


Dengan itu, kami telah mencipta panduan langkah demi langkah tentang cara menggunakan Text-Generation-WebUI untuk memuatkan Llama 2 LLM terkuantasi secara setempat pada komputer anda.
Terdapat banyak sebab mengapa orang memilih untuk menjalankan Llama 2 secara langsung. Sesetengah melakukannya untuk kebimbangan privasi, beberapa untuk penyesuaian dan yang lain untuk keupayaan luar talian. Jika anda sedang menyelidik, memperhalusi atau menyepadukan Llama 2 untuk projek anda, maka mengakses Llama 2 melalui API mungkin bukan untuk anda. Tujuan menjalankan LLM secara tempatan pada PC anda adalah untuk mengurangkan pergantungan pada alatan AI pihak ketiga dan menggunakan AI pada bila-bila masa, di mana-mana sahaja, tanpa perlu risau tentang membocorkan data yang berpotensi sensitif kepada syarikat dan organisasi lain.
Dengan itu, mari kita mulakan dengan panduan langkah demi langkah untuk memasang Llama 2 secara tempatan.
Untuk memudahkan perkara, kami akan menggunakan pemasang satu klik untuk Text-Generation-WebUI (program yang digunakan untuk memuatkan Llama 2 dengan GUI). Walau bagaimanapun, untuk pemasang ini berfungsi, anda perlu memuat turun Alat Binaan Visual Studio 2019 dan memasang sumber yang diperlukan.
Muat turun:Visual Studio 2019 (Percuma)
Teruskan dan muat turun perisian edisi komuniti. Sekarang pasang Visual Studio 2019, kemudian buka perisian. Setelah dibuka, tandakan kotak pada pembangunan Desktop dengan C++ dan tekan pasang.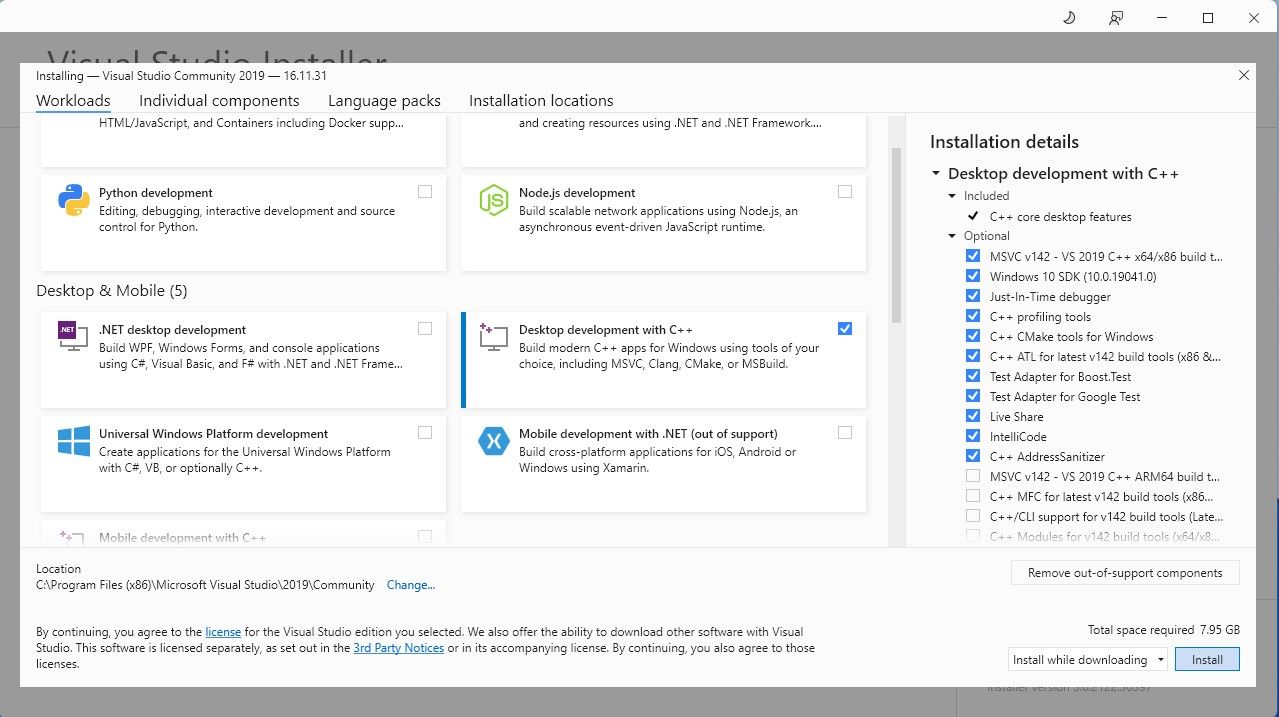
Kini setelah anda mempunyai pembangunan Desktop dengan C++ dipasang, tiba masanya untuk memuat turun pemasang satu klik Text-Generation-WebUI.
Pemasang satu klik Text-Generation-WebUI ialah skrip yang mencipta folder yang diperlukan secara automatik dan menyediakan persekitaran Conda dan semua keperluan yang diperlukan untuk menjalankan model AI.
Untuk memasang skrip, muat turun pemasang satu klik dengan mengklik pada Kod > Muat turun ZIP.
Muat turun:Text-Generation-WebUI Installer (Percuma)
Setelah dimuat turun, ekstrak fail ZIP ke lokasi pilihan anda, kemudian buka folder yang diekstrak. Dalam folder, tatal ke bawah dan cari program permulaan yang sesuai untuk sistem pengendalian anda. Jalankan program dengan mengklik dua kali pada skrip yang sesuai. Jika anda menggunakan Windows, pilih start_windows batch file untuk MacOS, pilih start_macos shell scrip untuk Linux, start_linux shell script.
Anti-virus anda mungkin mencipta amaran; ini baik. Gesaan itu hanyalah positif palsu antivirus untuk menjalankan fail atau skrip kelompok. Klik pada Run anyway. Terminal akan dibuka dan memulakan persediaan. Pada awalnya, persediaan akan dijeda dan bertanyakan GPU yang anda gunakan. Pilih jenis GPU yang sesuai dipasang pada komputer anda dan tekan enter. Bagi mereka yang tidak mempunyai kad grafik khusus, pilih Tiada (Saya mahu menjalankan model dalam mod CPU). Perlu diingat bahawa berjalan pada mod CPU adalah jauh lebih perlahan jika dibandingkan dengan menjalankan model dengan GPU khusus.
 Setelah persediaan selesai, anda kini boleh melancarkan Text-Generation-WebUI secara tempatan. Anda boleh berbuat demikian dengan membuka penyemak imbas web pilihan anda dan memasukkan alamat IP yang disediakan pada URL.
Setelah persediaan selesai, anda kini boleh melancarkan Text-Generation-WebUI secara tempatan. Anda boleh berbuat demikian dengan membuka penyemak imbas web pilihan anda dan memasukkan alamat IP yang disediakan pada URL. WebUI kini sedia untuk digunakan.
WebUI kini sedia untuk digunakan.
Walau bagaimanapun, program ini hanyalah pemuat model. Mari muat turun Llama 2 untuk pemuat model dilancarkan.
Terdapat beberapa perkara yang perlu dipertimbangkan semasa memutuskan lelaran Llama 2 yang anda perlukan. Ini termasuk parameter, kuantisasi, pengoptimuman perkakasan, saiz dan penggunaan. Semua maklumat ini akan ditemui dalam nama model.
Parameter: Bilangan parameter yang digunakan untuk melatih model. Parameter yang lebih besar menjadikan model yang lebih berkebolehan tetapi pada kos prestasi. Penggunaan: Boleh sama ada standard atau sembang. Model sembang dioptimumkan untuk digunakan sebagai bot sembang seperti ChatGPT, manakala standard ialah model lalai. Pengoptimuman Perkakasan: Merujuk kepada perkakasan yang terbaik menjalankan model. GPTQ bermaksud model dioptimumkan untuk dijalankan pada GPU khusus, manakala GGML dioptimumkan untuk dijalankan pada CPU. Pengkuantitian: Menandakan ketepatan pemberat dan pengaktifan dalam model. Untuk inferens, ketepatan q4 adalah optimum. Saiz: Merujuk kepada saiz model tertentu.Ambil perhatian bahawa sesetengah model mungkin disusun secara berbeza dan mungkin tidak mempunyai jenis maklumat yang sama dipaparkan. Walau bagaimanapun, konvensyen penamaan jenis ini agak biasa dalam perpustakaan Model HuggingFace, jadi ia masih patut difahami.

Dalam contoh ini, model boleh dikenal pasti sebagai model Llama 2 bersaiz sederhana yang dilatih pada 13 bilion parameter yang dioptimumkan untuk inferens sembang menggunakan CPU khusus.
Bagi mereka yang menggunakan GPU khusus, pilih model GPTQ, manakala bagi mereka yang menggunakan CPU, pilih GGML. Jika anda ingin bersembang dengan model seperti yang anda lakukan dengan ChatGPT, pilih sembang, tetapi jika anda ingin mencuba model dengan keupayaan penuhnya, gunakan model standard. Bagi parameter, ketahui bahawa menggunakan model yang lebih besar akan memberikan hasil yang lebih baik dengan mengorbankan prestasi. Saya secara peribadi akan mengesyorkan anda mulakan dengan model 7B. Bagi pengkuantitian, gunakan q4, kerana ia hanya untuk membuat inferens.
Muat Turun:GGML (Percuma)
Muat turun:GPTQ (Percuma)
Kini setelah anda mengetahui lelaran Llama 2 yang anda perlukan, teruskan muat turun model yang anda mahukan.
Dalam kes saya, memandangkan saya menjalankan ini pada ultrabook, saya akan menggunakan model GGML yang diperhalusi untuk sembang, llama-2-7b-chat-ggmlv3.q4_K_S.bin.
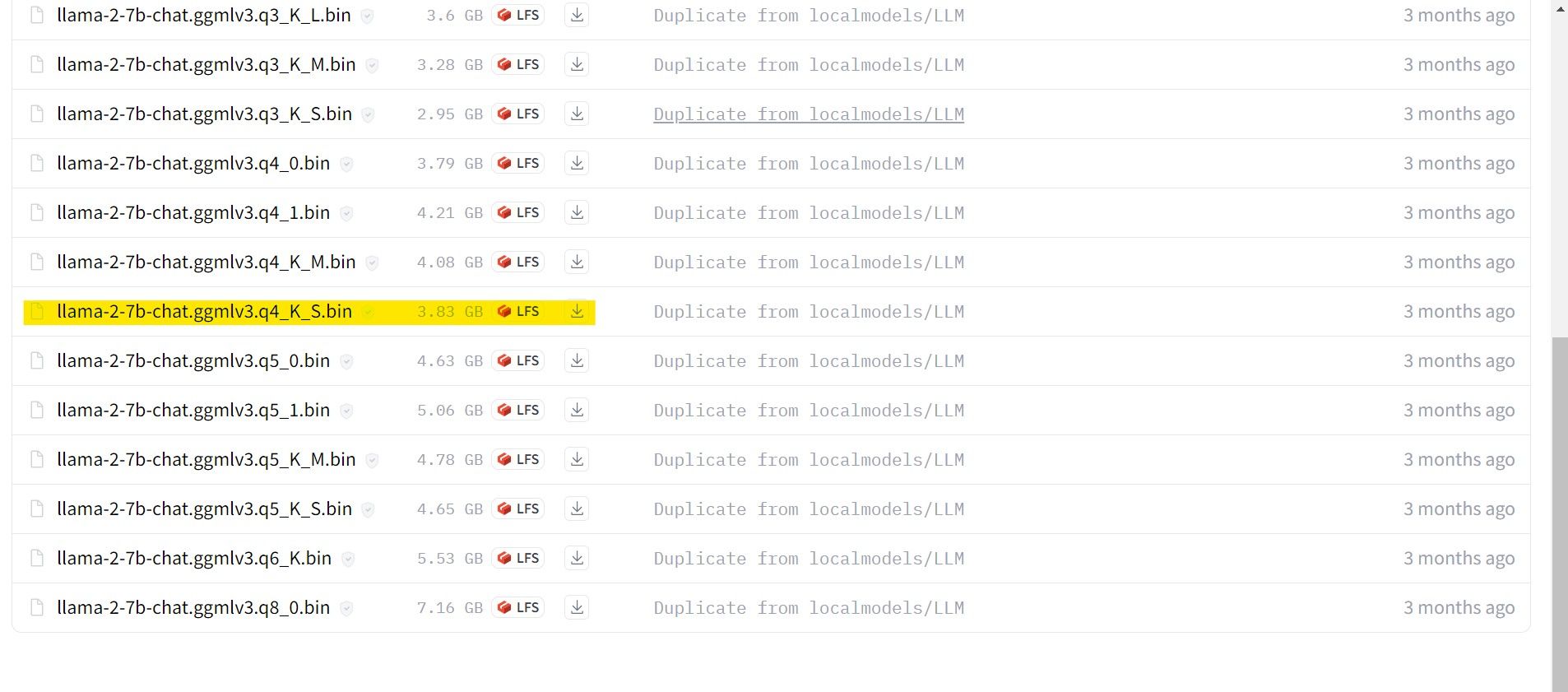
Selepas muat turun selesai, letakkan model dalam text-generation-webui-main > model.

Setelah model anda dimuat turun dan diletakkan dalam folder model, tiba masanya untuk mengkonfigurasi pemuat model.
Sekarang, mari kita mulakan fasa konfigurasi.
Sekali lagi, buka Text-Generation-WebUI dengan menjalankan fail start_(OS anda) (lihat langkah sebelumnya di atas). Pada tab yang terletak di atas GUI, klik Model. Klik butang muat semula pada menu lungsur model dan pilih model anda. Sekarang klik pada menu lungsur turun Pemuat Model dan pilih AutoGPTQ untuk mereka yang menggunakan model GTPQ dan ctransformer untuk mereka yang menggunakan model GGML. Akhir sekali, klik pada Muatkan untuk memuatkan model anda. Untuk menggunakan model, buka tab Sembang dan mula menguji model.
Untuk menggunakan model, buka tab Sembang dan mula menguji model.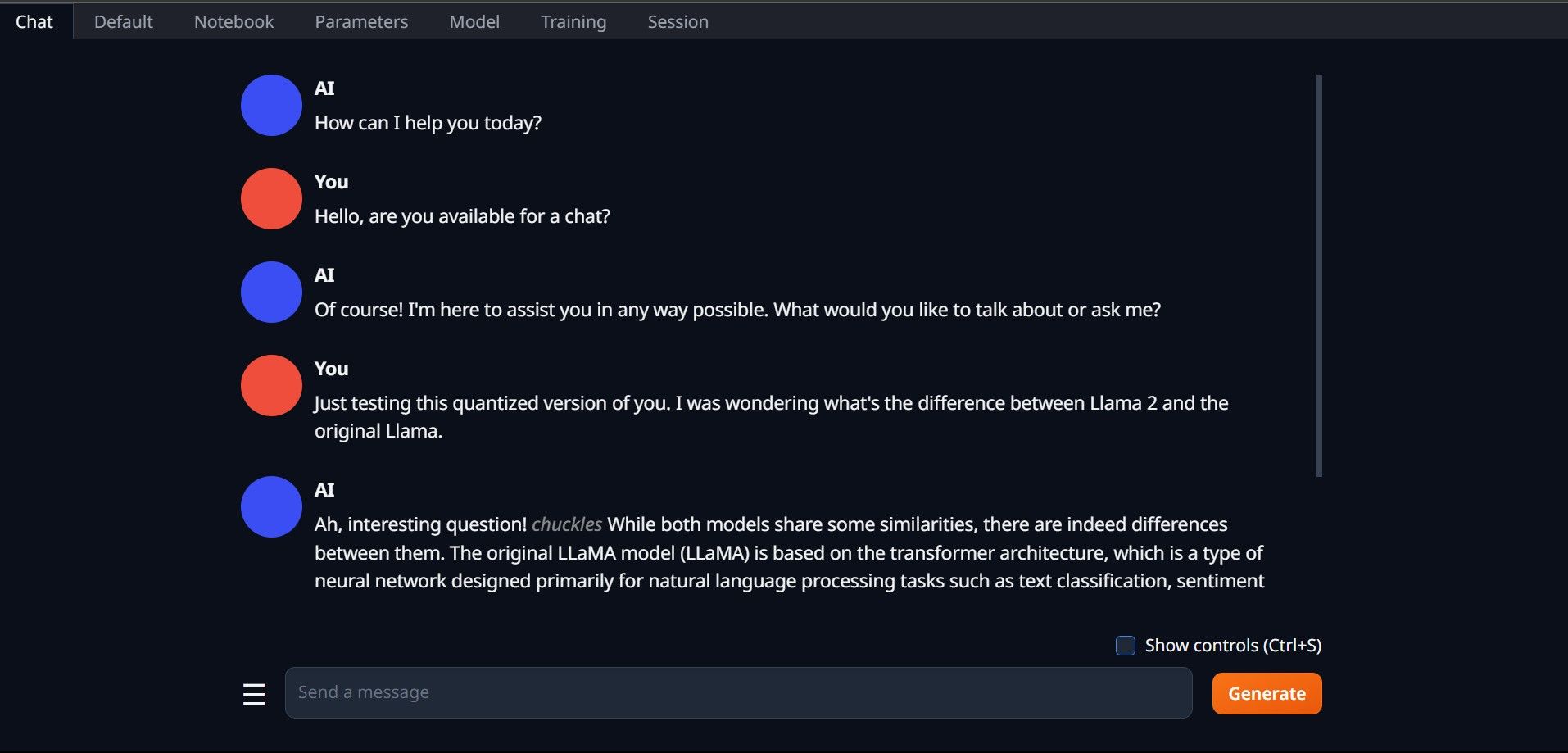
Tahniah, anda telah berjaya memuatkan Llama2 pada komputer tempatan anda!
Sekarang setelah anda tahu cara menjalankan Llama 2 secara langsung pada komputer anda menggunakan Text-Generation-WebUI, anda juga sepatutnya boleh menjalankan LLM lain selain Llama. Ingatlah konvensyen penamaan model dan hanya versi model terkuantasi (biasanya ketepatan q4) boleh dimuatkan pada PC biasa. Banyak LLM terkuantisasi tersedia di HuggingFace. Jika anda ingin meneroka model lain, cari TheBloke dalam pustaka model HuggingFace, dan anda harus menemui banyak model yang tersedia.
Atas ialah kandungan terperinci Cara Muat Turun dan Pasang Llama 2 Secara Tempatan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



