Gemma 2 dengan prestasi dua kali ganda, bagaimana untuk bermain Llama 3 dengan tahap yang sama?
Di landasan AI, gergasi teknologi bersaing hebat. GPT-4o keluar di kaki hadapan, dan Claude 3.5 Sonnet muncul di kaki belakang. Dalam pertempuran yang begitu sengit, walaupun Google melancarkan usahanya lewat, ia mempunyai keupayaan yang ketara untuk membuat susulan dalam tempoh yang singkat, yang menunjukkan potensinya untuk pembangunan teknologi dan inovasi. Selain model Gemini, Gemma, siri model terbuka SOTA yang ringan, nampaknya lebih dekat dengan kami. Ia dibina berdasarkan penyelidikan dan teknologi yang sama seperti model Gemini dan bertujuan untuk memberi semua orang alat untuk membina AI. Google terus mengembangkan keluarga Gemma untuk memasukkan CodeGemma, RecurrentGemma dan PaliGemma—setiap model menawarkan keupayaan unik untuk tugas AI yang berbeza dan mudah diakses melalui rakan kongsi seperti Hugging Face, NVIDIA dan Ollama. 
Kini, keluarga Gemma mengalu-alukan ahli baru - Gemma 2, meneruskan tradisi pendek dan ringkas. Dua versi parameter 9 bilion (9B) dan 27 bilion (27B) yang disediakan oleh Gemma 2 kali ini mempunyai prestasi dan kecekapan inferens yang lebih baik daripada generasi pertama, dan mempunyai peningkatan keselamatan yang ketara. Malah, versi parameter 27 bilion boleh bersaing pada tahap yang sama dengan model yang lebih daripada dua kali saiz dan memberikan prestasi yang sebelum ini hanya dicapai oleh model proprietari yang kini boleh dicapai pada satu NVIDIA H100 Tensor Core GPU atau TPU Dilaksanakan pada hos, sekali gus mengurangkan kos penggunaan. 
Pasukan Google membina Gemma 2 pada seni bina yang direka bentuk semula, membolehkan ahli baharu keluarga Gemma ini memberikan prestasi cemerlang dan keupayaan inferens yang cekap. Untuk meringkaskan secara ringkas, prestasi, kos, inferens ialah ciri-ciri cemerlangnya:
- Prestasi cemerlang: Model Gemma 2 27B menawarkan prestasi terbaik dalam kategori volumnya, malah bersaing dengan model lebih daripada dua kali ganda persaingan Model saiznya. Model 9B Gemma 2 juga berprestasi baik dalam kategori saiznya dan mengatasi prestasi Llama 3 8B dan model terbuka setanding yang lain.
- Kecekapan tinggi, kos rendah: Model 27B Gemma 2 direka untuk menjalankan inferens dengan cekap pada ketepatan penuh pada hos TPU Google Cloud tunggal, GPU Teras Tensor NVIDIA A100 80GB atau GPU Teras Tensor NVIDIA H100, sambil mengekalkan prestasi tinggi Mengurangkan kos secara mendadak. Ini menjadikan penggunaan AI lebih mudah dan berpatutan.
- Inferens ultra-pantas: Gemma 2 dioptimumkan untuk berjalan pada kelajuan tinggi pada pelbagai perkakasan, sama ada komputer riba permainan yang berkuasa, desktop mewah atau persediaan berasaskan awan. Pengguna boleh cuba menjalankan Gemma 2 pada ketepatan penuh pada Google AI Studio, atau menggunakan versi terkuantiti Gemma.cpp pada CPU untuk membuka kunci prestasi tempatan, atau mencubanya pada komputer rumah menggunakan NVIDIA RTX atau GeForce RTX melalui Hugging Face Transformers.

Di atas adalah perbandingan data skor antara Gemma2, Llama3 dan Grok-1.
Malah, berdasarkan pelbagai data skor, kelebihan model besar 9B sumber terbuka tidak begitu ketara. Model domestik yang besar GLM-4-9B, yang sumber terbuka oleh Zhipu AI hampir sebulan yang lalu, mempunyai lebih banyak kelebihan.

Selain itu, Gemma 2 bukan sahaja lebih berkuasa, tetapi juga direka bentuk agar lebih mudah untuk disepadukan ke dalam aliran kerja. Google memberi lebih banyak kemungkinan kepada pembangun untuk membina dan menggunakan penyelesaian AI dengan lebih mudah.
- Terbuka dan boleh diakses: Seperti model Gemma asal, Gemma 2 membenarkan pembangun dan penyelidik berkongsi dan mengkomersialkan inovasi.
- Keserasian rangka kerja yang luas: Gemma 2 serasi dengan rangka kerja AI utama seperti Hugging Face Transformers, serta JAX, PyTorch dan TensorFlow yang disokong secara asli melalui Keras 3.0, vLLM, Gemma.cpp, Llama.cpp dan Ollama, menjadikannya Sepadukan dengan mudah dengan alatan dan aliran kerja pilihan pengguna. Selain itu, Gemma telah dioptimumkan dengan NVIDIA TensorRT-LLM dan boleh dijalankan pada infrastruktur dipercepatkan NVIDIA atau sebagai perkhidmatan mikro inferens NVIDIA NIM Ia juga akan dioptimumkan untuk NeMo NVIDIA pada masa hadapan dan boleh diperhalusi menggunakan Keras dan Hugging Face. Selain itu, Google sedang giat meningkatkan keupayaan penalaan halus.
- Pengedaran Mudah: Mulai bulan depan, pelanggan Google Cloud akan dapat menggunakan dan mengurus Gemma 2 dengan mudah pada Vertex AI.
Google juga menawarkan Buku Masakan Gemma baharu, satu siri contoh dan panduan praktikal yang direka untuk membantu pengguna membina aplikasi mereka sendiri dan memperhalusi model Gemma 2 untuk tugasan tertentu. Pautan Buku Masakan Gemma: https://github.com/google-gemini/gemma-cookbookPada masa yang sama, Google turut menyediakan pemaju produk rasmi yang diumumkan pada persidangan I/O beberapa masa lalu. 2 juta akses tetingkap konteks Gemini 1.5 Pro, keupayaan pelaksanaan kod untuk API Gemini dan penambahan Gemma 2 dalam Google AI Studio.
- Dalam blog terbaharu, Google mengumumkan bahawa ia telah membuka akses tetingkap konteks token 2 juta Gemini 1.5 Pro kepada semua pembangun. Walau bagaimanapun, apabila tetingkap konteks meningkat, kos input juga mungkin meningkat. Untuk membantu pembangun mengurangkan kos berbilang tugasan segera menggunakan token yang sama, Google dengan teliti melancarkan fungsi caching konteks dalam API Gemini untuk Gemini 1.5 Pro dan 1.5 Flash.
- Untuk menyelesaikan masalah yang model bahasa besar perlu menjana dan melaksanakan kod untuk meningkatkan ketepatan semasa memproses matematik atau penaakulan data, Google telah mendayakan pelaksanaan kod dalam Gemini 1.5 Pro dan 1.5 Flash. Apabila dihidupkan, model boleh menjana dan menjalankan kod Python secara dinamik dan belajar secara berulang daripada keputusan sehingga output akhir yang dikehendaki dicapai. Kotak pasir pelaksanaan tidak disambungkan ke Internet dan disertakan standard dengan beberapa pustaka berangka hanya perlu dibilkan berdasarkan token keluaran model. Ini adalah kali pertama Google memperkenalkan pelaksanaan kod sebagai langkah dalam fungsi model, tersedia hari ini melalui API Gemini dan Tetapan Lanjutan dalam Google AI Studio.
- Google mahu menjadikan AI boleh diakses oleh semua pembangun, sama ada menyepadukan model Gemini melalui kunci API atau menggunakan model terbuka Gemma 2. Untuk membantu pembangun mendapatkan model Gemma 2, pasukan Google akan menyediakannya untuk percubaan dalam Google AI Studio.
Berikut ialah laporan percubaan teknikal Gemma2 Kami boleh menganalisis butiran teknikal secara mendalam dari pelbagai sudut.
- Alamat kertas: https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf
- Alamat blog: https://blog.google/ teknologi/pembangun/google-gemma-2/
Sama seperti model Gemma sebelumnya, model Gemma 2 juga berasaskan seni bina pengubah. Jadual 1 meringkaskan parameter utama dan pilihan seni bina model. Sesetengah elemen struktur adalah serupa dengan versi pertama model Gemma, iaitu panjang konteks ialah 8192 token, penggunaan benam kedudukan diputar (RoPE) dan anggaran ketaklinearan GeGLU. Gemma 1 dan Gemma 2 mempunyai beberapa perbezaan, termasuk penggunaan rangkaian yang lebih dalam. Perbezaan utama diringkaskan seperti berikut:
- Tetingkap gelongsor tempatan dan perhatian global. Pasukan penyelidik bergantian menggunakan perhatian tingkap gelongsor tempatan dan perhatian global dalam setiap lapisan lain. Saiz tetingkap gelongsor lapisan perhatian tempatan ditetapkan kepada 4096 token, manakala rentang lapisan perhatian global ditetapkan kepada 8192 token.
- Logit soft cap. Mengikut kaedah Gemini 1.5, pasukan penyelidik mengehadkan logit pada setiap lapisan perhatian dan lapisan akhir supaya nilai logit kekal antara −soft_cap dan +soft_cap.
- Untuk model 9B dan 27B, pasukan penyelidik menetapkan had logaritma perhatian kepada 50.0 dan had logaritma akhir kepada 30.0. Pada masa penerbitan, attention logit soft capping tidak serasi dengan pelaksanaan FlashAttention biasa, jadi mereka telah mengalih keluar ciri ini daripada pustaka yang menggunakan FlashAttention. Pasukan penyelidik menjalankan eksperimen ablasi pada penjanaan model dengan dan tanpa perhatian logit soft capping, dan mendapati bahawa kualiti penjanaan hampir tidak terjejas dalam kebanyakan pra-latihan dan pasca penilaian. Semua penilaian dalam kertas ini menggunakan seni bina model penuh termasuk perhatian logit soft capping. Walau bagaimanapun, beberapa prestasi hiliran mungkin masih terjejas sedikit oleh pengalihan keluar ini.
- Gunakan RMSNorm untuk post-norm dan pre-norm. Untuk menstabilkan latihan, pasukan penyelidik menggunakan RMSNorm untuk menormalkan input dan output setiap sub-lapisan transformasi, lapisan perhatian dan lapisan suapan ke hadapan.
- Tanya perhatian dalam kumpulan. Kedua-dua model 27B dan 9B menggunakan GQA, num_groups = 2, dan eksperimen berasaskan ablasi menunjukkan kelajuan inferens yang lebih baik sambil mengekalkan prestasi hiliran.
Google menyediakan gambaran ringkas tentang bahagian pra-latihan yang berbeza daripada Gemma 1. Mereka melatih Gemma 2 27B pada 13 trilion token, terutamanya data Bahasa Inggeris, melatih model 9B pada 8 trilion token, dan melatih model 2.6B pada 2 trilion kereta api. Token ini datang daripada pelbagai sumber data, termasuk dokumen web, kod dan artikel saintifik. Model ini bukan multimodal, dan juga tidak dilatih secara khusus untuk keupayaan berbilang bahasa terkini. Campuran data akhir ditentukan melalui kajian ablasi yang serupa dengan Gemini 1.0. Pasukan penyelidik menggunakan TPUv4, TPUv5e dan TPUv5p untuk latihan model ditunjukkan dalam Jadual 3 di bawah. Dalam pasca latihan, Google memperhalusi model yang telah dilatih menjadi model yang ditala arahan.
- Pertama, gunakan penyeliaan penalaan halus (SFT) pada campuran teks biasa, sintesis Bahasa Inggeris tulen dan pasangan tindak balas segera yang dijana secara buatan.
- Kemudian, pembelajaran pengukuhan berdasarkan model ganjaran (RLHF) digunakan pada model ini Model ganjaran dilatih pada data keutamaan bahasa Inggeris tulen berasaskan token, dan strategi menggunakan gesaan yang sama seperti peringkat SFT.
- Akhir sekali, tingkatkan prestasi keseluruhan dengan membuat purata model yang diperolehi pada setiap peringkat. Kaedah pencampuran data akhir dan selepas latihan, termasuk hiperparameter yang ditala, dipilih berdasarkan meminimumkan bahaya model yang berkaitan dengan keselamatan dan halusinasi sambil meningkatkan kegunaan model.
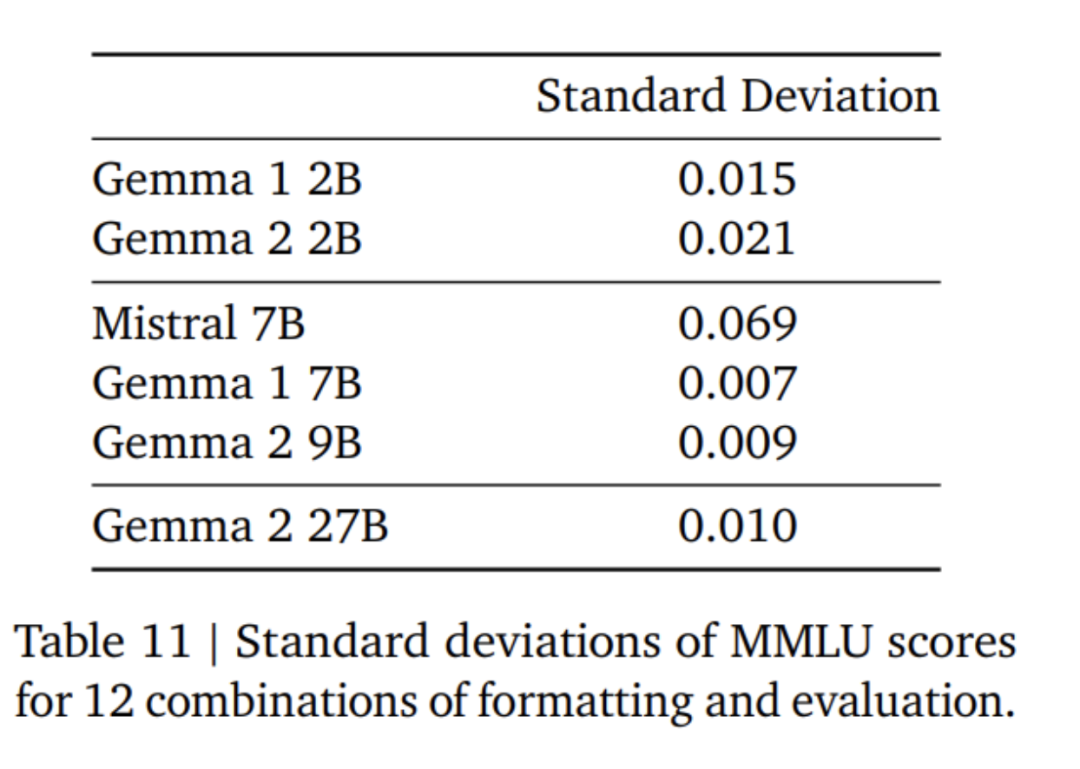
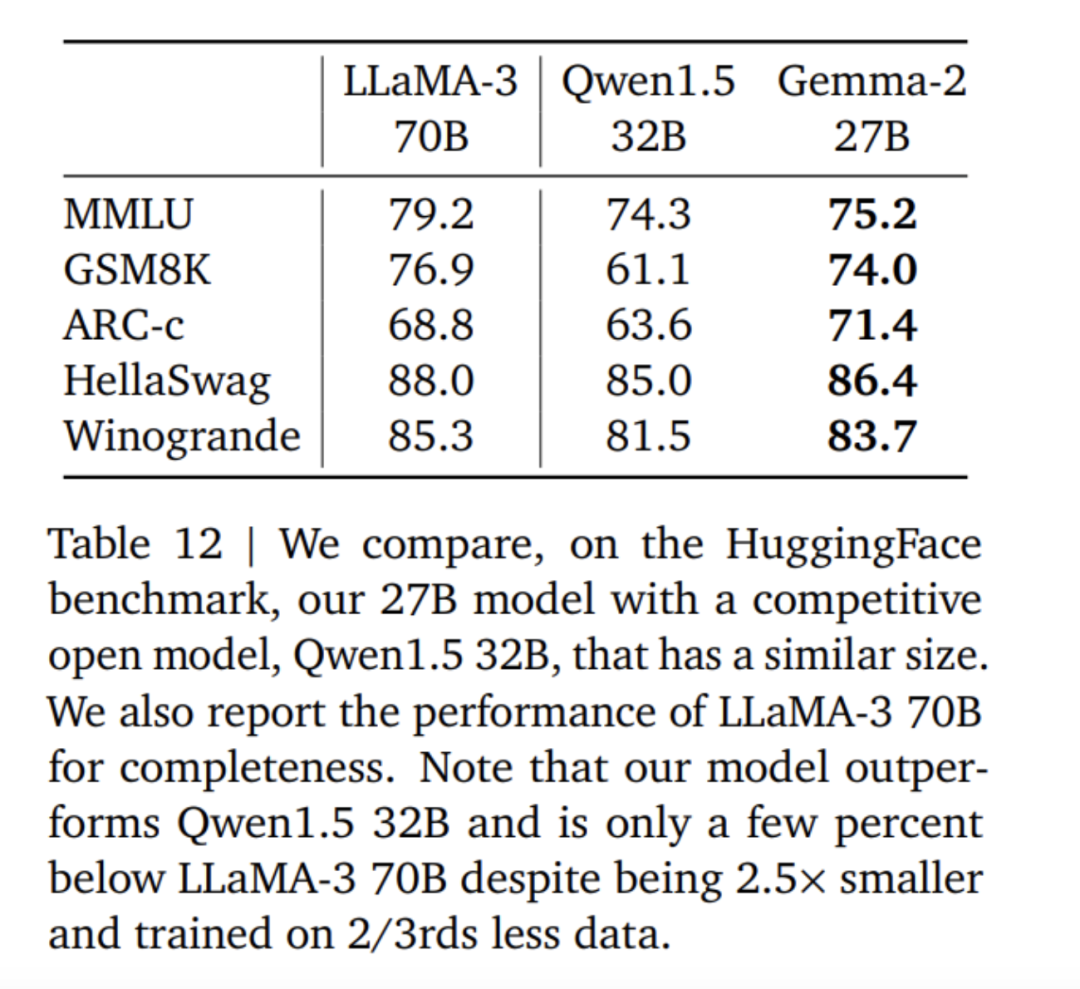
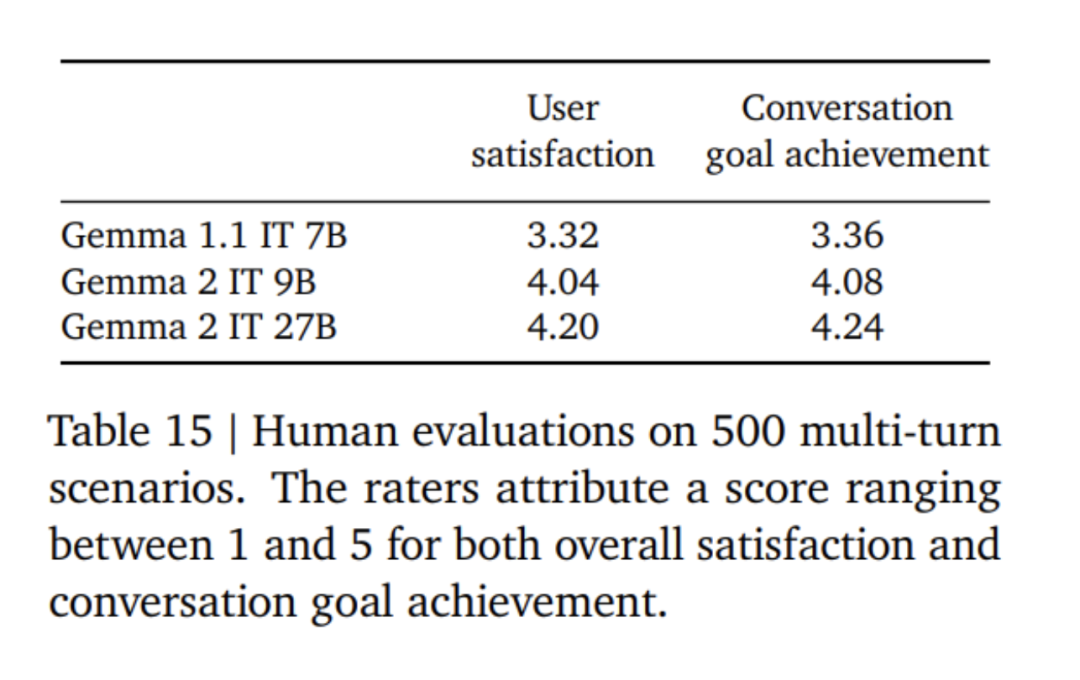
Penalaan halus model Gemma 2 menggunakan mod format yang berbeza daripada model Gemma 1. Google menggunakan token kawalan yang sama seperti yang diterangkan dalam Jadual 4, dan contoh perbualan disediakan dalam Jadual 5. Dalam Jadual 6 dapat dilihat bahawa menapis keputusan daripada model yang lebih besar meningkatkan prestasi. Perlu diingatkan bahawa token 500B adalah 10 kali ganda bilangan optimum token yang dikira untuk model 2.6B. Pasukan penyelidik melakukan penyulingan daripada model 7B untuk mengekalkan nisbah yang sama seperti penyulingan daripada model 27B kepada model 9B. Dalam Jadual 7, pasukan Google mengukur kesan penyulingan apabila saiz model bertambah. Dapat diperhatikan bahawa keuntungan ini berterusan apabila saiz model meningkat. Dalam eksperimen ablasi ini, pasukan penyelidik mengekalkan saiz model guru pada 7B dan melatih model yang lebih kecil untuk mensimulasikan jurang antara saiz model guru dan pelajar akhir. Di samping itu, Google mengambil kira kesan perubahan format segera/penilaian dan mengukur varians prestasi pada MMLU, seperti ditunjukkan dalam Jadual 11. Model Gemma 2B sedikit lebih rendah daripada model yang lebih besar dari segi keteguhan format. Perlu diingat bahawa Mistral 7B jauh lebih rendah daripada model siri Gemma dari segi kekukuhan. Pasukan penyelidik juga menilai prestasi model 27B yang dilatih menggunakan 13 trilion token (tanpa penyulingan) dan membandingkannya dengan model Qwen1.5 34B bersaiz sama dan 2.5 kali lebih besar LLaMA-3 70 daripada model pada suite penilaian HuggingFace telah dibandingkan, dan keputusan penilaian disenaraikan dalam Jadual 12. Model dipilih berdasarkan kedudukan mereka pada papan pendahulu HuggingFace. Secara keseluruhannya, model Gemma-2 27B menunjukkan prestasi terbaik dalam kategori saiznya malah boleh bersaing dengan model yang lebih besar yang mengambil masa lebih lama untuk dilatih. Model penalaan halus arahan Gemma-2 27B dan 9B dinilai secara membuta tuli dalam Chatbot Arena oleh penilai manusia berbanding model SOTA yang lain. Pasukan penyelidik melaporkan skor ELO dalam Rajah 1. Selain itu, pasukan penyelidik menilai keupayaan dialog berbilang pusingan model Gemma 1.1 7B, Gemma 2 9B dan 27B dengan meminta penilai manusia bercakap dengan model dan mengikuti senario yang ditetapkan untuk ujian. Google menggunakan set pemegangan yang pelbagai bagi 500 senario, setiap satu menerangkan satu siri permintaan untuk model, termasuk sumbang saran, membuat rancangan atau mempelajari sesuatu yang baharu. Purata bilangan interaksi pengguna ialah 8.4. Akhirnya, didapati bahawa berbanding dengan Gemma 1.1, pengguna menilai kepuasan dialog model Gemma 2 dan kadar pencapaian matlamat dialog sebagai lebih tinggi dengan ketara (lihat Jadual 15). Selain itu, model Gemma 2 lebih mampu mengekalkan respons berkualiti tinggi dari permulaan perbualan hingga pusingan seterusnya berbanding model Gemma 1.1 7B. Untuk butiran lanjut, sila baca kertas asal. Atas ialah kandungan terperinci 'Kerja ikhlas' Google, sumber terbuka 9B dan 27B versi Gemma2, memfokuskan pada kecekapan dan ekonomi!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



























![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



