AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文的主要作者为黄毅翀。黄毅翀是哈尔滨工业大学社会计算与信息检索研究中心博士生,鹏城实验室实习生,师从秦兵教授和冯骁骋教授。研究方向包括大语言模型集成学习、多语言大模型,相关论文发表于自然语言处理顶级会议 ACL、EMNLP、COLING。
随着大语言模型展现出惊人的语言智能,各大 AI 公司纷纷推出自己的大模型。这些大模型通常在不同领域和任务上各有所长,如何将它们集成起来以挖掘其互补潜力,成为了 AI 研究的前沿课题。
近期,哈工大和鹏城实验室的研究人员提出了「Training-free 的异构大模型集成学习框架」DeePEn。
不同于以往方法训练外部模块来筛选、融合多个模型生成的回复,DeePEn 在解码过程中融合多个模型输出的概率分布,联合决定每一步的输出 token。相较而言,该方法不仅能快速应用于任何模型组合,还允许被集成模型访问彼此的内部表示(概率分布),实现更深层次的模型协作。
结果表明, DeePEn 在多个公开数据集上均能取得显著提升,有效扩展大模型性能边界:


-
论文标题:Ensemble Learning for Heterogeneous LargeLanguage Models with Deep Parallel Collaboration
-
论文地址:https://arxiv.org/abs/2404.12715
-
代码地址:https://github.com/OrangeInSouth/DeePEn
异构大模型集成的核心难点在于如何解决模型间的词表差异问题。为此,DeePEn 基于相对表示理论,构建由多个模型词表之间的共享 token 构成的统一相对表示空间。在解码阶段,DeePEn 将不同大模型输出的概率分布映射到该空间进行融合。
全程无需参数训练。
下图中展示了 DeePEn 的方法。给定 N 个模型进行集成,DeePEn 首先构建它们的转换矩阵(即相对表示矩阵),将来自多个异构绝对空间的概率分布映射到统一的相对空间中。在每个解码步骤中,所有模型进行前向计算并输出 N 个概率分布。这些分布被映射到相对空间并进行聚合。最后,聚合结果被转换回某个模型(主模型)的绝对空间,以确定下一个 token。

Rajah 1: Gambar rajah skema. Antaranya, matriks transformasi perwakilan relatif diperoleh dengan mengira perkataan yang membenamkan persamaan antara setiap token dalam perbendaharaan kata dan token anchor yang dikongsi antara model. Membina transformasi perwakilan relatif perbendaharaan kata yang dikongsi, Dan ekstrak subset A⊆C atau gunakan semua perkataan yang dikongsi sebagai kata kunci set A=C.
Untuk setiap model, DeepPEn mengira persamaan pembenaman antara setiap token dalam perbendaharaan kata dan token anchor untuk mendapatkan matriks perwakilan relatif
. Akhir sekali, untuk mengatasi masalah degradasi perwakilan relatif bagi perkataan terpencil, pengarang kertas kerja melakukan normalisasi baris pada matriks perwakilan relatif dan melakukan operasi softmax pada setiap baris matriks untuk mendapatkan matriks perwakilan relatif ternormal
relative perwakilan gabungan
Dalam setiap langkah penyahkodan, sebaik sahaja model
Outputs taburan kebarangkalian
, mendalam menggunakan matriks perwakilan relatif normal untuk menukar
ke dalam perwakilan relatif
 :
:
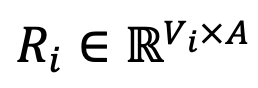
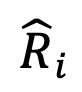
Atas ialah kandungan terperinci LLama+Mistral+…+Yi=? Rangka kerja pembelajaran bersepadu model besar heterogen tanpa latihan DeePEn ada di sini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!





 其中
其中 是模型
是模型 的协作权重。作者尝试了两种确定协作权重值的方法:(1) DeePEn-Avg,对所有模型使用相同的权重;(2) DeePEn-Adapt,根据各个模型的验证集性能成比例地为每个模型设置权重。
的协作权重。作者尝试了两种确定协作权重值的方法:(1) DeePEn-Avg,对所有模型使用相同的权重;(2) DeePEn-Adapt,根据各个模型的验证集性能成比例地为每个模型设置权重。
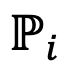 表示模型
表示模型
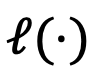 是衡量相对表示之间距离的损失函数(KL 散度)。
是衡量相对表示之间距离的损失函数(KL 散度)。
 相对于绝对表示
相对于绝对表示
 的梯度来指导搜索过程,并迭代地进行搜索。具体来说,DeePEn 将搜索的起始点
的梯度来指导搜索过程,并迭代地进行搜索。具体来说,DeePEn 将搜索的起始点
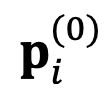 初始化为主模型的原始绝对表示,并进行更新:
初始化为主模型的原始绝对表示,并进行更新:

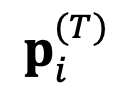 다음 단계에서 출력할 토큰을 결정합니다.
다음 단계에서 출력할 토큰을 결정합니다.


 대형 모델과 전문가 모델을 통합하여 특정 작업의 성능을 효과적으로 개선합니다
대형 모델과 전문가 모델을 통합하여 특정 작업의 성능을 효과적으로 개선합니다




























![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



