為了進一步提升紋理質量,LivePortrait採用了感知和GAN損失,不僅對輸入圖的全局領域,面部和嘴部的局部領域也施加了這些損失,記為級聯感知損失(LP,cascade) 和級聯GAN損失(LG,cascade) 。面部和嘴部區域由2D語義關鍵點定義。 LivePortrait也採用了人臉身分損失 (Lfaceid) 來保留參考圖片的身份。 第一階段的所有模組為從頭訓練,總的訓練最佳化函數 (Lbase) 為以上損失項的加權和。 LivePortrait將隱式關鍵點可以看成一種隱式混合變形,並發現這種組合只需借助一個輕量的MLP便可被較好地學習,計算消耗可忽略。考慮到實際需求,LivePortrait設計了一個貼合模組、眼部重定向模組和嘴部重定向模組。When the reference portrait is cropped, the driven portrait will be pasted back to the original image space from the crop space. The fitting module is added to avoid pixel misalignment during the pasting process, such as the shoulder area. As a result, LivePortrait can be action-driven for larger picture sizes or group photos. The eye retargeting module is designed to solve the problem of incomplete eye closure when driving across identities, especially when a portrait with small eyes drives a portrait with large eyes. The design idea of the mouth redirection module is similar to that of the eye redirection module, which normalizes the input by driving the mouth of the reference picture into a closed state for better driving. The second phase of model training: fit and redirect the module training 
Follow the module : During the training process, the input of the module (s) is the reference diagram Implicit keypoints (xs) and the implicit keypoints (xd) of another identity-driven frame, and estimate the expression change (Δst) driving the implicit keypoints (xd). It can be seen that, unlike the first stage, LivePortrait uses cross-identity actions to replace the same-identity actions to increase the difficulty of training, aiming to make the fitting module have better generalization. Next, the driver implicit keypoint (xd) is updated, and the corresponding driver output is (Ip,st). LivePortrait also outputs self-reconstructed images (Ip,recon) at this stage. Finally, the fitting module's loss function (Lst) calculates the pixel-consistent loss of the shoulder region of both shoulders and the regularization loss of the fitting variation. Eye and mouth redirection module: The input of the eye redirection module (Reyes) is the reference image implicit key point (xs), the reference image eye opening condition tuple and a random The driving eye opening coefficient is used to estimate the deformation change (Δeyes) of the driving key point. The eye opening condition tuple represents the eye opening ratio, and the larger it is, the greater the degree of eye opening. Similarly, the inputs of the mouth redirection module (Rlip) are the implicit key points (xs) of the reference image, the mouth opening condition coefficient of the reference image and a random driving mouth opening coefficient, and the driving key points are estimated from this The amount of change (Δlip). Next, the driving key points (xd) are updated by the deformation changes corresponding to the eyes and mouth respectively, and the corresponding driving outputs are (Ip,eyes) and (Ip,lip). Finally, the objective functions of the eye and mouth retargeting modules are (Leyes) and (Llip) respectively, which calculate the pixel consistency loss of the eye and mouth areas, the regularization loss of the eye and mouth variation, and the random loss. The loss between the drive coefficient and the opening condition coefficient of the drive output. The eye and mouth changes (Δeyes) and (Δlip) are independent of each other, so during the inference phase they can be linearly summed and the driving implicit keypoints updated. Same identity driver : From the above same identity driver comparison results, it can be seen that compared with the existing non-diffusion model method and the diffusion model-based method, LivePortrait With better generation quality and driving accuracy, it can capture the subtle expressions of the eyes and mouth driving frames while preserving the texture and identity of the reference image. Even in larger head postures, LivePortrait has a more stable performance. : From the above same identity driver comparison results, it can be seen that compared with the existing non-diffusion model method and the diffusion model-based method, LivePortrait With better generation quality and driving accuracy, it can capture the subtle expressions of the eyes and mouth driving frames while preserving the texture and identity of the reference image. Even in larger head postures, LivePortrait has a more stable performance.

Cross-identity driver: As can be seen from the above cross-identity driver comparison results, compared with existing methods, LivePortrait can accurately inherit the subtle eye and mouth movements in the driver video, and is also relatively stable when the posture is large. . LivePortrait is slightly weaker than the diffusion model-based method AniPortrait [11] in terms of generation quality, but compared with the latter, LivePortrait has extremely fast inference efficiency and requires fewer FLOPs. Multi-person driver: Thanks to LivePortrait’s fitting module, for group photos, LivePortrait can drive designated faces with designated driver videos, thus achieving Multi-person photo driver broadens the practical application of LivePortrait.  Animal driven: LivePortrait not only has good generalization for portraits, but also can be accurately driven for animal portraits after fine-tuning on animal data sets. Animal driven: LivePortrait not only has good generalization for portraits, but also can be accurately driven for animal portraits after fine-tuning on animal data sets. 
Portrait video editing: In addition to portrait photos, given a portrait video, such as a dance video, LivePortrait can use the driving video to perform motion editing on the head area. Thanks to the fitting module, LivePortrait can accurately edit movements in the head area, such as expressions, postures, etc., without affecting the images in non-head areas.  Implementation and prospectsLivePortrait’s related technical points have been implemented in many of Kuaishou’s businesses, including Kuaishou magic watch, Kuaishou private messaging, Kuaiying’s AI emoticon gameplay, and Kuaishou live broadcast , and the Puchi APP for young people incubated by Kuaishou, etc., and will explore new implementation methods to continue to create value for users. In addition, LivePortrait will further explore multi-modal driven portrait video generation based on the Keling basic model, pursuing higher-quality effects. [1] Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu. One-shot free-view neural talking-head synthesis for video conferencing. In CVPR, 2021.[2] Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. Voxceleb: a large-scale speaker identification dataset. In Interspeech, 2017.[3] Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wayne Wu, Chen Qian, Ran He, Yu Qiao, and Chen Change Loy. Mead: A large-scale audio-visual dataset for emotional talking-face generation. In ECCV, 2020. [4] Steven R Livingstone and Frank A Russo. The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english. In PloS one, 2018 [5] Mingcong Liu, Qiang Li, Zekui Qin, Guoxin Zhang, Pengfei Wan, and Wen Zheng. Blendgan: Implicitly gan blending for arbitrary stylized face generation. In NeurIPS, 2021.[ 6] Haotian Yang, Mingwu Zheng, Wanquan Feng, Haibin Huang, Yu-Kun Lai, Pengfei Wan, Zhongyuan Wang, and Chongyang Ma. Towards practical capture of high-fidelity relightable avatars. In SIGGRAPH Asia, 2023. [7] Kai Zhao, Kun Yuan, Ming Sun, Mading Li, and Xing Wen. Quality-aware pre-trained models for blind image qualityassessment. In CVPR, 2023. [8] Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, and Saining Xie. Con-vnext v2: Co-designing and scaling convnets with masked autoencoders. In CVPR, 2023.[9] Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive normalization. In CVPR, 2019. [10] Wenzhe Shi, Jose Caballero, Ferenc Husz ´ar, Johannes Totz, Andrew P Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network . In CVPR, 2016.[11] Huawei Wei, Zejun Yang, and Zhisheng Wang. Aniportrait: Audio-driven synthesis of photorealistic portrait animation. arXiv preprint:2403.17694, 2024. Implementation and prospectsLivePortrait’s related technical points have been implemented in many of Kuaishou’s businesses, including Kuaishou magic watch, Kuaishou private messaging, Kuaiying’s AI emoticon gameplay, and Kuaishou live broadcast , and the Puchi APP for young people incubated by Kuaishou, etc., and will explore new implementation methods to continue to create value for users. In addition, LivePortrait will further explore multi-modal driven portrait video generation based on the Keling basic model, pursuing higher-quality effects. [1] Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu. One-shot free-view neural talking-head synthesis for video conferencing. In CVPR, 2021.[2] Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. Voxceleb: a large-scale speaker identification dataset. In Interspeech, 2017.[3] Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wayne Wu, Chen Qian, Ran He, Yu Qiao, and Chen Change Loy. Mead: A large-scale audio-visual dataset for emotional talking-face generation. In ECCV, 2020. [4] Steven R Livingstone and Frank A Russo. The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english. In PloS one, 2018 [5] Mingcong Liu, Qiang Li, Zekui Qin, Guoxin Zhang, Pengfei Wan, and Wen Zheng. Blendgan: Implicitly gan blending for arbitrary stylized face generation. In NeurIPS, 2021.[ 6] Haotian Yang, Mingwu Zheng, Wanquan Feng, Haibin Huang, Yu-Kun Lai, Pengfei Wan, Zhongyuan Wang, and Chongyang Ma. Towards practical capture of high-fidelity relightable avatars. In SIGGRAPH Asia, 2023. [7] Kai Zhao, Kun Yuan, Ming Sun, Mading Li, and Xing Wen. Quality-aware pre-trained models for blind image qualityassessment. In CVPR, 2023. [8] Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, and Saining Xie. Con-vnext v2: Co-designing and scaling convnets with masked autoencoders. In CVPR, 2023.[9] Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive normalization. In CVPR, 2019. [10] Wenzhe Shi, Jose Caballero, Ferenc Husz ´ar, Johannes Totz, Andrew P Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network . In CVPR, 2016.[11] Huawei Wei, Zejun Yang, and Zhisheng Wang. Aniportrait: Audio-driven synthesis of photorealistic portrait animation. arXiv preprint:2403.17694, 2024.
|






 di GitHub Kami telah menerima pujian meluas dan perhatian masih berkembang:
di GitHub Kami telah menerima pujian meluas dan perhatian masih berkembang:  Kedudukan No. 1 selama seminggu berturut-turut , baru-baru ini mendahului HuggingFace all theme rankings
Kedudukan No. 1 selama seminggu berturut-turut , baru-baru ini mendahului HuggingFace all theme rankings 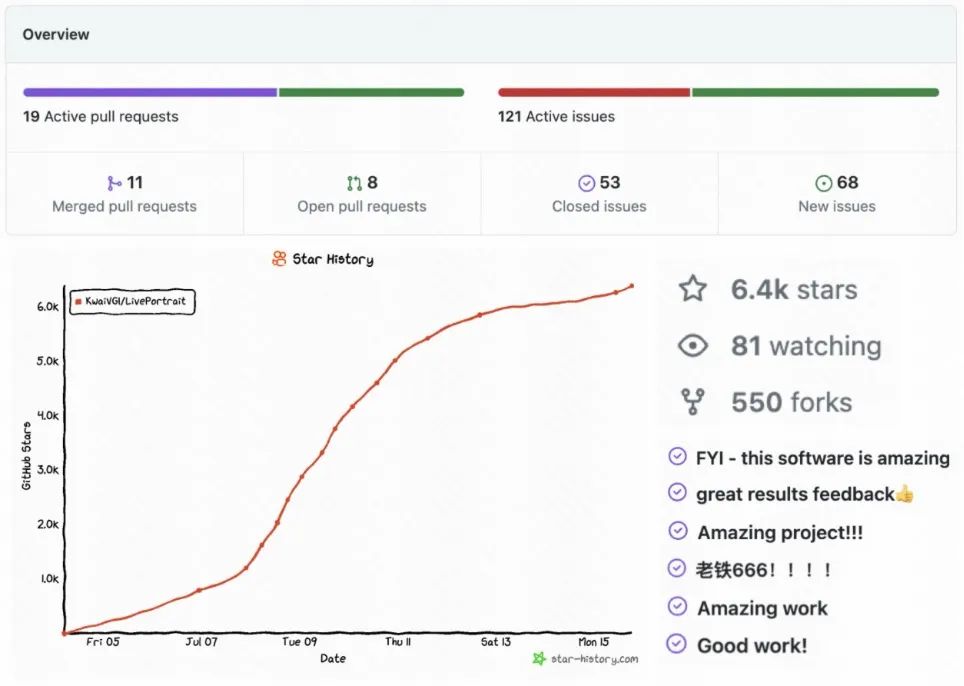 Kedudukan Hugging 1
Kedudukan Hugging 1  Bagaimana untuk menyelesaikan ralat pengecam mysql yang tidak sah
Bagaimana untuk menyelesaikan ralat pengecam mysql yang tidak sah
 Bagaimana untuk memadam halaman kosong dalam perkataan tanpa menjejaskan format lain
Bagaimana untuk memadam halaman kosong dalam perkataan tanpa menjejaskan format lain
 penggunaan split js
penggunaan split js
 penggunaan fungsi stripslash
penggunaan fungsi stripslash
 Bagaimana untuk menyalin jadual Excel untuk menjadikannya saiz yang sama dengan yang asal
Bagaimana untuk menyalin jadual Excel untuk menjadikannya saiz yang sama dengan yang asal
 Pengenalan kepada penggunaan vscode
Pengenalan kepada penggunaan vscode
 Linux menambah kaedah sumber kemas kini
Linux menambah kaedah sumber kemas kini
 Penggunaan asas pernyataan sisipan
Penggunaan asas pernyataan sisipan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



