Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Penulis kertas kerja ini adalah dari Makmal Bahtera Nuh Montreal di Huawei Kang Jikun, Li Xinze, Chen Xi, Amirreza Ka Boxing Kecerdasan buatan (AI) telah mencapai kemajuan besar dalam dekad yang lalu, terutamanya dalam bidang pemprosesan bahasa semula jadi dan penglihatan komputer. Walau bagaimanapun, cara untuk meningkatkan keupayaan kognitif dan keupayaan penaakulan AI kekal sebagai cabaran besar. Baru-baru ini, kertas kerja bertajuk "MindStar: Enhancing Math Reasoning in Pra-trained LLMs at Inference Time" mencadangkan kaedah penambahbaikan keupayaan masa inferens berasaskan carian pokok MindStar [1], yang dilaksanakan dalam model sumber terbuka Llama. -13-B dan Mistral-7B telah mencapai keupayaan penaakulan anggaran model besar sumber tertutup GPT-3.5 dan Grok-1 pada masalah matematik. 
- Tajuk kertas: MindStar: Meningkatkan Penaakulan Matematik dalam LLM Pra-latihan pada Waktu Inferens
- Alamat kertas: https://arxiv.org/abs/2605.
MindStar Kesan aplikasi pada masalah matematik:

Rajah 1: Ketepatan matematik model bahasa besar yang berbeza. LLaMA-2-13B adalah serupa dalam prestasi matematik kepada GPT-3.5 (4-shot) tetapi menjimatkan lebih kurang 200 kali lebih banyak sumber pengiraan. Pengenalan Hasil yang mengagumkan telah ditunjukkan dalam bidang seperti , dan penulisan kreatif [5]. Walau bagaimanapun, membuka kunci keupayaan LLM untuk menyelesaikan tugas penaakulan yang kompleks masih menjadi cabaran. Beberapa kajian baru-baru ini [6,7] cuba menyelesaikan masalah melalui Penyeliaan Penalaan Halus (SFT) Dengan mencampurkan sampel data inferens baharu dengan set data asal, LLM mempelajari pengedaran asas sampel ini dan cuba meniru pengedaran asas. Belajar logik untuk menyelesaikan tugas penaakulan yang tidak kelihatan. Walaupun pendekatan ini mempunyai peningkatan prestasi, ia sangat bergantung pada latihan yang meluas dan penyediaan data tambahan [8,9]. Laporan Llama-3 [10] menyerlahkan pemerhatian penting: apabila berhadapan dengan masalah inferens yang mencabar, model kadangkala menjana trajektori inferens yang betul. Ini menunjukkan bahawa model tahu cara menghasilkan jawapan yang betul, tetapi menghadapi masalah memilihnya. Berdasarkan penemuan ini, kami bertanya soalan mudah: Bolehkah kami meningkatkan keupayaan penaakulan LLM dengan membantu mereka memilih output yang betul? Untuk meneroka perkara ini, kami menjalankan percubaan menggunakan model ganjaran yang berbeza untuk pemilihan output LLM. Keputusan eksperimen menunjukkan bahawa pemilihan peringkat langkah dengan ketara mengatasi kaedah CoT tradisional.
2. Kaedah MindStar
Rajah 2 Algoritma Gambarajah Senibina Mindstar Kami memperkenalkan rangka kerja carian kesimpulan baru - MindStar (M*), dengan merawat tugas kesimpulan sebagai masalah carian dan memanfaatkan ganjaran model pengawasan proses (proses -Model Ganjaran yang diselia, PRM), M * menavigasi dengan berkesan dalam ruang pokok inferens dan mengenal pasti laluan yang optimum. Menggabungkan idea Beam Search (BS) dan Levin Tree Search (LevinTS), kecekapan carian dipertingkatkan lagi dan laluan penaakulan optimum ditemui dalam kerumitan pengiraan yang terhad. 2.1 Model Ganjaran Diawasi Proses Model Ganjaran Diawasi Proses (PRM) direka untuk menilai langkah perantaraan penjanaan model bahasa besar (LLM) untuk membantu memilih laluan inferens yang betul. Pendekatan ini membina kejayaan PRM dalam aplikasi lain. Secara khusus, PRM mengambil laluan penaakulan semasa 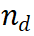 dan potensi langkah seterusnya
dan potensi langkah seterusnya 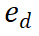 sebagai input, dan mengembalikan nilai ganjaran
sebagai input, dan mengembalikan nilai ganjaran 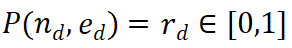 . PRM menilai langkah baharu dengan mempertimbangkan keseluruhan trajektori penaakulan semasa, menggalakkan ketekalan dan kesetiaan kepada laluan keseluruhan. Nilai ganjaran yang tinggi menunjukkan bahawa langkah baharu
. PRM menilai langkah baharu dengan mempertimbangkan keseluruhan trajektori penaakulan semasa, menggalakkan ketekalan dan kesetiaan kepada laluan keseluruhan. Nilai ganjaran yang tinggi menunjukkan bahawa langkah baharu 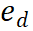 ) mungkin betul untuk laluan penaakulan tertentu
) mungkin betul untuk laluan penaakulan tertentu 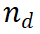 , menjadikan laluan pengembangan bernilai penerokaan selanjutnya. Sebaliknya, nilai ganjaran yang rendah menunjukkan bahawa langkah baharu mungkin tidak betul, yang bermaksud bahawa penyelesaian yang mengikut laluan ini mungkin juga salah. Algoritma M* terdiri daripada dua langkah utama, berulang sehingga penyelesaian yang betul ditemui: 1 Pengembangan laluan inferens: Dalam setiap lelaran, LLM asas menjana langkah seterusnya bagi laluan inferens semasa. . 2. Penilaian dan Pemilihan: Gunakan PRM untuk menilai langkah yang dihasilkan dan pilih laluan penaakulan untuk lelaran seterusnya berdasarkan penilaian ini. 2.2 Peluasan laluan inferens
, menjadikan laluan pengembangan bernilai penerokaan selanjutnya. Sebaliknya, nilai ganjaran yang rendah menunjukkan bahawa langkah baharu mungkin tidak betul, yang bermaksud bahawa penyelesaian yang mengikut laluan ini mungkin juga salah. Algoritma M* terdiri daripada dua langkah utama, berulang sehingga penyelesaian yang betul ditemui: 1 Pengembangan laluan inferens: Dalam setiap lelaran, LLM asas menjana langkah seterusnya bagi laluan inferens semasa. . 2. Penilaian dan Pemilihan: Gunakan PRM untuk menilai langkah yang dihasilkan dan pilih laluan penaakulan untuk lelaran seterusnya berdasarkan penilaian ini. 2.2 Peluasan laluan inferens
Selepas memilih laluan inferens untuk dilanjutkan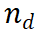 , kami mereka bentuk templat segera (Contoh 3.1) untuk mengumpulkan langkah seterusnya daripada LLM. Seperti yang ditunjukkan dalam contoh, LLM menganggap soalan asal sebagai {soalan} dan laluan penaakulan semasa sebagai {answer}. Ambil perhatian bahawa dalam lelaran pertama algoritma, nod yang dipilih ialah nod akar yang mengandungi soalan sahaja, jadi {answer} kosong. Untuk laluan inferens
, kami mereka bentuk templat segera (Contoh 3.1) untuk mengumpulkan langkah seterusnya daripada LLM. Seperti yang ditunjukkan dalam contoh, LLM menganggap soalan asal sebagai {soalan} dan laluan penaakulan semasa sebagai {answer}. Ambil perhatian bahawa dalam lelaran pertama algoritma, nod yang dipilih ialah nod akar yang mengandungi soalan sahaja, jadi {answer} kosong. Untuk laluan inferens  , LLM menjana N langkah perantaraan dan menambahkannya sebagai anak nod semasa. Dalam langkah seterusnya algoritma, nod anak yang baru dijana ini dinilai dan nod baharu dipilih untuk pengembangan selanjutnya. Kami juga menyedari bahawa cara lain untuk menjana langkah ialah memperhalusi LLM menggunakan penanda langkah. Walau bagaimanapun, ini mungkin mengurangkan keupayaan inferens LLM, dan yang lebih penting, ia bertentangan dengan fokus artikel ini - untuk meningkatkan keupayaan inferens LLM tanpa mengubah suai pemberat. . Seperti yang dinyatakan sebelum ini, PRM mengambil laluan dan langkah , dan mengembalikan nilai ganjaran yang sepadan. Selepas penilaian, kami memerlukan algoritma carian pokok untuk memilih nod seterusnya untuk dikembangkan. Rangka kerja kami tidak bergantung pada algoritma carian tertentu, dan dalam kerja ini kami menggunakan dua kaedah carian terbaik pertama, iaitu Beam Search dan Levin Tree Search. 3. Keputusan dan Perbincangan Penilaian yang meluas pada set data GSM8K dan MATH menunjukkan bahawa M* meningkatkan keupayaan inferens bagi model sumber terbuka (seperti yang serupa), kerana model sumber terbuka (seperti2) kepada Ia adalah setanding dengan model sumber tertutup yang lebih besar (seperti GPT-3.5 dan Grok-1), sambil mengurangkan saiz model dan kos pengiraan dengan ketara. Penemuan ini menyerlahkan potensi mengalihkan sumber pengiraan daripada penalaan halus kepada carian masa inferens, membuka jalan baharu untuk penyelidikan masa hadapan ke dalam teknik peningkatan inferens yang cekap. Jadual 1 menunjukkan hasil perbandingan pelbagai skema pada penanda aras inferens GSM8K dan MATH. Nombor untuk setiap entri menunjukkan peratusan masalah yang diselesaikan. Notasi SC@32 mewakili ketekalan diri antara 32 keputusan calon, manakala n-shot mewakili keputusan pada contoh beberapa pukulan. CoT-SC@16 merujuk kepada ketekalan diri di kalangan 16 keputusan calon Rantaian Pemikiran (CoT). BS@16 mewakili kaedah carian rasuk, yang melibatkan 16 keputusan calon pada setiap peringkat langkah, manakala LevinTS@16 memperincikan kaedah carian pokok Levin menggunakan bilangan keputusan calon yang sama. Perlu diingat bahawa keputusan terkini untuk GPT-4 pada set data MATH ialah GPT-4-turbo-0409, yang kami tekankan terutamanya kerana ia mewakili prestasi terbaik di kalangan keluarga GPT-4.
, LLM menjana N langkah perantaraan dan menambahkannya sebagai anak nod semasa. Dalam langkah seterusnya algoritma, nod anak yang baru dijana ini dinilai dan nod baharu dipilih untuk pengembangan selanjutnya. Kami juga menyedari bahawa cara lain untuk menjana langkah ialah memperhalusi LLM menggunakan penanda langkah. Walau bagaimanapun, ini mungkin mengurangkan keupayaan inferens LLM, dan yang lebih penting, ia bertentangan dengan fokus artikel ini - untuk meningkatkan keupayaan inferens LLM tanpa mengubah suai pemberat. . Seperti yang dinyatakan sebelum ini, PRM mengambil laluan dan langkah , dan mengembalikan nilai ganjaran yang sepadan. Selepas penilaian, kami memerlukan algoritma carian pokok untuk memilih nod seterusnya untuk dikembangkan. Rangka kerja kami tidak bergantung pada algoritma carian tertentu, dan dalam kerja ini kami menggunakan dua kaedah carian terbaik pertama, iaitu Beam Search dan Levin Tree Search. 3. Keputusan dan Perbincangan Penilaian yang meluas pada set data GSM8K dan MATH menunjukkan bahawa M* meningkatkan keupayaan inferens bagi model sumber terbuka (seperti yang serupa), kerana model sumber terbuka (seperti2) kepada Ia adalah setanding dengan model sumber tertutup yang lebih besar (seperti GPT-3.5 dan Grok-1), sambil mengurangkan saiz model dan kos pengiraan dengan ketara. Penemuan ini menyerlahkan potensi mengalihkan sumber pengiraan daripada penalaan halus kepada carian masa inferens, membuka jalan baharu untuk penyelidikan masa hadapan ke dalam teknik peningkatan inferens yang cekap. Jadual 1 menunjukkan hasil perbandingan pelbagai skema pada penanda aras inferens GSM8K dan MATH. Nombor untuk setiap entri menunjukkan peratusan masalah yang diselesaikan. Notasi SC@32 mewakili ketekalan diri antara 32 keputusan calon, manakala n-shot mewakili keputusan pada contoh beberapa pukulan. CoT-SC@16 merujuk kepada ketekalan diri di kalangan 16 keputusan calon Rantaian Pemikiran (CoT). BS@16 mewakili kaedah carian rasuk, yang melibatkan 16 keputusan calon pada setiap peringkat langkah, manakala LevinTS@16 memperincikan kaedah carian pokok Levin menggunakan bilangan keputusan calon yang sama. Perlu diingat bahawa keputusan terkini untuk GPT-4 pada set data MATH ialah GPT-4-turbo-0409, yang kami tekankan terutamanya kerana ia mewakili prestasi terbaik di kalangan keluarga GPT-4.
Rajah 3 Kami mengkaji bagaimana prestasi M* berubah apabila bilangan calon peringkat langkah berubah. Kami memilih Llama-2-13B sebagai model asas dan carian rasuk (BS) sebagai algoritma carian, masing-masing.  Rajah 4 Penskalaan undang-undang keluarga model Llama-2 dan Llama-3 pada set data MATH. Semua keputusan diperoleh daripada sumber asalnya. Kami menggunakan alat Scipy dan fungsi logaritma untuk mengira lengkung yang dipasang.
Rajah 4 Penskalaan undang-undang keluarga model Llama-2 dan Llama-3 pada set data MATH. Semua keputusan diperoleh daripada sumber asalnya. Kami menggunakan alat Scipy dan fungsi logaritma untuk mengira lengkung yang dipasang.
Jadual 2 Purata bilangan token yang dihasilkan dengan kaedah berbeza semasa menjawab soalanMakalah ini memperkenalkan MindStar (M*), rangka kerja penaakulan berasaskan pencarian yang baru. model bahasa besar yang telah dilatih sebelumnya. Dengan menganggap tugas inferens sebagai masalah carian dan memanfaatkan model ganjaran penyeliaan proses, M* menavigasi dengan cekap dalam ruang pokok inferens, mengenal pasti laluan yang hampir optimum. Menggabungkan idea carian rasuk dan carian pokok Levin meningkatkan lagi kecekapan carian dan memastikan laluan penaakulan terbaik boleh ditemui dalam kerumitan pengiraan yang terhad. Keputusan percubaan yang meluas menunjukkan bahawa M* meningkatkan keupayaan inferens model sumber terbuka dengan ketara, dan prestasinya adalah setanding dengan model sumber tertutup yang lebih besar, sambil mengurangkan saiz model dan kos pengiraan dengan ketara. Hasil penyelidikan ini menunjukkan bahawa mengalihkan sumber pengkomputeran daripada penalaan halus kepada carian masa inferens mempunyai potensi besar, membuka jalan baharu untuk penyelidikan masa depan tentang teknologi peningkatan inferens yang cekap. [1] Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radiford, Dario F Amomari dengan maklum balas manusia. Kemajuan dalam Sistem Pemprosesan Maklumat Neural, 33:3008–3021, 2020.[2] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Zhang Mishkin, Sandhini, Chong Agarwal, Katarina Slama, Alex Ray, et al. Melatih model bahasa untuk mengikuti arahan dengan maklum balas manusia Kemajuan dalam sistem pemprosesan maklumat saraf, 35:27730–27744, 2022. [3] Ziyang Luo, Can Xu. , Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin dan Daxin Jiang Wizardcoder: Memperkasakan model bahasa besar dengan evol-instruct arXiv:2306.08568, . [4] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al pracetak arXiv:2107.03374, 2021.[5] Carlos Gómez-Rodríguez dan Paul Williams Gabungan model: Penilaian komprehensif llms pada penulisan kreatif. [6] Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller dan Weiyang Liu: Bootstrap soalan matematik anda sendiri untuk model bahasa besar pracetak arXiv:2309.12284, 2023. [7] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, YK Li, Y Wu, dan Deep Daya Gumakoth penaakulan matematik dalam model bahasa terbuka arXiv pracetak arXiv:2402.03300, 2024.[8] Keiran Paster, Marco Dos Santos, Zhangir Azerbayev dan Jimmy Ba dengan set data web terbuka berkualiti tinggi . arXiv pracetak arXiv:2310.06786, 2023.[9] Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Yi Wu Sheng,. Sahkan dan kuatkan llms langkah demi langkah tanpa anotasi manusia, abs/2312.08935, 2023.[10] Meta AI Memperkenalkan meta llama 3: .24 April yang paling berkebolehan. URL https://ai.meta.com/blog/meta-llama-3/ Diakses: 2024-04-30.
Atas ialah kandungan terperinci Tidak sabar untuk OpenAI's Q*, senjata rahsia Huawei Noah MindStar untuk meneroka penaakulan LLM ada di sini dahulu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!




 , LLM menjana N langkah perantaraan dan menambahkannya sebagai anak nod semasa. Dalam langkah seterusnya algoritma, nod anak yang baru dijana ini dinilai dan nod baharu dipilih untuk pengembangan selanjutnya. Kami juga menyedari bahawa cara lain untuk menjana langkah ialah memperhalusi LLM menggunakan penanda langkah. Walau bagaimanapun, ini mungkin mengurangkan keupayaan inferens LLM, dan yang lebih penting, ia bertentangan dengan fokus artikel ini - untuk meningkatkan keupayaan inferens LLM tanpa mengubah suai pemberat. . Seperti yang dinyatakan sebelum ini, PRM mengambil laluan dan langkah , dan mengembalikan nilai ganjaran yang sepadan. Selepas penilaian, kami memerlukan algoritma carian pokok untuk memilih nod seterusnya untuk dikembangkan. Rangka kerja kami tidak bergantung pada algoritma carian tertentu, dan dalam kerja ini kami menggunakan dua kaedah carian terbaik pertama, iaitu Beam Search dan Levin Tree Search.
, LLM menjana N langkah perantaraan dan menambahkannya sebagai anak nod semasa. Dalam langkah seterusnya algoritma, nod anak yang baru dijana ini dinilai dan nod baharu dipilih untuk pengembangan selanjutnya. Kami juga menyedari bahawa cara lain untuk menjana langkah ialah memperhalusi LLM menggunakan penanda langkah. Walau bagaimanapun, ini mungkin mengurangkan keupayaan inferens LLM, dan yang lebih penting, ia bertentangan dengan fokus artikel ini - untuk meningkatkan keupayaan inferens LLM tanpa mengubah suai pemberat. . Seperti yang dinyatakan sebelum ini, PRM mengambil laluan dan langkah , dan mengembalikan nilai ganjaran yang sepadan. Selepas penilaian, kami memerlukan algoritma carian pokok untuk memilih nod seterusnya untuk dikembangkan. Rangka kerja kami tidak bergantung pada algoritma carian tertentu, dan dalam kerja ini kami menggunakan dua kaedah carian terbaik pertama, iaitu Beam Search dan Levin Tree Search.  Apakah perisian anti-virus?
Apakah perisian anti-virus?
 Platform mata wang digital domestik
Platform mata wang digital domestik
 Bagaimana untuk mengkonfigurasi pembolehubah persekitaran Tomcat
Bagaimana untuk mengkonfigurasi pembolehubah persekitaran Tomcat
 Apakah maksud c#?
Apakah maksud c#?
 Bagaimana untuk memulihkan fail yang dipadam secara kekal pada komputer
Bagaimana untuk memulihkan fail yang dipadam secara kekal pada komputer
 Bagaimana untuk membuka fail html pada telefon bimbit
Bagaimana untuk membuka fail html pada telefon bimbit
 Kaedah pemulihan pangkalan data Oracle
Kaedah pemulihan pangkalan data Oracle
 Bagaimana untuk menyelesaikan masalah semasa menghuraikan pakej
Bagaimana untuk menyelesaikan masalah semasa menghuraikan pakej








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



