


一、项目需求
前言:BBS上每个id对应一个用户,他们注册时候会填写性别(男、女、保密三选一)。
经过检查,BBS注册用户的id对应1-300000,大概是30万的用户
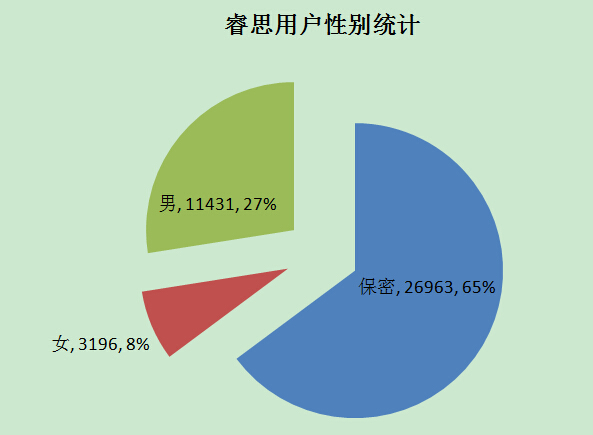
笔者想用Python统计BBS上有多少注册用户,以及这些用户的性别分布
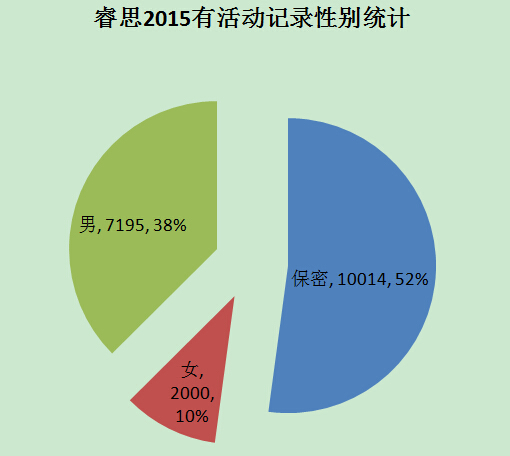
顺带可以统计最近活动用户是多少,其中男、女、保密各占多少
活动用户的限定为“上次活动时间”为 2015年
二、最终结果
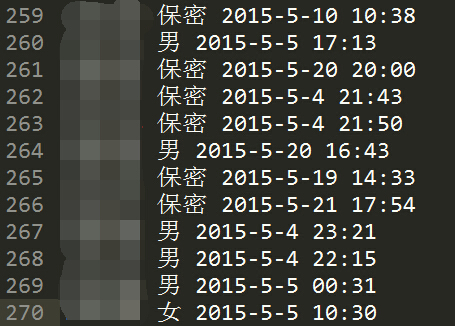
性别信息保存在文本里,一行表示一个用户的信息,各列分别表示
【行数,id(涂掉了),性别,最后活跃时间】
三、实现思路
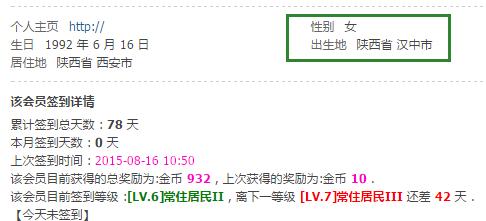
用户性别信息在哪个页面?
得到下面个人主页
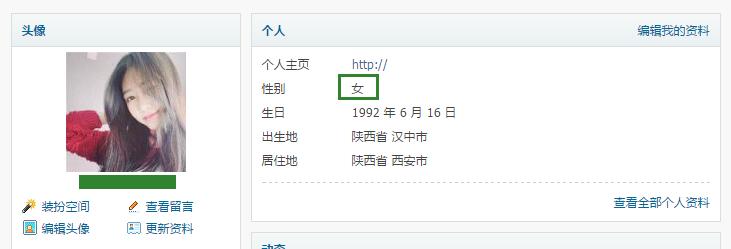
把后面的uid=256730数字改成其他数字,就可以得到其他人的主页。
另外,如果上面的链接无法得到性别,可以再通过这个链接,也是修改uid可以访问其他人主页。
http://rs.xidian.edu.cn/home.php?mod=space&uid=256730&do=profile
四、数据如何存储?
用数据库还是其他方案?
为了阅读方便,我们考虑用文本文件存储。
30万的用户存储在一个文本里会导致文本过大。如果程序被意外终止,30 万的用户数据需要重新爬取。
我们我们考虑一个文本里存放1000条记录,理论上可以用30个文本来存放30万条数据。
文本名称为correct1-1001.txt correct47001-48001.txt,注意:1-1001是[1,1001),包含1,不包含1001
1、使用正则匹配找出性别
查看网页源代码
<!-- 找出性别这一栏--> <li><em>性别</em>女</li> 还可以找到活动时间--> <li><em>上次发表时间</em>2015-11-4 20:04</li> <!-- 有些id不存在相应的用户,会有这样的提示--> <p>抱歉,您指定的用户空间不存在</p>

我们可以利用re模块来进行正则匹配
sexRe = re.compile(u'em>\u6027\u522b</em>(.*?)</li') timeRe = re.compile(u'em>\u4e0a\u6b21\u6d3b\u52a8\u65f6\u95f4</em>(.*?)</li') notexistRe = re.compile(u'(p>)\u62b1\u6b49\uff0c\u60a8\u6307\u5b9a\u7684\u7528\u6237\u7a7a\u95f4\u4e0d\u5b58\u5728<')
因为中文的原因,需要Unicode 转换 中文工具,可以用站长工具 Unicode 转换 ASCII,ASCII 转换 Unicode,比如下面这个链接: http://tool.chinaz.com/Tools/Unicode.aspx
这儿是简单获取性别的源代码,通过urllib2对链接myurl发送一个get请求,将得到的html保存下来。注意编码问题unicode(html, 'utf-8'),然后对html正则匹配seWord。
如果该用户有性别信息,返回对应的性别;否则,返回None
#对myurl页面进行seWord匹配查找
#seWord是用unicode表示
def getInfo(myurl, seWord):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
req = urllib2.Request(
url=myurl,
headers=headers
)
time.sleep(0.3)
response = urllib2.urlopen(req)
html = response.read()
html = unicode(html, 'utf-8') #需要进行编码,否则找不到信息
timeMatch = seWord.search(html) #因为seWord是用unicode表示
if timeMatch:
s = timeMatch.groups()
return s[0]
else:
return None
五、错误处理
1、断网情况(热修复方案)
2、无法获取性别
知识点小结
对于这种错误,SyntaxError: Non-ASCII character '\xe5' in file
需要在文件开头加上# -*- coding: UTF-8 -*-
因为 python 的默认编码文件是用的 ANSCII 码
BBS网页源代码使用utf-8进行编码的。
本项目设计到中文字符,自然会遇到编码问题。
import sys print sys.getdefaultencoding()
输出 ascii
从上面的代码可以看出 sys.defaultencoding 是 ANSCII,ANSCII是无法对中文字符进行编码的。UTF-8是Unicode的实现方式之一,可以对中文字符进行编码。遇到中文字符,我们需要加上这行代码
reload(sys)
# sys.setdefaultencoding('utf-8')
更改 sys.defaultencoding 为'utf-8'
后期整理的时候发现了自己一个小问题,因为正则表达式当时用unicode来表示的,所以需要把html进行unicode转换进行查找。
后来发现可以直接用汉字对原来的html进行查找。
# -*- coding: UTF-8 -*-
html = response.read()
sexRe = re.compile('em>性别</em>(.*?)</li')
timeMatch = sexRe.search(html)
if timeMatch:
s = timeMatch.groups()
print "字符串 "+s[0]
html = unicode(html, 'utf-8')
sexRe = re.compile(u'em>\u6027\u522b</em>(.*?)</li')
timeMatch = sexRe.search(html)
if timeMatch:
s = timeMatch.groups()
print "unicode " +s[0]
输出
字符串 女 unicode 女 html = response.read() print len(html) html = unicode(html, 'utf-8') # print len(html)
输出
html = response.read() print len(html) html = unicode(html, 'utf-8') # print len(html)
输出
35423 33658
以上就是python实现爬虫统计学校BBS男女比例的前期准备和方案分析,希望对大家的学习有所帮助。
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



